
一种基于深度学习的视网膜病变图像识别方法
2021-01-15 08:31连先峰刘志勇韩雨晨史国梅
计算机应用与软件 2021年1期
连先峰 刘志勇,2* 张 琳 韩雨晨 史国梅
1(东北师范大学信息科学与技术学院 吉林 长春 130117) 2(东北师范大学教育部数字化学习支撑技术工程研究中心 吉林 长春 130117) 3(吉林大学软件学院 吉林 长春 130012)
0 引 言
2018年,国际糖尿病联盟(IDF)发布的第8版糖尿病地图数据以及《2018—2024年中国糖尿病药物行业分析与投资决策咨询报告》显示:2017年,全球约有4.25亿人患有糖尿病,其中我国约为1.14亿,位列第一。2017年“中国糖网筛防工程”研究中心调研报告指出,我国糖尿病人群中糖网(糖尿病性视网膜)患病率为25%~47%,平均在30%左右,这也意味着中国有3 000万~3 500万人口患此疾病。研究表明,糖尿病性视网膜患者失明概率比正常人高25倍。由于发病初期眼底视网膜血管图像特征变化不明显,且存在人工识别病变图像费时费力、准确率不高、主观性强等问题,以至于该疾病的筛查率不足10%,延误了患者的最佳治疗时机。针对以上问题,我们迫切需要建立一个糖尿病性视网膜病变图像识别模型,高效且准确地识别病变图像,让患者在发病初期得到有效治疗。
从2012年至今,深度学习[1]在世界上获得突破性进展,其中图像识别成为广大专家和学者的热门研究点。李琼等[2]以Alex-Net[3]网络模型为基础,通过在每个卷积层和全连接层前引入批归一化层得到结构更复杂的卷积神经网络BN-Net。该模型将糖尿病性视网膜图像按照病变程度分为5类,准确率达到93%。但该方法在图像预处理、特征提取和图像分类3个阶段中并未形成一个完整的系统,且Alex-Net网络结构也有待进一步优化。丁蓬莉等[4]通过设计紧凑的Compact-Net网络模型,分类指标达到87%。但此网络结构对病变图像特征提取不完整,没有融合各网络层特征,且鲁棒性不高。梁平等[6]综述了基于局部病灶、全局图像的识别方法,同时分析了常用数据集、各类方法优缺点和识别性能,但并未涉及对神经网络结构的优化。曹桂铭等[7]提出了基于栈式稀疏自编码器的眼底图像特征提取及图像识别的方法,该方法采用逐层贪婪训练法从无标签的数据集中学习到数据的内部特征,将学习到的特征作为Softmax分类器的输入,识别精度达到89%。但文中数据集容量较小,使用机器学习训练出来的模型自适应性不强。何雪英等[8]采用迁移学习优化卷积神经网络结构,识别率达到91%。但迁移学习具有难于求解、容易发生过适配等问题。
针对以上问题,本文提出一种基于特征融合的深度学习图像识别方法。主要工作有以下3个方面:
(1) 构建了包含128 339幅眼底图像的数据集,数据集初始来源于5个公开眼底图像数据库,共计30 571幅眼底图像。初始数据集经扩充、统一化处理成为新的数据集。在新数据集上训练模型,使模型获得良好的鲁棒性和泛化能力。
(2) 优化了网络结构,并调整网络权重初始化的取值和学习率,提升模型的识别性能。
(3) 设置了对比实验,验证该网络模型相较于Alex-Net等常规模型,能够表现出更好的识别效果。
1 数据集与预处理
1.1 数据来源
实验所用初始数据来自一些大学以及竞赛平台,主要包含5个数据集,共计眼底图像30 571幅,其中正常图像13 615幅,病变图像16 956幅,详见表1。

表1 初始数据集
初始数据集的分辨率、颜色、格式、拍摄相机、拍摄角度等属性信息如表2所示。
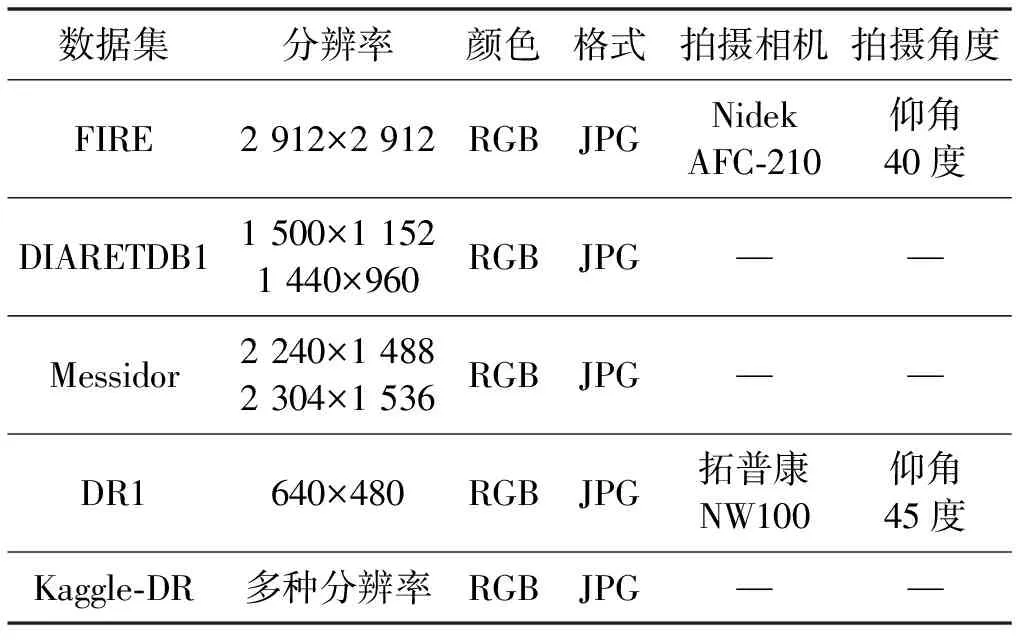
表2 初始数据集属性表
1.2 数据预处理
由于初始数据分辨率大小不一,为适应模型训练,使用OpenCV对眼底图像作统一化和增强化处理。以下为具体操作步骤:
(1) 使用OpenCV中resize()方法将眼底图像分辨率统一缩小为64×64×3。
(2) 将数据集分为两大部分,分别记为Data1和DataFinal。其中Data1占80%,向上取整约有24 457幅眼底图像,用于扩充数据集;DataFinal占20%,约6 114幅眼底图像,用于模型最终测试。
(3) 将Data1使用OpenCV中的getAffineTransform函数、getPerspectiveTransform函数和warpPerspective函数进行仿射变换,使用flip函数上下左右翻转等几种方式将数据集扩充为原来的5倍,得到新的Data1,包含122 285幅眼底图像。
(4) 将Data1分为两部分,分别记为DataTrain和DataTest。其中:DataTrain占80%,向上取整有97 828幅眼底图像,用于训练模型;DataTest占20%,共24 457幅眼底图像,用于测试模型。表3是分类后的实验数据集。

表3 实验数据集
图1是经过处理后的部分图像示例。

(a) 正常图像 (b) 病变图像 (c) 加噪图像 (d) 增强亮度图像 (e) 仿射变换图像图1 部分图像数据集
2 实验方法
2.1 反向传播算法
反向传播算法[9]是目前用来训练人工神经网络[10](Artificial Neural Network,ANN)的最常用且最有效的算法。其主要思想是:(1) 将DataTrain数据输入到ANN的输入层,经过隐藏层,最后到达输出层并输出结果;(2) 计算输出结果与真实值之间的误差,并将该误差从输出层向隐藏层反向传播,直至输入层;(3) 在反向传播的过程中,根据误差调整各种权重的值。迭代上述过程,直至收敛。
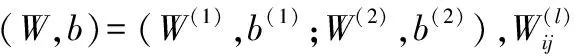
(1)
(2)
(3)
用hW,b(x)计算输出结果:
(4)
给定一个包含m个样本数据集M={(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},则神经网络整体损失函数可表示为:
(5)
式中:W、b分别表示权重参数和偏置项;λ为权重衰减因子。使用随机梯度下降算法[11]更新网络中的权重和偏置项,公式如下:
(6)
(7)
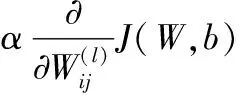
2.2 实验设计
2.2.1模型设计
鉴于VGG-16[12]网络结构规整、参数量较少、分类性能较好等特点,实验以VGG-16为基础模型,通过融合各卷积层上提取的特征,进一步优化模型。图2为改进后的网络模型。
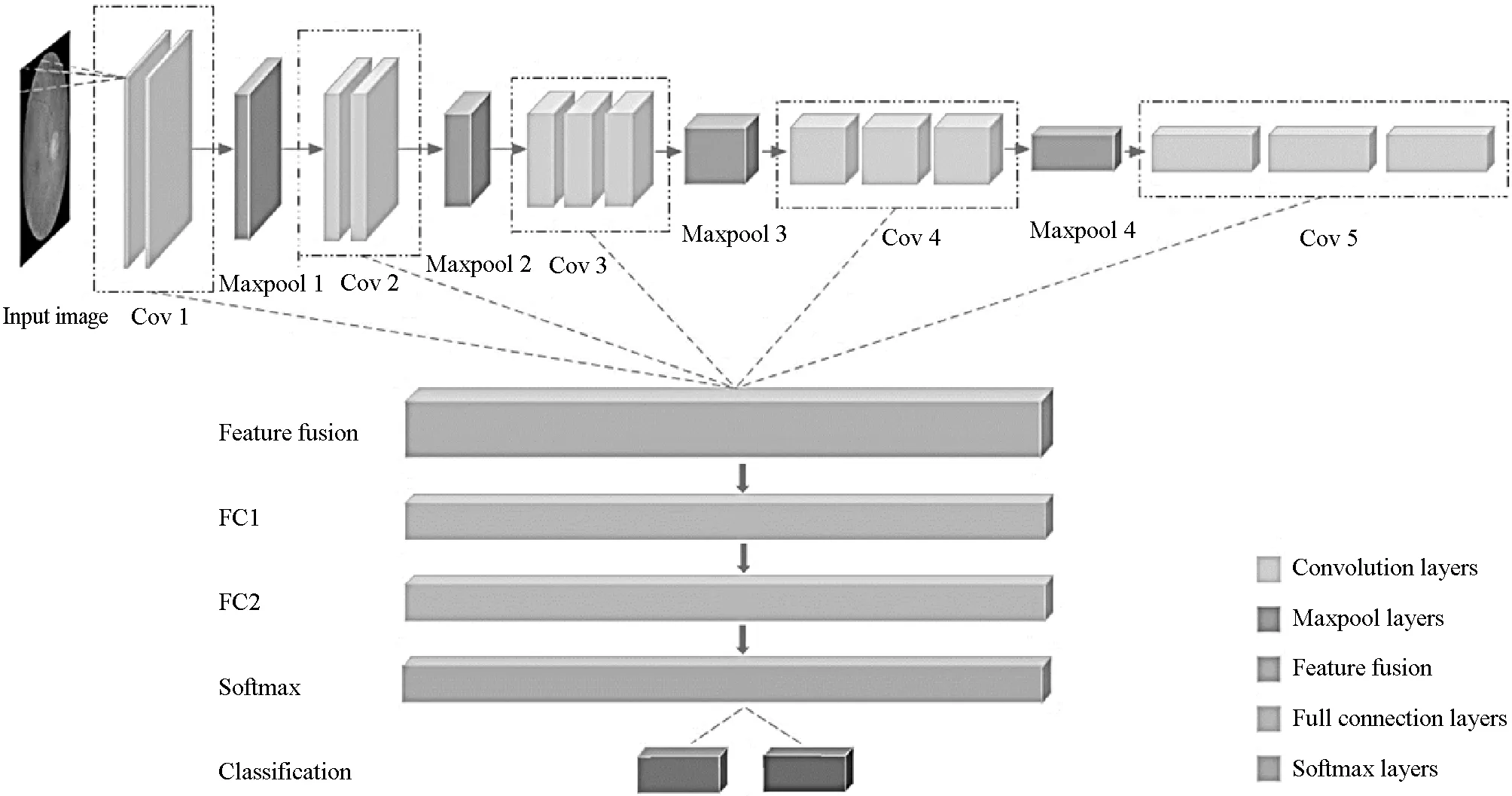
图2 优化后的实验模型
特征融合有concat和add两种方式:concat方式是将图像的通道数合并,即图像本身的特征数(通道数)增加,特征信息没有增加;add方式是将图像对应的特征信息相加,通道数不变,之后进一步执行卷积操作。由于每个输出上的卷积核各自独立,可只看单个通道的输出。给定两路通道分别记为X1,X2,…,XC和Y1,Y2,…,YC,两种特征融合方式的计算公式为:
(8)
(9)
式中:K表示卷积核;*表示卷积。由于concat相比add方式需要更多的参数,且特征融合之后生成的维度更高,计算量较大,负载重,故在二者优势相当的情况下,本实验采用add方式的特征融合。
Softmax层的分类过程表示为:
(10)
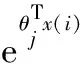
2.2.2网络参数
模型中有5个Convolution层、5个Maxpool层、1个Feature Fusion层、2个Full Connection层和1个Softmax层,输入图像大小为64×64×3。其中Cov1、Cov2、Cov3、Cov4、Cov5中的Filter个数分别为64、128、256、512、512。Filter尺寸为3×3×3,Filter stride为1。Maxpool层中Filter尺寸为2×2×3,Filter stride为2。2个Full connection层的维度分别为8 192和4 096。Softmax层的输出分为2类,分别代表正常眼底图像和病变眼底图像。表4为模型中参数变化情况。
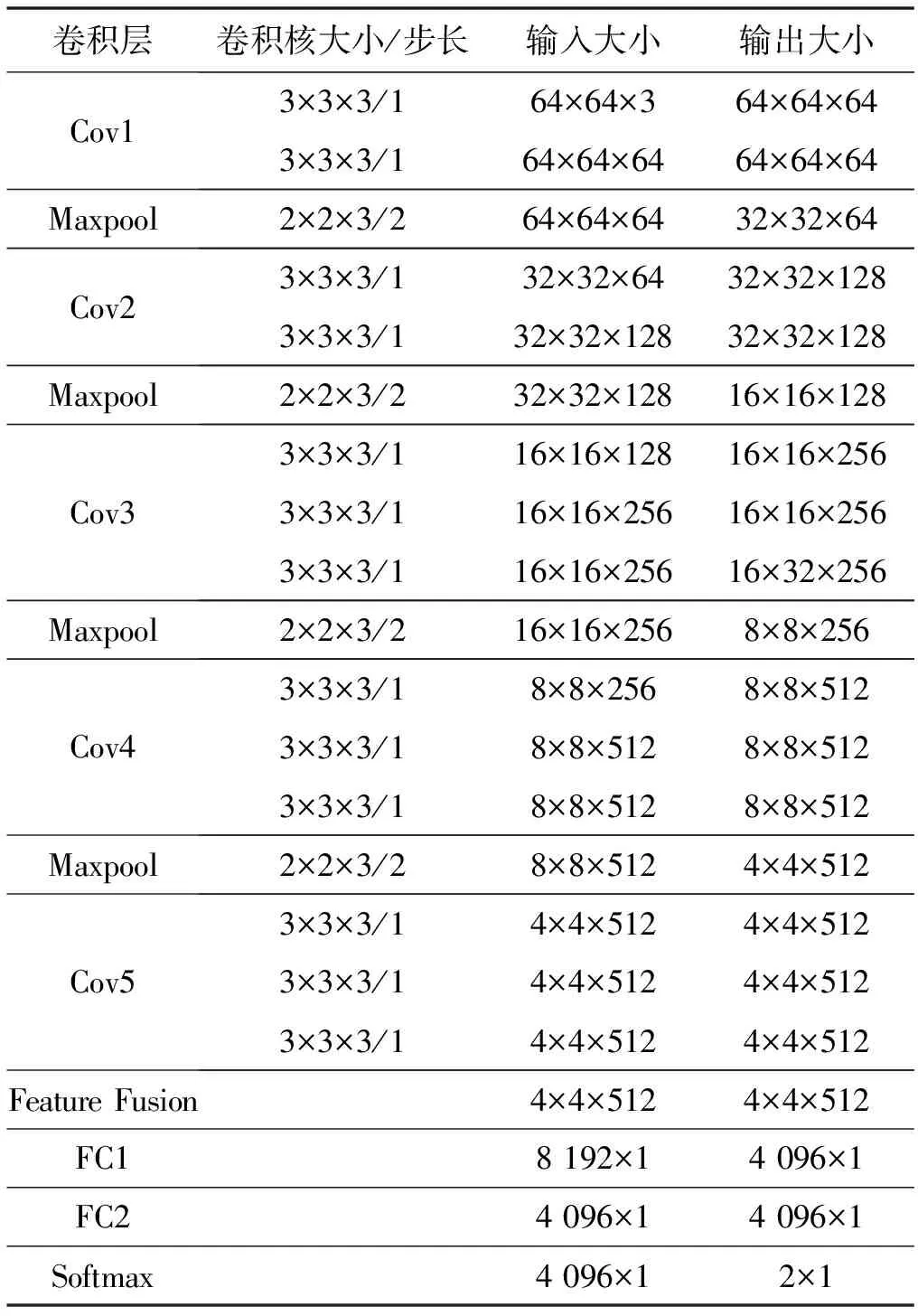
表4 实验模型参数
2.2.3模型优化设计
为防止网络模型训练过程中易出现过拟合的问题,实验采用Dropout技术[13]。Dropout的工作原理是按照一定的概率随机断开一些网络连接,保留网络层的权重。由于被断开的网络连接的输出值为0,所以该连接相当于被舍弃,达到降低模型过拟合的目的。网络计算过程如下:
Youtput=f(Xinput×Bernoulli(p)+bbias)
(11)
式中:Xinput、Youtput分别表示网络层的输入和输出;Bernoulli(p)表示以概率p随机生成的由0和1组成的向量;bbias表示偏置项。本实验模型在FC1和FC2两个全连接层上使用了Dropout技术,根据文献[13]中的结论,Dropout丢失率p的取值范围为0.10至0.50,被保留下来神经元的概率为q=1-p。实验经过多次尝试,设置p=0.30时效果最佳。
ReLU是神经网络中常用的激活函数,可以将网络层计算的线性关系转换为非线性,从而构建真正意义上的神经网络,且具有收敛快、泛化性好等特点。公式如下:
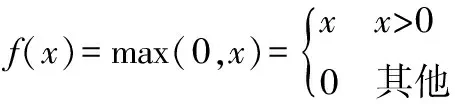
(12)
2.2.4模型训练步骤
基于VGG-16的特征融合眼底病变图像识别模型训练步骤如下:
1) 输入预处理之后分辨率为64×64×3的标准眼底图像,并初始化网络权重、偏置项和学习率值。
2) 设置1个训练样本batch的值为30,最大迭代次数为3 000次,使用随机梯度下降算法,不断更新和的值。
3) 根据反向传播算法,计算输出值与真实值之间的误差值,不断调整和的值。当迭代次数达到设置的最大次数时,训练结束。
4) 返回步骤2),循环训练模型,直到参数达到最优。
5) 将训练好的模型在眼底图像测试集上做分类测试,验证其识别效果。
2.3 模型评估标准
实验模型是将数据集分为正常眼底图像和病变眼底图像,针对二分类问题,常用的模型评估标准是F1-score。该标准由准确率precision和召回率recall通过进一步计算得到,使模型评估更加稳定、可靠。相关计算公式如下:
(13)
(14)
(15)
式中:TP表示正确分类的正样本的数量;FP表示负样本中错误标记为正样本的数量;FN表示正样本中错误标记为负样本的数量。F1-score的取值在[0,1]之间,值越大,分类效果越好。
3 实 验
3.1 实验环境
硬件配置:Inter(R) Core(TM) i7-3770 CPU@ 3.40 GHz;8 GB内存;NVIDIA GeForce GTX1060 3 GB显卡。
软件配置:Windows 10 64位操作系统;Python 3.5.6编程语言;TensorFlow 1.0[14]深度学习框架。
3.2 实验数据集
根据数据预处理的结果,用于训练、测试、最终测试模型的DataTrain、DataTest和DataFinal分别包含97 828、24 457和6 114幅眼底图像。
3.3 实验结果与分析
3.3.1Loss和Accuracy的变化情况
实验过程中设置DataTrain的每个batch的值为30,最大迭代次数为3 000次。权重的初始化服从标准差为0.01、均值为0.1的截断正态分布,避免了使用正态分布使权重出现过低或过高的情况。损失函数中权重衰减因子的值为0.1。本实验由于数据量较大,迭代次数较多,为加快损失函数的收敛速度,初始学习率为0.07。根据钟志权等[15]在左右眼图像识别中的结论,本实验使用Softmax分类器。随着迭代次数的不断增多,Loss和Accuracy的变化曲线如图3所示。
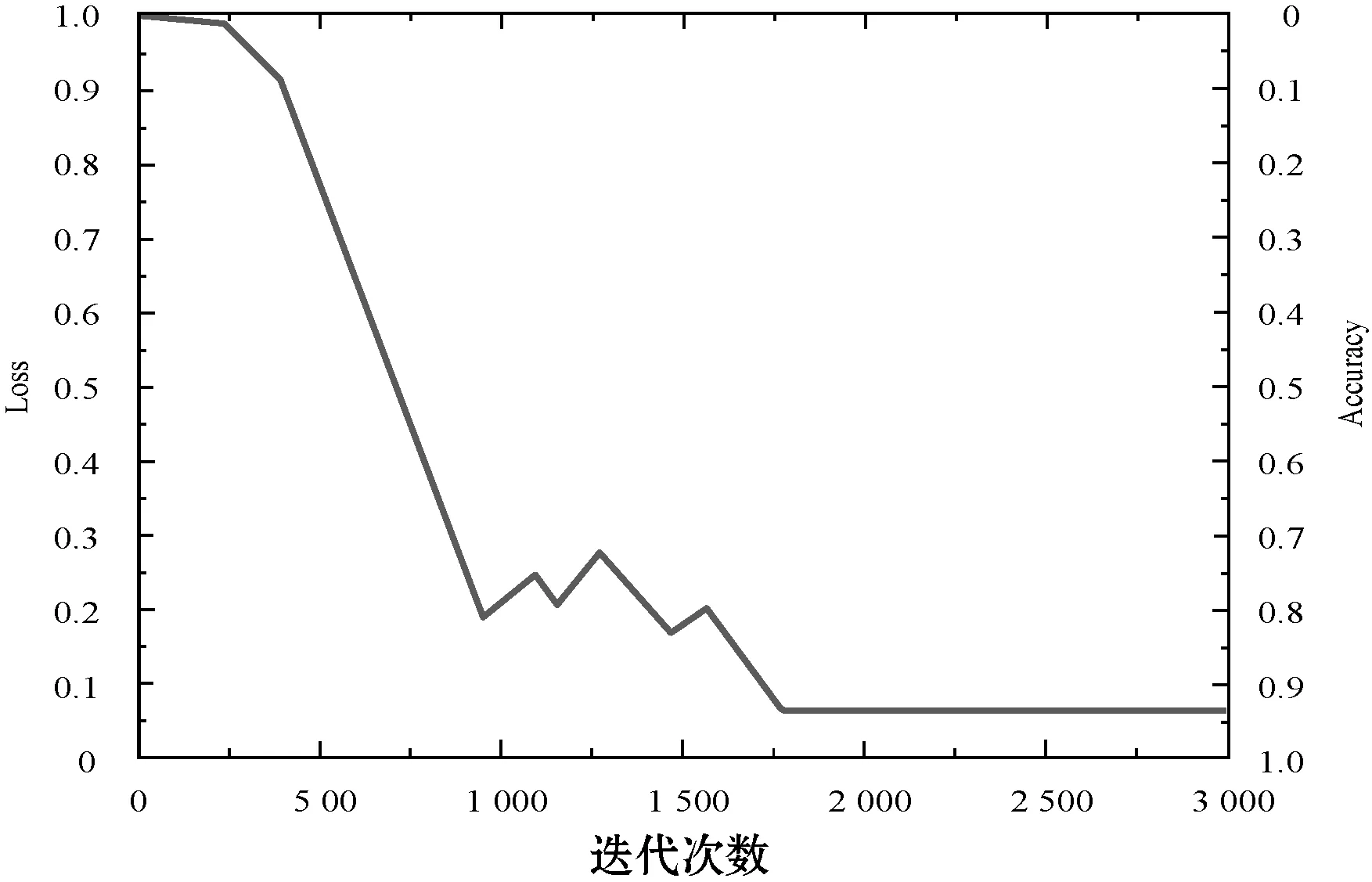
图3 Loss和Accuracy的变化曲线
当训练次数接近1 000轮时,Loss的值从1.0降至0.18,Accuracy的值由0升至0.82,变化幅度最大,这是随机梯度下降算法通过计算损失函数方向导数的值,不断寻求最快下降点的缘故。当训练次数在1 000轮和接近1 750轮之间时,Loss和Accuracy的值出现小幅度波动,其波动范围分别在[0.06,0.27]和[0.73,0.94]之间,这是随机梯度下降算法得到局部最优解造成的。当进行1 750轮训练之后,损失函数Loss的值收敛于0.06左右,Accuracy的值也稳定在0.94。以上结果表明,实验模型对图像识别的效果较为理想。
3.3.2模型对比实验
模型在数据集DataTest和DataFinal上的识别情况如表5所示。
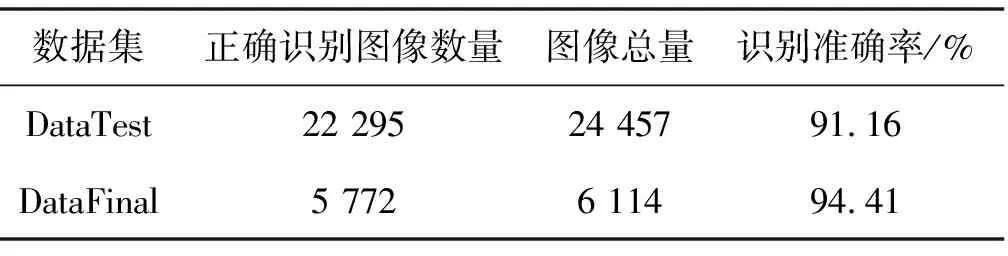
表5 模型在测试数据集上的识别情况
由表5可知,模型在DataTest和DataFinal上的识别准确率分别为91.16%和94.41%,后者相较于前者高出3.25个百分点。原因是训练模型使用的是经过5种方式扩充后的数据集DataTrain,该数据集中眼底图像特征较多,训练出的模型泛化能力更强。另外,实验通过融合各卷积层上的特征,使模型对眼底图像的细微特征更加敏感,在特征相对较少的DataFinal上识别效果更优,鲁棒性较好。
为进一步验证本实验算法的图像识别效果,设置了与Alex-Net、Google-Net[16]、ResNet-101[17]等常规算法及文献[4]中Compact-Net算法的对比实验。实验在数据集DataTest和DataFinal上F1-score的值及在两数据集上的平均准确率如表6所示。
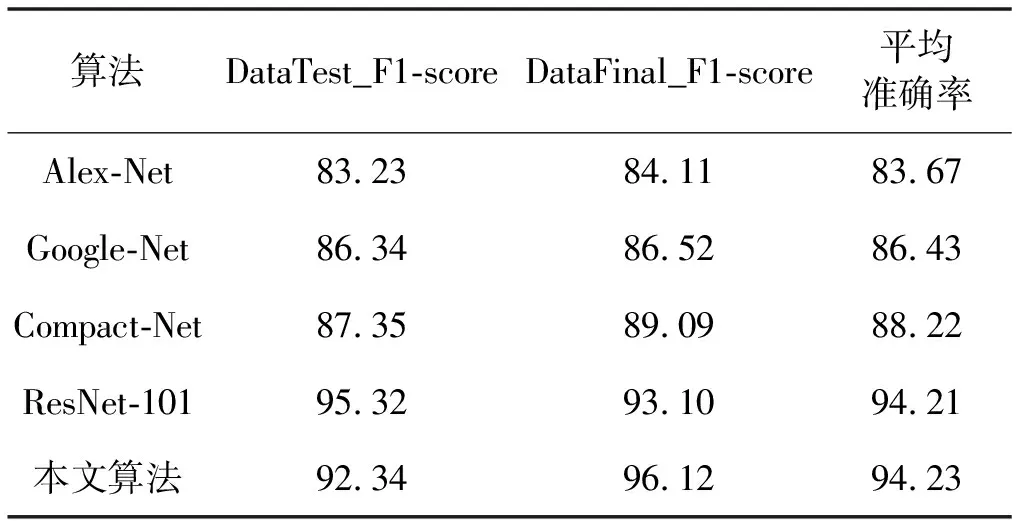
表6 不同网络模型的F1-score值对比结果 %
本文算法在DataTest上的F1-score值为92.34%,相较于Alex-Net、Google-Net、Compact-Net算法分别提高了9.11、6.00和4.99个百分点,在相同数据集的情况下,本文通过特征融合优化网络结构,增强了算法对眼底图像的特征提取能力和识别能力。在DataFinal上,本文算法的F1-score值相较于Alex-Net、Google-Net、Compact-Net、ResNet-101分别提高了12.01、9.60、7.03和3.02个百分点,表现效果最好,即在实际应用中,算法达到了预期要求。本文算法的平均准确率为94.23%,相较于其他4种算法,分别提高了10.56、7.80、6.01和0.02个百分点,验证了本文算法在对眼底图像识别上是非常有效的。
本文算法和ResNet-101的平均准确率分别为94.23%和94.21%,十分接近。原因是ResNet-101使用了101层网络结构,通常更深的网络结构,图像识别效果更好。本实验是基于VGG-16的16层网络结构,所以在DataTest下,ResNet-101的F1-score值比本文算法高出了2.98%。但本实验网络结构相对简单,参数较少,训练更快,同时说明了经过特征融合的16层网络结构达到了更深网络结构的分类效果。
本文通过实验验证了算法的鲁棒性。为保证单一变量,从DataTest中随机选取与DataFinal相同数量的眼底图像,记为DataTest*。算法在DataTest*和DataFinal上F1-score的差值(DataFinal_F1-score-DataTest*_F1-score)如表7所示。
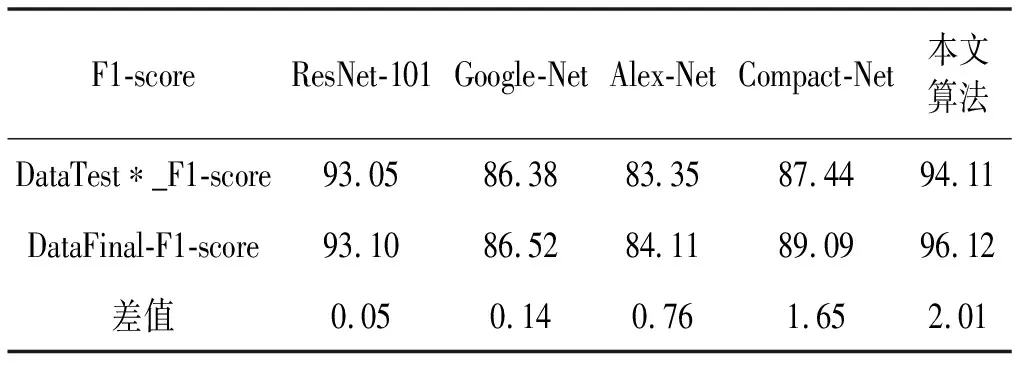
表7 算法在DataTest*和DataFinal上F1-score的差值 %
差值表示算法在测试集与原始数据集上识别效果的差异,其大小在一定程度上反映了算法鲁棒性的好坏。差值越大,鲁棒性相对越好。由表7可知,ResNet-101、Google-Net、Alex-Net、Compact-Net和本文算法的差值分别为0.05%、0.14%、0.76%、1.65%、2.01%。可以看出,本文算法的鲁棒性相对较好,ResNet-101的鲁棒性最差。
3.3.3特征可视化分析
卷积神经网络的图像特征提取过程及特征融合如图4所示。由图可知,在Cov1_1、Cov_2、Cov1_3层提取了原始图像的大部分特征信息,Cov2_1、Cov2_2和Cov2_3中只保留了原始图像的边缘轮廓。随着网络深度的不断增加,Cov3_1、Cov3_2、Cov3_3、Cov4_1、Cov4_2、Cov4_3更多地提取了图像的线条和轮廓,而Cov5_1只提取了原始图像的高阶特征信息。通过以上卷积过程可发现,不同卷积核可提取到不同的特征,网络层数越深,卷积核提取到的特征越抽象。特征融合作为全连接层FC1的输入层,融合了各卷积层上的特征。通过分析卷积神经网络的工作原理,可为以后模型的优化提供帮助。
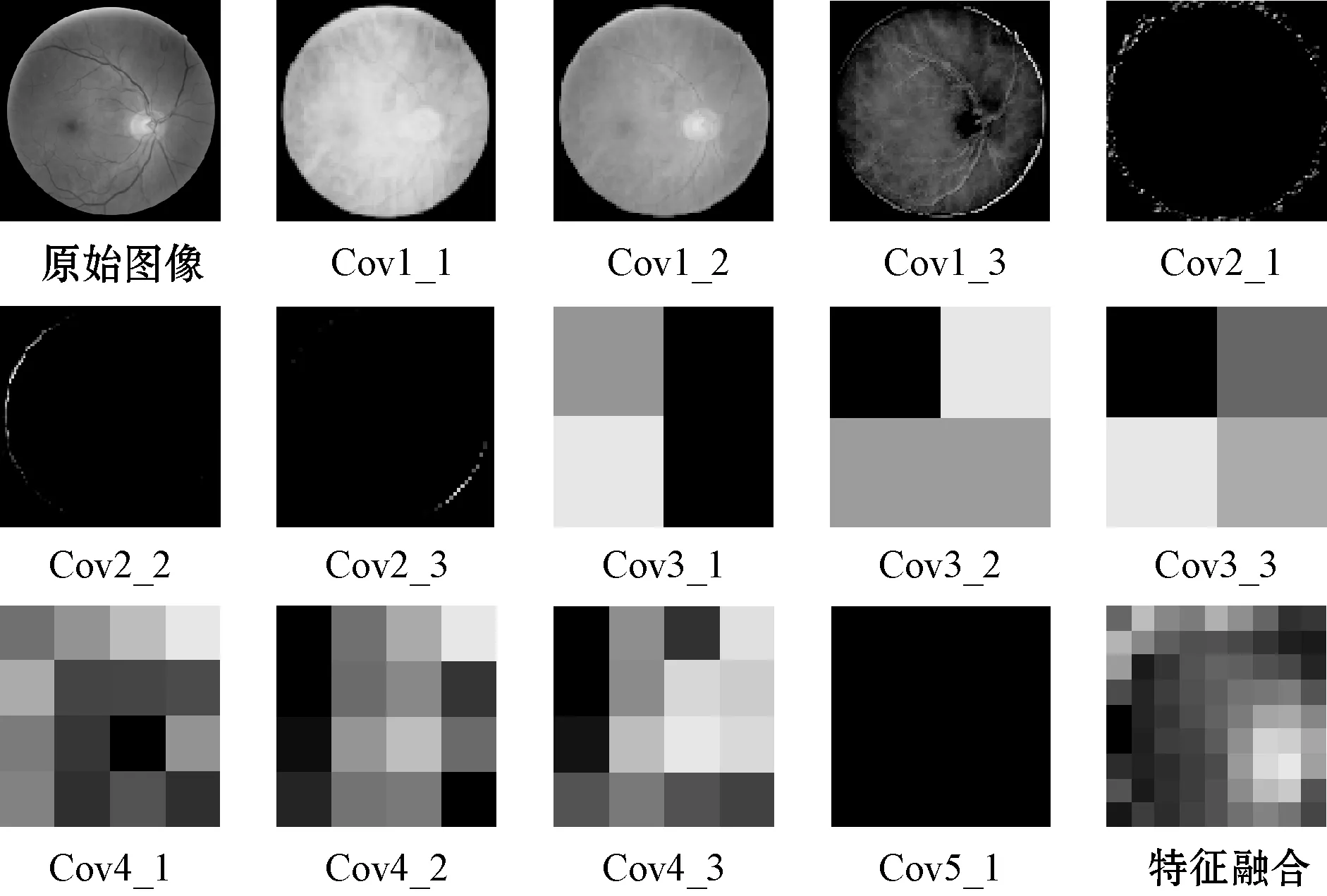
图4 卷积过程部分图像特征可视化
3.3.4图像错分类原因分析
本文算法的错误识别率在5.77%左右,部分识别错误的图像如图5所示。
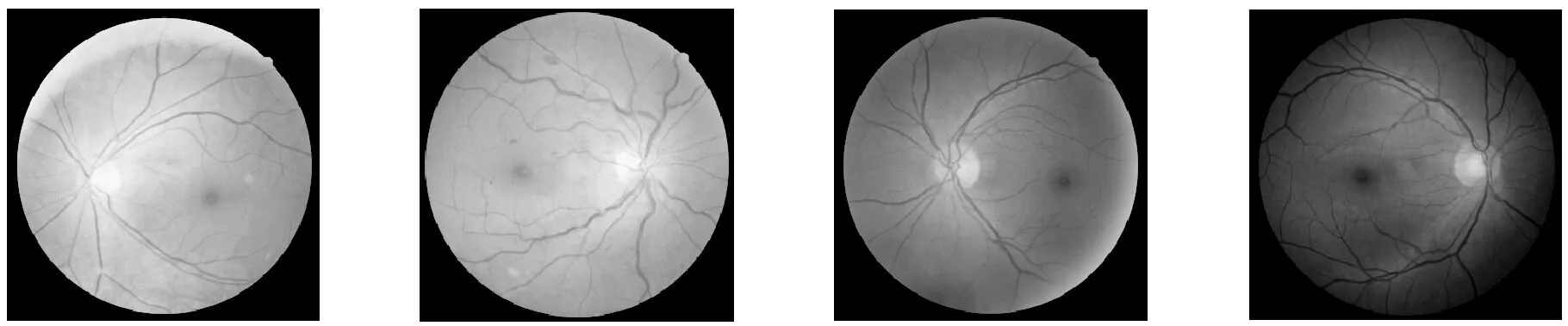
(a) 正常图像(b) 病变图像(c) 病变图像(d) 病变图像图5 眼底图像错误识别示例
图5(b)作为对比图片,是已经标注为含有血斑的病变眼底图像。图5(a)的标注为正常眼底图像,由于图像色彩的原因,算法误将图5(a)中的黄斑识别为图5(b)中的血斑,以致算法将图5(a)判定为病变眼底图像。图5(c)和图5(d)的标注为病变眼底图像,同样算法将图5(c)和图5(d)中的血斑识别为黄斑,从而将其判定为正常眼底图像。根据以上结果,图像的色彩对算法的识别过程造成了一定的干扰,致使算法识别错误。
4 结 语
本文针对糖尿病性视网膜发病初期特征不明显、人工识别病变图像困难、准确率不高等问题,提出了一种基于卷积神经网络的眼底图像识别方法。该方法在VGG-16网络结构的基础上,通过融合各卷积层上的特征,使模型对病变眼底图像的细微特征更加敏感。为了进一步优化模型,使用ReLU函数加快网络中参数的收敛,并在两个全连接层上使用Dropout技术,使模型识别图像的平均准确率达到94.23%,与常规算法Alex-net、Google-net、Resnet-101和文献[4]中Compact-net方法相比,分别提高了10.56%、7.80%、0.02%和6.01%,验证了该方法的有效性。
由于实验数据集使用的是RGB格式的图像,以致色彩对图像识别造成了一定的影响。下一阶段的工作是对眼底图像数据做二值灰度处理,并根据眼底图像病变的程度划分不同的等级,做更加细致的分类;使用基于判别区域的网络结构算法,进一步提高模型识别准确率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
国际商业技术(2022年4期)2022-04-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
数码世界(2019年6期)2019-09-09
中国信息技术教育(2016年21期)2016-12-05
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
