
基于BERT的心血管医疗指南实体关系抽取方法
2021-01-21 03:23武小平
计算机应用 2021年1期
武小平,张 强,赵 芳,焦 琳
(1.武汉大学计算机学院,武汉 430072;2.武汉大学中南医院心血管内科,武汉 430070)
0 引言
心血管疾病具有发病因素多、高患病率、老年人占比多等特点,而且治疗康复周期长。通过将心血管领域医疗知识与计算机优势相结合,构建心血管领域的专病知识图谱应用,可在一定程度上缓解医疗资源紧张的问题。关系抽取是构建计算机医疗知识层的基础信息处理任务之一。
随着近几年深度学习的发展,学者们开始采用深度学习的方法来解决经典关系抽取方法的精确度低的问题,包括使用卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)以及相关门循环单元(Gated Recurrent Unit,GRU)、长短期记忆(Long Short Term Memory,LSTM)网络。深度学习方法能在一定程度上缓解基于经典特征的关系抽取模型的弊端,即对特征的选取是由模型训练完成,不存在人为的主观因素介入,同时特征信息十分原始,很少有二次加工的特征信息的输入,因此累计误差更少,从而使得深度学习方法在很多场合中比经典的基于特征工程的关系抽取方法精度都要高。文献[1]将双向变形编码器(Bidirectional Encoder Representation from Transformers,BERT)[2]预训练模型应用到关系抽取领域并在对应数据集上取得了很好的结果,说明BERT 预训练模型在自然语言处理(Natural Language Processing,NLP)中十分有成效。本文在此基础上,以心血管疾病的部分中文医疗指南语料作为数据集,对心血管疾病领域的实体关系抽取做出相关研究。
本文工作主要有:
1)本文提取了心血管疾病领域的部分医疗指南,包括《中国高血压防治指南2018 年修订版》《冠心病合理用药指南》(第二版)《稳定性冠心病中西医结合康复诊疗专家共识》等文献中的语料,同时对这些语料在专业医生的指导下进行了相应的实体类别和实体关系类别标注,构建了心血管疾病领域的关系抽取数据集。同时,针对心血管类疾病的特点,提出了“因素”这个实体类别,用以表示心血管类疾病中生活的重要习惯等特征。
2)基于双向变形编码器循环神经网络(Bidirectional Encoder Representation from Transformers and Long Short Term Memory,BERT-LSTM)模型在实体关系抽取中的研究基础,本文针对心血管类疾病关系抽取提出了基于双向变形编码器卷积神经网络(Bidirectional Encoder Representation from Transformers and Convolutional Neural Network,BERT-CNN)模型,该模型通过加载BERT 预训练模型,在一定程度上提取语料中上下文的特征,再通过与CNN 模型综合,从而更好地对关系抽取做出最后的分类预测。
3)本文基于心血管疾病医疗指南构建的关系抽取数据集是中文的,由于中文语句中是基于词的表达语义,原有的BERT 网络模型按字掩盖的自监督训练任务不太适应中文数据集。而基于全词掩模的双向变形编码器(Bidirectional Encoder Representation from Transformers based on Whole Word Mask,BERT-WWM)[3]是通过整个词掩盖的自监督训练任务训练出来的模型,因此本文将中文数据集预训练的BERTWWM 替换了原来的BERT 网络。实验证明,在心血管疾病医疗指南关系抽取数据集下,基于全词掩模的双向变形编码器卷积神经网络(Bidirectional Encoder Representation from Transformers and Convolutional Neural Networks based on whole word mask,BERT(wwm)-CNN)模型具有更好的评测结果。
1 相关工作
1.1 关系抽取方法
文献[4]通过语言学的知识编写关系规则,从文本中匹配与规则相似度高的实例,该方法对于小规模的数据准确率比较高,但是相对应的,召回率很低,而且需要该领域的专家才能编写出对应的规则。文献[5]通过使用支持向量机作为分类器,研究语料中的语法、词汇特征与实体关系抽取之间的联系。尽管经典的关系抽取方法取得了一定的效果,但是特征工程的误差会有传播效应,对抽取的结果有着极大的影响。
1.2 基于深度学习的关系抽取方法
随着近几年深度学习的发展,学者们开始采用深度学习的方法来解决经典关系抽取方法无法解决的问题,比如可以减少人工因素的介入,减少人为选择特征,从而缓解特征抽取带来的误差累积问题[6]。文献[7]首次提出将RNN 模型应用于关系抽取中,该模型可以学习任意类型及长短的词语和句子成分表示。文献[8]将语法树引入到RNN 模型中,可以对目标任务的重要短语显式地提高权重,这一点与注意力机制[9]类似。该模型还证明了对模型的参数进行平均以提高泛化能力。文献[10]首次将CNN 引入到关系抽取中,将所有单词转换为词向量后作为输入,而不需要引入词性标注等,同时联合句子级别特征并串联起来,形成最终的向量。
1.3 生物医疗领域关系抽取
文献[11]首次将深度学习方法应用在医疗领域关系抽取中,利用卷积神经网络自动学习语义中的特征,从而减少对手动特征工程的依赖;文献[12]提出使用以LSTM 为门单元的双向循环神经网络来抽取疾病与治疗药品之间的关系;文献[13]提出基于字符的单词表征模型特征输入到卷积神经网络中,同时联合LSTM 网络,用于提取化学物质和疾病之间的关系,表明字符的单词特征信息输入能提高模型的性能。
1.4 BERT网络模型关系抽取
文献[2]在基于Transformer[14]网络模型基础上提出了BERT 网络模型,认为该模型可以作为通用的语言表征模型,能理解语义之间的关系。该模型框架在2018 年刷新了11 项NLP 任务。后续有研究都使用BERT 网络模型进行相关工作并取得了一定的效果[15-17]。文献[1]在实体关系抽取领域中提出BERT-LSTM 网络模型并在2019 年取得了最好的性能。尽管LSTM 网络模型十分适合解决序列模型的问题,但是在训练时容易出现梯度消失和爆炸的问题,特别是在已经使用BERT作为特征抽取模型的前提下,同时网络也过于繁杂。
2 心血管类疾病语料收集与标注
近年来,实体关系抽取领域出现了许多相关的公开数据集用于模型的训练与评测。然而在一些较为专业的垂直领域比如心血管类疾病领域却很少有公开的关系抽取数据集。在医疗领域,专病医疗指南汇集了众多专家的共识和医疗经验,可以作为该类疾病医疗的重要参考资料。本文通过搜集心血管类疾病领域中一些医疗指南中的语料,结合心血管类疾病的医疗实践,在专业医生的指导下通过人工标注实体类别与实体关系类型,构建了一个心血管类疾病领域实体关系抽取数据集。
2.1 实体类别与关系类别
本文在确定实体类别与关系类别时,首先了解关于疾病领域的公开数据集的类别情况,主要借鉴了关于电子病历的实体与关系类别[18-20]。然后结合心血管类疾病本身的特点,对电子病历的类别与关系做了一定的修改。实体具体如表1所示,总共6 大实体,包含疾病、治疗、症状、药物、因素和检查。“因素”是本文根据心血管类疾病的特点添加的。结合医生的医疗实践,心血管类疾病从问诊、治疗到最后的康复都十分重要,特别是康复阶段,尤为需要注意。

表1 实体类别Tab.1 Categories of entities
而康复阶段需要注意许多生活上的习惯、饮食、体育锻炼等方面,针对心血管领域的实体类别中特定添加了“因素”这一类别。实体关系类别如表2 所示,共6 大关系,因为添加了“因素”这个实体,因此在实体关系类别里也做了扩充。

表2 关系类别Tab.2 Categories of relations
2.2 数据集构建
本文提取了《中国高血压防治指南2018 年修订版》《冠心病合理用药指南》(第二版)《稳定性冠心病中西医结合康复诊疗专家共识》中的语料,然后根据前文提到的实体类别和关系类别对提取的语料进行人工标注。该数据集中的标签内容主要包含实体类别、实体关系类型、实体短语在语料中的索引。本文共搜集了4 656 条语料,具体关系类别分布比例如图1 所示,可以看出Trid类别占比最大,这是由于医疗指南更多地描述用于治疗疾病,但从整个类别分布来看,虽然做不到十分均衡,但是大体上相差不大。

图1 数据集类别比例Fig.1 Ratio of different categories in dataset
3 基于BERT-CNN的实体关系抽取
3.1 BERT-CNN网络架构
文献[1]提出的BERT 和LSTM 综合的网络模型用于关系提取取得了较好的效果。在这种情形下,相当于把BERT 网络作为一种词嵌入模型提取初步的特征,然后利用LSTM 作为后续的网络模型。RNN 的确十分适合序列模型,尽管LSTM 门单元和GRU 门单元在一定程度上能缓解梯度消失、梯度爆炸的问题,但是其框架结构复杂,训练模型的周期长[6]。特别是在前面已经采用了BERT模型的前提下,更显得有些冗余。而CNN 结构相对而言简单,训练更为迅速。文献[10]提出用深度卷积神经网络提取语料的特征来用作关系抽取,在SemEval-2010 Task 8中取得了很好的结果,因此本文通过将BERT 网络模型作为语料的预训练模型抽取语料的上下文特征,然后使用CNN 网络模型作为关系抽取的网络,即BERT-CNN 实体关系抽取网络模型。BERT-CNN 网络模型架构如图2 所示,其中:GeLU(Gaussian error Linear Unit)为激活函数高斯误差线性单元,ReLU(Rectified Linear Unit)为激活函数整流线性单元。
整个网络模型分为3步:
第一步 在语料输入网络首先需要进行预处理操作,用具体的实体类别代替语料中的实体,然后将语料中的实体附加在语料中。例如:语料“儿童吸烟对动脉硬化形成有很大促进作用”会预处理为“因素对疾病形成有很大促进作用SEP儿童吸烟SEP动脉硬化”。
第二步 BERT 网络预训练模型输入信息由输入语料转化的三个词嵌入相加而成。第一个是将输入语料通过WordPiece[21]模型转化为Token Embeddings 的词向量;第二个是用于区分句子之间是否存在上下文关系的Segment Embeddings;第三个是将单词位置通过学习出来的网络模型抽取的Position Embeddings。将该输入向量输入到BERT 预训练模型中,取得BERT 网络输出的last_hidden_state 部分作为CNN网络部分的输入特征。
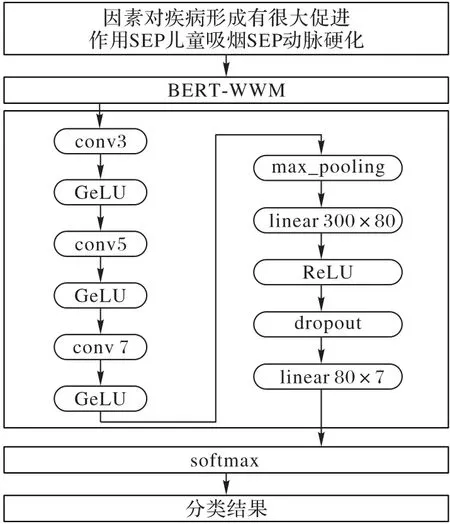
图2 BERT-CNN网络模型架构Fig.2 BERT-CNN network model structure
第三步 将BERT 网络之后的特征信息接入CNN 网络模型。CNN 网络部分首先是三个不同尺寸的卷积模块和GeLU激活函数,如式(1)所示。然后通过max_pooling 操作将特征信息降维,接着经过线性层和随机失活层用以缓解网络的过拟合。然后通过最后一个线性层将维度降为关系类别的总数6维用于最后的分类。最后接softmax 分类器用于做最后的预测,如式(2)所示:
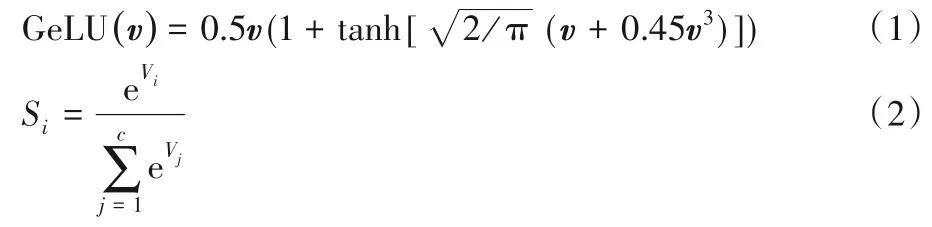
其中:V表示网络结构中的特征向量;Vj表示向量第j个位置的权值;Si表示预测类别为i的概率;e 表示自然常数;表示该元素的指数;c为类别总数。
仅有该网络模型还不能有效地抽取出语料的特征信息,因为尽管BERT 网络模型是通过开源语料预训练过的,但是整个网络模型参数并没有针对心血管类疾病领域的实体关系抽取任务进行训练,本文则通过构建的心血管类疾病领域的医疗指南数据集对提出的网络模型进行训练微调,训练损失函数如式(3)所示:

其中:yi表示真实值表示预测值。
3.2 基于BERT-WWM的改进
在BERT 网络的自监督任务中,有一个是Masked Language Model(MLM),即在网络训练的时候随机从输入序列中掩盖(mask)掉一部分单词,然后通过上下文输入到BERT 网络中来预测该单词。MLM 一开始是针对英文的NLP训练方法,因此可以针对单词进行mask 而不会损失句子本身的语义。而应用到中文领域,MLM 任务会将本身是一起的中文词语分割,从而导致损失了中文句子本身的语义。Google在2019 年5 月31 发布了BERT 的更新版本,即BERT-WWM。该版本的BERT就是改变了原来MLM 任务的训练策略,不再是将句子中一个一个的单词随机掩盖(mask),而是将词看成是一个整体,所以掩盖的时候会将词一起掩盖,从而尽量保护句子本身的语义不被分割。然而,Google 发布的BERTWWM并没有针对中文版的,文献[3]则基于此提出了用中文训练好的BERT-WWM 网络模型参数。该网络模型在训练中文的MLM 任务时,不再是以字为粒度切分随机掩盖(mask),而是采用了哈尔滨工业大学LTP(Chinese Language Technology Platform)分词[22]工具先对句子分词,然后再以词为粒度随机掩盖(mask),进行自监督训练。在针对心血管类疾病领域中文医学指南关系抽取数据集前提下,为更好地提高中文语义理解,将BERT-CNN 中的BERT 网络模型用BERT-WWM 模型替换,从而提高对中文语料特征的抽取效果。
4 实验与数据分析
4.1 评价指标
在分类领域,为了精确地评测模型的性能优劣,一般看准确率(precision)与召回率(recall)。首先可以将测试集中样本分为预测正确的阳样本(True Positive sample,TP)、预测错误的阳样本(False Positive sample,FP)、预测错误的阴样本(False Negative sample,FN)、预测正确的阴样本(True Negative sample,TN)。准确率(P)和召回率(R)如式(4)、(5)所示。在比较不同模型的准确率与召回率时,两个指标各有高低的时候不好直接评判性能的优劣,因此在关系抽取领域,一般比较的是F1值,如式(6)所示:

4.2 验环境与参数介绍
本文的实验数值计算得到了武汉大学超级计算中心的计算支持和帮助。本文实验申请部署的GPU 服务器配置为4 块Nvidia Tesla V100 显卡(16 GB 显存),2 块Xeon E5-2640 v4 x86_64 CPU(20 核心),128 GB DDR4 内存,240 GB 固态硬盘,使用Centos 操作系统,编程工具为python3.6,同时使用了开源机器学习库pytorch1.3.1 GPU版。
在本文的实验中,为了充分对比本文提出的网络模型,在同一心血管类疾病医学指南关系抽取数据集下,除了使用BERT-CNN、BERT(wwm)-CNN 模型,还选取了BERT-LSTM[1]与RNN[23]网络模型作为实验对比。
按照算法1 对网络模型进行训练。首先下载训练好的BERT和BERT-WWM模型参数,然后使用训练对网路模型进行微调,按照显存容量设置合适的batch_size。同时根据训练日志判断损失函数的收敛情况,同时对随机失活率、学习率与学习率的衰减值进行微调,直到训练的损失稳定收敛。在本文实验中,batch_size 设置为96,随机失活率为0.3,学习率设置为0.001,衰减率设置为0.7。在模型训练结束后,通过测试集对网络模型进行测试,并计算出准确率、召回率和F1值。
4.3 实验结果与分析
图3 所示为各个网络模型训练时的损失函数图,可以观察到各网络模型在数据集的迭代训练下,最后训练损失都收敛了。相对而言RNN 模型收敛最快但是最终损失值却最大,而BERT(wwm)-CNN 网络模型收敛后的训练损失值最小。图4 所示为各网络模型在测试集下的F1值随着数据集训练过程的变化情况,同样最后都收敛到稳定的值。从图中可以得出BERT(wwm)-CNN 取得的F1值最好。整体上看BERT 网络模型比RNN 网络模型效果更好一些,详细数据如表3所示。
从表3 可以看出,BERT-LSTM 比RNN 网络模型的F1值要高,说明相比词嵌入模型而言,BERT网络预训练模型可以更好地抽取出语料之间的特征信息。BERT-CNN 比BERTLSTM 网络模型测试的F1值高,说明在该数据集中CNN 的效果更好,LSTM 因为结构更加复杂反而降低了网络性能。同时由于数据量规模的原因,BERT-LSTM 在一定程度上也无法发挥出本身的性能优势,因此在该数据集下BERT-CNN 能取得更好的结果。
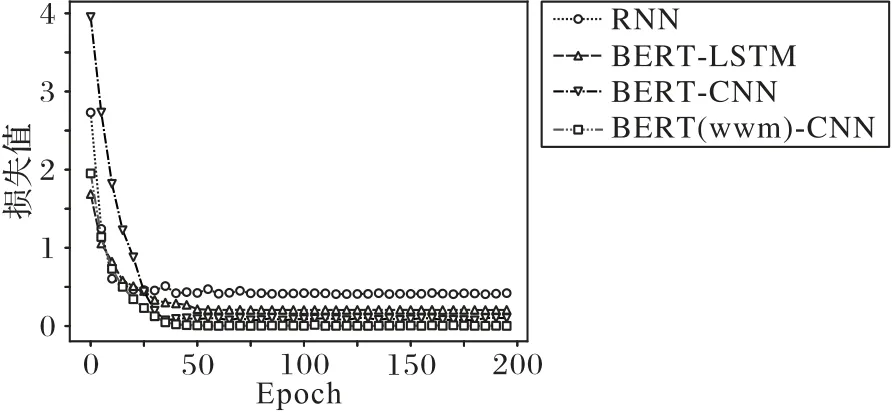
图3 不同网络模型的训练损失函数Fig.3 Training loss functions of different network models
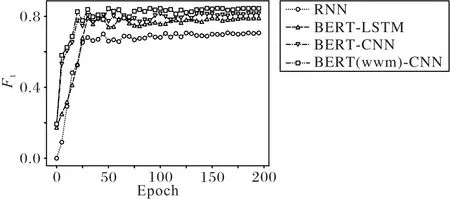
图4 不同网络模型在测试数据集下的F1值Fig.4 F1 values of of different network models on test dataset

表3 各网络模型准确率、召回率和F1值Tab.3 Precision,recall and F1 value of different network models
对比BERT-CNN 与BERT(wwm)-CNN 的F1值,因为是中文数据集,采用整体分词模型自监督任务的BERT-WWM 预训练模型在实验中取得了更好的效果,说明在中文自然语言处理中,通过对中文的分词预处理能够提高模型的性能。最后通过对比这4 项数据,说明在心血管类疾病中文医疗指南关系抽取数据集中,本文提出的BERT(wwm)-CNN 模型取得了最好的性能,F1值达到了0.83。
5 结语
计算机应用与其他学科的交叉研究不断地加深,极大地促进了各个行业的发展与进步。通过对心血管类疾病领域的医疗指南做相应的关系抽取研究,在基于BERT 网络模型的基础上,提出了针对该领域的BERT-CNN 实体关系抽取模型,从而可以提取出更有意义的语义关系特征,进一步为心血管类疾病领域的知识图谱构建、医疗自动问答等做出了基础性的工作。
在本文提出的BERT-CNN 模型中,通过将BERT 与CNN结合的网络模型结构取得了比较好的结果,可以肯定的是BERT 的预训练模型有着至关重要的作用,但尚不能确定与CNN 模型的结合就是最好的模型。BERT 网络基于Tansformer网络模型,即完全基于Attention机制构建起来的超大规模网络,可以解决序列模型带来的长期依赖问题,但同时对语料本身的位置问题上解决得有些粗略。长期依赖问题与输入顺序问题好像鱼和熊掌不可兼得,或许探索其他网络模型结构的特点包括残差网络模型、胶囊网络等,或者在其他领域取得较好成绩的网络模型与BERT 网络的结合都可以值得考虑。
猜你喜欢
心血管病防治知识(2022年22期)2022-11-11
心血管病防治知识(2022年24期)2022-11-11
心血管病防治知识(2022年23期)2022-11-10
心血管病防治知识(2022年25期)2022-11-10
现代计算机(2021年33期)2022-01-21
少儿画王(3-6岁)(2020年4期)2020-09-13
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
东方教育(2018年20期)2018-08-22
微型计算机(2009年4期)2009-12-23
