
基于BERT和GCN的引文推荐模型
2021-01-15 08:31查云杰
计算机应用与软件 2021年1期
查云杰 汪 洋
1(南京烽火天地通信科技有限公司 江苏 南京 210000) 2(武汉邮电科学研究院 湖北 武汉 430074) 3(南京烽火星空通信发展有限公司 江苏 南京 210000)
0 引 言
随着科学论文发表数量的巨大增长,在撰写科学论文的同时寻找参考文献并标注是一个繁琐的过程,研究根据上下文在句中适当位置添加引用的技术是很有实用价值的。上下文感知引文推荐的研究已有近20年,许多研究者利用围绕引文标签的文本数据,即上下文句子,以及目标论文的元数据来寻找合适的被引文献。然而,由于缺乏良好的基准数据集和高性能的模型,使得该技术的研究进展缓慢。
He等[2]在第19届万维网国际会议上提出一种解决方案,通过占位符自动找到被引用的信息,即引文周围的文本可以用作占位符,称为“上下文感知的引用推荐”,占位符两边的句子称为“上下文”。上下文感知的引文推荐任务是一种监督分类,可根据内容选择合适的论文作为占位符。除了上下文,它还考虑了科学文献的特征,使用了作者、标题、引文和期刊(或会议名称)等,这些都是科学论文的元数据或文献计量学[2-6]。近年来,使用深度神经网络来解决此类问题的尝试越来越多[7-9]。
解决该问题最棘手的一个方面是没有可以用来衡量适当性能的基准数据集。通常,该任务需要使用元数据以及围绕所引用论文的上下文。在常用数据中,ACL Anthology Network(AAN)数据集不提供预处理后的论文句子和元数据,DBLP数据集只提供书目信息。在文献[7]中,CiteseerX数据集只提供上下文和引文信息,没有同时提供元信息。因此,相关研究未能使用相同的基准数据集。
本文研究目的是提供一种适合上下文感知的论文推荐任务研究的数据集和现状模型,进而为研究者提供一个改进的论文写作环境。主要工作如下:首先,为该任务构建可重复的基准数据集,并对现有的AAN数据集进行预处理[10-11],为了适应这一任务,修改PeerRead[12]构建新的数据集PeerReadPlus。其次,使用BERT[1]和图卷积网络(Graph Convolution Networks,GCN)[13]构建任务模型。由于科学论文包含文本内容数据和可以表示为图形的元数据,因此使用BERT进行自然语言处理。最后,通过实验分析了影响任务效率的各种因素。
1 建立数据集
1.1 数据集概述
本文通过修改现有数据集为上下文感知的引文推荐任务构造了新的数据集AAN[10]和PeerReadPlus,这是PeerRead数据集[12]的扩展。AAN和PeerRead数据集具有组织良好的书目计量信息,PeerRead数据集主要提供顶级会议论文的同行评审,以及文献计量信息。由于这两个数据集都缺少引用上下文中的信息,所以这里的重点是使用元数据收集上下文信息,因此,需要重新处理AAN和PeerRead数据集来创建数据集。
1.2 数据采集
本文使用arXiv Vanity创建新的数据集。arXiv Vanity是一个可将基于LaTeX的PDF文件转换为HTML文档的站点。我们的目标是提取引文符号两侧的上下文信息,以及参考文献信息。为此,通过arXiv Vanity将LaTeX解析为HTML,并使用正则表达式来匹配识别文档中的引用符号,然后将引文符号两侧的句子存储在一个包含参考文献信息的数据库中,把收集到的信息与现有元数据一起存储,并将其构建到新的数据库中。
由于LaTeX文档的格式不一致,实际收集的数据是有噪声的。在自动收集了必要的数据后,手动删除噪声数据。例如CiteSeerX库中的文献,与占位符对应的引用符号将留在上下文中,同时提供数据。占位符文本本身用于过度拟合学习,因此可以用来告诉正确的答案,即占位符可以作为预测的重要因素。
1.3 静态数据集
构建的数据集的静态数据如表1所示。所提取的数据集比原始的AAN或PeerRead数据集的数量要少,因为需要去除不使用LaTeX或使用arXiv Vanity处理时噪声很大的.pdf文件。表1中,总论文指的是不包括重复论文在内的基础论文和被引论文的总数,基础论文是引用了其他研究的论文,论文的元数据信息作为分类任务的输入。另外,提取了引文符号两侧的段落单位,引用上下文是指提取的段落中句子数量的总和。
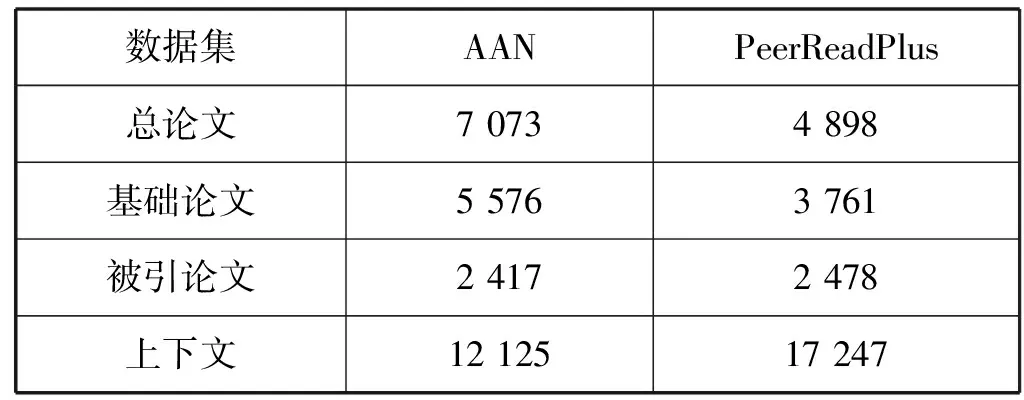
表1 数据集内容
2 BERT-GCN模型
2.1 模型概述
这里使用BERT[1]和GCN[14]构建上下文感知的引文推荐模型。BERT是NLP学习表示中性能最好的预训练模型之一,本文通过预先训练的BERT 来实现上下文句子的学习呈现。除了文本数据之外,论文还包含各种元数据。本文使用GCN模型来表示论文之间的引用关系,并提取论文的学习表示。
如图1所示,本文构造了一个上下文编码器来提取文本嵌入,使用BERT以及一个引文编码器来从GCN提取图形嵌入。利用上下文数据对每个编码器进行预训练,并从文中提取引文图数据。然后将数据插入预训练的模型中,并由每个编码器计算连接的嵌入。最后,将连接后的向量传递给前馈神经网络(简称FFNN),生成Softmax输出层,并采用交叉熵作为损失函数进行训练。
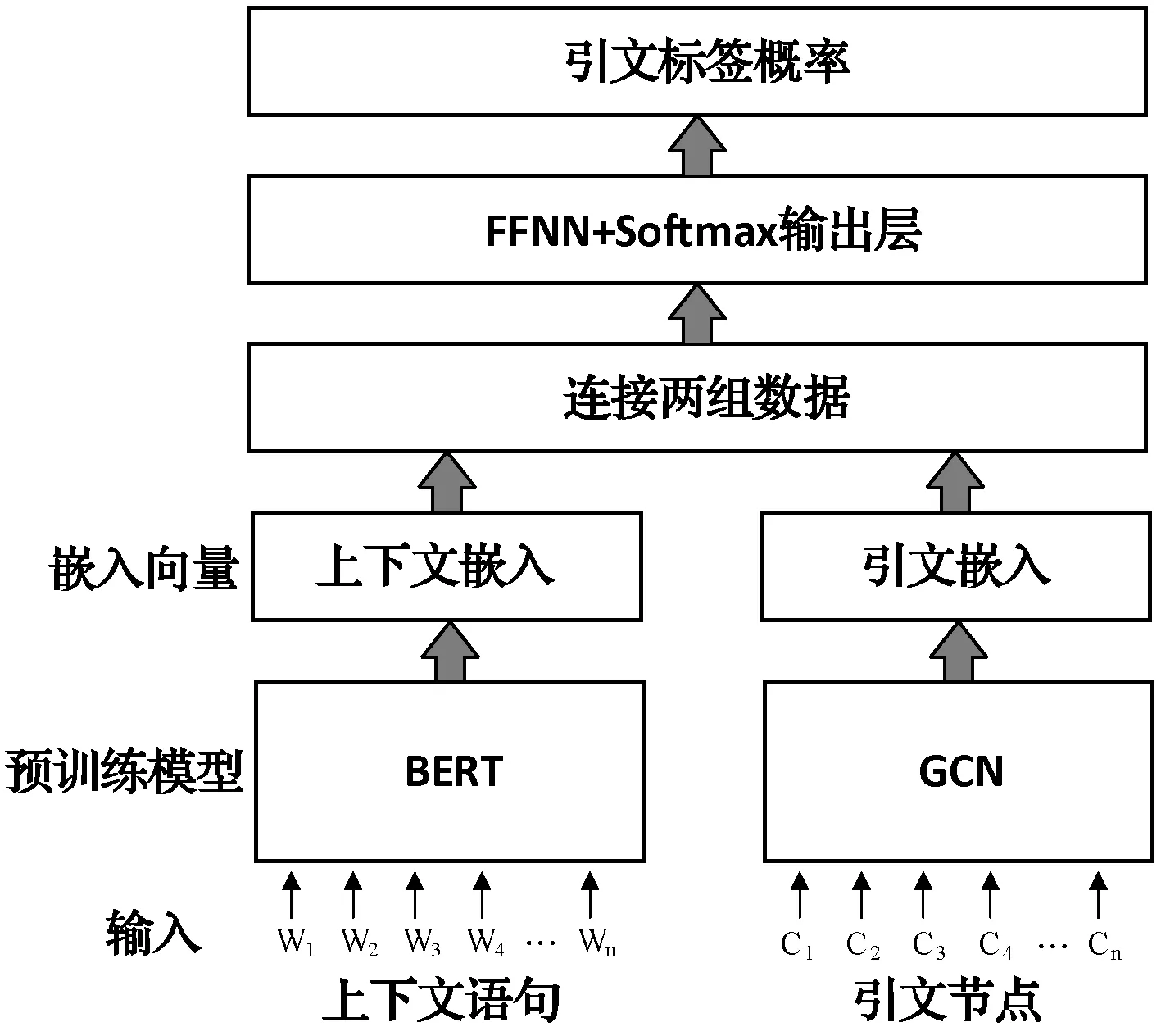
图1 BERT+GCN模型架构
该模型的结构与基准CACR[9]相关。CACR同时具有论文编码器和引文上下文编码器,使用AAN数据集和LSTM模型演示了SOTA作为最新的上下文感知引文推荐模型的性能,它通过作者、地点和论文的抽象信息构造了一个论文文本编码器,本文模型仅利用引文信息构建了基于GCN的引文编码器。
2.2 引文编码器
引文编码器对引文进行无监督学习,将预测与基于GCN的变分图自动编码器(VGAE)模型[13]相连接,利用论文之间的引文关系作为输入值。当将论文信息作为预处理的GCN的输入时,该模型将关系学习表示作为嵌入向量返回。VGAE可以捕获图形数据的潜在学习表示。
在现有的研究中,如何表达一篇论文的引文关系一直是个难题,因为Doc2Vec[15]在嵌入了对单个元信息的学习之后,被用来对论文信息进行编码和总结。本文的引文编码器通过使用引文链接预测信息作为引文预测功能来解决这个问题。
2.3 图卷积网络层
本模型中,GCN层的作用是通过卷积网络抽象引文网络图信息。将GCN层作为VGAE的推理模型。VGAE的GCN层计算式为:
(1)
该模型由两个GCN层组成。GCN层使用两个矩阵作为输入:单位矩阵X和邻接矩阵A,矩阵大小为N×N,N是输入论文的数量。通过第一个GCN层的学习,使用层参数W0作为第二层的权值矩阵,每一层都分层传播扩展。
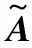
(2)
2.4 变分图自编码器
如图2所示,VGAE是将变分自编码器[16]的无监督学习方法应用于图卷积神经网络模型。它通过最小化推理模型和生成模型之间的成本来学习潜在表示。损失函数L包括生成图和原始图之间的距离度量,以及节点表示向量分布和正态分布的KL散度两部分,其计算式为:
L=E|q(Z|X,A)[ logp(A|Z)]-KL[q(Z|X,A)‖p(Z)]
(3)
式中:E|q(Z|X,A)表示交叉熵函数。
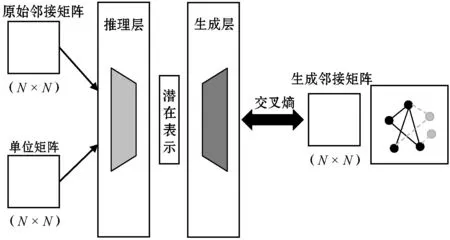
图2 变分图自编码器的结构
VGAE推理层通过减少来自GCN层结果的正态分布与高斯正态分布之间的KL-散度损失来对表示矩阵Z进行学习,计算式为:
(4)
式中:μ=GCNμ(X,A)是特征向量的均值;logσ=GCNσ(X,A)是节点向量的方差。
然后,生成层根据干涉层的表示矩阵Z学习邻接矩阵。潜在变量zi和zj为i与j的内积值,通过论文向量之间的内积,根据潜在变量生成邻接矩阵,如式(5)所示。生成模型通过减小其邻接矩阵A与实际邻接矩阵之间的差来定义表示矩阵Z。
(5)
3 实 验
3.1 实验概述
本文将提出的模型与现有SOTA模型之一的CACR[9]进行比较,重点放在性能上。实验中使用了AAN和PeerReadPlus(PRP)数据集,并使用平均精度均值、倒数排序法(MRR)和Recall@K作为评估指标。实验目的是考察模型的总体性能以及以下方面:
(1) 将提出的模型与现有的SOTA(CACR模型)进行性能比较,以衡量BERT和GCN的性能优于传统模型。
(2) 研究使用BERT和GCN模型之间的性能差异,用BERT表示文本数据,用GCN表示图形数据,并分析每个模型对总体性能的影响。
(3) 根据文本数据的长度来检查模型的性能。当使用BERT时,检查那些离引文符号较远的句子是噪音还是有用的信息。
(4) 根据聚合数据集中的论文出现量来度量性能的好坏。当特定论文很少被引用时,去观察这个模型是怎样执行的。
3.2 实验设置
(1) 实验数据集。在实验中,AAN数据集使用了2014年之前发布的数据,而新建的PeerReadPlus数据集包含了2018年之前发布的论文数据。数据集分为两部分:AAN数据集使用5 806篇2013年以前的论文作为训练集,973篇2013年以前的论文作为测试集。PeerReadPlus数据集使用3 411篇2017年以前的论文作为训练集,2 559篇2017年以后的论文作为测试集。然后,为了测试各种情况下的模型性能,进行了不同频率、不同上下文长度的对比实验。
(2) 评价指标。对于实验评估,本文使用MAP、MRR和Recall Top@K指标,这些是用于信息检索的常用度量标准。MAP测量反映检索列表的排名位置的平均精度,这个指标是基于K推荐列表对应的标签值的位置,这里测量K=30的指标。MRR指示器的定义是识别推荐列表中实际标签第一次出现的位置。最后,将Recall Top@K定义为Top@K推荐列表中实际标签命中率的指示器。实验通过K=5,10,30,50,80,100来评估召回率。
(3) 参数设置。在独立的学习过程中,从BERT层和GCN层中提取了嵌入的上下文向量和文档向量。在BERT,多头注意数为12,编码器栈数为12,学习的epoch(训练模型的迭代次数)总数为30,批量大小为16,使用Adam优化器。学习率为2e- 5,epsilon为1e- 6,beta1为0.9,beta2为0.999,权值衰减率为0.01。实验将序列长度的最大值设置为128,如果长度小于128,则填充0,并且隐藏的大小为768。
对于GCN,epoch的数量为200,第一个隐藏维度与文档大小相同,第二个隐藏维度为768,批大小与总文档大小相同(全批梯度下降),优化器为Adam优化器[17],学习率为0.01。
3.3 实验结果
(1) 基准比较。如表2所示,与现有CACR相比,本文模型提供了显著的性能改进。与SOTA模型相比,本文模型在MAP、MRR和Recall@K索引方面的性能大约提高了3倍。特别是Recall@5,即只有5篇检索引文时,有显著的改进。
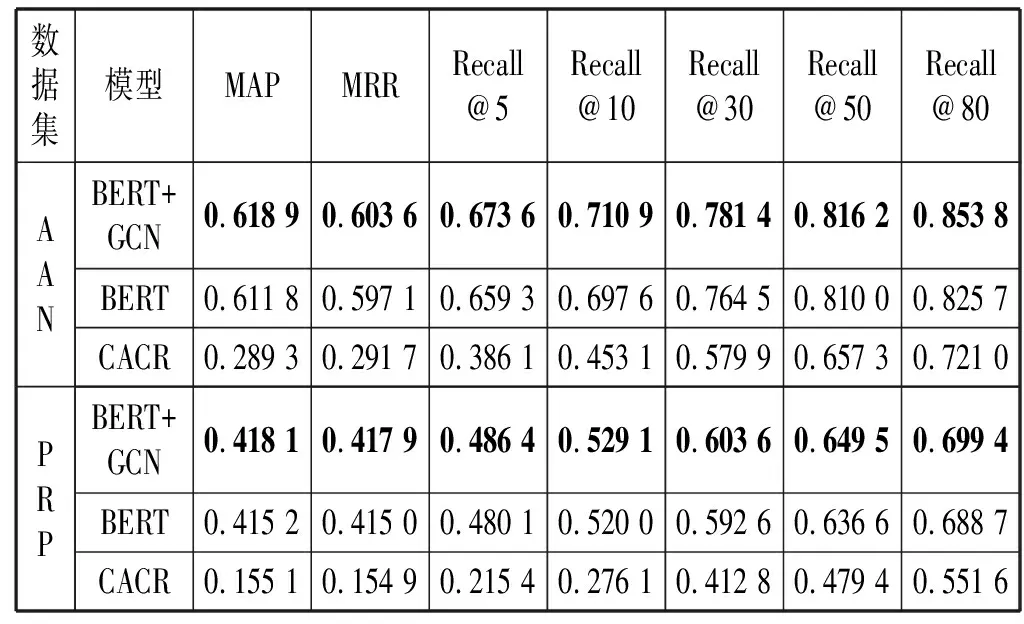
表2 上下文长度为50引文频率大于5的性能测试结果
实验中,本文模型和CACR都只用于被引次数最少为5次的论文,学习方法是在引文符号两边同时考虑50个单词。
通过独立地复制CACR论文中与Python相关的代码来比较性能。在实际的论文中没有详细的实验信息,如频率等。由于没有提到频率,这里假设CACR论文中描述的性能是基于频率为1得到的,将本文模型性能与CACR论文中所描述的性能进行比较,如表3所示。对于MAP、MRR和Recal@10,本文模型表现更好,但是当分类标签值随被引论文频率变高时表现出在Recall@10之后性能不如CACR模型。
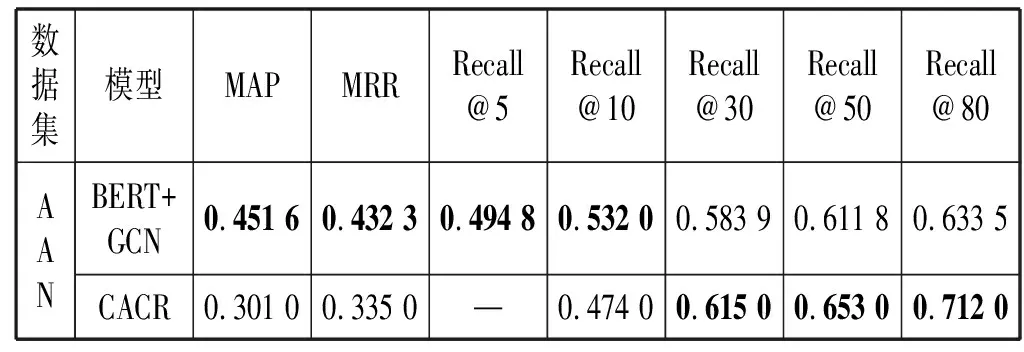
表3 频率为1时与CACR性能的比较
(2) BERT和GNC的影响。当添加GCN后,模型的性能得到了提高,如图3所示,实验所使用数据集为ANN,文本长度100,频率为5。
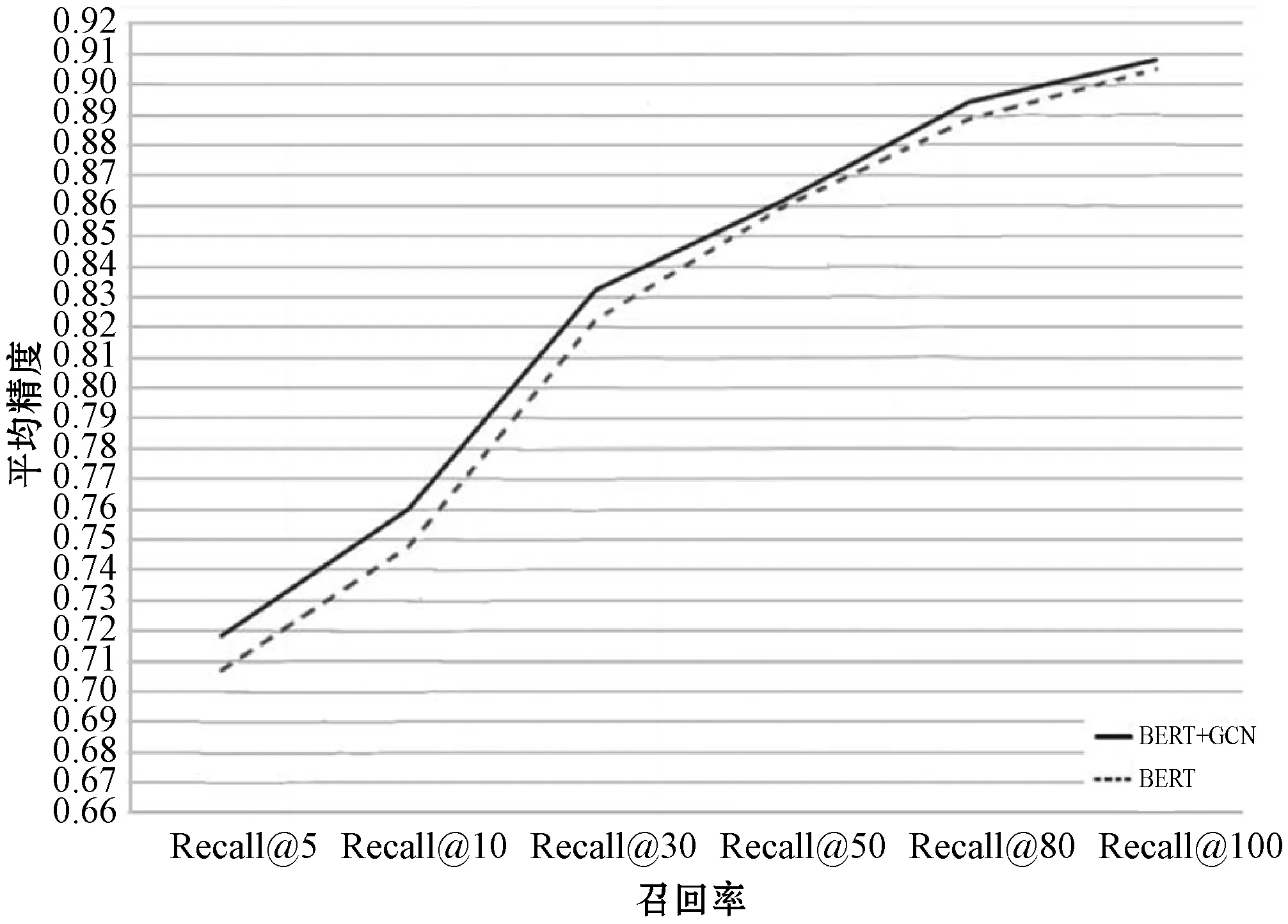
图3 BERT和GCN的效果
(3) 上下文序列长度的影响。频率为1时,各模型性能随句子上下文长度的变化情况如图4所示。当上下文长度达到或超过100时,上下文长度对模型性能的影响较小,说明性能与上下文句子的长度是相关的,但是超过一定的长度后,上下文长度对性能的影响就减小了。
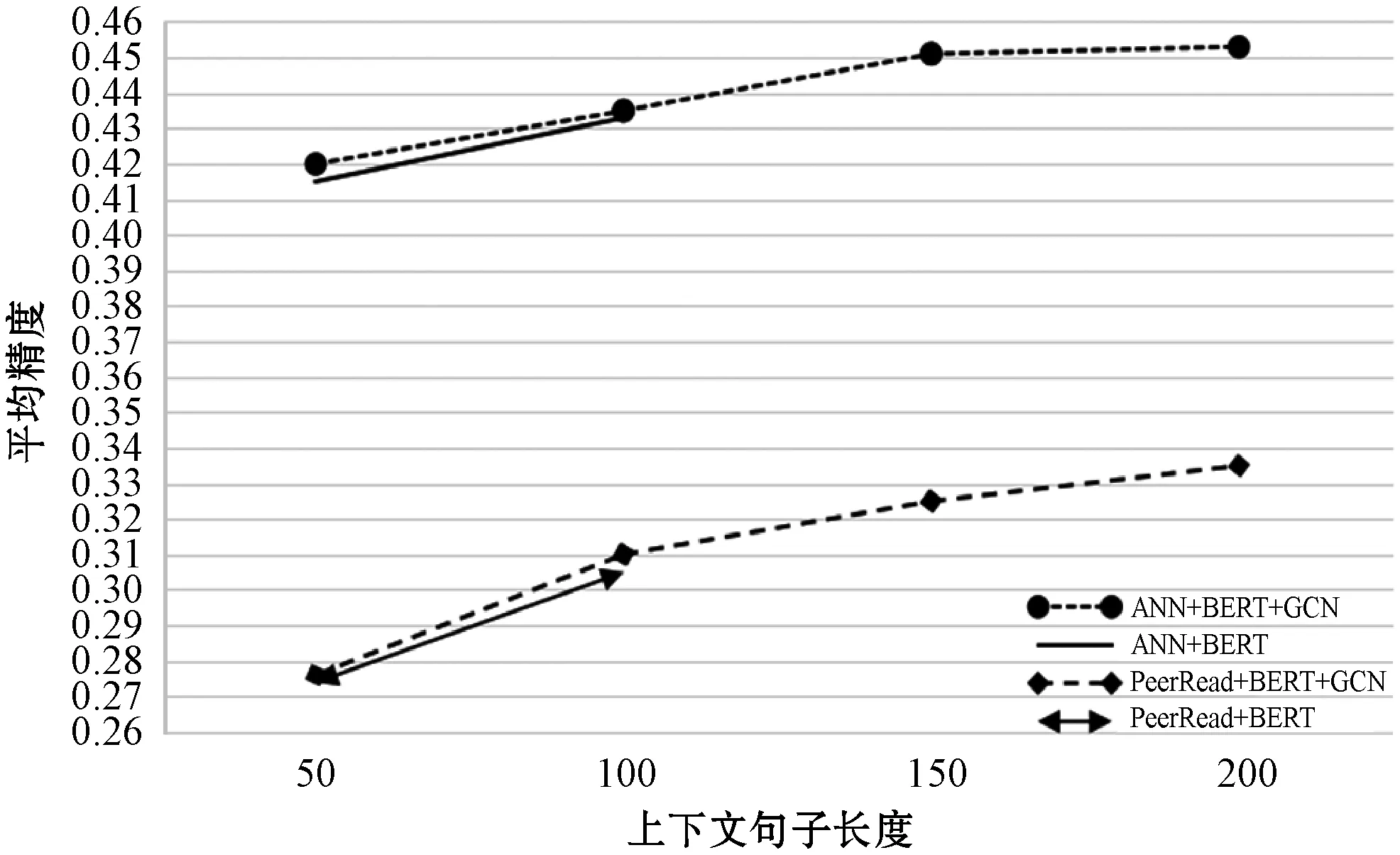
图4 频率为1时,性能随句子上下文长度的变化
(4) 论文被引频次的影响。如表4所示引文频率1、频率3和频率5的实验结果表明,引文频率越高,性能越好。一般而言,未被引用的论文不用于训练,即使在测试时也可以作为稀疏数据处理。因此训练数据应根据引文频率进行细化,即用均匀包含不同频率的数据对模型进行训练,以获得更优性能。
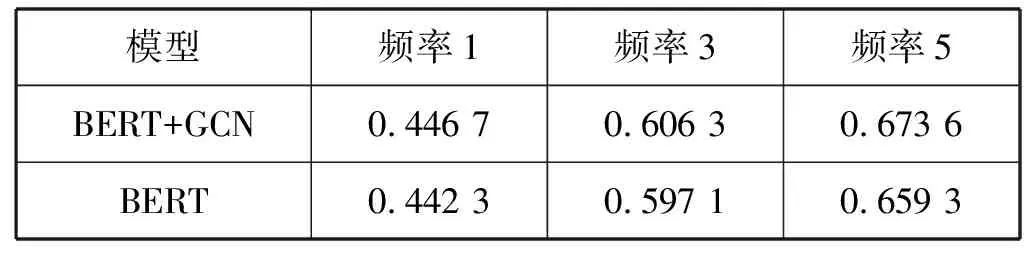
表4 基于引用论文频率的性能变化比较
4 结 语
对于上下文感知的引文推荐研究,现有的数据集都不是最新的,也没有明确的上下文检测。为了解决这个问题,本文采用了PeerReadPlus数据集。该数据集包含了2017年以前的最新论文,提供了一种方便、准确的提取上下文元数据的方法,并且具有良好的组织视角。
本文提出的上下文感知引文推荐任务模型在MAP、MRR和Recall@K方面相比现有模型有显著改进。性能改进的基础是采用了BERT模型,它在最近的NLP任务中各方面表现良好,适用于本文的上下文感知框架。通过BERT实现上下文编码,改进了上下文侧的表示学习。此外,本文还采用了VGAE,根据图数据包含一个GCN层,以减轻BERT单独应用时对本地上下文的过度拟合。它应用于框架引文编码器,将论文的引文网络图数据处理成论文的潜在表示形式。编码后的论文网络和上下文的组合是正则化的,从而在基于BERT的模型上提高了性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
传感器世界(2022年3期)2022-05-24
电脑爱好者(2021年12期)2021-06-22
数字技术与应用(2021年1期)2021-03-24
天天爱科学(2020年6期)2020-09-10
作文大王·低年级(2017年11期)2017-12-05
中学生数理化·八年级物理人教版(2017年2期)2017-03-25
学苑创造·A版(2017年1期)2017-01-19
哈尔滨理工大学学报(2016年2期)2016-09-12
