
基于Pytorch的LSTM模型对股价的分析与预测
2021-01-19 02:26:50张康林叶春明李钊慧王锦文
计算机技术与发展 2021年1期
张康林,叶春明,李钊慧,王锦文
(1.上海理工大学 管理学院,上海 200093;2.南昌大学 公共管理学院,江西 南昌 330000)
0 引 言
股票市场发展至今已有400多年历史,股票投资者随着金融市场发展的越来越成熟也变得越来越多,而股价的预测一直都是股票投资者关注的问题。文献[1]说明了由于股票价格具有高噪声、动态、非线性和非参数等特性,想要准确预测股价仍具有很大的挑战。但随着大数据时代的到来和人工智能技术的发展,准确预测股票价格已经慢慢变为了可能。
目前,越来越多的学者采用人工智能技术来实现股价的预测,从传统的人工神经网络模型到深度学习模型,再到现在的多种模型相互结合进行预测,这些技术一直都在被改进并且被广泛使用。许兴军[2]使用反向传播神经网络(backward-propagation network,BPN)模型对浦发银行近一年交易日的股票数据进行了预测;韩山杰等人[3]采用多层感知机(multi-layer perceptron,MLP)模型预测了苹果公司每日的股票收盘价;Ticknor等人[4]将日市场价格和财务指标作为输入,利用前馈神经网络模型对微软公司和高盛集团未来一天的收盘价进行了预测。但是由于人工神经网络在对股价进行预测时,存在很多问题,比如:模型优化过程中,存在梯度消失和梯度爆炸问题,导致模型无法优化;容易出现局部极值问题;过拟合现象的发生导致模型在对测试集进行预测时,其预测精度变小。为了解决上述问题,针对深度学习的研究也是越来越多。Graves等人[5]说明了LSTM模型可以解决梯度消失和梯度爆炸问题,Polson等人[6]探讨了深度学习技术在金融市场研究中不仅可以解决过拟合问题,还能提高样本的拟合程度。同时,国内外学者也利用深度学习技术对股价预测进行研究。Hoseinzade等人[7]提出了一个基于CNN的框架,并对标普500指数、纳斯达克指数、道琼斯指数、纽约证交所指数和罗素指数次日的走势进行了预测,结果表明,预测性能比基线算法更高;Zahra等人[8]通过递归神经网络(RNN)对卡萨布兰卡证券交易所29天的maroc股票价格进行预测;宋刚等人[9]使用基于自适应粒子群优化的LSTM模型分别对沪市、深市、港股股票数据进行了股价预测,具有更高适用性。
通过上述分析,少有研究将聚类算法和深度学习技术进行结合来应用于金融预测,相关研究如文献[10],并且大多数研究使用的是Tensorflow深度学习框架进行建模分析。因此,该文使用SOM算法对187只不同业绩的股票进行聚类和基于Pytorch的LSTM模型对三类中的共9只股票进行股价预测,主要贡献有:(1)使用Pytorch深度学习框架进行深度学习模型的构建,相对于被广泛使用的Tensorflow,Pytorch更加简洁直观;(2)使用了同一LSTM神经网络结构对9只股票进行股价预测,证明了LSTM神经网络在股价预测上有着很好的泛化能力;(3)针对不同业绩的股票进行分类预测,证明了LSTM模型对业绩优良的股票预测精度更高。
1 SOM神经网络原理及改进
1.1 SOM神经网络原理
1981年,自组织映射(self-organizing map,SOM)神经网络由芬兰学者Kohonen[11]提出,该聚类算法由于可以实现自学习,网络具有自稳定性,无须外界给出评价函数,能够识别向量空间中最有意义的特征,抗噪音能力强等优点。文献[12-14]证明了SOM算法在各个领域应用广泛。
1.2 SOM算法的具体过程
(1)初始化输入数据Xi,j,i=1,2,…,n,j=1,2,…,m。
(2)初始化参数。模型需要初始化学习率η(0<η<1),最小学习率ηmin,输入神经元数m,输出神经元数P=Pr*Pc,邻域值R,邻域值的缩小率a(a<1),学习率的缩小率λ(λ<1),最初迭代次数Iteration=0,最大迭代次数Max_iteration,时间k=0。
(3)初始化权重Wp,q,j(中心点Cp,q),随机生成[0,1)之间的数,p=1,2,…,Pr,q=1,2,…,Pc,j=1,2,…,m。
(4)最初迭代次数加1,并且设置目前的数据位置a=0。
(5)将数据下标o加1,数据位置a加1:
o=o+1
(1)
a=a+1
(2)
(6)设置当前来自于Xi,j数据Xo,Xo=[xa,1,xa,2,…,xa,m]。
(7)计算当前数据Xo与每个中心点的距离:
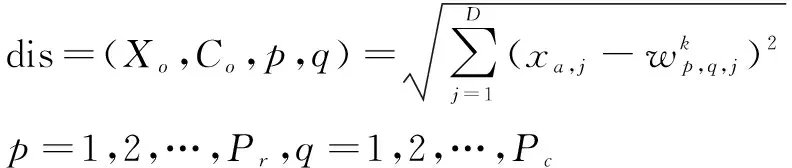
(3)
(8)通过步骤(7)的最小距离来确定获胜中心点(WC);
(9)依次修改所有权重坐标(即中心点坐标):
(a)在拓扑图(见图1)中计算当前中心点与获胜中心点的距离:
disCC,WC=dic(Cp,q,WC)=
(4)
(b)修改权重坐标:
(5)
(c)重复步骤(a)与(b),直到所有中心点坐标被修改。
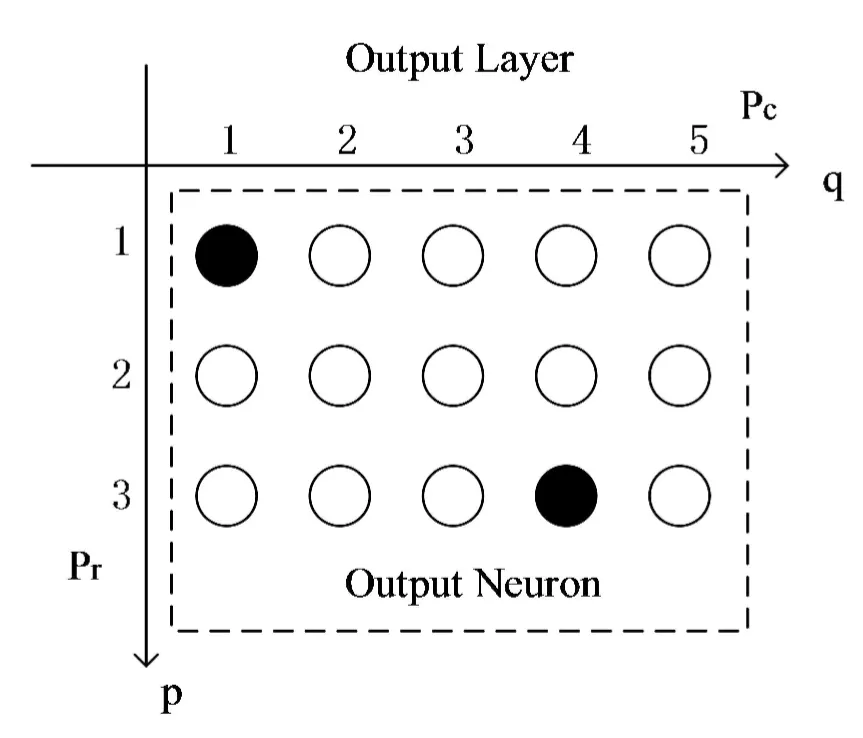
图1 拓扑图
(10)判断中心是否被所有数据修改:
(a)如果a=n,则跳到第(11)步;
(b)如果a≠n,则返回第(5)步。
(11)修改邻域值和学习率:
R=R*a
(6)
η=η*λ
(7)
(12)判断学习率:若η<ηmin,则令η=ηmin。
(13)停止标准:
(a)如果Iteration=Max_iteration,则跳到第(14)步;
(b)如果Iteration≠Max_iteration,则返回第(4)步。
(14)将数据分配到距离最小的中心点,再计算每个中心点的数据数。
(15)根据拓扑图矩阵确定每一类中包含数据的数量。
1.3 SOM算法的改进
为了进一步探讨不同类别的股票在对其收盘价格进行预测时,其预测精度是否也会有所不同,在计算出分布矩阵和最佳中心点的坐标后,再一一计算每一个点和中心点的欧氏距离,见式(8)。通过分布矩阵,找出距离中心点最近的n个点,即可找到每一类中所含的股票代码。
(8)
2 改进的SOM实验及其结果分析
2.1 数据下载
该文所做的SOM分析所需要的数据均来自于证券宝平台,该平台可以通过python API获取股票年报数据。分析中选取了沪市股票(600000-600100)、深市股票(000001-000100)与创业板股票(300001-300100)总共187家上市公司2018年的销售净利润率、净资产收益率、销售毛利率、净利润和每股收益5项能充分反映上市公司综合盈利能力的指标作为主要研究对象。
为了避免指标单位对结果的影响,需先将原始数据进行归一化处理,归一化公式如下:
(9)
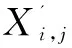
2.2 实验结果分析
该文在系统WIN10、1TB+128G(SSD)的硬盘、INTEL酷睿I7-6700Q的CPU和内存4 GB的PC机上使用python3.7实现SOM算法,输入神经元数为5。由于该文将187只股票分为了亏损股、盈利股和小幅亏损或小幅盈利股三类,所以输出神经元数P=Pr*Pc=1*3,邻域值为4,学习率为0.1,最小学习率为0.001,邻域值的缩小率为0.99,学习率的缩小率为0.99。迭代次数经过多次调整发现,当Max_itreation大于等于200时,最终的聚类结果不变,所以将Max_itreation设为200,减少程序运行时间。
经过多次对程序的运行,可以求出其中有71只股票以点[0.916 956 54 0.955 327 9 0.623 186 590.077 145 72 0.540 198 69]为中心聚为第一类,有96只股票以点[0.906 286 24 0.948 758 48 0.390 331 97 0.047 142 88 0.520 635 68]为中心聚为第二类,有20只股票以点[0.499 768 73 0.800 670 52 0.380 143 94 0.023 035 95 0.243 620 15]为中心聚为第三类,通过SOM算法的改进原理,进一步优化python实现的SOM代码,将每一个类别中所含的股票一一求出。
为了比较每一类的股票盈利能力大小,表1将三类中部分股票的盈利能力指标列出。

表1 每一类部分股票的盈利能力
其中,code代表股票代码,roeavg代表净资产收益率(平均)(%),npMargin代表销售净利率(%),gpMargin代表销售毛利率(%),netProfit代表净利润(元),epsTTM代表每股收益。
该文选取的五项指标是衡量公司获利能力和成长性最好的指标,即能通过这五项指标说明该类上市公司在技术水平、经营规模、经营实力等方面具有很大优势,经营业绩优良,竞争能力比较强,综合财务状况较佳,颇具发展潜力和长期投资价值,即通过这五项指标的大小可以判断该公司的综合盈利能力大小。所以结合表1可以看出,综合盈利能力的大小排序:第一类>第二类>第三类。计算出不同类别所包含的股票后,将进一步对不同类别的股票使用LSTM模型进行预测。
3 Pytorch深度学习框架
3.1 简 介
Pytorch是Facebook在2017年开源的一款深度学习框架,它是源于torch更新后的一种新产品,同时也是一个原生的python包,它与python是无缝集成的,而且还特意使用了命令式编码风格。Pytorch由于具有动态计算图表、精简的后端与高度可扩展等优势,目前得到了广泛的应用。Pytorch在已经在聊天机器人、机器翻译、文本搜索、文本到语音转换和图像与视频分类等项目中取得了巨大成功。
3.2 开发环境
该文是在系统WIN10、1TB+128G(SSD)的硬盘、INTEL酷睿I7-6700Q的CPU和内存4 GB的PC机上通过python3.7版本和anaconda5.3.1版本来使用Pytorch构造LSTM深度学习模型。Anaconda是一个开源的python包管理器,包含了python、conda等180多个科学包及其依赖项。它支持Windows、Linux和Mac三种系统,由于它提供了包管理与环境管理的功能,所以能很方便地解决多版本python切换、并存以及下载安装各种第三方包等问题。然后打开其中的jupyter notebooks应用程序,直接在谷歌网页页面中编写、运行和调试代码。
4 LSTM神经网络的原理
长短期记忆神经网络(long-short term memory,LSTM)在1997年由Hochreiter等人[15]提出。它是循环神经网络(recurrent neural network,RNN)的一种变体,能够更好地解决传统RNN在处理大型时间序列时存在的梯度消失和梯度爆炸等问题。由于深度学习框架发展得越来越成熟,再加上LSTM能够更好地处理序列化数据,所以LSTM神经网络目前得到了广泛的应用,相关研究如文献[16-17]说明了LSTM算法在时间序列预测、视觉识别、分类等都取得了重大成功。
LSTM的网络结构由三个门控和一个记忆细胞组成。记忆细胞能将历史记忆信息进行保留。下面是三个门控的计算原理。
第一步,遗忘门能决定从单元信息状态中去丢弃哪些信息,采用sigmoid作为激活函数,它能为单元状态中的每个元素输出0到1之间的数值,公式表示如下:
ft=σ(Wf*[ht-1,Xt]+bf)
(10)
第二步,确定要添加到单元状态的信息。这里包括两个部分:一个是采用sigmoid作为激活函数的输入门,它决定要更新的值;另一个是tanh层,它创建要添加到单元状态的新值。公式表示如下:
it=σ(Wi*[ht-1,Xi]+bi)
(11)
Ct=tanh(WC′*[ht-1,Xt]+bC′)
(12)
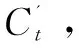
(13)
第四步,决定输出门的值,公式表示如下:
Ot=σ(Wo*[ht-1,Xt]+bo)
(14)
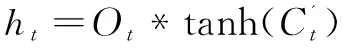
(15)
式(10)~式(15)中,σ表示sigmoid激活函数,Wf表示遗忘门的权重矩阵,Wi表示输入门的权重矩阵,Wc表示更新门的权重矩阵,Wo表示输出门的权重矩阵,bf表示遗忘门的偏置,bi表示输入门的偏置,bc表示更新门的偏置,bo表示输出门的偏置,ht表示t时刻的输出,Ct表示t时刻更新的细胞状态。
5 LSTM神经网络设计与实现
5.1 实验设计
预测流程包括:下载数据、数据处理、数据归一化、LSTM模型的训练、微调参数和收盘价格预测。
下载数据:每一类中随机挑选3只股票,下载每一只实验股票2018年的收盘价格,通过证券宝平台的python API接口,编写python程序进行下载和储存。
数据处理:将存储的原始数据打开,删除股票代码一列,并且删除缺失值的每一行,进一步构建完整有效的数据集,便于数据分析。
数据归一化:为了使模型更加容易正确的收敛,将收盘价格进行了归一化处理。
LSTM模型的训练:上文已将187只股票分成了3类,并且也已知每一类别中所含的股票代码,所以接下来将使用LSTM模型对每一个类别中的股票随机进行预测,观察每一类别的预测精度。该文想通过前面2天的股价来预测当天的收盘价,所以将前两天的股价当作输入,当天的股价当作输出,最后再基于Looney[18]的研究,将每只实验股票收集到的65%数据作为训练数据集,35%数据作为测试数据集。
微调参数:在模型的训练过程中,需要不断调整学习率、LSTM层数和隐藏层神经元数,直到模型的预测效果最佳。
价格预测:将测试数据集导入训练好的模型进行价格预测。
实验流程如图2所示。
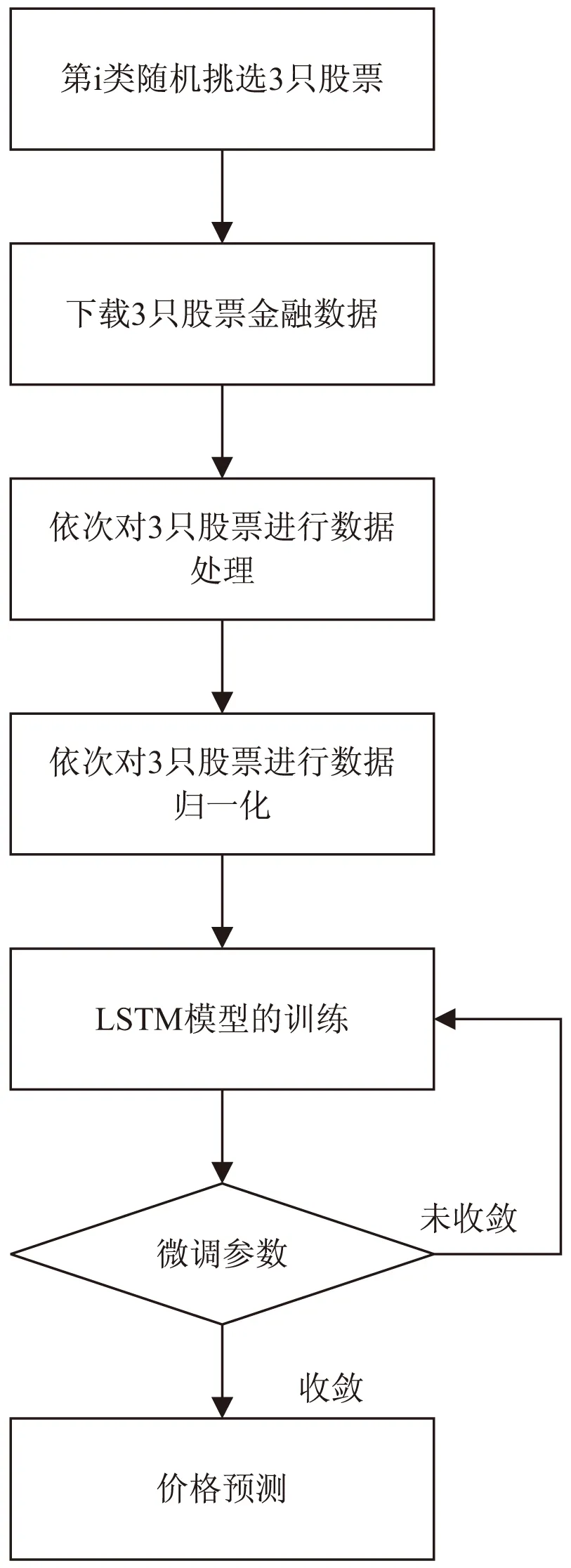
图2 股价预测实验流程
5.2 模型评价标准
选取均方误差(MSE)和决定系数(R2)作为评价指标对模型预测结果进行定量评价。其中MSE数值越小,模型预测结果与真实值偏差越小,结果也就越准确;决定系数R2越接近数值1,说明拟合优度越大,模型预测效果也就越好。具体公式如下:
(16)
(17)
其中,N代表数据集中数据的个数,yp代表模型预测值,yn代表实际值,yave代表实际值的平均值。
5.3 LSTM模型参数设置
LSTM模型结构由输入层、输出层、两层LSTM层组成,其中输入层单元数为2,在权衡了模型的预测准确度后,将1-3类的隐藏层单元数都设置为4,输出层单元数为1,迭代次数为1 000,学习率为0.01,损失函数采用均方误差MSE,模型训练过程采用的优化算法为Adam算法,模型的搭建在Pytorch深度学习框架下实现。
5.4 结果分析
每一类中随机抽取3只股票的预测结果,如图3~图5所示,每一张图的纵坐标代表股价做归一化处理后的值,横坐标代表时间第x天。两条曲线分别代表LSTM模型预测值和股价真实值,可以看出LSTM模型的预测曲线都很接近于股价的真实曲线。
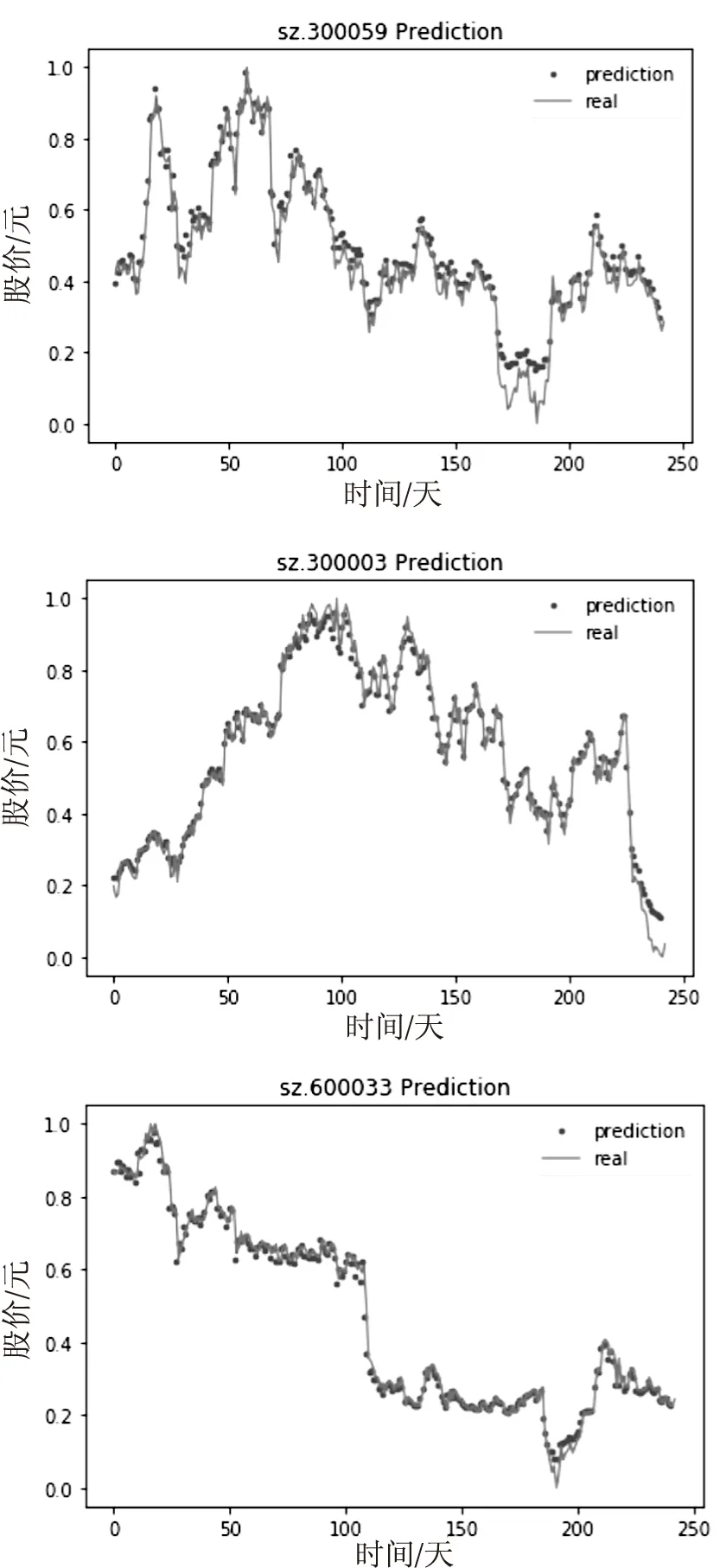
图3 第一类中的sz.300059、sz.300003、sh.600033股票预测结果
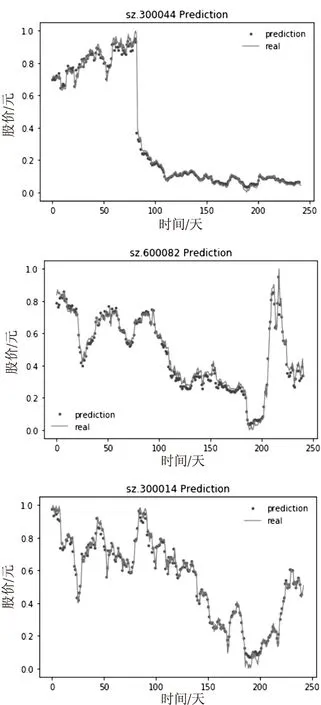
图4 第二类中的sz.300044、sh.600082、sz.300014股票预测结果
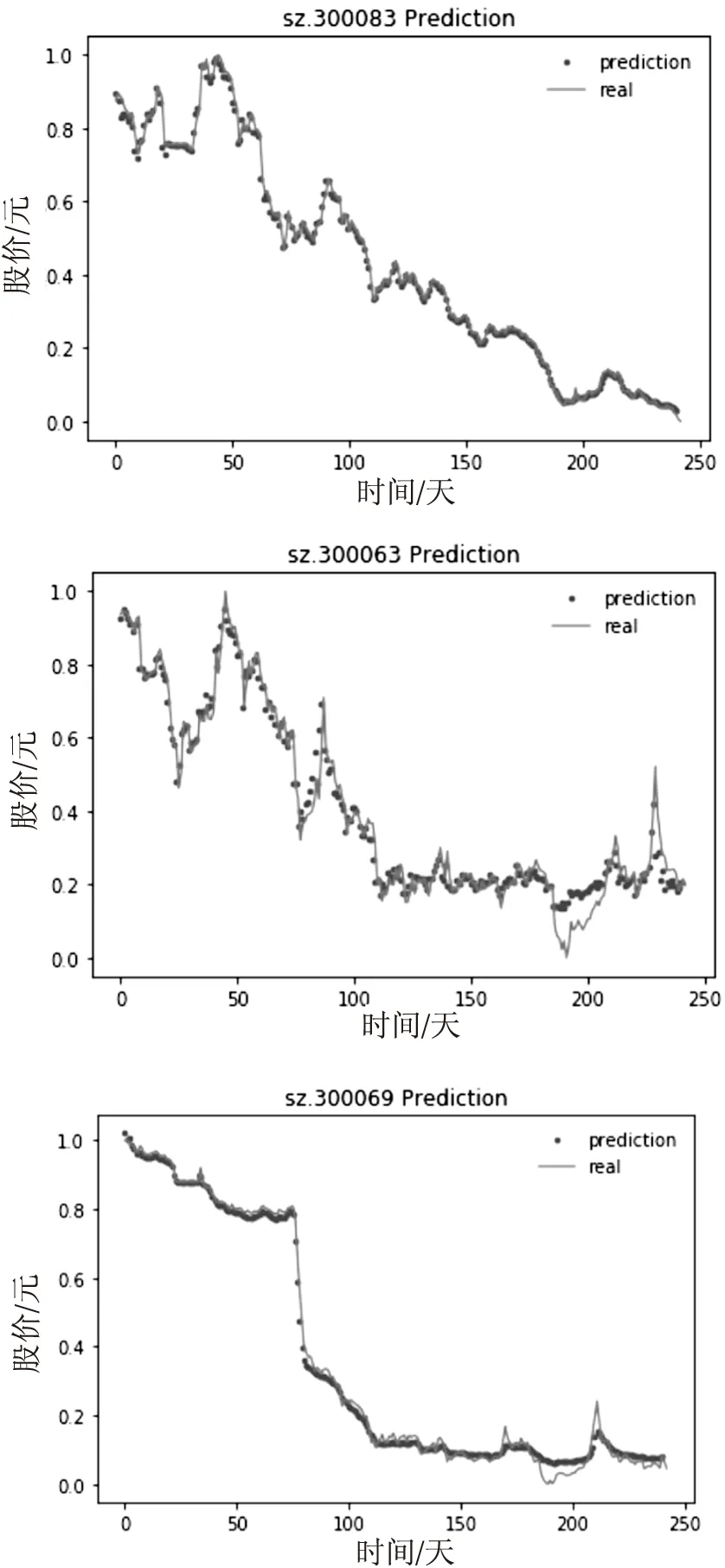
图5 第三类中的sz.300083、sz.300063、sz.300069股票预测结果
为进一步验证模型预测不同盈利能力的股票的预测性能,表2给出了三类中各3只股票的评价标准计算结果。第一类的平均均方误差为0.003 40,第二类的平均均方误差为0.006 21,第三类的平均均方误差为0.008 71,所以第一类预测误差小于第二类,第二类的预测误差小于第三类,说明相同的LSTM模型预测第一类股票的股价结果最准确。同时,在决定系数R2评价标准中,第一类的R2平均值为0.931 18,第二类的R2平均值为0.899 17,第三类R2平均值为0.860 01,所以同样的LSTM模型在预测不同类的股票价格时,第一类的决定系数更接近1,其次是第二类,说明LSTM模型在对第一类进行预测时,模型拟合优度最大,预测效果最好,其次是第二类。综合以上分析,可以得出:使用相同的LSTM模型预测不同盈利能力的股票价格时,盈利能力越强的股票,模型对其股票价格预测结果越准确。
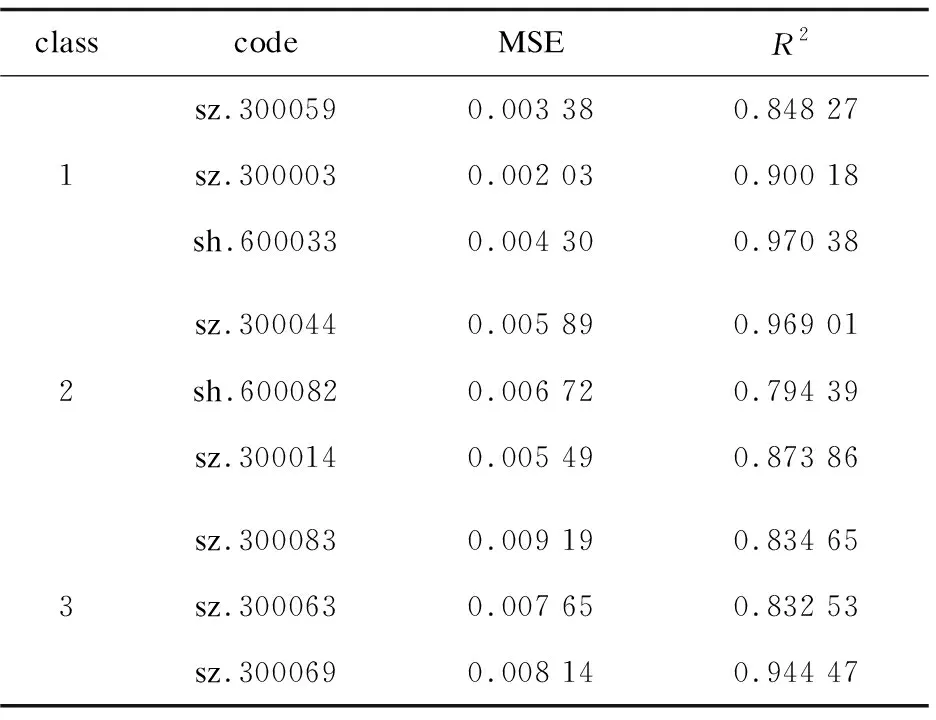
表2 评价标准结果
6 结束语
股票价格的预测是一个非常复杂的过程,因为股票市场的预测过程基本上是动态的、非线性的、复杂的。因此,通过证券宝平台下载187只股票数据,提出一种基于自组织特征映射(SOM)神经网络和长短期记忆网络(LSTM)相结合的股价预测方法。首先使用python实现Kohonen提出的SOM算法,然后通过加入计算每一只股票与最终中心点的距离的改进,将187只股票聚成3类,并且得出三类中每一类所含股票,再基于Pytorch深度学习框架构建LSTM模型,分别对三类中随机选取的3只股票进行股价预测。实验结果表明:在使用相同网络结构的LSTM模型对不同盈利能力的股票价格进行预测时,模型对盈利能力较大的股票价格预测有更高的预测精度。
该文对股价的预测方法,能通过聚类帮助股票投资者筛选出拥有更大盈利能力的股票,从而进一步提高预测精度。此方法在未来金融时间序列研究中拥有广泛的应用前景,不仅能为投资者提供一定的参考信息,也能为后续的研究者提供相应的参考。
猜你喜欢
理财周刊(2023年11期)2023-11-08 00:37:19
电脑报(2020年12期)2020-06-30 19:56:42
股市动态分析(2019年42期)2019-11-13 01:55:04
电脑报(2019年4期)2019-09-10 07:22:44
股市动态分析(2016年23期)2016-12-27 19:01:58
股市动态分析(2016年22期)2016-12-27 10:39:02
股市动态分析(2016年7期)2016-09-29 11:18:25
股市动态分析(2016年4期)2016-09-29 08:39:10
股市动态分析(2016年2期)2016-09-27 21:22:52
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
