
基于深度学习挖掘用户搜索主题研究
2021-01-19 02:26:20宋毅
计算机技术与发展 2021年1期
宋 毅
(哈尔滨华德学院 数据科学与人工智能学院,黑龙江 哈尔滨 150025)
0 引 言
用户搜索主题模型更新和学习研究工作,用户搜索主题并非一成不变,有相关实验证明,用户搜索主题随时间变化符合一定规律,基本规律是先快后慢,先多后少,逐渐遗忘。面对兴趣遗忘过程,如果兴趣模型不进行更新,将会出现用户搜索主题漂移现象:搜索引擎使用的数据操作简单,一般而言,只需要增、删、改、查几个功能,而且数据都有特定的格式,可以针对这些应用设计出简单高效的应用程序。而一般的数据库系统则支持大而全的功能[1-3],同时损失了速度和空间。最后,搜索引擎面临大量的用户检索需求,搜索引擎在检索程序的设计上要分秒必争,将大运算量工作在索引建立时完成,使检索运算尽量少。一般的数据库系统很难承受如此大量的用户请求,而且在检索响应时间和检索并发度上都不及专门设计的索引系统。大型的商业搜索引擎索引都是亿级甚至百亿级的网页数量,面对如此海量数据[4],使得数据库系统很难有效的管理。个性化、智能化的检索系统在获取用户兴趣时,其目的是提取真实准确的用户兴趣,同时尽量减少用户的参与程度。不同的用户由于不同的偏好,可能需要不同的相关搜索结果。个性化的基本构成是模型表示和存储用户兴趣偏好的算法[5]。个性化搜索引擎以用户需求为前提,分析用户上网特征,例如,鼠标滚动次数、拖动滚动条次数、网页浏览时间、保存、打印和收藏等行为。个性化服务通过收集和分析用户信息来学习用户的兴趣偏好,从而实现主动推荐的目的。个性化服务技术能充分提高搜索的服务质量,从而吸引更多的访问用户。个性化服务实现信息找人、按需服务、信息推送和减轻用户负担。个性化搜索服务首先需要建立对用户的描述,当用户的兴趣、偏好和访问模式等用户信息可以很好地被系统理解的时候,才可能实现理想的个性化服务。根据用户搜索历史构建用户模型,发现用户兴趣偏好,即用户兴趣偏好挖掘,也就成为了个性化服务的核心和关键技术。对个性化服务系统来说,最重要的是用户的参与,为了跟踪用户的兴趣与行为,有必要建立用户模型。文中用户模型特点:(1)可以通过搜索历史构建,不需要用户主动提交信息,减小用户额外负担,方便用户;(2)用户模型进行个性化查询扩展,通过分类词典自动抽取特征词进行扩展,不但可以识别普通用户兴趣类别偏好,对于查询属于兼类的用户兴趣类别偏好能够有效识别,解决查询类别歧义问题;(3)用户兴趣模型能够根据用户搜索历史发现用户兴趣,通过性能评价发现用户兴趣模型可以有效识别用户兴趣类别偏好,为个性化搜索机制提供了良好的条件。而且通过发现用户兴趣,对于分类的网站,实现个性化用户产品推荐、社交网络挖掘、个性化搜索排序等应用。
1 用户搜索主题存储模型
不同的信息检索模型都需要对Term的权重进行估计。影响权重的因素包括:(1)Term频率(term frequency,TF);(2)文档频率(document frequency,DF)或反文档频率(inverse document frequency,IDF);(3)文档长度。TF是在一篇文档中Term出现的频率;文档频率是文档集中包含该Term的文档个数;IDF可以根据log(N/df)计算,其中N为文档集中的文档个数[6-7]。可以这样理解这三个因素,Term在一篇文档出现的次数越多,这个Term就越重要,这也就是TF的作用;一个Term在某篇文档中出现的次数越多,在其他文档中出现的越少,这个Term的区分度越大,在这个文档中也越重要,这也就是IDF的作用;长文档和短文档都包含了相关内容,但由于长文档还会含有不相关内容,应把短文档排在前面,这也就是文档长度的作用。
为了精确地表示用户搜索主题,文本用特征向量去表示微博信息;文本特征向量由特征词和对应的权重组成,表示该词在文档中的重要程度。词的特征越重要,权重越高。目前,很多研究学者通过TF-IDF表示词的特征权重。而且TF-IDF使用很多,如式(1)所示。
(1)
TF-IDF算法考虑了特征词在收集的全部文档中的关系,没有考虑特征词在每个兴趣类别文档中的分布情况。所以权重对精确度有一些影响。
目前,特征词权重[8]算法有一些成熟的计算方法。但是这些算法仍然有缺点和不足之处。许多国内外研究人员已经进行了相关研究,而且有些研究人员提出了合理的先进算法。
特征词通过该词所在的文档和词的频率来计算,如式(2)所示。

(2)
算法:计算微博特征词权重。
步骤1:统计在这段时间兴趣类别里的所有内容的微博数量N。
步骤2:首先找到特征词集合t={t1,t2,…,tm},然后这个t被用作用户搜索主题类别向量的候选集合。
步骤3:计算特征词ti在第i篇文档ni中的出现频率。
步骤4:采用TF-IDF-MI方法计算特征词在候选特征词的权重,如式(3)所示。
wi=TFi*IDFi
(3)
用户搜索主题模型不仅要记录兴趣内容,而且需要记录其他信息。例如兴趣更新或者次数的创造和兴趣权重。为了提供个性化服务,如何存储用户搜索主题模型很重要。用户搜索主题模型(包括长期兴趣模型、短期兴趣模型和混合优划模型)使用向量空间模型VSM表示。向量空间模型利用n维向量特征{(c1,w1),(c2,w2),(c3,w3)}来表示。每个特征向量维度表示用户的一个兴趣类别和兴趣类别的扩展兴趣。VSM不仅能反映用户搜索主题在各个类别的兴趣度,而且也能通过计算向量来提供个性化推荐服务[6-7]。因此,文中用户搜索主题模型的逻辑结构如图1所示。
图中根节点是用户,第二层是用户搜索主题类别。为了更好地表示用户搜索主题变化,该文采用了两个用户搜索主题树模型,分别表示短期用户搜索主题模型和长期用户搜索主题模型。最后,通过短期用户搜索主题和长期用户搜索主题来分析用户的最终兴趣类别。实际生活中用户搜索主题常常随时间变化。用户搜索主题类别也会有一些变化。随着时间变化用户搜索主题被认为是用户搜索主题漂移。因此,兴趣模型应该包括用户搜索主题偏移的解决策略。两个用户搜索主题漂移模型经常被使用:第一个是用滑动时间窗口模型表示用户搜索主题模型。该方法非常注重用户实时时间,忽略了性能的持久性。第二个方法是使用遗忘函数策略,忽略了发现新的用户搜索主题[9-11]。该文指出现有用户搜索主题模型用户搜索主题漂移和用户搜索主题更新的不足之处,然后提出改进的用户搜索主题模型策略。首先采用用户搜索主题向量模型提出模型算法,然后分析当前用户的用户搜索主题漂移策略,最后改进用户搜索主题模型的这些缺点。
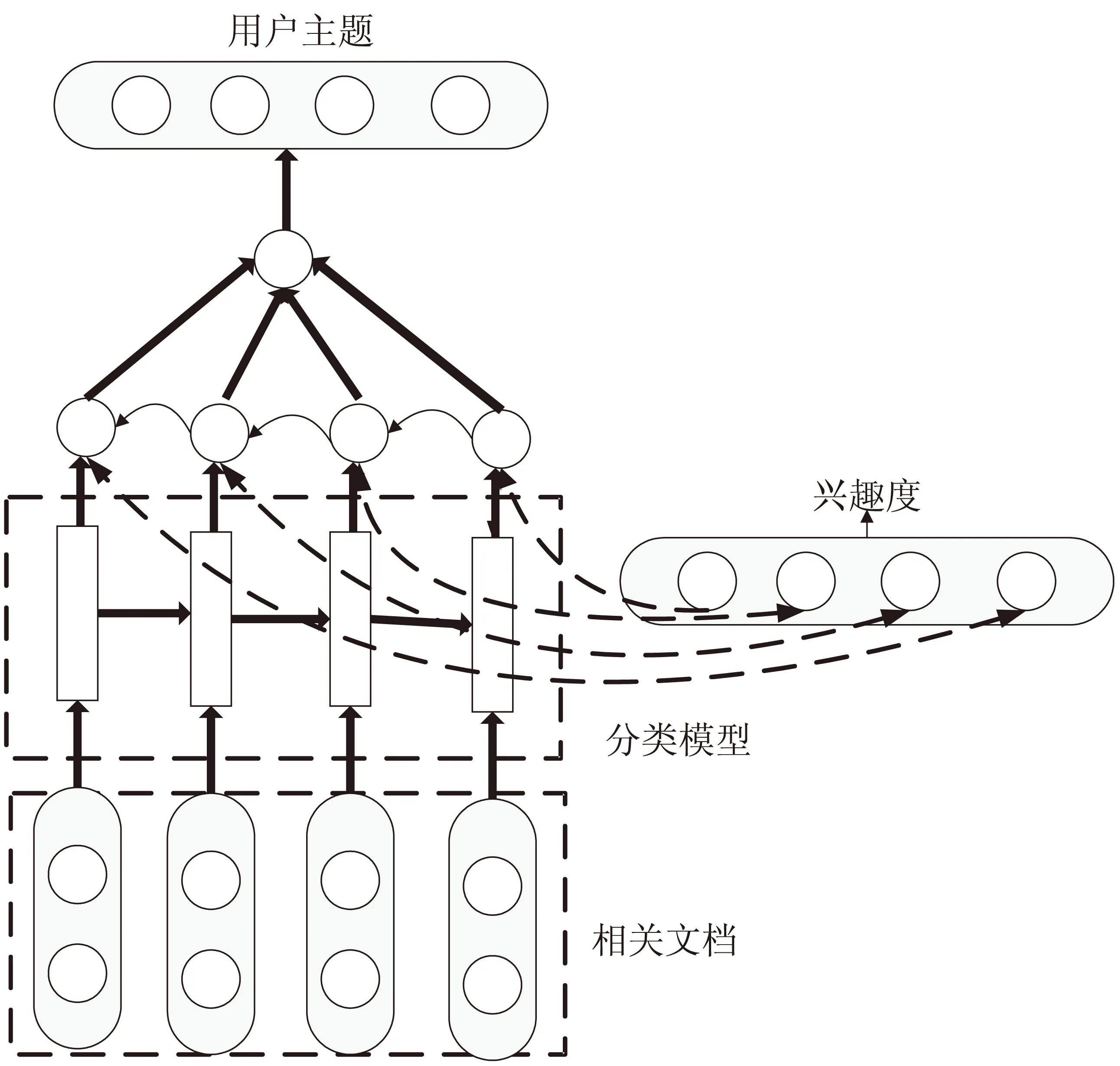
图1 用户主题模型构建
人的记忆力遵循自然遗忘的规律[12-16]。意味着人的记忆力随着时间的流失会逐渐减弱。笔者认为用户搜索主题也遵循像用户搜索主题遗忘规律一样的规律。也就意味着用户搜索主题随着时间推移逐渐减弱。而且遗忘规律是先快后慢原则。通常用户最新更新的兴趣类别属于短期用户搜索主题。对于用户搜索主题类别还没有更新的属于长期用户搜索主题。可以让衰老的用户搜索主题对象过滤。因此,该文在用户搜索主题模型中介绍了遗忘因子的概念。当用户搜索主题模型更新时,用户不仅仅在用户搜索主题模型中添加最新的用户搜索主题类别,而且也调整了现有的用户搜索主题类别的权重。也意味着确定用户搜索主题类别特征词权重通过遗忘因子和逐渐消失的那些老的旧的不再使用的特征词。
2 查询扩展
语义知识辞典扩展方法大多在某一具体领域的知识辞典中应用,将查询串与分类字典里每一项进行匹配,并进行相应的特征项的权值求和计算,权值和最大的一类就是与查询串最相关的一类。这种方法可以较快地定位到相关类,但是分类字典里计算特征项的权值是以单个单词为单位,而每个单词可能同属多个类,导致最相关类别判定错误,影响下步检索结果的准确度。
扩展中词典方法采用搜狗词库作为词典。搜狗拼音输入法可以覆盖几乎所有的中文词汇,所以文中词典使用搜狗细胞词库。搜狗细胞词库11 016个词条,包括8个大类,49个小类。例如,体育健身:足球、篮球、健身、田径等。每个小类下包含词库,例如篮球(23个词条)、篮球明星(718词条)、NBA球队名(57词条)、篮球术语(228词条)、篮球词汇大全(2 384词条)、NBA球员名字(75词条)、NBA(43词条)和体育类专用(621词条)等。用户输入的查询首先对词典进行扫描,在词典中进行最长匹配查找过程,即输入查询序列,查找序列在词典中所有最长的匹配词条。如果有和查询串匹配的词,将其加入扩展词库。例如,输入查询为苹果,文中扩展为:苹果手机、苹果11,如图2所示。

图2 基于词典扩展样例
通过研究发现,存在用户查询是不同类别的现象,单独根据用户查询很难分清用户感兴趣的类别,所以该文将查询进行个性化查询扩展,通过查询扩展技术,将与“苹果”相关的两类查询,依据用户搜索主题兴趣相关度都扩展进来,然后再进行实验。经过查询扩展前后实验对比,扩展后有效改进了歧义类别的兴趣查询的识别问题。查询扩展库样例如表1所示。

表1 查询扩展库样例
通过查询扩展,查询相关和相似的都加入查询扩展库,为下一步用户兴趣模型识别用户兴趣兼类类别提供基础,有效改进了用户搜索主题的整体性能。
3 实验结果
采用分类技术对用户的兴趣进行挖掘,相比于用关键词匹配方式,达到了模糊识别主题的效果,取得了较好的兴趣挖掘结果。该文通过爬虫爬取实验数据,在分类过程完成之后,需要对分类效果进行评估。平均准确率和平均召回率都达到96%以上,分类效果比较理想,分类实验结果计算文本的类别,然后通过查询和文档关系以及文档类别将用户查询映射到类别体系,进而识别用户兴趣类别偏好。
兴趣通过爬虫爬取,采用微博数据。采用5 260条微博最近一段时间的,4 230有用的微博日志抽取和分析在挖掘之前,然后分别通过微博日志文本处理。首先,抽取15天的用户数据作为短期用户搜索主题,然后抽取30天用户数据作为长期数据。然后,使用抽取的数据去更新短期用户搜索主题模型,每隔15天。长期兴趣模型每隔30天更新一次。实验分别在每个时间点完成。最终,长期用户搜索主题模型和短期用户搜索主题模型分别计算它们所占的比例。文中采用各种测试结合,短期用户搜索主题模型和长期用户搜索主题模型,短期兴趣一般有10天,长期兴趣有30天;综合兴趣显示如图3所示。

图3 兴趣综合曲线
在实验中,模型参数选择如下:a=0.6,b=0.4,hlper=25,hlcur=10。使用爬虫爬取微博数据测试效率,提出改进算法,滑动时间窗口模型、遗忘策略兴趣模型。确定兴趣模型比例和优化混合性启蒙关系;关键搜索性能是每次的100倍。第15个结果用户搜索主题类别;最后兴趣比例被计算。测试结果如图4所示。
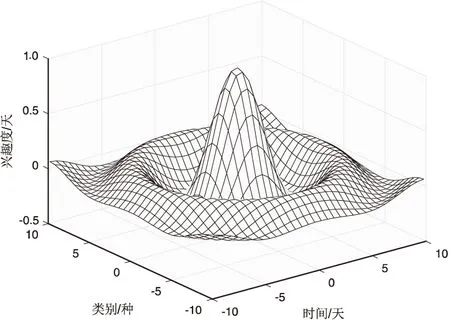
图4 兴趣度曲线
每个用户总体兴趣是个恒定常数。人的精力是有限的,用户兴趣类别偏好也是有限的,如果对某些类兴趣度高,对其他类兴趣度必然降低,文中关注用户感兴趣的类别。用户整体兴趣满足固定常数,也就是随着更新学习,用户某些兴趣可能由高到低递减变化,而有些类别兴趣由低到高递增变化,但是用户在整个类别偏好体系中兴趣度总和是个恒定常数,用户兴趣能够反映用户主题偏好。然而现有大部分个性化搜索引擎没有识别用户长期兴趣和短期兴趣。当用户更关心短期用户搜索主题模型时,滑动窗口策略优于遗忘策略模型;因为滑动窗口模型对于长期用户搜索主题模型是最差的。不仅仅开发长期和短期混合策略,而且也改变用户搜索主题模型调整时间和兴趣模型。这兴趣模型影响更实际的用户搜索主题。
4 结束语
首先阐述了用户搜索主题更新学习意义和现有方法,基本的用户搜索主题更新学习方法包括时间窗机制、遗忘因子更新学习和最近最少使用算法等。文中分为短期用户搜索主题更新学习和长期用户搜索主题更新学习。其中短期兴趣学习方法采用遗忘因子进行更新学习,长期兴趣更新学习方法采用最近最少使用算法进行更新学习。用户搜索主题模型通过更新学习,能够更好地动态识别用户搜索主题。首先介绍了个性化搜索研究相关技术、个性化搜索关键技术,以及个性化搜索中用户兴趣偏好学习获取方法,基于搜索日志分析,从实验分析中可以看出用户查询满足一定规律性。引入查询扩展技术进行个性化查询扩展,通过查询扩展形成扩展词库,采用基于词典查询扩展方法进行查询扩展。通过查询扩展技术,解决了用户查询串短、用户查询歧义等问题。同时将查询扩展技术应用在用户兴趣模型中,能够有效识别用户兴趣类别属于兼类的查询,例如用户输入“苹果”,事先并不知道用户对电子产品的“苹果”感兴趣,还是对水果类别的“苹果”感兴趣,但是通过查询扩展技术,将电子和水果类别相关的查询信息扩展,能够清晰识别用户查询的意图。因此,查询扩展技术为用户兴趣模型识别兼类兴趣打下良好基础。然后研究了用户搜索主题模型的评价方法,包括相对误差分析方法、传统的准确率方法。相对误差值越小、查询串分类准确率越高,说明用户搜索主题模型识别用户搜索主题类别越准确。相应地给出实验分析,具体评价了用户搜索主题模型的性能。挖掘用户兴趣主题搜索研究工作一直有学者研究。尤其是用户兴趣模型的建立工作。对于实验数据稀疏问题,最佳解决办法是和大型互联网公司合作,互联网公司提供真实数据进行科研。也有研究学者开发了元搜索系统,挂在搜索系统上来获取用户上网习惯。通过服务器管理用户日志,然后通过日志进行分析用户偏好类别,也是可行的研究方法。
总之,机遇深度学习挖掘用户搜索主题能够有效地为不同用户提供个性化服务,用户不再为面对浩如烟海的信息如何进行选择而愁眉不展。随着时代发展,手机、平板上网用户增多,个性化服务可以由互联网向手机上网用户研究应用转变,这将是未来的研究工作热点问题。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
信息安全研究(2016年4期)2016-12-01 06:06:54
新校长(2016年8期)2016-01-10 06:43:59
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中文信息学报(2015年4期)2015-04-21 08:29:12
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
