
基于模拟退火算法改进的大脑情感学习模型*
2021-01-19 11:01潘建国
计算机与数字工程 2020年12期
唐 詹 潘建国
(上海师范大学信息与机电工程学院 上海 201400)
1 引言
数据分类技术是数据挖掘领域中最重要的技术之一,迄今为止已有大量的数据分类算法被相继提出,包括朴素贝叶斯、决策树、Logistic回归以及BP神经网络等方法[1]。然而,随着数据复杂度的增加,尤其对于维度较高的数据,传统分类方法已难以满足对不同类型数据进行快速、准确分类的要求[2]。
大脑情感学习(Brain Emotional Learning,BEL)模型是一种模拟人类情感反应的神经网络模型,于2001年由瑞典隆德大学的Moren[3]提出,其计算复杂度较低,运算速度快,可以克服传统神经网络训练时间长的缺点,在自动控制和模式识别中有着较为广泛的应用[4~5],在无人机姿态控制中也有一定应用[6],近年来也开始应用于分类和预测问题[7]。
Lotfi等[8]率先提出将遗传算法(Genetic Algorithm,GA)应用于BEL模型的训练,替代原始的简单训练算法,取得了较为理想的实验结果,遗传算法开始成为训练BEL模型的一种重要手段,也展现了BEL模型在分类问题上的优秀能力。
Sharafi等[9]提出了一种基于区间知识改进的BEL模型的方法,该方法利用区间知识来改变BEL模型杏仁体和眶额皮质的权值,在混沌时间序列预测问题上取得了良好的效果。
Muhammad等[10]结合模糊神经网络对BEL模型做出改进并应用于模式识别和分类问题中,其分类准确性有了进一步的提高,但局部最优问题仍然制约着训练速度,且分类准确率不够理想,其对噪声的敏感性也不适用于物联网数据分类。而Javadi B等[11]基于大脑情感学习和模糊推理系统的融合算法,对脑电图频谱图像进行分类,取得了较高的正确率,由于从图像中提取的纹理特征产生了巨大的矩阵数据,还使用了局部线性嵌入算法(LLA)来减少大矩阵,以降低输入维度。
梅英等[12]提出GA-BEL模型,采用遗传算法代替奖励信号的作用对BEL网络权值进行优化调整,将BEL网络权值分布在染色体基因序列上,用适应度函数评估网络输出,选出最优染色体,经过解码后得到最优的网络权值。该方法在低维数据样本上的表现已全面超越BP神经网络等传统方法,但在高维度数据上表现不佳。
由于BEL模型的特点,数据维度增加,整个模型也随之变得更复杂,局部最优问题使得模型的分类准确率下降。为进一步提高BEL模型在高维度数据样本上的分类识别能力,本文提出了一种用模拟退火算法来改进BEL模型学习过程的方法。模拟退火算法是以一定的概率来接受当前状态的非最优解,赋予搜索过程一种时变且最终趋于零的概率突跳性,从而可有效避免陷入局部极小并最终趋于全局最优。用模拟退火算法改进BEL模型的学习过程,能一定程度上避免因维度增加、神经元增多带来的局部最优问题。
2 相关理论
2.1 BEL模型
情感是人类大脑的一种特殊能力,它使人类能更好地适应外界环境。假如遭遇对本体有利的外部刺激,能产生积极愉悦的情感,会对造成这种刺激的事物产生更多关注,反之会产生消极、厌恶的情绪,对造成这种刺激的事物失去关注或者避而远之。而且人脑会对相应的刺激产生记忆,受到同样刺激的时候会加强记忆,并对相同或相近的刺激产生对应情绪[13]。
这些过程主要是通过大脑内部的杏仁体、眶额皮质等器官实现的。BEL模型就是模拟人脑中的杏仁体和眶额皮质之间的信息传递而建立的神经网络模型,主要由丘脑、感官皮质、眶额皮质、杏仁体四个部分组成,如图1所示。
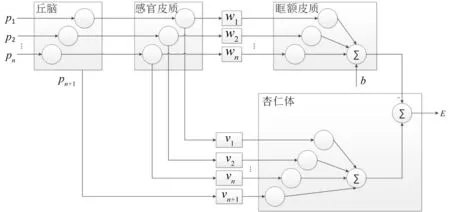
图1 BEL神经网络模型
对于每个感官输入p,眶额皮质以及杏仁体中都有相应的节点来处理。设共n个感官输入,各个感官输入值为p=[p1,p2,…,pn],丘脑输出最大刺激pn+1即感官输入的最大值:

设杏仁体的权值为v,杏仁体的单个输出Ai为权值乘上感官输入及丘脑输出Ath:
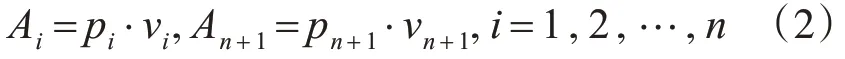
杏仁体的总输出为A=Ai=Ai+A n+1。
设眶额皮质的权值为w,眶额皮质的单个输出Oi为权值乘上感官输入:

设眶额皮质的偏置值为b,则眶额皮质的总输出为O=Oi+b。
BEL模型的最终输出为

2.2 BEL模型的训练算法
近年来的研究常常使用遗传算法来完成BEL模型的训练,在分类问题上能取得较好的效果。遗传算法是一种优化算法,包括选择、交叉、变异等操作,计算出最优个体来优化适应度函数。将权值及偏置值编码成染色体:

适应度函数定义为

Ek为BEL模型对第k个输入样本的输出值,Tk为第k个样本的目标输出值,n为样本总数,此适应度函数用来衡量BEL模型对所有训练样本的输出误差,优化目标为最小化适应度函数(此时通常也称适应度函数为成本函数)。
2.3 模拟退火算法
模拟退火算法是解决局部最优问题的一个有效方法,它的基本思想是以一定的概率接受某个状态的非最优解,增加“爬山”能力,接受的概率随着算法的进行逐渐减小,符合Metropolis准则[14]。通过以概率作为接受新状态的方法,可以有效避免搜索陷入局部最优的问题,提高寻优能力。设当前状态为x,其能量为e(x),温度为T,则接受修改的概率P(x)满足:

上式中K为波耳兹曼常数。
降低温度的方式有许多种,为了提高模拟退火算法的性能,有以下三种退火方式最为常用:

式(8)~(10)中t表示模拟退火阶段的迭代次数,a表示可调参数,T0表示初始温度。式(8)的特点是温度下降缓慢,算法的收敛速度慢;式(9)的特点是高温区时温度下降较快,低温区时温度下降较慢;式(10)的特点是温度下降快,算法的收敛速度快。
3 模型的改进方案
3.1 对网络结构的改进
为了提高拟合能力,发挥模拟退火算法的优势,给眶额皮质每个节点都增加一个偏置值,进一步复杂化网络,如图2所示。

图2 改进的网络结构
眶额皮质的单个输出Oi变为权值乘上感官输入加上偏置值:
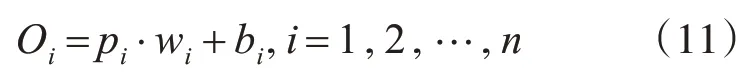
眶额皮质的总输出为O=Oi。
BEL模型的最终输出为
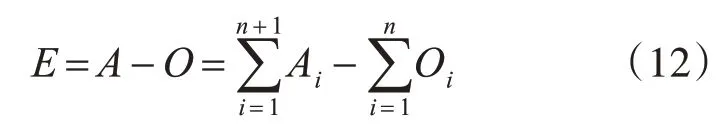
这样的改进使得偏置值的个数随着数据集特征维度的增加而增加,进一步提高了模型的学习能力,使其拟合能力增强,同时偏置值个数的增加也使得染色体编码更为复杂,为遗传算法引入了更多的随机因素,配合模拟退火算法改进变异过程,改善局部搜索能力,提升模型性能。
3.2 对训练过程的改进
遗传算法应用模拟退火的方式有很多种,一种是只应用模拟退火的思想,在遗传算法运行到后期适应度趋于一致的时候对适应度进行适当的拉伸,放大适应度的选择作用,使遗传算法的选择具备更强的择优能力。另外一种是用模拟退火算法改进遗传算法中新个体的产生方式,比如将退火过程作用于交叉、变异或者新个体的保留过程上,允许当前不优解的存在,提高局部搜索“爬山”能力,可以一定程度上避免早熟的出现。针对遗传算法的主要缺点,本文采用模拟退火算法对交叉和变异过程进行改进,使不能优化适应度的变异个体也有一定概率得到保留,保留的概率随着训练过程的进行而下降。用这种方式对模型进行训练,有助于提高模型的分类准确率。具体改进描述如下。
1)编码:传统遗传算法采用二进制编码法,但BEL模型中的权值及偏置值均为实数,而二级制数转换为实数存在着误差,所以采用实数编码法,染色体编码形式为

2)选择:采用轮盘赌与最优个体保留相结合的方法,父代中的最优个体被保留到子代参与竞争,保证最优个体始终参与遗传操作,提高算法的搜索速度。
3)交叉:采用多点位单基因交叉方式,采用Srinvivas提出的自适应方法[15],自适应地更改交叉概率。交叉完成之后计算交叉生成子代的适应度,若子代适应度更小,则用子代进行替换,否则按一定概率决定是否替换,且此概率逐渐减小。
4)变异:用模拟退火思想改进传统变异方式,计算变异后新的适应度与变异前适应度的差值,若变异后适应度更小,则接受变异;若变异后适应度变大,则按一定概率接受变异,且接受的概率逐渐减小。
算法程序流程图如图3所示。

图3 程序流程图
首先根据输入数据样本的特征维度用随机值作为初始权值及初始偏置值来初始化BEL模型,并设置模拟退火的初始温度,然后把眶额皮质和杏仁体的权值以及偏置值以实数方式编码为染色体作为初始种群。用遗传算法进行训练,适应度函数仍定义为式(6),根据适应度的计算进行选择、交叉、变异等操作,交叉和变异时引入模拟退火算法,以适应度函数值作为能量计算接受概率,若向有利方向改变,则接受这次改变,若没有向有利方向改变,则按Metropolis准则即式(7)的概率接受这次改变;然后降低温度对权值及偏置值做新一轮的修改,直到找到最优个体或达到停止条件,停止条件达到最大迭代次数或者适应度函数值停止改变。
4 实验分析
实验中采用Intel酷睿i5-7200U处理器,主频2.5GHz,8G内存,Windows 7操作系统,Matlab 2012a编程环境。选取UCI上6组数据集进行实验:Glass、Ionosphere、Iris、Wine、Sonar、Vehicle。数据集信息如表1所示。
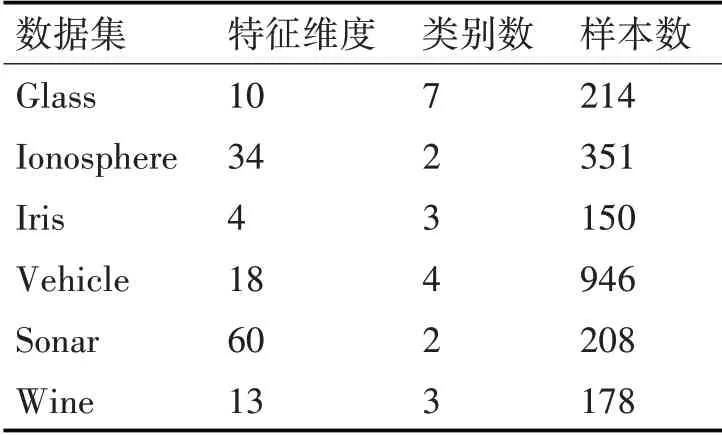
表1 数据集信息
将70%的数据样本划分为训练集,30%的数据样本划分为测试集,对比BP神经网络、支持向量机(SVM),目前表现最佳的GA-BEL模型及本文模型的分类结果准确率。因所用的样本数据集中并不存在正负类样本极度不平衡的情况,所以只对准确率进行对比。每项准确率的得出方式为重复实验20次取平均值。准确率的实验结果如表2所示,准确率单位为百分数(%)。
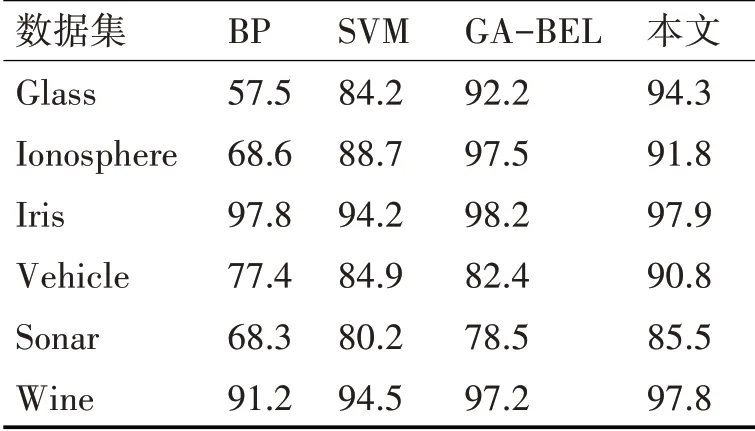
表2 准确率实验结果
实验结果表明,本文模型在高维度数据集Ionosphere、Sonar尤其是Vehicle数据集上准确率有较大提升,说明其对高维度数据样本具有较强的拟合能力。
5 结语
本文提出一种基于模拟退火算法改进的BEL模型,使用模拟退火算法改进BEL神经网络模型的训练过程,改善因数据特征维度变高,模型变得复杂而带来的局部最优问题。通过UCI数据集的实验验证得知,采用该方法能在高维数据集上取得较高的分类准确率,具有很好的应用价值。由于模拟退火算法的计算量大,训练时间仍然较长,因此下一步的工作将对模拟退火算法的计算过程进行优化,进一步提高模型的训练效率。
猜你喜欢
智能计算机与应用(2022年9期)2022-09-28
汽车实用技术(2022年15期)2022-08-19
成都信息工程大学学报(2022年3期)2022-07-21
中国信息化(2022年5期)2022-06-13
汽车实用技术(2022年10期)2022-06-09
北京汽车(2021年1期)2021-03-04
软件(2017年7期)2018-01-24
软件(2016年3期)2016-05-16
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
