
基于内容推荐与时间函数结合的新闻推荐算法*
2021-01-19 11:01翁海瑞何立健
计算机与数字工程 2020年12期
翁海瑞 林 穗 何立健
(广东工业大学计算机学院 广州 510006)
1 引言
随着电子设备和通信系统的发展,在线的信息源不断的增长,互联网的快速发展在给我们生活带来便捷的同时也带来了“信息过载”问题。为了解决“信息过载”问题,让我们可以轻松获取有价值的信息,推荐系统[1]在很多大型互联网企业得到了广泛应用,例如:购物(如亚马逊)[2],音乐(如网易云音乐)和电影(如Netflix)[3]。相对于搜素引擎来说,推荐系统无需人工搜索就可以把信息推送给特定的客户,一般通过计算用户-项目的相似度来实现。在新闻领域,人们的阅读习惯越来越碎片化。如何能有效地过滤信息,帮助用户找到感兴趣的文章给新闻研究者带来了巨大的挑战。
结合新闻文章属性和用户的兴趣偏好进行匹配推荐是新闻推荐的常用方法[4~5]。通过兴趣相似的用户推荐新闻,可以很好地捕捉用户潜在兴趣[6]。当用户没有足够的浏览记录和用户数量时,会导致用户和项目的冷启动问题。文献[7]提出基于显示语义分析感知的个性化推荐方法。研究者基于内容推荐和协同过滤推荐提出了混合推荐模型[8~9],文献[10]对混合推荐模型进行了改进,在融合协同过滤推荐和基于内容推荐基础上,使用了用户模型的最近邻算法。虽然国内外研究已经取得了一定的进展[11~18],但是个性化的新闻推荐[19~20]仍然是一个具有挑战性的问题。首先,在许多新闻推荐系统中,基于用户的个人历史资料是片面的,没有很好评估用户对历史新闻的偏好程度。另外,新闻与许多领域不同,随着时间的推移,新闻文章的受欢迎程度和用户兴趣的时效性变化很快,传统的推荐方法没有考虑时间对用户兴趣变化的影响。
基于以上研究,本文提出了:
1)通过新闻关键字、新闻主题和命名实体来构建新闻文本模型和用户兴趣模型。
2)通过引入时间函数来调整短期用户兴趣和长期用户兴趣的权重。
以上两者结合起来有助于我们对用户实时兴趣偏好更客观、更全面地进行建模。
2 新闻推荐系统框架
本文推荐系统框架由3个模块组成:用户模块、新闻模块和推荐算法模块,如图1所示。
1)用户模块:收集和处理用户的基本注册信息(地址,性别,年龄等);以及用户的行为数据(订阅,转发,收藏等)。
2)新闻数据模块:通过与新闻内容进行中文分词和标注处理,可以实现关键词,命名实体,主题抽取等功能。
3)推荐算法模块:当前流行的三种推荐算法是基于内容推荐算法,基于协同过滤算法,混合推荐算法。本文框架使用基于内容推荐与时间函数相结合的算法。

图1 新闻推荐系统框架
3 新闻文本模型构建
新闻文本模型构建主要从三个方面进行。首先,通过语义分析系统(NLPIR)对每一条新闻得到分词结果,然后利用TF-IDF(term frequency-inverse document frequency)算法构建一个新闻关键词的向量空间模型,提取新闻的命名实体。并且通过文档主题生成模型(Latent Dirichlet Allocation,LDA)得到新闻的主题类别,新闻文本向量表示V n={F n,E n,G n}。其中,F n表示为新闻文本关键字向量,E n表示为新闻文本命名实体的向量,G n为新闻文本主题向量。
3.1 提取新闻文本关键字
新闻文本关键字序列主要以向量空间模型表示,通过TF-IDF加权来对关键字的提取以及关键的权值计算。关键字向量可表示为

其中:f i表示新闻第i个关键字,wi为关键字对应的权值。
使用TF—IDF公式计算关键字的权值。公式如下:
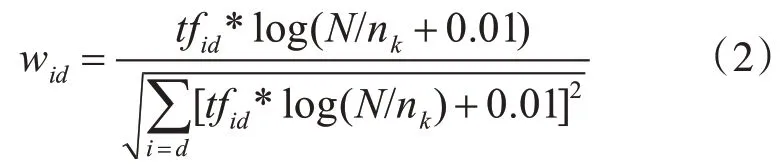
其中:wid表示第i个关键字在文本d上的权重,tf id是第i个关键字在文本d上出现的频率,N表示新闻文本的篇数,n k表示关键词k的文本数量。
3.2 新闻文本命名实体提取
很多时候浏览者会倾向阅读有命名实体(含人命、地名、时间)的文章,所以需要把命名实体也考虑到新闻文本模型构建中。通过汉语言处理包(Han Language Procession,HanLP)获取新闻命名实体。命名实体向量为
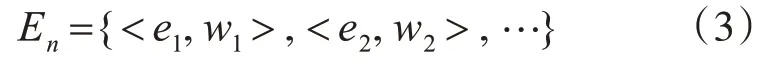
其中:ei表示新闻第i个命名实体,wi为对应命名实体的权值。
3.3 新闻文本主题类别
读者一般会对主题类别相似的新闻感兴趣,所以需要我们进一步分析主题的类别,可以使用LDA作为语言模型来检测潜在的主题,并对每条新闻的主题类别提取进行建模。新闻主题分布向量:

其中,g i表示新闻第i个主题,wi为对应主题的权值。
4 用户兴趣模型构建
为了更好地了解读者的阅读偏好,在新闻文本模型基础上构建用户兴趣模型是非常重要的。传统的方法是通过跟踪用户阅读的文章,通过关键字或者主题来构建用户兴趣模型,此类模型并不能很准确地获取用户的阅读兴趣。一方面,此方法容易出现过拟合现象,仅仅通过关键字来构建,不能在没有相同关键字的情况下有效的推荐新闻。另外一方面,此方法不能突出命名实体的重要性,很多用户对命名实体更感兴趣。所以我们从三个不同但相关的方面来构建用户兴趣模型:新闻关键字、命名实体、新闻主题分布。用户兴趣模型表示为式(5),其中式(6),式(7)和式(8)分别为用户访问的历史新闻关键字、命名实体和主题分布向量。

其中:f i表示过去访问的新闻历史的关键字,wi为该关键字相应的权值。

其中:e u表示过去访问的新闻历史的命名实体,wi表示相应的权值。

其中:gi表示过去访问的新闻历史的主题分布,wi表示为该主题相应的权值。
5 用户对新闻的实时兴趣度
新闻推荐系统时隔一段时间会将历史的新闻数据来更新语料库,给定的t j时间段,新闻文本向量为V nt j={F nt j,E nt j,G nt j},用户兴趣表示为向量V ut j={F u t j,Eut j,Gut j},用户对新闻的兴趣度Ht j通过进行匹配度计算。

其中,系统参数α,β,λ是用来调节系统相似度的比例。
随着时间的推移,人们的兴趣也在改变。在电影,音乐领域,用户的偏好在短时间内表现出轻微的差异,但在新闻领域,用户兴趣往往会随着环境,心情和新闻的热度变化。兴趣的实时性要从用户长期兴趣和短期兴趣两方面结合考虑,因为用户最近对新闻的浏览、评论和转发反映了用户最近的兴趣点。本文定义一个时间单调递减函数f(t)来描述随着时间的推移用户兴趣向量权重的递减。

其中,系数k主要用来调整陡峭情况。
所以,结合内容推荐和时间函数,得到目标函数,即用户对新闻实时兴趣度,可定义为H u:

其中,H t1,H t2,H tn分别为第1,第2,第n时间段的用户对新闻的兴趣度,f(t1),f(t2),f(t n)分别为第1,第2,第n时间段的时间函数,用来调整相应时间段用户对新闻兴趣度的权重。
6 实验与结果分析
6.1 实验数据集
本实验的数据集主要从各大新闻门户爬取的文章。主要包括5000个用户在2017年6月期间浏览的54123条浏览记录,共分为体育、财经、科技、游戏、汽车、娱乐等11大类。
6.2 评价指标
为了从推荐性能角度对用户的兴趣进行评估。选用了准确率precision,召回率recall,F1-Measure作为评价指标。与传统推荐算法进行了对比实验和分析。
1)准确率:
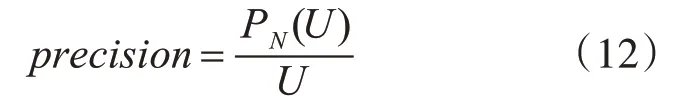
式中,P N(U)推荐给用户并被用户浏览的新闻数目,U推荐给用户的新闻总数目。
2)召回率:

式中,P N(U)表示推荐给用户并被用户浏览的新闻数目P(U)表示所有阅读的新闻总数目。
3)为了综合权衡这2个指标,引入新的指标F1-Measure。

6.3 对比实验和参数设置
6.3.1 用户兴趣模型影响因素
在以往的研究中,通常只是用新闻关键字,或者新闻主题来构建用户模型,无法充分体现用户兴趣。本实验通过采用新闻关键字,新闻主题,命名实体三个不同但相关的因素来构建用户模型,多方面去分析模型的性能和推荐结果的影响。通过模型精确率、召回率和F1-Measure指标,图2实验结果表明,只有结合新闻关键字、新闻主题和命名实体三者的情况下,模型推荐效果最好。

图2 不同的新闻特征组合的推荐指标比较
6.3.2 相似度计算中的参数
为了获取最合适的参数α,β,λ我们单独选取每个参数值进行测试,并且计算相应的F1-Measure的平均值。因为α+β+λ=1,取α,β值进行测试得出结果。如表(1)可以看出,当α=0.5,β=0.2,λ=0.3时,基于这三者的参数值进行实验的效果最好。
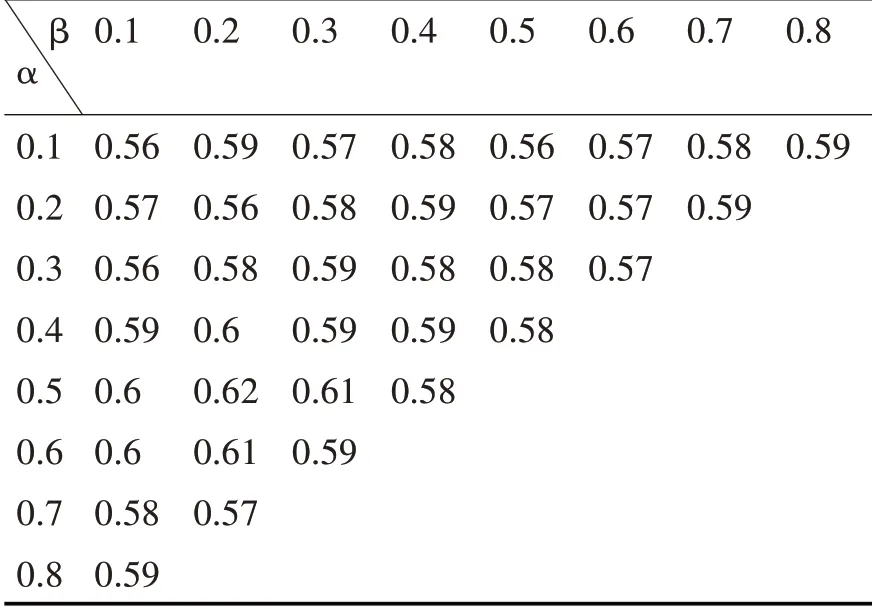
表1 用户兴趣度计算的参数设置
6.3.3 时间函数的选择
随着时间的推移,用户的兴趣模型向量权重会递减。本实验主要对比实验了逻辑函数、阻尼函数、指数函数三个时间函数。并且衰减系数k预先设置为0.4。如图3可以得出,在准确率、召回率、F1-Measure指标上,指数函数都会优于其他两种。

图3 各时间函数性能对比
6.3.4 衰减系数的调整
用户的浏览习惯和兴趣会随着时间而发生变化;采用了指数时间函数来表示,其中指数k表示变化的快慢。k值越小,意味用户最近浏览的新闻数据对用户兴趣的影响越大。反之,k值越大,意味着最近浏览的新闻数据对用户兴趣的影响下降。本实验分别对k取不同值得情况下来计算参数对推荐结果的影响,以准确率、回召率、F1-Measure为指标,如图4所示。
当k=0,时间函数f(t)=1,表示不对用户的历史兴趣权重进行处理。当k变大时;即提高短期兴趣的权重,推荐效果也变好。当k趋近0.4时,三个指标为最高,效果最好。当k>0.4后,推荐效果下降。可见,引入时间函数对于用户的长短期兴趣进行加权处理,能够显著提高新闻推荐效果。

图4 不同k的取值下推荐性能指标的对比
6.3.5 与其他方法的比较
为了验证提出的算法具有更好的推荐性能,论文对基于用户的协同过滤(UserCF)算法,基于加权动态兴趣度WDDI模型进行了实验,并且与基于内容和时间函数结合的新闻推荐算法实验结果分别从pre0.6cision,recall,F1-Measure三个评价标准进行了对比分析。从如表2实验结果可以看出:基于内容和时间函数结合的新闻推荐算法在precision、recall和F1-Measure提高了5.2%、3.9%、和8.4%。因而验证了从新闻关键字,命名实体和主题进行建模,以及引入时间函数的正确性。

表2 各推荐算法实验结果指标
7 结语
本文对新闻个性化推荐系统算法进行了研究,提出了基于内容推荐和时间函数结合的新闻推荐算法。综合了新闻关键字,新闻主题和命名实体三者来构建新闻模型和用户兴趣模型,进行匹配生成推荐列表。并且通过了时间函数对用户历史行为数据进行加权处理从而提取用户实时兴趣向量。在准确率、召回率等指标上,本文所提的方法均有优异的表现。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
华人时刊(2022年1期)2022-04-26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
动漫界·幼教365(大班)(2019年10期)2019-10-28
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
高中生学习·高三版(2016年9期)2016-05-14
理科考试研究·高中(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
新高考·高二数学(2015年7期)2015-10-22
环球时报(2009-11-25)2009-11-25
