
跨语言多任务学习深层神经网络在蒙汉机器翻译的应用
2021-01-15 08:22苏依拉仁庆道尔吉王宇飞
计算机应用与软件 2021年1期
张 振 苏依拉 仁庆道尔吉 高 芬 王宇飞
(内蒙古工业大学信息工程学院 内蒙古 呼和浩特 010080)
0 引 言
机器翻译是人工智能领域的重要研究课题之一,主要目标是研究如何使用计算机实现一种自然语言到另一种自然语言的自动转换。近年来,已经有很多研究尝试将深度神经网络的方法扩展到低资源语言对上,但因缺乏数以百万计甚至更多的平行句对而无法获得理想的结果。因此,如何用半监督学习无标记数据、多任务联合训练来缓解资源匮乏的问题成为近来神经机器翻译的一个重要研究方向。
目前,深度学习在自然语言处理中的困境之一是缺少大规模的标注数据。解决深度学习目前缺少大规模的标注数据这一困难的方法主要有两种:无监督预训练方法和多任务学习联合训练多个任务。
2018年发表的文献[1]提出了ELMo模型,介绍了一种新型深度语境化词表征,可对词使用的语法、时态、语态和语义等多个特征和词使用在上下文语境关联程度中的变化进行建模。ELMo中的词向量是在一个大型文本语料库中预训练而成。文献[2]提出了GPT模型,使用无监督预训练和监督微调的组合探索了用于语言理解任务的半监督方法。谷歌Brain团队提出的BERT[3]在GPT模型的基础上进行了修改,取得了很好的效果。
多任务学习[4](MTL)联合训练看起来相似的多个任务,能够通过单个模型解决协同任务。它通过将相关任务中训练信号所包含的域信息用作归纳偏差来提高泛化程度,在使用共享表示的同时并行学习任务来实现这一点,每项任务的学习内容可以帮助其更好地学习其他任务。
2017年,Google提出了一个多模型架构,混合编码输入与先前输出的混合器(自回归部分),以及处理输入和混合以产生新输出的解码器[5]。同年,Johnson等[6]提出了一种使用单个神经机器翻译(NMT)模型在多种语言之间进行翻译的解决方案。2018年,Kiperwasser等[7]提出的模型令语法和翻译交错学习,然后逐渐将更多的注意力放在翻译上。预训练的一个优点单词嵌入是词汇表外(OOV)单词的表示。
蒙汉平行语料资料目前处于匮乏阶段,如何利用有限的语料数据缓解资源不足问题已经成为神经机器翻译的一个重要的研究课题。然而蒙汉机器翻译研究工作仍处于探索阶段,成熟多样的蒙汉机器翻译以及采用前沿机器翻译方法的模型和成果相对较少。
针对蒙汉平行语料资源比较稀缺和现有的平行语料数据的覆盖面少等困难导致的蒙汉翻译质量不佳的问题,本文采用跨语言多任务学习的方式对机器翻译建模,并引入了两种新的无监督预训练方法和一种监督预训练的方法,用于使用跨语言建模来学习跨语言表示,并研究三种语言预训练方法在蒙汉翻译中的效果。
1 跨语言多任务预训练模型
本文引入三种语言预训练模型:蒙面语言模型(Masked Language Model,MLM),因果推理语言模型(CLM)和基于平行语料的翻译语言模型[8](TLM)。其中,MLM和CLM模型使用的是基于单语数据的无监督训练方式,而TLM是基于平行标记数据的有监督训练方式。
1.1 蒙面语言模型(MLM)
模型架构是一个多层双向Transformer编码器,与BERT的输入单个文本句子或一对文本句子的输入表示方法不同,MLM的输入文本是任意长度的单语文本,每个句子用分隔,如图1所示。MLM输入表示由句子唯一标识符En(n取整数,n∈[1,N],N表示需要预训练的总句子数量)、位置信息编码和Masked蒙面处理后的句子向量组成。
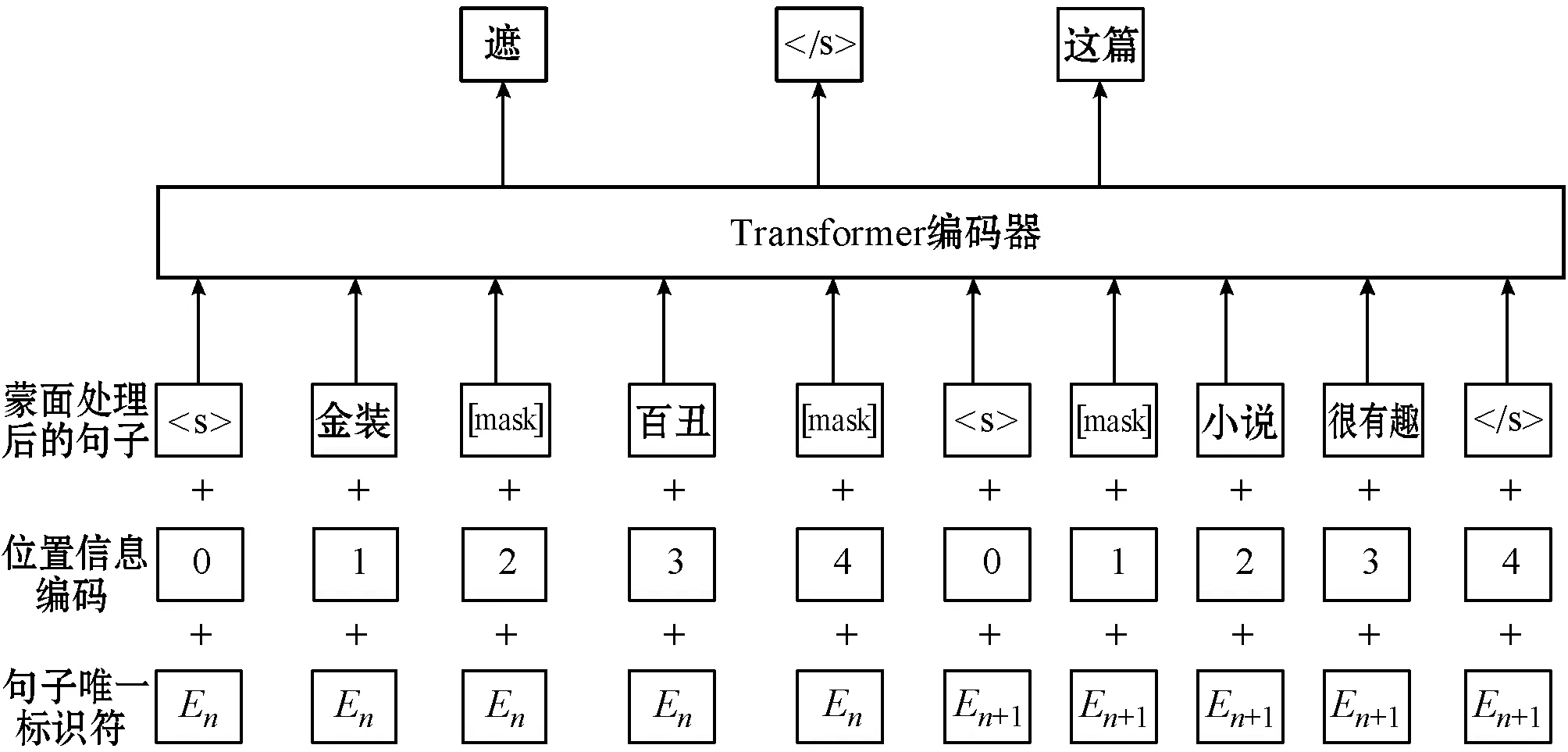
图1 蒙面语言模型的结构模型
理论上,深度双向训练Transformer模型比从前向后或从后向前地对输入序列进行预训练会学习到更多有用的特征。但是,双向训练模型将导致每个单词在多个层的上下文向量中间接地找到自身的向量表示。
为了避免出现上述的情况发生,本文模型依据一定的比例随机地对句子的若干位置进行蒙面操作。为了提高模型的健壮性,受到去噪编码器[9]增加无关的干扰信息作为噪声输入,本文对蒙面语言模型增加了一项内容,并不总是用[mask]这个标记符号替换要“蒙面”操作的字符,按照十分之一的比例用噪声作为“蒙面”的另一种随机符号,但是实验结果显示,这样的设计方式会降低模型的准确表达能力。受到对抗学习的启发,本文又按照十分之一的比例用未经过“蒙面”的单词自身作为假“蒙面”标记,即不对“蒙面”位置的字符做任何改变。实验结果显示,这种加入噪声和对抗性的训练机制可以有效提高模型预测的能力,提高模型的健壮性。
1.2 因果推理语言模型(CLM)
模型架构是一个Transformer-XL模型(超出固定长度的注意语言模型)[9],它使Transformer能够在不中断时间序列连贯性关系的情况下学习可变长度的依赖性关系。Transformer-XL模型由段落级循环复现机制和新颖的位置编码方案在Transformer上改进完成。基于Transformer-XL的蒙汉翻译上的预训练模型可以更好地学习序列之间的长期依赖性关系,而且还可以解决上下文碎片化问题,即解决上下文连贯性中断的现象。因此,将提出的基于Transformer-XL的预训练模型命名为因果推理语言模型。Transformer-XL学习序列的依赖性关系比循环神经网络RNN更长,是RNN学习到的依赖性关系的1.8倍,是vanilla Transformer学习到的依赖性关系的4.5倍。
1.2.1段落级循环复现机制
Transformer-XL将循环的机制引入深层的自我注意力机制网络。它的一个重要的改变是每个隐藏层的状态不再从头开始计算每个新段落的隐藏状态,而是复用在之前计算的段落中获得的隐藏状态。也可以这样理解,隐藏状态不再仅仅是一个纯计算用的中间函数,它具备了简单的存储功能,可复用的隐藏状态作为当前状态的存储器可随时被调用,所以重用的隐藏状态可以在段之间建立重复连接,如图2所示。一方面,Transformer-XL模型可以建立非常长距离的依赖关系,因为它的复用隐藏状态的机制可以允许信息通过循环连接传播。另一方面,这种信息传递机制也可以帮助Transformer解决上下文碎片化的问题,使得上下文更加连贯。
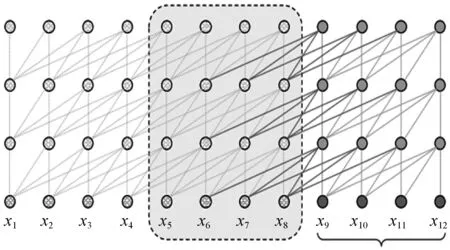
图2 段级长度为4的Transformer-XL模型的结构模型
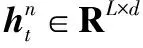
(1)
查询向量、键向量、值向量组成的向量计算如下:
(2)
自注意力机制和前向传播:
(3)
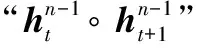
1.2.2相对位置编码方案
隐藏状态的复用机制存在一个关键问题:当重用隐藏状态信息时,如何保持位置信息的一致性。在标准的Transformer中,序列顺序的排列信息用一组位置编码层嵌入到输入层,表示为U∈RLmax×d,其中第i行的Ui对应于段内的第i个绝对位置。Lmax规定了要建模的最大可能长度。如果直接把这种位置编码方案应用到1.2.1节的循环复用隐藏层机制中,隐藏状态序列的计算方式如下:
hτ+1=f(hτ,Esτ+1+U1:L)
hτ=f(hτ-1,Esτ+U1:L)
式中:Esτ∈RL×d是sτ的字嵌入序列;f表示变换函数。注意Esτ和Esτ+1都与相同的位置编码U1:L相关联。结果对于任何j=1,2,…,L,模型没有信息可以区分xτ,j和xτ+1,j之间的位置差异,这会导致明显的性能损失。
为了避免这种失败模式,仅对隐藏状态中的相对位置信息进行编码。理论上,位置编码为模型提供了输入文本序列先后顺序信息并提供给神经网络加以训练。出于同样目的,不将偏差静态地结合到初始嵌入中,而可以将相同的信息注入到每层的注意分值中。以相对方式定义时间偏差更直观和通用。例如:当查询向量qt,i参与关键向量kt,≤i时,无须知道每个关键向量的绝对位置以识别该段的时间顺序;相反,查询向量知道每个键Key向量kt,j与其自身的向量qt,i之间的相对距离就足够了,即i-j。实际上,可以创建一组相对位置编码R∈RLmax×d,其中第i行Ri表示两个位置之间的i的相对距离。通过将相对距离动态地注入注意力分值,查询向量可以很容易地从不同的距离区分xt,j和xt+1,j的表示,使得状态重用机制可行。加入改进后的位置编码方案的注意力计算公式如下:
uTWk,EExj+vTWk,RRi-j
(4)
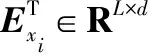
1.3 翻译语言模型(TLM)
MLM和CLM的处理对象都是单语数据。因此上述两种模型都是无监督的预训练方式。为了方便预训练系统利用并行数据,本文引入了一种新的翻译语言模型(TLM),用于改进跨语言预训练。翻译语言模型是MLM的改进,其不是输入单语言文本序列,而是同时输入平行语料库中句子序列,如图3所示。本文提出的TLM模型随机地对源语言语句和目标语言语句进行蒙面处理。考虑到充分利用平行语料库中的句子的语义相同等内在联系,模型用MUSE工具对齐蒙古文和汉文的向量表示。这种处理方式的优势在于如果蒙语语境无法充分地推理预测出蒙面的蒙文单词,则该模型可以利用汉语的上下文语境,反之亦然。
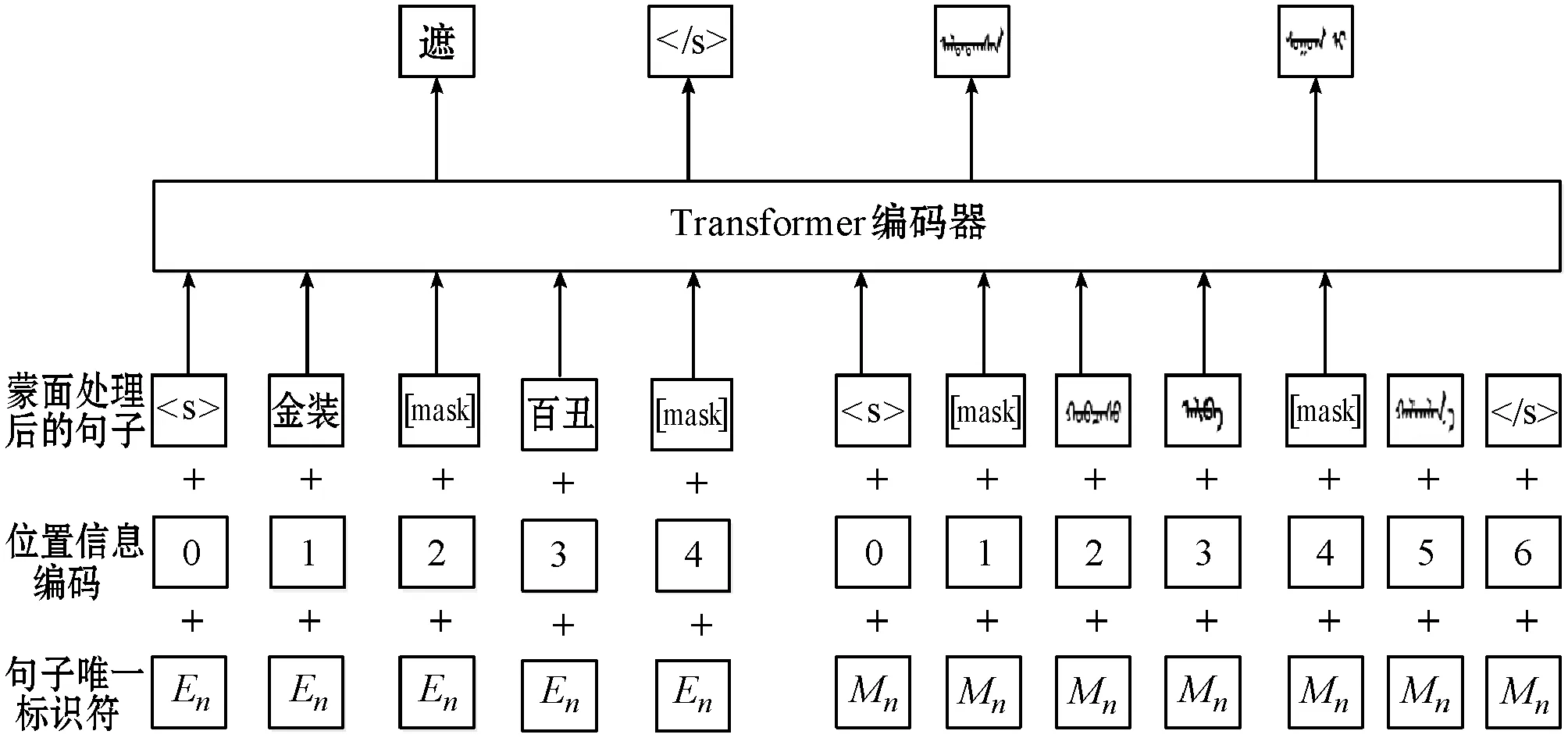
图3 翻译语言模型的结构模型
2 预训练模型在蒙汉翻译中的应用
2.1 数据预处理
本文使用126万句蒙汉平行语料库和3万余条专有名词词典作为翻译对象。其中126万蒙汉平行语料库涵盖政府工作报告、日常对话、新闻、法律条文和小说等多种蒙-汉平行语句对。3万余条专有名词词典涵盖人名、地名、物理、化学和生物等学科领域名词等专有名词,一方面扩大了平行语料库的规模;另一方面,因为126万句蒙汉平行语料库中缺少一些不常用的生僻字词,所以引入专有名词作为基础的平行语料库之外的附加词典库可以方便解码器解码时对未登录词进行近似替换。对于中文和蒙文,分别使用文献[10]提出的标记器和Kytea标记器。
2.2 预训练模型和翻译模型的构建
第1节中介绍的MLM、CLM和TLM可以分别作为蒙汉翻译模型的预训练模型,用于编码器或解码器的初始化节点。本文的翻译模型采用具有循环因果推理机制的Transformer-XL模型。在本文的所有实验中,都使用210个隐藏单元、8个注意力头和6层编码器-解码器模型的基础Transformer架构。Transformer-XL模型的N层编码器-解码器计算程序如式(5)-式(8)所示,代表了一个注意力头所做的计算工作。段落间的上下文向量、查询向量、键向量、值向量计算同式(1)-式(2)。
相对位置注意力计算:
(5)
(6)
(7)
(8)
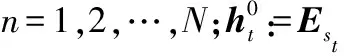
2.3 实验结果和分析
对于编码器和解码器的初始化,为了对上面的预训练模型在蒙汉翻译上的效果进行对比,采用不同的方法进行初始化:蒙面预训练(MLM)、因果推理预训练(CLM)或随机初始化,这三种组合需要9组实验。在模型中使用基于去噪自动编码的损失函数和基于在线反向翻译的损失函数来训练模型。训练结果的数据见表1。
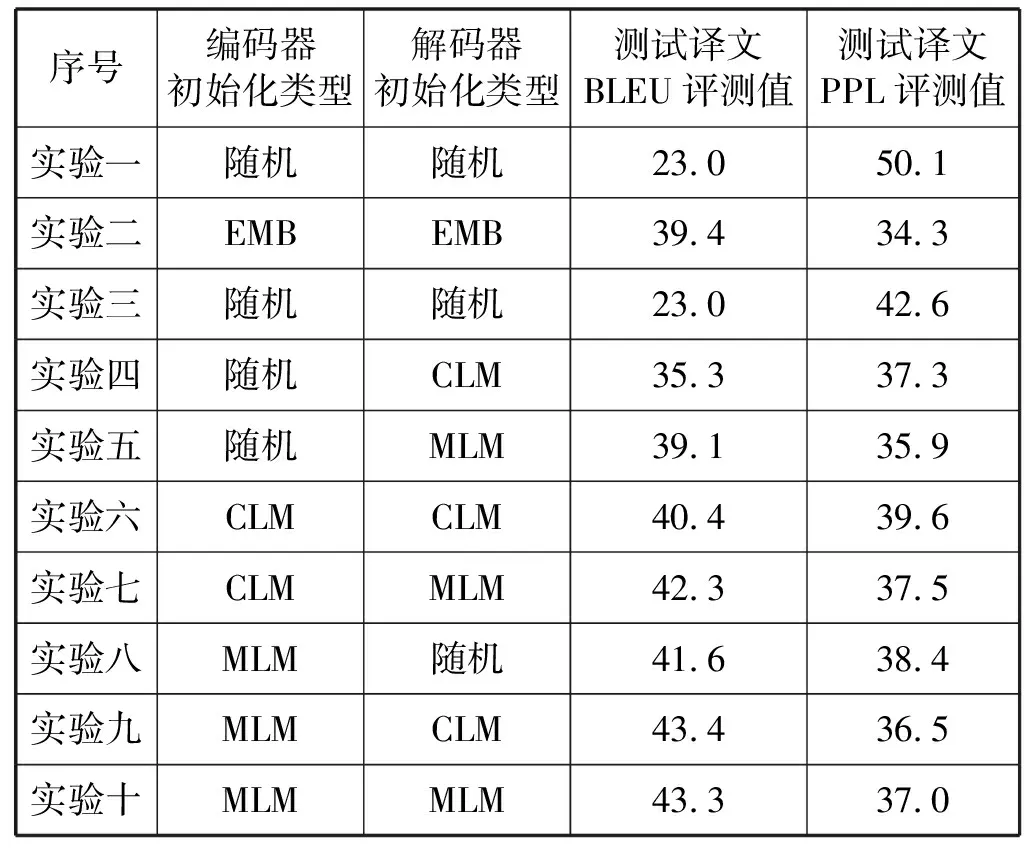
表1 多种初始化方式用于翻译模型的对比分析结果
表1中:“EMB”表示使用跨语言嵌入向量预训练的方式引入查找表对编码器和解码器进行初始化表示;PPL表示语义困惑度;“随机”就是对编码器-解码器的初始参数随机初始化表示。
令编码器-解码器参数矩阵随机初始化作为翻译的基线模型。实验结果表明,使用跨语言嵌入向量预训练的方式引入查找表对编码器和解码器进行初始化表示,比基线模型的测试译文BLEU值评估提高了6.4,在解码器中用CLM初始化比基线模型的测试译文BLEU值提高了12.3,在同样条件下,使用MLM模型比CLM模型预训练效果好一些。但是,使用MLM对编码器初始化,同时使用CLM模型对解码器进行初始化得到了目前对比实验中的最高BLEU值,比随机初始化的基线模型提高了21.4。可以看出语义困惑度PPL的值和BLEU值的大小成反比例关系。MLM初始化编码器参数和CLM初始化接麦器参数的语义困惑度比统一使用MLM初始化编码器和解码器参数的方式虽然只提高0.1的BLEU值,但是PPL的值相对降低0.5,说明因果推理模型对序列中的历史信息进行了有效的记忆,在一定程度上有效地提高了翻译质量。
3 结 语
本文针对蒙汉平行语料资源比较稀缺和现有的平行语料数据的覆盖面少等困难导致的蒙汉翻译质量不佳的问题,采用跨语言多任务学习的方式对机器翻译建模。本文在数据预处理阶段,引入了两种新的无监督预训练和一种监督预训练的方法,用于跨语言建模来学习跨语言表示,并研究三种语言预训练方法在蒙汉翻译中的效果。实验结果表明,上述三种跨语言预训练的模型可以显著降低低资源语言的困惑度,提高蒙汉翻译质量,蒙面预训练模型初始化编码器参数和因果推理语言模型初始化解码器参数的方案可以显著提高翻译质量,比随机初始化参数的BLEU值提高了20.4,同时语义困惑度能降低了13.6。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
凤凰动漫(军事大王)(2022年3期)2022-06-17
传感器世界(2022年3期)2022-05-24
科普童话·神秘大侦探(2021年10期)2021-09-15
数字技术与应用(2021年1期)2021-03-24
现代信息科技(2019年18期)2019-09-10
科技创新与应用(2017年26期)2017-09-12
中国信息技术教育(2016年13期)2016-09-10
电脑爱好者(2015年24期)2015-09-10
