
基于软判决下的不删余极化码参数识别
2021-01-19 04:58吴昭军钟兆根张立民但波
通信学报 2020年12期
吴昭军,钟兆根,张立民,但波
(1.海军航空大学航空作战勤务学院,山东 烟台 264001;2.海军航空大学航空基础学院,山东 烟台 264001;3.海军航空大学岸防兵学院,山东 烟台 264001)
1 引言
为了对抗信道噪声的干扰,信道编码技术被广泛应用于无线通信系统中。在各种信道编码类型中,极化码是已从理论上证明,性能可逼近香农极限的编码,目前这种编码已经被确定为5G 通信中eMBB 场景控制信道的编码方案,可以预见,在不久的将来,应用了极化码的数字通信系统会越来越多地出现,然而,针对极化码参数识别的研究目前还未见报道,对于非合作通信领域而言,极化码参数识别问题是一个亟待解决的问题。
目前,信道编码盲识别问题已经是非合作通信领域研究的热点。从公开发表的文献来看,针对编码识别的算法主要集中于线性分组码、循环码、卷积码、Turbo 码、LDPC(low density parity check)码等,而单独针对极化码参数识别的算法还未见公开报道。针对线性分组码而言,目前大部分算法主要基于秩准则算法[1-3]完成参数识别,这种算法计算量大,且容错性不好;为了提高秩准则方法的容错性,文献[4]分析了码字经高斯消元后,每一列上0-1分布特征,通过设定门限识别出线性相关列,从而检测出秩亏,该方法容错性有较大的提升,但是计算复杂度有明显的增加;文献[5]在高斯信道下,基于码字之间的欧氏距离分布,对码字进行聚类,从而识别出码长、生成矩阵等参数,该方法适用于低码率、短码长下的分组码;针对循环码而言,目前算法主要基于其严格的代数结构进行识别,如基于码重统计方法[6]、欧几里得辗转相除法[7]及基于多项式分解算法[8-9]等,这些方法都具有较好的工程实用性;针对卷积码而言,文献[10]采用迭代的高斯消元方法获取对偶向量,由于卷积码约束长度较短,故该方法实时性较好,同时还具有一定的容错性;为了进一步提升文献[10]算法的容错性,文献[11-13]提出基于快速Walsh-Hadarmard 变换(FWHT,fast Walsh-Hadarmard transform)的识别方法,该方法本质上是一种穷举算法,虽然具有较好的容错性,但是随着约束长度增加,算法的计算复杂度呈指数增加;此外还有欧几里得算法[14]、快速双合冲算法[15]等,这些算法复杂度低,适用于低误码情况;由于Turbo 码编码结构较为复杂,故针对Turbo 码识别主要分为三部分,即帧结构识别、分量编码器识别和随机交织识别。对于帧结构识别,文献[16-17]充分利用了Turbo 码的编码结构,提出了基于差分预处理的参数识别方法,该方法能够在信道环境恶劣的情况下,完成Turbo 码帧同步、交织长度及码率等参数识别,这为后续分量编码器及交织器识别准备了条件;针对分量编码器,文献[18-19]构造出关于多项式系数的目标函数,然后基于梯度迭代优化的方法求解多项式系数,该方法具有较强的实用性;对于随机交织器识别,文献[20-21]综合了校验符合度方法及Turbo 码反馈迭代译码的思想,提出了预估矫正识别方法,该方法具有较强的容错性,克服了随交织长度增加,算法性能会急剧恶化的问题;针对LDPC码的识别,文献[22-23]首次提出了基于高斯消元及2阶、多阶行消元的稀疏校验矩阵重建方法;为了提升重建方法的容错性,文献[24]将LDPC 码迭代译码的思想引入重建过程中,这使在有噪声条件下,LDPC 码重建率有较大的提高,但是计算复杂度也有较大幅度的增加。从上述分析来看,单独针对极化码参数识别的算法还未出现,而目前实际工程中极化码的应用越来越广泛,对于非合作通信而言,极化码参数识别问题是一个亟待解决的难题。
基于此,本文提出了基于软判决序列下的不删余极化码识别算法,该算法基于极化码的编码结构,首先给出并证明了有关极化码码长、信息比特与冻结比特位置的3 个定理,这3 个定理是识别极化码参数的理论基础;其次,引入了对数似然比(LLR,log-likelihood ratio)概念,为了检测极化码信息比特与冻结比特位置,详细分析了LLR 的统计特性,基于最小错误判决准则,设定最优判决门限,最终实现了参数的识别。仿真结果证明了所提算法的有效性及较好的容错性。
2 极化码基本原理
对于一个二进制离散无记忆信道W重复使用n次,可以得到n个相互独立的信道,然后通过某种线性变换,将其转化为n个相互关联的信道其中,X为信道W的输入符号{ 0,1} ;Y为信道输出符号,为任意实数;Yn表示Y的n维随机向量,Xi−1表示X的i− 1维随机向量。当n充分大时,极化信道将趋近于2 个极端,即一部分极化信道容量趋近于1,剩余部分信道容量趋近于0。在信息发送过程中,信息容量为1 的极化信道用来发送信息比特,而信道容量为0 的极化信道用来发送冻结比特(冻结比特通常为0),从而实现信息快速可靠的发送。极化码原理包含信道合并、信道分裂两部分,下面分别就信道合并、信道分裂及编码方法进行简要介绍。
2.1 信道合并过程
将n个独立无关联的信道合并成Wn:Xn→Yn,其中n=2m。在信道合并过程中,由于系统的信道容量不变,信道的转移概率为



图1 W2 信道结构
此时,W2的信道转移概率为

其中,Bn为比特反转置换矩阵,主要作用为将矩阵F⊗m的行顺序按照某种规则置换。以n等于4 为例,(0,1,2,3)的二进制数为(00,01,10,11),将其二进制反转后得到(00,10,01,11),对应的十进制数为(0,2,1,3),从而得到比特反转置换矩阵为


2.2 信道分裂过程

从信道可靠性而言,巴氏参数含义正好与信道容量相反,即Z(W)值越大,信道可靠性越差,对于巴氏参数的计算,目前有密度进化方法、高斯进化方法等,当信道为二进制删除信道时,巴氏参数的递推计算表达式[25]为
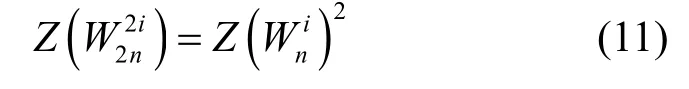
图2 给出了在接收端擦除符号误判概率为0.5下,码长为1 024,码率为的极化码信道巴氏参数分布,从图2 可以明显看出分裂信道的可靠性趋近于2 个极端。

图2 子信道的巴氏参数分布
2.3 极化码编码

由极化码的编码结构可知,对于不删余极化码盲识别而言,需要识别的参数为极化码码长、信息比特位及冻结比特位。由于在实际通信系统中,发送的数据都有固定的帧结构,在每一帧数据前会有2 B 的同步码,故本文假设已经利用帧同步码完成了码字同步,主要的研究内容是利用软判决序列完成不删余极化码码长、信息比特位置及冻结比特位置的识别。
3 极化码识别模型建立
3.1 极化码码长识别
由于极化码码长满足n=2m(m为正整数)关系,故可以遍历m的值,构造不同码长下的码字,然后寻找某固定的特征,实现极化码码长识别,在给出具体的码长识别步骤之前,首先给出定理1 及定理2。



其中,0k×n为k×n的全零矩阵。

定理2 同样具有递推性,即当扩展的码长为4n,8n,…时,码率同样会保持不变。
由定理1 和定理2 可知,利用截获的序列构造不同码长下的极化码码字,当码长小于实际极化码码长时,该码字对应的码率会大于实际的极化码码率;反之,当码长大于实际的码长时,对应的码字码率会等于实际极化码码率,由此可知,在遍历一系列码长中,真实的码长等于最小码率对应的最小码长。从上述分析可知,极化码码长识别的关键在于准确识别出不同遍历码长下的码字码率,传统方法一般基于高斯消元方法求取码率,但是这种方法容错太长。从极化码编码原理来看,如果能识别出克罗内克矩阵中信息比特位和冻结比特位,则不仅可以间接识别出码率,还能识别出极化码的生成矩阵,下面重点讨论极化码信息比特位与冻结比特位的识别方法。
3.2 信息比特位与冻结比特位识别
由第2 节中极化码的编码原理可知,极化码的生成矩阵中每一行向量都是克罗内克幂矩阵中行向量的一部分,故需要判断出克罗内克幂矩阵中哪些是信息比特位置,哪些为冻结比特位置,在给出具体的识别方法之前,首先给出定理3。


从定理3 可知,为了识别出码长为n的极化码信息比特位,可以首先构造m克罗内克幂矩阵,其中,n满足n=2m,然后从第1 行到第n行依次剔除克罗内克幂矩阵中行向量,然后求取其对应的对偶向量,如果对偶向量与码字构成正交关系,剔除的位置为冻结比特位,反之则为信息比特位,从而识别出在遍历的码长n下,所有的信息比特位及冻结比特位,然后间接求解出码率。由于矩阵的维度为(n− 1)×n,故的对偶空间维度为1×n,利用初等行变换与列变换可以得到

由于在信息传输过程中,码字会受到噪声的干扰,不妨设剔除的行标号为k′,则无论遍历的位置k′是否为冻结比特位置,与码字都不会完全构成校验关系,此时有必要对码字是否与构成校验关系进行检测,由于极化码码长较长,硬判决序列不可避免会造成信息的丢失,故本文利用软判决序列来对码字的校验关系进行检测。
设信号的调制方式为BPSK,即星座图映射方式为码元1 映射为+1,0 映射为−1。设遍历的极化码码长为n′,利用截获的软判决序列r构造出N个码字,则码字矩阵T为



利用截获的数据构造出不同码长的极化码,然后剔除m次克罗内克幂矩阵中第k′行元素,求解校验向量,同时计算统计量及门限Λopt,一旦时,可以断定位置k′为冻结信息位置,反之则判定为信息比特位置,从而实现极化码生成矩阵的识别。
3.3 极化码参数识别算法流程
利用3.2 节中求解的门限Λopt与统计量进行比较,一旦,则判定假设条件H0成立,此时剔除的矩阵行对应的位置可判定为信息比特位置,从而实现在该遍历码长下码率及信息比特位置的识别,最后利用定理1 和定理2 的结论识别出真实极化码码长,同时获得该码长下的信息比特位置,具体如算法1 所示。
算法1极化码参数识别算法

3.4 算法计算复杂度分析
不妨设截获的数据量为L,遍历的码长范围为。当遍历的码长为时,需要对2m个信息比特位置进行遍历,而对每一个信息比特位置进行遍历时,需要进行次元素大小比较、次向量加法运算及一次门限解算。由于克罗内克积矩阵构造是固定的,故在识别之前,可以将对偶向量求解并保存,从而减少计算量。为方便描述,本文把一次比较大小等价为一次向量加法运算,将以此门限计算等价于20 次向量乘法,故对码长为2m进行遍历时,需要20 × 2m次向量乘法和L2m次加法运算。对不同遍历码长下的计算量求和,得到总的乘法计算复杂度为加法复杂度为。由此可见,本文算法计算量近似与截获的数据长度及遍历的最大码长成线性增加。
4 仿真分析
在本节仿真中,首先验证本文算法对极化码参数识别的有效性;其次,考察极化码码长、截获码字数目及码率3 个因素对算法正确识别率的影响;最后,对比了在硬判决与软判决2 种条件下算法的性能,以突出软判决序列的优势。
4.1 算法有效性验证
首先,从图3(a)和图3(c)来看,当遍历的极化码码长小于实际码长128 时,码长逐渐减小,码率逐渐增加,直到增加到1;而当编码的码长大于128 时,码长逐渐增加,而码率保持不变,这与定理1 与定理2 的结果完全一致;其次,分析图3(b)及图3(d)可知,当剔除的位置为冻结比特位置时,对应的对偶向量与码字能够保持校验关系,反之当剔除的是信息比特位置时,对偶向量与码字之间的校验关系不在成立,这说明定理3 的结论是一致的。通过设定的判决门限来检测这种校验关系,正好能识别出信息比特位置,从而完成极化码生成矩阵的识别。虽然图3(d)中码字受到了噪声的干扰,但是设定的门限仍然能够有效地完成参数识别,这说明本文提出的算法对噪声具有较强的稳健性。

图3 低信噪比与高信噪比下,本文所提算法的有效性验证
4.2 算法容错性验证
1) 码长对算法性能的影响
仿真设定极化码码长分别为32、64、128、256、512 和1 024,每种极化码的码率为每一种极化码下的码字为2 000 个,设定信噪比范围为−2~8 dB,间隔为0.25 dB,蒙特卡罗实验次数为1 000,统计在不同信噪比下每种极化码参数(包括码长、信息比特位和冻结比特位)的识别率,结果如图4所示。
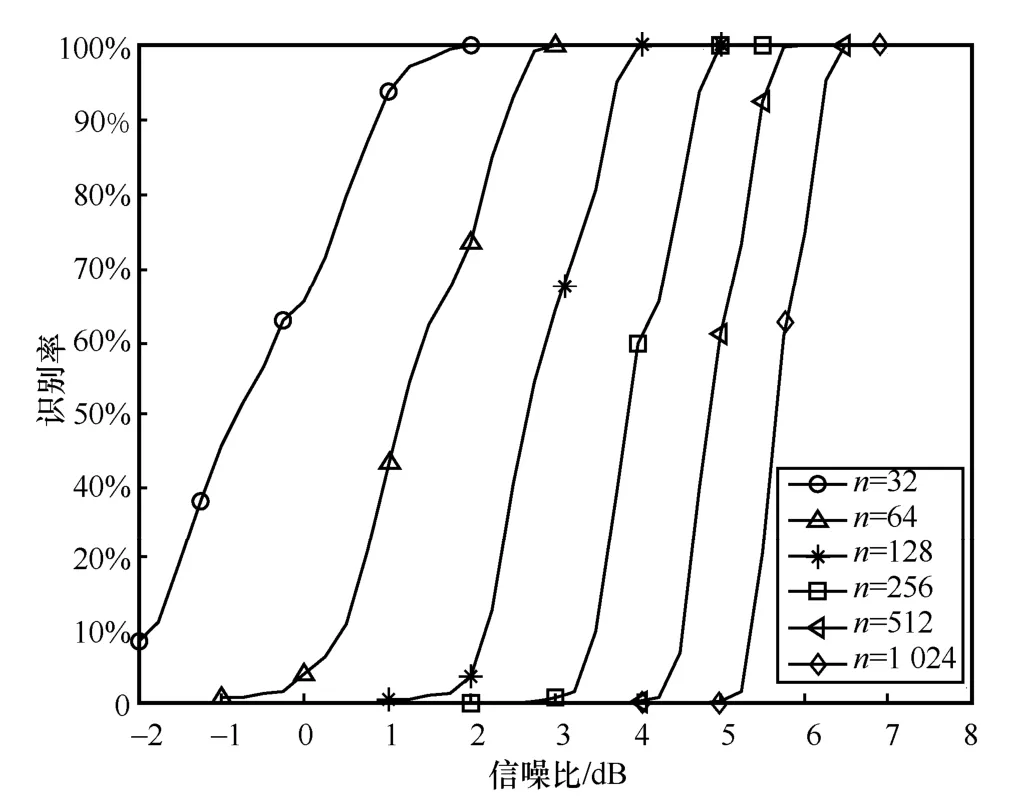
图4 不同码长对算法影响
从图4 结果来看,本文所提算法的性能随着码长的增加,性能逐渐变差,主要原因在于,在同一码率条件下,码长越长,需要准确识别的极化码的信息比特位置就越多,故在同等条件下,码长越长,出现对信息比特位置的误判概率就越大,故越难识别极化码参数。此外,从识别率来看,本文所提算法在信噪比为6.5 dB 条件下,对码长为1 024 的极化码参数识别率达到98%以上,这说明了算法具有较好的低信噪比稳健性。
2) 码字数目对算法影响
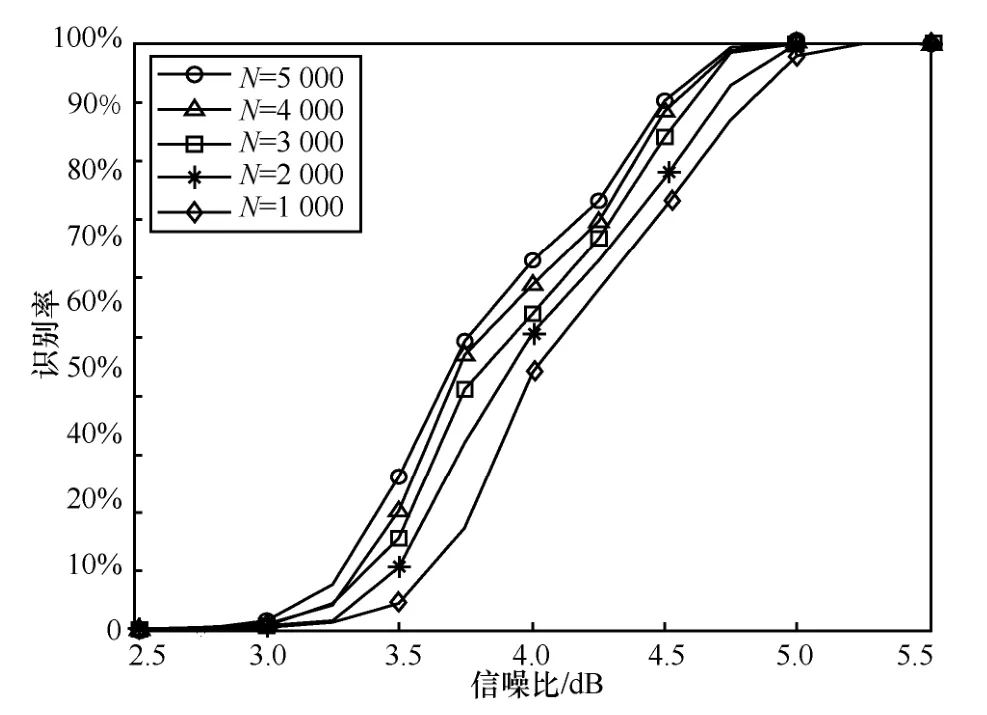
图5 不同码字数目对算法影响
从图5 结果来看,通过增加极化码码字个数,可以有效地提高参数识别正确率。主要原因在于,码字个数越大,求取的统计量就越近理论均值,此时对信息比特位置的误判概率就会减少,从而算法识别性能就增加了。
3) 码率对算法影响
仿真设定极化码码长为64 和128,每种码长下的极化码码率分别为设定截获的码字个数为2 000 个,蒙特卡罗实验次数为1 000 次,统计2 种码长在不同码率下极化码参数的正确识别率,结果如图6 所示。

图6 不同码率对算法的影响
从图6 结果来看,极化码参数识别概率与码率大小关系不大。主要原因在于,虽然码率增加,会导致信息比特位置的增加,但是在识别过程中,每种码率上的信息比特位置所对应的对偶向量码重却非常接近并且都比较小,即使码率增加,信息比特位置的误判率变化也不会太大,故在不同码率下,极化码识别非常接近。
4.3 与硬判决方法对比
为了突出采用软判决序列的优势,本节将采用了硬判决序列的算法进行对比。仿真设定极化码码长为64、128、256 及512,每种极化码码率为截获的码字个数为2 000,设定信噪比范围为0~7 dB,间隔0.25 dB 取值,蒙特卡罗实验次数为1 000,统计在2 种不同序列类型下,算法的识别性能,结果如图7 所示。

图7 与硬判决算法对比
从图7 结果来看,基于软判决序列的识别方法性能要明显好于基于硬判决的方法,软判决算法的性能提升近0.5 dB。主要原因在于,与硬判决序列相比,软判决序列包含丰富的信道噪声信息,而本文所提算法能够充分利用软判决序列,故其在低信噪比下的稳健性会更强。
5 结束语
基于极化码的编码结构,首先给出并证明了定理1 和定理2,即原始极化码具有最小的码率,同时所有具有最小码率的极化码码长中,原始极化码的码长最短;其次为了求解不同码长下极化码的码率、信息比特位及冻结比特位,给出并证明了定理3;然后为了在低信噪比情况下实现极化码信息比特位置参数识别,引入了LLR 概念,基于定理3 及LLR 的统计特性,设定出最优的信息比特位判决门限,从而在低信噪比下,快速识别出极化码编码参数。仿真结果验证了本文所提算法的有效性和较强的低信噪比下的容错性,在非合作通信领域具有较好的应用前景。
猜你喜欢
计算机应用(2022年9期)2022-09-25
现代财经-天津财经大学学报(2022年5期)2022-06-01
航天电子对抗(2022年2期)2022-05-24
电子测试(2022年4期)2022-03-17
北京航空航天大学学报(2021年9期)2021-11-02
科学技术创新(2021年2期)2021-01-21
航天电子对抗(2019年4期)2019-06-02
扬子江诗刊(2018年1期)2018-11-13
舰船电子对抗(2018年3期)2018-08-28
计算机应用(2018年7期)2018-08-27
