
加权误差:让神经网络更快收敛
2021-01-15 10:35安徽交通职业技术学院万芳
交通建设与管理 2020年5期
文/安徽交通职业技术学院 万芳
安徽省交通运输综合执法监督局 李明
关键字:卷积神经网络;加速收敛;加权误差;计算机视觉;图像分类;深度学习;误差函数;梯度下降
神经网络一直被居高不下的计算量让任务耗费着大量的计算资源,而且严重限制了神经网络在各个领域地普及。近些年,各类降低参数量[1,2]和加速神经网络收敛速度[3-5]的研究出现在人们的视线中,让神经网络得以运行在手机等移动电子设备中,也促进了神经网络研究的进程。其中ShuffleNet[1]采用分组卷积减低参数量,Batch Normalization[4]着眼于每层特征图的不同协方差进行了研究,并在之后的各类神经网络中广泛使用,极大地缩减了神经网络的运行时间,但是神经网络的训练速度仍然有待提高。
在梯度下降缩减误差的同时,我们考虑加入另一个类似的通道,提出了加权误差(Weighted error, WE),加权误差在神经网络中应用不多,大都是不同应用场景的改进[6],而我们针对最原始的神经网络进行改进。以分类举例:我们通常使用交叉熵作为误差函数,由其在神经网络中的独特作用,其是将真实分类对应的输出增大,来近似期望模型的,其等价地就是缩小其错误分类对应的输出。
基于这种想法,我们采用乘法连接两个模块,将这个通道作为误差函数的权重输入,在零参数增加和少量计算量的增加下,加快了10-20%神经网络的收敛速度。
1 加权误差
在随机梯度下降算法中,我们对于批量大小为m 的输入采用:
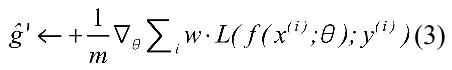
由于梯度的性质,我们可以自然地将其转化为:

1.1 第二个优化通道
我们以分类举例,分类中误差函数通常选择交叉熵:

在神经网络中考虑单个样本中p1一般是one-hot 编码的概率分布,所以只有为1 的类别即只有期望响应会返回计算值,对数函数在(0,1]导数为正,为负,则loss降低对应着期望响应的增加,这符合我们想要的结果,同样的我们降低非期望相应也能达到相同的效果。基于这种想法我们将降低非期望相应的部分当作权重传递给误差,这个部分表示为则整体误差表现为:

值得注意的是,这里并不是采用对应样本的权重相乘再求和,而是先求和再乘,我们采用这种方式保证第二个通道的可用性,并不之将其作为权重使用。
1.2 权重分析
由神经网络中的知识为概率,所以:
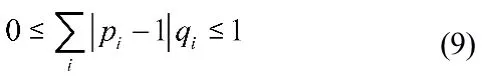
这为权重的学习率衰减作用提供了良好的保障。随着误差下降,准确率的提升,权重随之减小,这符合我们对于学习率衰减一贯的认知。同时不像平时学习率的指数化衰减等方案,其学习率和当前训练步数密切相关,这使得很多时候冗长的训练步数并没有为我们带来良好的效果。我们想要的应该是每一个状态都有与之匹配的学习率,我们的权重正好可以满足这个特点,不同于之前需要做一些实验才能找到比较好的学习率衰减时机不同,我们甚至只需要在前期定义一个合理的学习率即可,这在有效避免了一部分计算浪费的同时,大大降低了神经网络对于超参数的依赖性。众多周知,神经网络对于超参数学习率的依赖性比较高。
2 实验验证
本文选用CIFAR-10[9]和MNIST[10]数据集进行测试,CIFAR-10 由32*32 的彩色1 像组成,包含50k 训练数据和10k 测试数据;MNIST 由28*28 的灰度图像组成,包含60k 训练数据和10k 测试数据。模型选用经典的VGG[7]和ResNet[8],其余参数和数据增强方法采用ResNet 的操作。见表1,选用这两种方法包含了各种模块,包括BN,1*1 卷积,全局平均池化[11]等等有着比较好的对比价值。

表1 VGG 和Resnet 模块对比

BN √1*1 卷积 √全局平均池化 √
2.1 CIFAR-10
考虑CIFAR-10[9]的图像大小,我们对VGG 网络进行了如表2 的一些缩减,而Resnet 就保持其在论文中的结构,在本文中为了方便计算我们采用Resnet-20[8]进行实验,参数设计遵循原论文中的参数,由于本论文的重心是加快网络收敛速度,所以并不对算法效果过多关注。
如图1,在VGG 网络中我们为防止过拟合添加了10-4 的参数衰减和0.1 的学习率,选用batch size 为128 得到加权误差有了很好的加速效果,其准确率基本全局高于传统方法,加速效果非常明显,而在Resnet-20 中这种加速就不显得那么明显了,这主要是Resnet 本身收敛速度就比较快,所以大多情况下都处于震荡情况下,而较大学习率产生的震荡效果太强,掩盖了部分加速效果,但是我们仍然可以较为直观地观察到WE-Resnet 以较小的震荡,较快的收敛速度进行收敛。为了说明这种情况,我们统计了两组实验的测试准确率的标准差和均值,可以看到加权误差可以在震荡较小的同时具有更快的收敛速度。但是WE 模块在迭代前期效果并不好,这就是标准差相差不大的原因。这种情况是由于初期神经网络受样本误差影响较小,而WE 模块更倾向于“找准方向”小步长地移动,我们统计1000 步以后的标准差得到VGG 和Resnet 中受到WE模块影响,标准差分别降低9.0%和9.2%。

表2 缩减的VGG 结构

Table 3 Test set accuracy rate

图1 准确率对比
之后我们对比另一个和神经网络性能密切相关的数据——误差。如图2,我们对比了两种网络的误差,其中WE 模块对应误差也只取交叉熵部分,发现其相比于不加WE 的网络有所增加,即在相同的准确率下,WE 将有这更大的误差,虽然这个误差将和WE 做乘法后缩减,但是本质上还是为神经网络的进一步训练带来了契机。我们将训练继续,如图3 我们发现,WE 模块的效果显著好于传统的VGG 模块,平均提升了2%的准确度,实际降低误差率9%。这一方面印证了我们之前对于其类似于降低学习率的加速效果,同时也印证的其存在一定的正则化效果,这个正则化效果并不强,在VGG 这种参数量大,很容易过拟合的网络中能起到一定作用,在与其对比的Resnet中效果就不是很明显了。
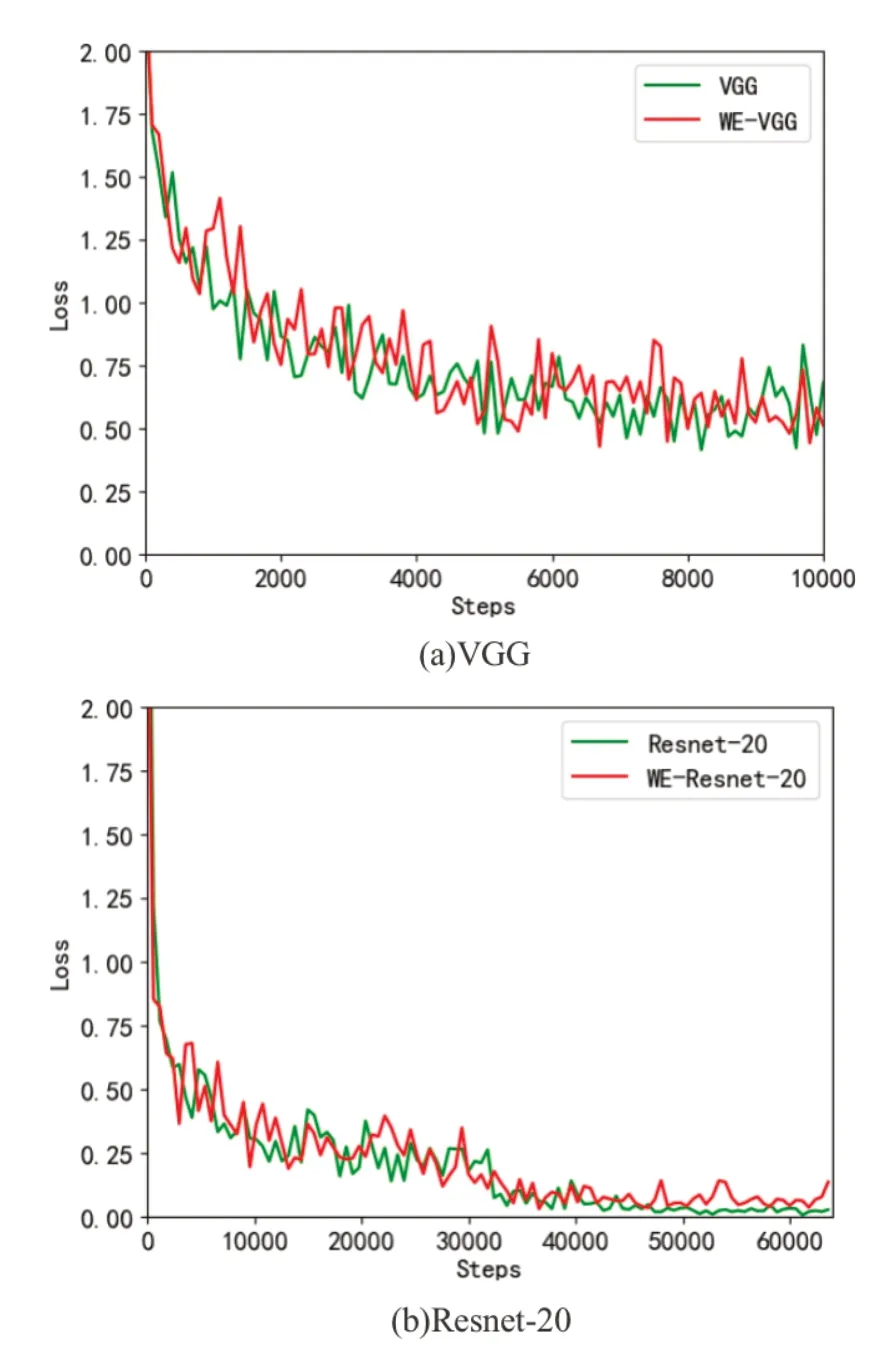
图2 误差对比

图3 VGG 的最高准确率检测

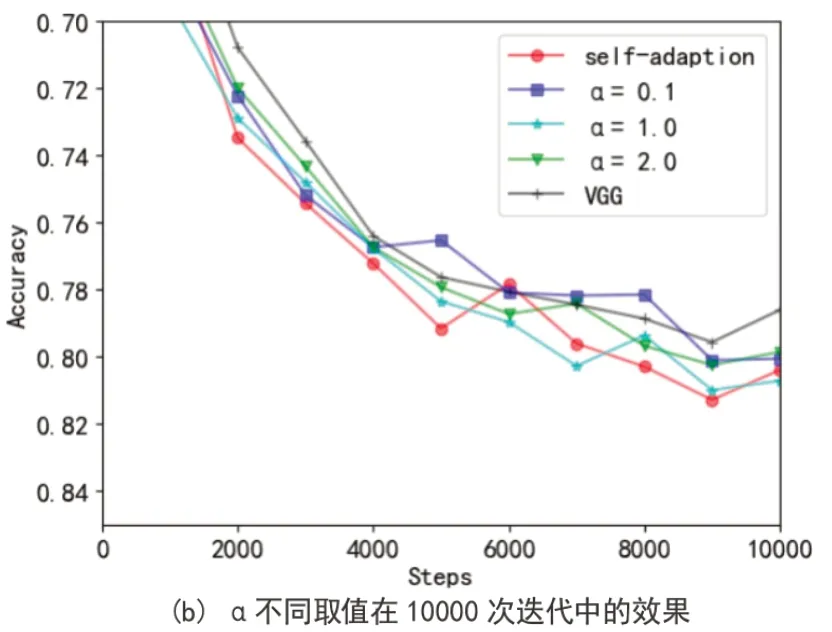
图4 准确率对比
在Resnet 的模块中我们可以看到WE 模块类似学习率下降的效果似乎很弱或者说被干扰了,这是由于其不止是一个权重还是一个梯度下降通道,这个通道会加强梯度下降步长,致使其发生这种情况,其实面对不同的需求我们还可以简单的设计不同的WE 进行操作使用,例如(WE)α,α =0,1,...,∞,值得注意的是,当α =0 时就是不加WE 模块的网络,α =1 就是我们前文中所介绍WE 模块,α 取其他值就有不同的效果,但是大致效果和α =1 时类似,α =∞时误差会趋于0,神经网络将无法优化。如图4,我们对比了几种取值的VGG 网络在CIFAR-10 数据集上的结果,如图1(a)α 取较小的值时在前期下降效果比较好,如图1(b)α 取较大值在后期效果比较好,且效果均优于原始模型,这也和我们之前分析的情况相一致,WE 模块的缩减作用随着α 的增大而增强,这种缩减不利于前期的梯度下降,但是在后期有着很稳定的效果,我们针对这种情况设计了:
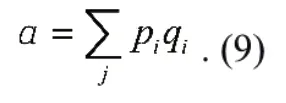
我们称之为自适应(self-adaption,SA)的方式,这样的做法可以同时具有两种好的特性,幅度可以根据情况再做调节,为了式子表示的美观,我们不再探讨对自适应模块的处理。
我们发现当作为两个通道作用时,类似学习率的效果会被大幅削弱,所以在Resnet 中仍然需要降低学习率来逼近最优效果。但是我们的算法可以压缩这个训练过程,但是由于Resnet本身在论文中的设计就有训练次数超出需要,而且需要多少步才能做到相似效果的量化难以考究,所以我们并没有对于Resnet 有过多的探讨,只要知道WE 模块对于Resnet 仍有好的加速效果即可。
2.2 MNIST
在MNIST[10]上我们对VGG 和Resnet 去除了一组降采样模块后进行了相似的运算,由于MNIST 数据集比较简单,收敛速度很快,所以我们在VGG 中令α=0.1,Resnet 中仍使用α=1 在得到了如图5 的效果,符合我们在CIFAR-10上的效果和分析。而且我们也不难发现,WE 模块对于越加复杂的数据集效果越好,α 的取值也趋向于变大,也印证了我们对于WE 的解释。
在使用WE 模块的时候要注意,整个模块需要手动编写,使用框架自带函数并将其作为权重传入,可能会导致WE 模块不会被求导,甚至可能导致收敛减速。

图5 误差对比
2.3 效果分析
我们根据得到的各组结果,将序列的十组准确率进行平均,以此来规避神经网络震荡带来的影响,发现WE 方法对于各种网络的加速效果不一,而且各有特点,但是大都和我们之前的分析相一致,即越大的越后期效果越好,越小的越前期效果越好。CIFAR-10 数据集中,在VGG 以为正则好效果明显所以可能达到60%以上的加速,表现为越后期加速效果越好;在Resnet 中最高也只有40%的加速,表现为前中期效果好,但是随着Resnet 本身也慢慢拟合,这个加速效果会被慢慢追上,在学习率改变后,WE 模块又会再次加速收敛。统计各种网络效果我们大致确定WE 模块的加速效果为10-20%。
3 总结
本文针对神经网络需要大量运算时间的弊端,考虑神经网络存在不同的训练水平,应该针对不同的状态给予适应性的训练,借此提出了一种自适应的加权误差(SAWE)模块,加快了神经网络的收敛速度。实验表明其对于神经网络有着很好的加速效果,并在多个数据集均有较好的表现。
猜你喜欢
数学物理学报(2022年1期)2022-03-16
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
当代陕西(2020年17期)2020-10-28
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
中国交通信息化(2018年5期)2018-08-21
人大建设(2018年5期)2018-08-16
