
基于轻量级模型的经编布瑕疵在线检测算法
2021-01-20 12:28唐有赟盛晓伟余智祺孙以泽
东华大学学报(自然科学版) 2020年6期
唐有赟, 盛晓伟,徐 洋, 余智祺,孙以泽
(东华大学 机械工程学院, 上海 201620)
布匹瑕疵检测是纺织企业生产流水线上的一个重要环节,布匹的检测效率以及准确度决定企业的经济效益及客户持续合作的意向。现阶段,大多数纺织企业采用人工检测的方式,该检测方法需要工人长时间站立于验布机台前,通过不间断地仔细观察处于移动状态中的布匹瑕疵状态。其存在以下不足:首先对人眼伤害极大并且检测效率低,其次因不同工人的评判标准不一致导致检测准确率低,最后对工人的培训以及工资支付成本高。近年来,随着机器视觉技术的发展,其被工业界广泛应用[1-2]。该方法不仅可以弥补工人效率低的不足,还可以降低工人劳动强度,并且不受工人主观性的影响,可以提高检测准确率。
在瑕疵检测中,应用机器视觉的方法大致可以分类两类。一类是传统的图像处理方法:如胡克满等[3]通过改进Canny算子提取瑕疵特征进行检测;吴莹等[4]通过K- 奇异值分解(K-singular value decompostion, K-SVD)学习字典提取织物的表明纹理特征进行检测;汤晓庆等[5]通过Gabor滤波器结合方向梯度直方图(histogram of oriented gradient,HOG)特征进行瑕疵检测;万东等[6]通过先计算瑕疵的灰度共生矩阵(gray level co-occurrence matrix, GLCM)特征,然后利用支持向量机进行分类。该类方法由于需要人工提取特征,检测性能容易受到预测样本的多样性影响,泛化能力弱。另一类是近年来发展迅速的深度学习方法[7-8],该方法不需要人工提取特征,可以真正实现端到端的学习。但是由于大多数模型采用大量的卷积层操作,如赵志勇等[9]通过采用Inception-Resnet-v2进行瑕疵检测,但是一张图的检测耗时为0.2 s,虽在精度上远超传统图像处理方法,但速度达不到工厂实时在线检测的要求。
为满足实际工厂需求,本文提出轻量级模型的经编布匹瑕疵在线检测算法,通过改进MUNIT[10]模型算法以扩充瑕疵样本,在一阶模型YOLO(you only look once)的基础上引入深度可分离卷积以减少参数量,从而提升检测速度,加入自定义ASPP(atrous spatial pyramid pooling)模块以提高模型检测精度,并采用Focal Loss损失函数减少类别不平衡对检测精度的影响。为验证模型的高效性,通过设置一系列试验与原始一阶模型YOLO及二阶模型Faster R-CNN(region-convolutional neural network)进行对比。
1 经编布匹瑕疵在线检测系统组成
经编布匹瑕疵在线检测系统主要由相机、条形光源、计算机、编码器、检测平台组成,如图1所示。相机为DALSA黑白线扫相机,型号为LA-CM-04K08A-00-R,相机的图像分辨率为4 096像素×1像素,采样频率由编码器根据布匹的速度发出脉冲信号决定。相机高度以及相邻相机之间的间距可以根据实际需要拍摄布匹的幅宽进行上下、左右调整,光源的亮度可以根据布匹的颜色深浅通过输出电压进行调整。由于布匹在运动过程中不可避免会产生抖动,可能导致相机所拍摄的图像模糊,因此,检测系统的检测平台与相机及光源独立安装。瑕疵检测程序基于Windows 10操作系统、TensorFlow框架、python语言,CPU为E3-1220v3处理器,内存容量为32G, GPU型号为NVIDIA GeForce GTX 1660。
2 布匹瑕疵在线检测算法设计
经编布匹瑕疵在线检测算法是整个系统的核心,主要包含:改进MUNIT模型扩充瑕疵样本、自定义ASPP模块、设置深度可分离卷积、采用Focal Loss函数、建立模型评判标准5个部分。通过MUNIT模型扩充瑕疵样本,将扩充的瑕疵样本与真实拍摄图像共同用于检测模型的训练,将训练得到的最优模型进行瑕疵检测。
2.1 改进MUNIT模型
基于深度学习的目标检测准确度在一定程度上取决于瑕疵样本训练集的数量,虽然通过搭建的瑕疵检测系统已经采集一定数量的瑕疵图像,但是部分不常见瑕疵样本数量略有不足。目前样本增强的方法大概有以下3种:几何变换、VAE(variational auto-encoder)、GAN(generative adversarial networks)。几何变换的方式由于没有生成新的图片,作用效果不大;VAE由于没有对抗损失,生成的图片会比较模糊;而传统GAN容易出现模式崩溃的问题。
为解决以上3种方法的不足,采用改进的MUNIT模型进行瑕疵样本扩充,该模型的框架如图2所示。将瑕疵图像(X)编码为内容和风格两部分,将内容存储于共享内容空间(C),而风格存储于不同风格空间(S),如图2(a)所示。输入正常经编布匹样本(X1),将其内容编码存储至共享内容空间C,将共享内容空间C的内容与风格空间S2中随机抽取一份解码合成新的瑕疵图像,在这个过程中加入随机噪声,如图2(b)所示。
为解决传统GAN因训练不稳定而容易出现模式崩溃的问题,改进MUNIT模型,如图3所示。通过构建多个重构过程,在重构过程中都加入随机噪声,同时使用像素损失和GAN损失,在训练过程中将所有的损失函数联合在一起同时优化,最终得到训练过程稳定、生成瑕疵样本多样性好的MUNIT模型。将正常布匹和瑕疵图像分别编码成内容和风格,再将编码的内容和风格重构为原始图像,如图3(a)所示。同理,通过交叉重构实现正常布匹与瑕疵布匹的内容和风格编码及解码。此外,为使生成图像多样性更好,将正常布匹和瑕疵图像重构的图像进行再次编码,然后对原始图像的内容及风格进行优化,如图3(b)所示。
2.2 自定义ASPP模块
通常神经网络的卷积核越大,其感受野越大,从而能够更好地获取特征图上的全局信息,因此在一定程度上ASPP模块能提高模型检测准确率。但是,随着卷积核的增大,其参数量大幅增加,最终导致模型的计算量过大,运行速度急剧降低。因此,基于空洞卷积的思想,为经编布图像定义符合瑕疵特征的ASPP模块,如图4所示。通过设置不同生长率的空洞卷积,在不增加计算量的前提下提升感受野,以提高模型的检测精度。
2.3 设置深度可分离卷积
传统卷积过程如图5所示。
在卷积过程中某一层经编布匹的瑕疵特征图为10×10×512(10×10表示瑕疵特征的大小,512表示特征的数量),卷积核的大小为3×3,数量为1 024
个,步长为2,填充采用same形式,因此根据卷积操作,得到的特征图为5×5×1 024,总的FLOPs(floating point operations)计算量为235 929 600(3×3×2×5×5×512×1 024)。
由于传统卷积操作的计算量大,因此,采用深度可分离卷积的思想降低参数量,如图6所示。首先对经编布匹的瑕疵特征在通道上进行卷积操作,得到5×5×512的瑕疵特征图。然后再使用1 024个1×1×512的卷积进行操作,最终得到和传统卷积一样的特征输出为5×5×1 024。总的FLOPs计算量为26 444 800(3×3×512×2×5×5+1 024×512×2×5×5),计算量约为传统卷积的11.2%。
通过结合ASPP模块以及深度可分离卷积,最终的经编布匹瑕疵检测模型整体网络框架如表1所示。
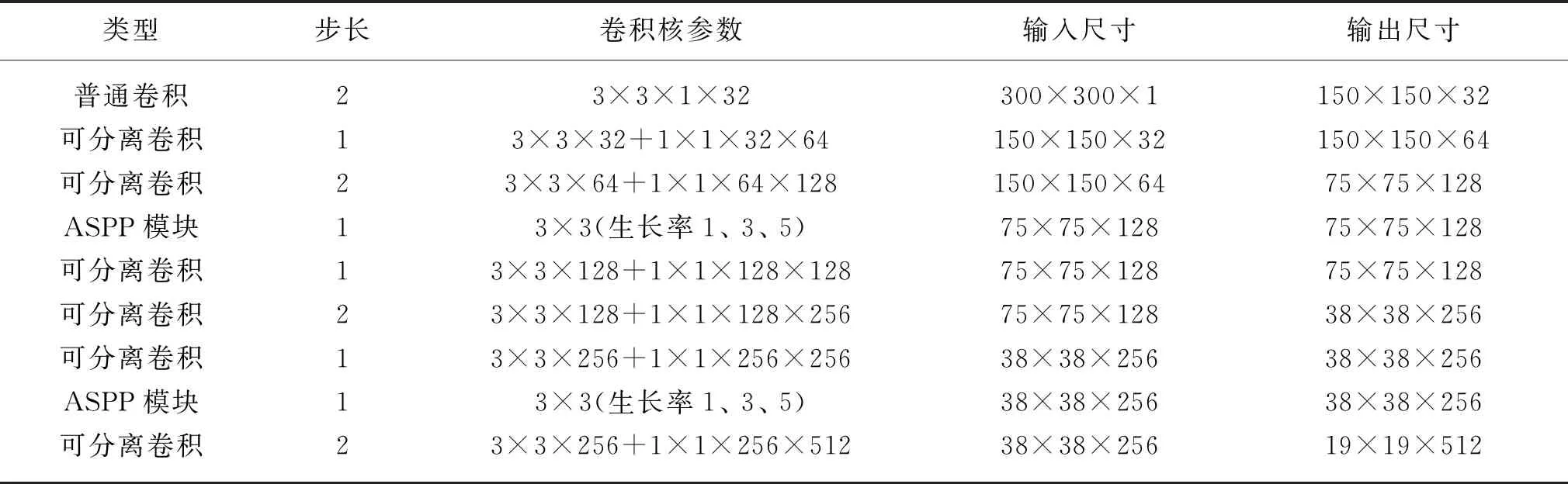
表1 整体网络结构框架
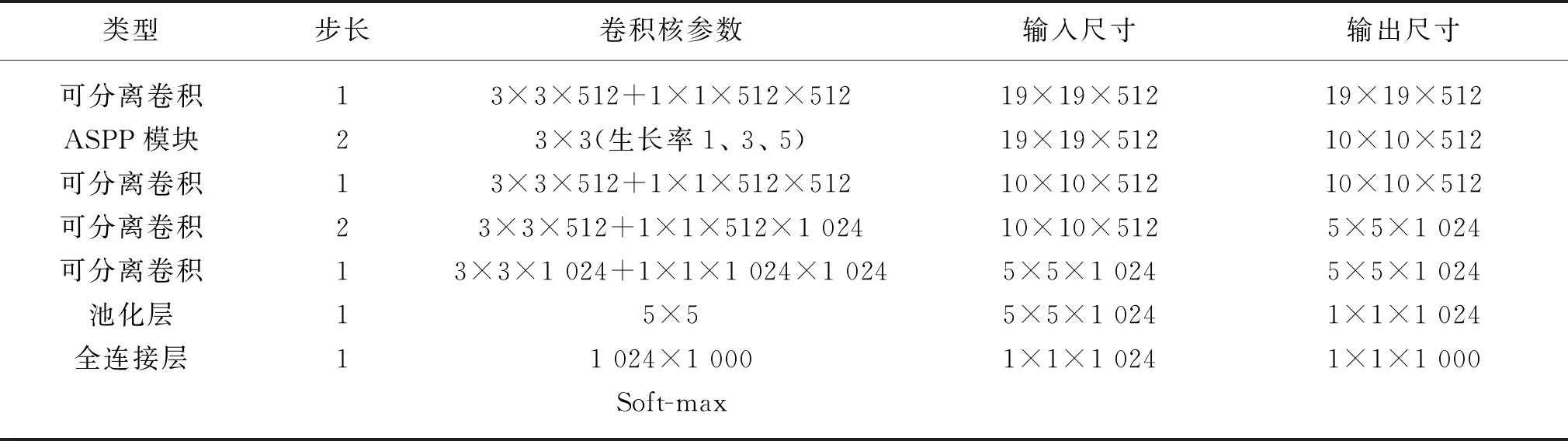
(续表)
2.4 设置Focal Loss函数
神经网络训练过程中参数优化的稳定性在一定程度上取决于损失函数的选择。目前,常用目标检测网络的类别损失函数为交叉熵损失函数,其二分类交叉熵公式为
CE(p,y)=-ylog(p)-(1-y)log(1-p)
(1)
式中:p为模型预测的概率;y为真实值。定义表达式为
(2)
式中:pt为定义的中间变量名。为方便后续表示,则最终的二分类交叉熵损失函数为
CE(pt)=-log(pt)
(3)
根据式(3)可以推断,交叉熵损失值容易受到类别不平衡问题的影响。由于经编布匹中瑕疵所占据的像素区域相对于整个图像而言比例很小,在训练过程中会出现正负样本不平衡的问题,因此采用Focal Loss函数,如式(4)所示。
FL(pt)=-αt(1-pt)γlog(pt)
(4)
式中:αt为矫正系数;γ为超参数,一般取2。通过在交叉熵损失函数中增加αt和γ两个参数约束后,可以在网络的训练过程中自动对正、负样本,以及简单、复杂样本的不平衡进行调整。
2.5 建立模型评判标准
为使最终得到的模型在实际工厂的经编布匹瑕疵检测中也有很好的准确率,因此在模型训练过程中建立符合瑕疵特征的评判标准是极其重要的。通常检测模型好坏的标准有正确率、准确率、召回率、ROC(receiver operating characteristic)曲线、AUC(area under curve)值、mAP(mean average precision)等,不同评判标准用于不同场景。针对经编布匹瑕疵类别数量不平衡的问题以及瑕疵特征的独特性,采用mAP的评判方法。
假设瑕疵为二分类,可以得到混淆矩阵,其中,TP代表将瑕疵正确预测为瑕疵的数量,TN代表将背景正确预测为背景的数量,FP代表将背景错误预测为瑕疵的数量,FN代表将瑕疵错误预测为背景的数量。
准确率(P)表示真正瑕疵数量占预测瑕疵数量的百分比,其计算式为
(5)
召回率(R)表示被正确预测的瑕疵数量占真正瑕疵数量的百分比,其计算式为
(6)
为了结合瑕疵的准确率和召回率,使用PAP表示同一类别的瑕疵在不同召回率上的准确率平均值,其计算式为
(7)
针对瑕疵类别不平衡的特征,结合所有类瑕疵每一个PAP值,选择PmAP作为模型的最终评判标准,其计算式为
(8)
式中:c为瑕疵的类别数。根据PmAP的评判标准,只要最终训练得到的模型评判值足够高,说明该模型的泛化能力越强。
3 经编布匹瑕疵在线检测算法试验结果
为验证轻量级经编布匹瑕疵在线检测算法的精度与速度,设计不同类型的试验。待检测瑕疵的类型为折痕、脏污、破洞、脱针、勾纱,输入图像大小为300像素×300像素,其中用于训练MUNIT模型的瑕疵图像数量为1 000张,每类瑕疵图像数量为200张。用于检测模型的训练图像数量为10 000张,每类瑕疵图像数量各2 000张。
3.1 MUNIT模型扩充瑕疵样本
在训练MUNIT模型过程中,设定布匹的背景即正常图像为内容,不同种类的瑕疵为风格。因此,在扩充样本的时候只要输入正常图像就可以得到瑕疵图像,如图7所示。
3.2 瑕疵检测效果对比
将训练好的模型用于经编布匹测试集检测瑕疵,采用二阶模型Faster R-CNN、原始一阶模型YOLO及本文模型进行瑕疵检测效果对比,如图8所示。图8中预测类别后面的数值代表模型预测为该类瑕疵的置信度,置信度越高,模型在训练过程中提取不同类别瑕疵各自的特征越好,能够将不同的瑕疵进行准确分类。由图8可知,原始一阶模型YOLO的置信度不高,而本文模型的置信度与二阶模型Faster R-CNN基本一致。
3.3 检测准确率及速度
为评估本文模型的有效性,通过对折痕、破洞、脏污、脱针、勾纱分别各200张经编布匹图像进行检测,与原始一阶模型YOLO以及二阶模型Faster R-CNN进行对比,结果如表2所示。
分析表2可知:本文模型的平均识别准确率为95.8%,比原始一阶模型YOLO高5%左右,与二阶模型Faster R-CNN基本一致;由平均识别时间折算为检测速度时,本文模型的检测速度是原始一阶模型YOLO的3倍左右,约是二阶模型Faster R-CNN的8倍。对于幅宽为2 m的布匹而言,本文模型的检测速度可达1.2 m/s,是目前人工检测速度0.2~0.3 m/s的4~6倍,满足工厂实际需求。
4 结 语
本文采用轻量级模型的经编布匹瑕疵在线检测模型,在提高精度的同时减少模型的运行时间,可以代替人工实现瑕疵在线检测,具体结论如下:
(1) 通过改进MUNIT模型扩充瑕疵样本,生成的瑕疵样本图像清晰度较高,可以使检测模型训练数据集不受实际瑕疵样本数据采集的影响。
(2) 通过自定义符合瑕疵特征的ASPP模块,以及引入Folcal Loss损失函数,可显著提高模型的精度,使模型具有更好的泛化能力。
(3) 利用深度可分离卷积解决传统卷积计算量大的问题,显著提高模型运行速度,对于幅宽为2 m的布匹而言,检测速度可达1.2 m/s,满足工厂实际效率需求。
猜你喜欢
法律方法(2021年4期)2021-03-16
扬子江诗刊(2019年3期)2019-11-12
扬子江(2019年3期)2019-05-24
中国诗歌(2017年12期)2017-11-15
中国纺织(2015年12期)2016-01-22
人生十六七(2015年21期)2015-11-14
科普童话·百科探秘(2015年5期)2015-05-26
中国纺织(2015年1期)2015-03-19
中国纺织(2014年7期)2014-10-17
第二课堂(小学版)(2014年3期)2014-08-02
