
应用于电力营销的数据分析模型*
2021-01-19 11:01:42夏泽举
计算机与数字工程 2020年12期
周 堃 韩 号 陈 伟 夏泽举
(国网安徽省电力有限公司 合肥 230022)
1 引言
电力公司在其配电网中部署大量智能电表后,需要有效管理不断生成的大量用电数据,并将这些海量用电数据解码为对电力营销有帮助且有意义的信息[1~2]。此外,随着智能电网技术的普及和电力市场的改革压力,电力公司面临从服务可靠性扩展到电力营销市场化的挑战。所有这些内外部因素促使电力公司需要更加敏感地感知用户地用电需求,并依据大数据挖掘所得出地有效信息进行更有针对性和个性化的用电需求响应[3~4]。定义和描述不同的低压用户群体不仅将为电力企业的决策者提供有助于定价和项目营销计划,而且有助于电力公司进行有效资源配置和项目开发。对客户用电行为进行更深入的建模和分析还可以帮助电力公司提前基础设施规划,提前做出用电需求响应。为此本文提出了面向电力营销的电力大数据分析模型。所提出的数据模型基于预处理的负荷形状字典,依据智能电表所采集地低压用户用电数据对用户的生活方式进行分类,以便电力公司实施更有针对性需求响应的电力营销计划。
2 问题陈述
本文重点研究如何通过客户用电数据开发可扩展的生活方式聚类方法,并通过真实数据集的聚类结果分析加以验证。为了解决这个问题,首先需要定义生活方式。然后提出了在聚类过程中使用的几种生活方式特征。图1为基于客户用电数据的生活方式的总体流程。图2给出了生活方式分段步骤的详细流程。

图1 基于用电数据的生活方式分段流程
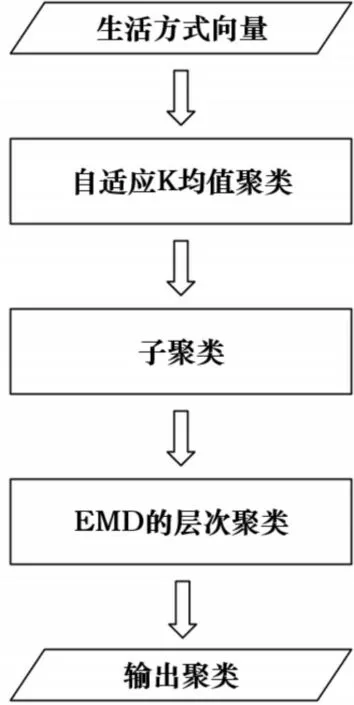
图2 两阶段聚类流程
2.1“生活方式”的定义
生活方式的字面含义是生活条件、行为和习惯的组合。从电力大数据挖掘的角度、生活方式可以看作是与家庭用电模式相关的特征向量[5~6]。本文将基于低压用户电力消耗的“生活方式”定义为给定生活方式特征的概率分布向量。为了生成这些向量,本文开发了一个生活方式函数LS():
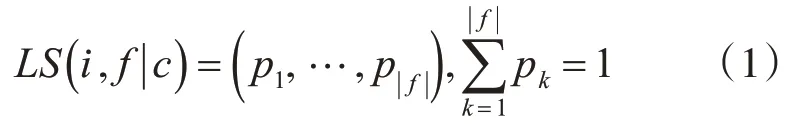
式1中 ||f表示特征维度。LS()的输入为用户i的用电数据和对生活方式特征(f)编码的字典。参数c表示对用户i用电数据的约束。LS()函数输出用户生活方式的向量(即给定生活方式特征的概率分布向量f)。例如,如果约束条件c是“周末”而f是用电模式,则LS()仅从周末的用电数据输出其用电模式的概率分布向量。
2.2 生活方式特征
基于用户电力消耗数据的生活方式特征维度有很多,如日总用电量、聚类用电模式的出现频率等[7]。从聚类计算的角度,如果生活方式特征的维度空间太大则很难聚类计算效率太低[8]。因此本文主要从以下三个维度进行生活方式特征的提取。
1)负载曲线:给定每日用电数据l(t)(小时间隔数据),将其分解为l(t)=a*s(t),其中
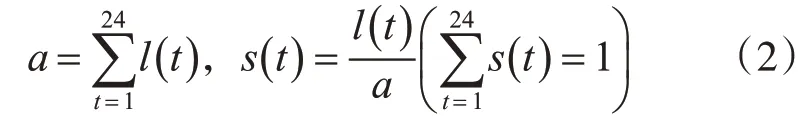
其中a是每日总用电量,s(t)是标准化负载曲线,即负载形状。为了兼顾负载形状的代表性质量和聚类计算负荷,本文创建大小为200的负载曲线字典用以负载曲线聚类。
2)负载曲线分段:该特征用以分析每日用电模式的高峰时间所在的位置。由此特征值可以知道用户何时积极地消耗电能,并估计用户在家的时间。根据高峰时间,负载曲线可分割为7个耗电高峰曲线段:早晨高峰(M:4:00-10:00)、白天高峰(D:10:00-16:00)、晚上高峰(E:16:00-22:00)、夜间高峰(N:0:00-4:00、22:00-24:00)、早晚双高峰(M&E)、晚间双高峰(E&N)、晚间日间双高峰(D&E)。因此,日常用电模式可以被编码为这七个负载形状段之一。
3)用电时段排名:基于负载曲线的合理解释,从上述的负载曲线分段编码中人工识别出用电峰值时段。该特征值能够识别出用电高峰时段,但无法粗略地捕捉一天中用电负载曲线形状的总体变化规律。因此,本文对高峰时段排名特征进行精简以较为概括地表征用电量变化。所提出的新地特征为用电曲线分段排名(RBU)。RBU使用一天中四个分区作为用电负载形状段:(M、D、E和N),因此RBU只有24种情况。如果早上的耗电量是最大的并且白天的耗电量是第二大的,则RBU值为“MDEN”。
为了使所得出地排名特征值对使用率相对较低的负载曲线段更加不敏感,可以通过忽略两个最低使用率负载形状来将RBU个数减少到12。如图3所示,三分之二的日常用电模式集中在两个负载曲线段中。如果将最小耗电提取为静态基本耗电,则四分之三的活跃耗电分段位于两个顶部负载曲线段中。因此,如果仅对两个顶部负载曲线段进行排序,则该特征值可以用以下12个编码表示:{MD、ME、MN、DM、DE、DN、EM、ED、EN、NM、ND、NE}。

图3 RBU值的经验分布
3 聚类方法
3.1 负载曲线字典约简
基于生活方式概率向量LS(i,f|c)对用户进行分割的最简单方法是使用具有适当距离度量的K-均值聚类[9]。通常,设置适当的K总是在聚类的简单性和代表性之间进行权衡。由于可以通过多种方式减少负载形状的数量,本文研究了多种选项以适当地减少字典大小同时最小化聚类代表性的缺失。假设可以允许10%的用电模式分配给最接近的负载形状,第一种聚类方法是使用前272个加载形状,因为90%的用电模式都分配给了它们。第二种聚类方法是在1000负载形状上进行如图2所示的两阶段聚类,以便在相同数量的负载形状下也能更少牺牲聚类准确度。第三种方法是对原始数据进行简单的K-均值设定K=272。在这三种方式中,本文选择使用第二种方法,原因如图4所示。
如图4所示,两阶段聚类和K-均值聚类的阈值分布基本相似,但是两阶段聚类可以通过相同数量的负载曲线分段能够表示更多的用电模式[10]。例如,对于200个负载形状,两阶段聚类可以覆盖总用电模式的82%,而经典的K-均值聚类仅覆盖45%。因此,两阶段聚类方法实现了更加简单的分割,同时保留了较好的聚类代表性。
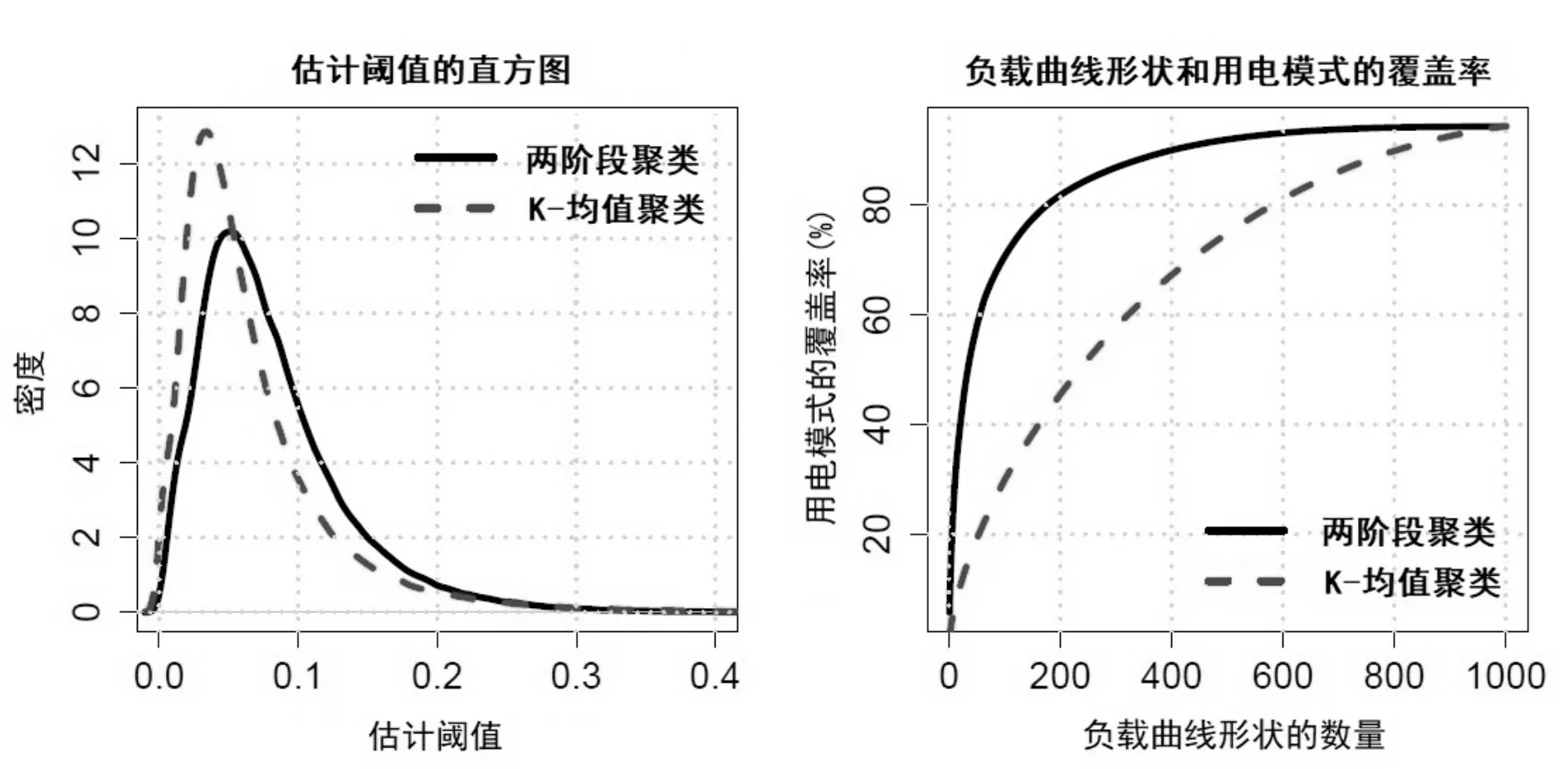
图4 两阶段聚类和K-均值聚类之间的比较
其中聚类代表性表示分配的负载曲线段与实际负载模式的接近程度。该数值可以通过估计的阈值来测量[11]。估计阈值的定义是[12]:

其中s(t)是归一化负载分布,CS是s(t)最接近的负载曲线段。由于该阈值表示地是与指定的聚类中心的相对距离,因此更好的聚类在中心数量相同的情况下具有较小的值。
图5指出了对各种减少的字典大小N的聚类错误率。如所预期的,较大的字典可以具有较低的错误率。但是,为了更好的可解释性,本文将字典大小设定为200,此时聚类错误率为10%。

图5 负载形状字典大小和聚类错误率的关系曲线
3.2 具有余弦距离的自适应K-均值算法
基于“生活方式”函数的输出,K-均值聚类可以用一个适当的距离度量来划分用户。考虑到某些生活方式特征的字典中的每个元素都可以表示为唯一的代码,余弦距离可以作为距离度量。具有余弦相似性的K-均值算法是高维文本聚类中常用的方法,特别是在比较两种不同的概率分布向量时。与其他距离测度相比,余弦距离测度的优点是对称的,便于实现,计算速度快,适用于K-均值算法[13]。余弦距离的定义是[14]:

为了找到满足每个聚类组内某个统计特性的适当K,本文使用基于式(5)中的阈值条件的自适应K-均值。
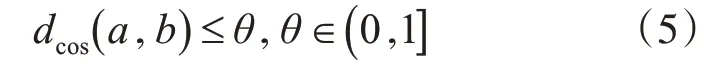
3.3 两个生活方式向量之间的EMD
假设在所有用户的生活方式向量上应用自适应k-均值后存在聚类群组。如果给定的生活方式特性的维度很高,那么集群组的数量仍然可能太大而无法解释。之前对生活方式向量的聚类方法只考虑了两个概率分布向量之间的相似性,没有考虑实际负载形状之间的距离。因此,考虑到负载形状之间的实际距离,按负载曲线的聚类组可以再聚类一次[15]。
两个负荷曲线之间的距离被定义为EMD。对于两种不同的负载形状,第i个负载形状si(t)和第j个负载形状sj(t),本文定义EMD距离度量d(si(t);sj(t))如下:
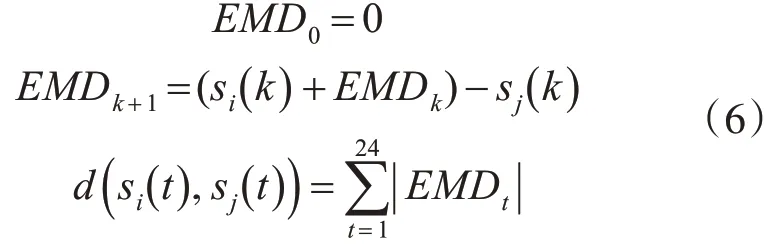
此外,各种负载曲线的距离矩阵M(200×200)可以表述如下:
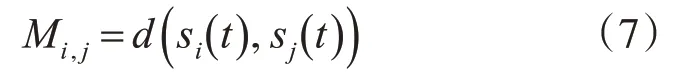
然后,必须定义两个子集群之间的距离度量(通过自适应K-均值获得)。如果将子集群的中心视为客户的生活方式向量,这实际上与定义两个客户的生活方式向量之间的另一个距离度量相同。为了在如式6所示的不同的负载曲线中考虑实际成本,两个生活方式向量之间的新距离被定义为另一种EMD,这是将一个用户的负载曲线分布概率转换成另一个用户的负载曲线分布概率的最小成本[16]。
当负载曲线用作生活方式特征时,将两个生活方式向量表示为a={a1,…,a200},b={b1,…,b200}。然后,通过求解式(8)中的线性规划(LP)问题,可以获得最小成本dmov(a,b)。式(8)中X是转移矩阵,Xi,j表示一个用户的第i个负载曲线与另一个用户的第j个负载曲线匹配的概率。dmov(a,b)的解释是每天平均将生活方式a转换为生活方式b需要多少用电成本。
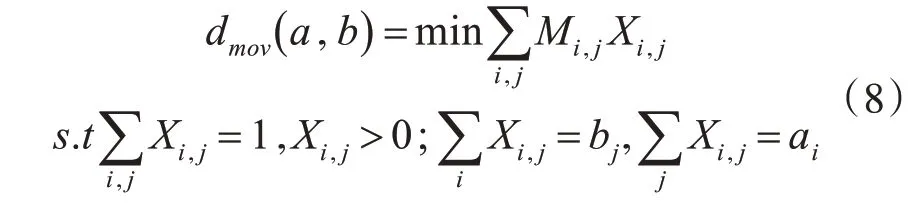
当聚类群组的数量太高而不能解释时,可以进行另一个聚类计算以适当的距离度量重新对群组重新聚类。如前述,EMD(dmov(a,b))被提出作为使用负载曲线形状作为生活方式特征时两个不同子集群之间的新的距离度量。为了保证同一集群中任意两个子集群中心之间距离不超过一定水平,选择具有完全链接的分层聚类算法作为聚类算法。
4 数据研究
4.1 数据准备
本研究所使用的智能电表数据由国家电网公司提供。智能电表218090台,每日负荷总数为66434179台。这些数据对应于不同的邮政编码,覆盖了8个不同的气候区域。数据记录时间从2017年8月到2018年7月。本文所研究的区间用电数据时间间隔为1h,如果数据的分辨率的不同可能导致聚类方法的改变。例如,如果有15min或1min的间隔数据,则负载曲线形状聚类和降维方法就需要改变。
4.2 负载曲线的分段
如前所述,负载形状字典的大小从1000减少到200。基于由该负载曲线形状字典的编码计算生活方式向量。然后使用具有余弦距离的自适应K-均值算法对客户进行聚类。式(5)中的θ被设置为0.4,因为图6显示了解释能力的边际增益很小,但是在较低的阈值下需要大量的聚类中心。

图6 各种阈值下(θ)的聚类数量
由图6可知,θ=0.4时有1,268个聚类中心。通过考虑不同负载曲线形状之间的实际距离来完成基于EMD的分层聚类以减少聚类中心的数量。
图7显示了不同分割高度的聚类群组的数量。为了最大限度地提高聚类群组的可解释性,本文选择在高度为1.4的情况下进行两阶段聚类,从而产生具有1,268个子聚类中心的24个聚类中心。这保证了在任何一个聚类群组中,任何子中心的生活方式都可以与另一个集群中心生活方式基本相同。分割高度1.4意味着对于两个生活方式相似的用户,如果其中一个用户的负载曲线形状转变成另外一个用户的负载曲线形状,改变平均每天用电量的10%则需要14h(或改变平均每天用电量20%则需要7h)。举个简单的例子,如果一个日常用电量约为18kWh的用户从早上8点到晚上10点改变它的10min淋浴(需耗电1.8kWh),那么其时间成本是14h。

图7 具有不同分割高度的聚类数量
图8显示了前10个生活方式群组的每个中间子群组中心的四个频繁负载曲线形状(覆盖95%用户),假设每个中间子群组代表相应的群组。基于式(8)中定义的EMD获得了子群组。如果从一个子群组到同一群组内的其他子群组的EMD的总和是所有子群组的EMD总和中的最小值,则该子集群是中间子群组。

图8 十大生活方式集群中的中间子集群中的四种频繁负载形状
从图8中可以清楚地看到,负载曲线形状的频繁集依据目标生活方式集群而不同。例如,代表集群1(最大集群)的所有四个频繁负载形状都具有傍晚峰值。集群2、集群3和集群4的每个代表具有两个频繁的傍晚峰值和两个频繁的双峰值负载形状,尽管比例和峰值定时不同。在集群2的代表中,最频繁的负载形状是早晨和傍晚的双峰,而在集群3的代表中,它是白天和傍晚的双峰。
在第5组的代表中,所有四种频繁负载形状都具有晚上峰值,这与集群1的代表中的负载形状不同:晚上的功耗部分较高而峰值在晚上。集群6和10的代表具有“U”型频繁负载形状,并且它们的两个频繁负载形状实际上是相同的。
集群7的代表具有频繁的负载形状和不同的峰值时间。集群8的代表具有频繁的负载形状,傍晚峰值和双峰出现在清晨和傍晚。集群9的代表有夜间峰值和夜间峰值。综上所述,图9表明,当使用上述两阶段聚类方法时,频繁负荷形态峰值时间的差异和这些负荷形态所占比例的差异是区分生活方式最重要的因素。
如果将生活方式细分结果与其他特征(例如:日均消费、消费模式的差异性)联系起来,就可以对特定的生活方式群体做出有趣的解释。图9为忽略过小的生活方式集群(大小<10)后,19个生活方式集群(24个生活方式集群)的客户日均消费和差异性散点图。圆圈的面积与每个生活方式组的大小成比例。如图所示,由于平均统计量分布在各个集群上,所以大多数集群都是可区分的,这意味着按负载形状划分的生活方式组在这两个特征上的分布是不同的:平均日消耗量和差异性。
从图9中可以看出,集群6、集群10、集群17的耗电量相对较轻,熵值较低,其主导荷载形状均为“U”形。根据这些事实,我们可以推测这些家庭用户可能是一个经常在白天工作的人。同时,从图9中可以看出,考虑到整个客户的平均熵为5.2,集群11、集群12、集群13、集群14消耗较大,熵值相对较低。
从图11中可以看出,集群11具有早高峰,集群12具有早高峰,集群13、集群14具有昼高峰。考虑到这些家庭用户大量耗电,可以推测这些家庭用户可能安装了大功率的空调系统。

图9 集群中心11~14的中间子集群中的四种频繁负载形状
总之,峰值时间和负载曲线形状的比例对于区分用户生活方式非常重要。通过与其他特征的关系,生活方式的分段可以提供合理的推测。如果任何调查数据或与来自相关生活方式组的抽样客户的通信能够证实这些猜想,那么这些可能是设计电力营销计划的重要因素。
上述消耗模式差异性是指式(9)中的负载形状熵。
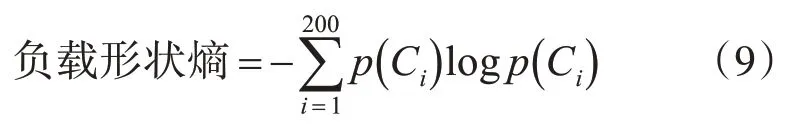
其中p(Ci)是用户日常耗电量中每个负载曲线形状代码Ci的相对频率。如果所有负载形状代码在数据集中具有相同的可能性,则熵最高;如果用户总是具有单个负载形状,则熵最低。
4.3 具有负载形状段的分段
图10的左图显示了各种阈值的集群数。通过应用于图7的相同推理,自适应K-均值的阈值被设置为0.4。图10的右图示出了在通过分层聚类将集群的数量从78减少到22之后的前8个集群的集群中心(覆盖95%)。如图10所示,可以通过一个或两个主要负载形状段容易地区分集群。因此,考虑到特征的维度仅为7,通过其最频繁的负载形状段来分割客户可以是简单且更可解释的集群。

图10 基于负载形状段的自适应K-均值结果
表1提供了基于总用电量分布的关于每个负载曲线分段聚类群组的实际比例、平均每日耗电量和平均负载形状熵的信息。如表1所示,大多数家庭用户都负荷晚间高峰值群组,晚间高峰值段约占所有用电模式的40%。
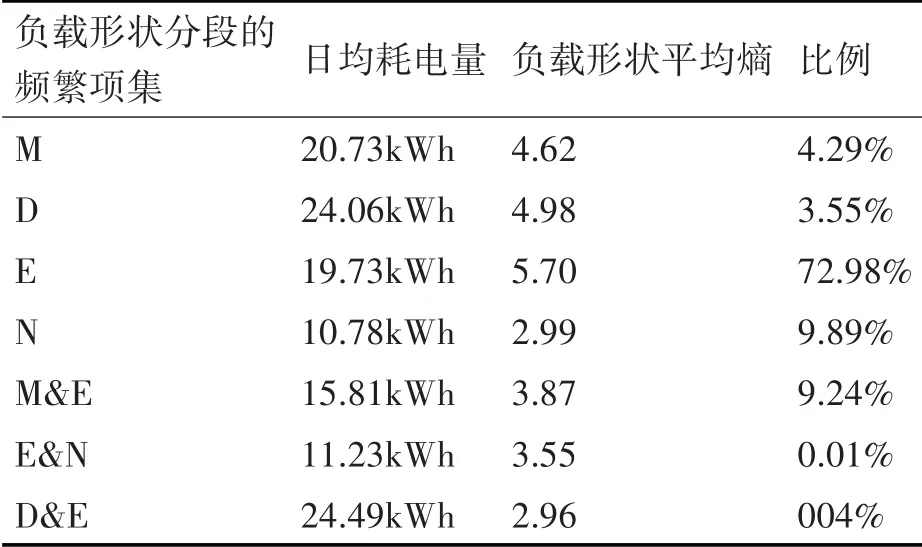
表1 图10中的住户用电统计数据
由表1可以看到白天高峰组和日间和晚间双峰组的日均耗电量很大。如果一个家庭用户主要在白天有高峰用电时间表明该家庭用户在白天在家里有活跃的用电行为。夜间高峰值群组和白天和夜间双峰群组的平均负载形状熵较低。夜间高峰值群组的用电统计量与中低熵组的用电统计量相匹配,其负载曲线形状以“U”为主,用电高峰通常出现在夜间。
4.4 使用RBU对负载曲线分段进行排名
使用RBU以便更容易地比较两个分割结果。图11的左图示出了在各种阈值处的聚类群组数量,其中自适应K-均值的阈值被设置为0.3。右图显示了通过层次聚类将聚类数量从99减少到22之后前8个聚类的聚类中心(覆盖95%)。如图11所示,可以通过一个或两个主导RBU容易地区分集群。考虑到RBU的维度仅为12,本文按照上一节中的最频繁RBU对用户负载曲线进行分段。

图11 基于RBU的自适应K-均值结果
表2列出了基于总分布的关于每个分段组的实际比例,平均每日消耗和平均负载形状熵的信息。如表中所示,M、MN、DM组的消耗量很大,平均负荷形状熵很低(总户数平均熵值为5.19)。如果一个家庭主要在早晨和白天消耗电力,这可能再次暗示家庭是一个家庭住户,其中在早晨和白天在家中进行活动,如白天高峰组的情况。因此,如果某个能源计划要求客户具有稳定的大量消费,则MD、MN、DM组可以是良好的候选者。NM组具有最低负载形状平均熵,其负载曲线形状以“U”为主,用电高峰主要发生在夜间和早晨。
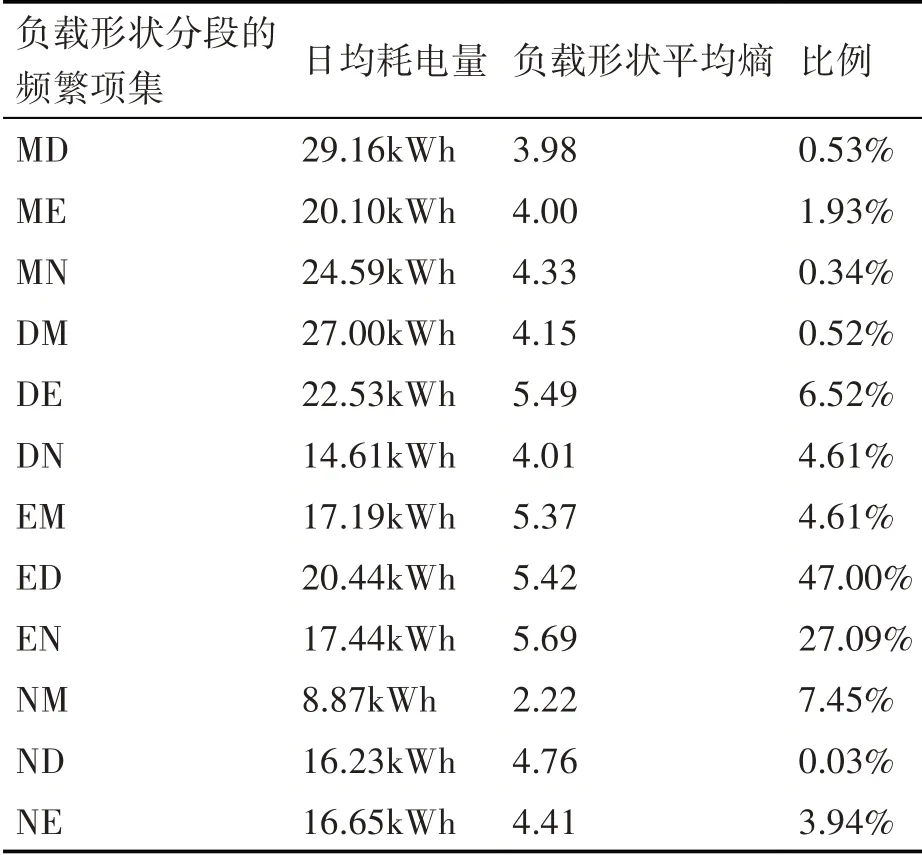
表2 图11中的住户统计数据
5 结语
本文提出了一种基于客户用电模式的生活方式细分需求管理方法。基于所提出的相关的生活方式特征对用电数据进行了聚类分析。该分析方法首先通过预处理的负载形状字典从编码数据中快速提取生活方式特征。其次,在最复杂的负载曲线分段情况下采用快速近似算法的两步聚类来计算两个子聚类之间的EMD距离。通过实验表明所提出的数据分析模型能够识别用户的用电模式及其所代表的生活方式,这为制定针对性的电力营销提供了有效的量化数据支撑。
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25 07:43:16
今日农业(2021年8期)2021-07-28 05:56:04
书香两岸(2020年3期)2020-06-29 12:33:45
新世纪智能(英语备考)(2018年11期)2018-12-29 10:56:52
电子测试(2018年14期)2018-09-26 06:04:10
小学生学习指导(低年级)(2016年10期)2016-12-01 06:10:42
卫星与网络(2016年12期)2016-02-05 09:23:22
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:42
计算机工程与设计(2011年7期)2011-09-07 10:16:54
中学生英语·中考指导版(2008年6期)2008-12-19 05:28:48
