
基于大流调度的软件定义数据中心网络负载均衡算法
2021-01-15 08:28朱素霞龙翼飞孙广路
计算机应用与软件 2021年1期
朱素霞 龙翼飞 孙广路
(哈尔滨理工大学计算机科学与技术学院 黑龙江 哈尔滨 150080)
0 引 言
随着云计算和互联网应用的飞速发展,数据中心网络(Data Center Network,DCN)的规模逐步扩大,其内部的网络流量也在以指数等级增长,对带宽的需求不断增加。现有的网络拓扑无法满足其对带宽的需求[1],为此,众多研究人员提出了许多新型数据中心网络拓扑结构,如DCell[2]、PortLand[3]、BCube[4]、Fat-Tree[5]等。目前,在数据中心使用最为广泛的是Fat-Tree网络拓扑。另外,传统的网络架构已经无法满足现代数据中心网络的发展需求。因此,软件定义网络(Software Defined Network,SDN)作为新兴的网络体系架构诞生了,其核心思想是将网络数据的控制和转发分离[6]。由于SDN集中式架构的特性,使其能够掌握全局网络视图,从而为解决数据中心流量调度,实现全网负载均衡提供了很好的思路。
针对数据中心流量负载均衡问题,国内外科研人员对真实的数据中心网络流量特征进行了大量的研究。其中,Benson等[7]发现在数据中心网络中大流数量虽然少于网络流数量的10%,但却占了网络流量带宽的80%。同时,有研究表明小流经常在大流的后面,容易产生较长时间的队列延迟[8]。为了提高数据中心的网络性能,研究对大流的重路由算法,减少大流之间的冲突,从而保证网络整体链路的负载均衡变得尤为重要。
鉴于目前的负载均衡算法在对大流进行调度的时候没有考虑到大流在链路上的分布情况,可能将多条大流分配到同一链路,导致流传输时延过高。为此,本文针对大流在网络链路中的分布,进一步提出了一种基于大流调度的软件定义数据中心网络负载均衡算法(Large-flows Routing Load Balancing,LRLB)。
本文的主要贡献如下:
(1) 结合多商品流问题(Multi-commodity Flow,MCF)[9],对负载均衡问题进行了建模,根据网络流量的分布提出了基于链路负载离散度的目标函数。
(2) 针对网络中的大流提出了基于大流分布度和可用负载度的大流重路由方法,并且与现有负载均衡方法进行了比较,综合多种评价指标,在Fat-Tree拓扑结构下进行实验研究,验证了LRLB算法的性能。
1 相关工作
关于数据中心网络中流量负载不均衡的问题,现有的解决方法主要有两大类,分别是确定性方法和非确定性方法[10]。确定性方法是针对特定的输入产生相同的输出,这类方法普遍存在的问题是容易产生较长的时延和过大的丢包率;而非确定性方法则是针对相同的输入,在不同的运行环境中可能会有不同的输出,该类算法的总体缺点是由于计算量较大,容易导致过高的系统开销和资源消耗。
在确定性算法中,传统的等价多路径算法(ECMP)[11]采用静态散列的方式将数据流均匀地分配到多条等价路径上,但该算法没有考虑到网络流量的特征以及链路状态的实时变化,以至于该算法局限性很大。付应辉等[12]提出了一种基于带宽需求的多路径负载均衡算法(F-MPLB),通过对链路的评估,在满足带宽需求的路径中选择瓶颈带宽最大的路径进行路由,考虑因素过于单一,可能错过更好的路径。彭大芹等[13]根据流量特征和链路状态提出了一种多路径路由算法(MLF),针对小流仅依据剩余带宽对其进行调度,调度路径可能时延较大,容易导致小流的传输时延不理想。
另外,在非确定性算法中,Al-Fares等[14]针对数据中心网络负载均衡问题提出了Hedera动态流量调度系统,其中包括全局最先匹配算法(GFF),该算法是从所有候选路径中贪婪地选择第一条满足流需求的路径,其缺点是该路径可能不是全局最优路径;模拟退火算法(SA)使用概率性搜索的方式确定最优路径,虽然执行的速度很快,但是收敛速度比较慢。林智华等[15]通过对粒子群算法的改进,进一步提出了离散粒子群算法(DPSOFS),算法针对路径随机搜索的盲目性,限定了其搜索范围,使其收敛速度加快,但是开销相对较大。
2 算法设计
2.1 负载均衡问题建模
由于负载均衡问题和多商品流问题MCF的本质是一样的,都是一种组合优化的NP(Non-deterministic Polynomial)完全问题。因此,本文把网络中的负载均衡问题转化为经典的多商品流问题,对其进行建模求解。其中模型的主要特征是在给定的网络拓扑结构和链路容量约束的条件下,通过合理地调度网络流量,控制其在网络中的传输代价值,进而使其均匀地分布在网络中的每条链路上。这里把多商品流问题中的商品映射为网络负载均衡问题中的数据流。目标是将数据流中的大流尽量均匀地分配到其候选路径上,从而均衡全网链路负载,实现数据中心网络的负载均衡。模型本质是一种整数线性规划数学模型,对于网络中包含大流数目较多的情况效果明显,具备一定优势。问题的具体建模描述如下:
对于典型的Fat-Tree网络拓扑结构,可以将其抽象为一个有向图G=(H∪S,E)。其中:H与S分别代表主机节点集合和交换机节点集合;E则代表链路集合。网络中共有m条链路,其中链路可表示为lij,i,j∈H∪S,另外,定义链路的最大负载为Cij。网络中共有n条流,流的集合可以表示为F={f1,f2,…,fn},定义其中一条流fk为一个四元组(sk,dk,rk,tk),k∈{1,2,…,n},其中:sk∈H表示源主机节点;dk∈H表示目的主机节点;rk表示流fk的带宽需求;tk为流fk的大小标记,当其值为1时即为大流,值为0时则为小流。
由于本文的目标是实现全网链路的负载均衡,即将网络流量均匀地分配到全网链路中。这里利用数学中的标准差概念,使用离散程度反映均匀程度,对目标函数的具体定义如下:
(1)
(2)
(3)
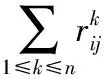
其约束条件如下:
(4)
(5)
(6)
(7)
(8)
其中:式(4)定义了流守恒约束;式(5)代表流fk从源主机流出的流量等于流入目的主机的流量;式(6)则表示除源主机和目的主机节点外,流fk在中间任意交换机节点流入和流出的流量相等;式(7)代表流容量约束,即任意一条链路上的总流量应小于等于链路容量;式(8)代表流请求带宽约束,流fk的请求带宽应大于等于0,不能为负值。
2.2 算法架构
本文提出的LRLB算法处理流程主要包括五大模块,分别为信息收集模块、拓扑发现模块、大流检测模块、路径计算模块、流表安装模块。总体架构如图1所示。具体的LRLB算法运行步骤如下:
(1) 拓扑发现模块通过链路层发现协议(Link Layer Discovery Protocol,LLDP)获取并更新全局网络拓扑。
(2) 信息收集模块通过周期性地调用端口状态请求方法和流状态请求方法向交换机发送相关状态请求消息,进而获取交换机端口状态信息以及流的统计信息。
(3) 大流检测模块根据信息收集模块所收集的信息对流经边缘交换机的流大小进行判定,由于目前普遍将超过链路带宽的1%~10%的流定义为大流[16],所以,这里将超过链路带宽5%的流标记为大流。路径计算模块则根据其判定结果对流进行路由,如果是小流则采用默认的ECMP路由方式对其进行路由,反之,若是大流则采用大流调度算法对其进行重路由。
(4) 流表安装模块根据路径计算模块的结果将流表下发到对应交换机。
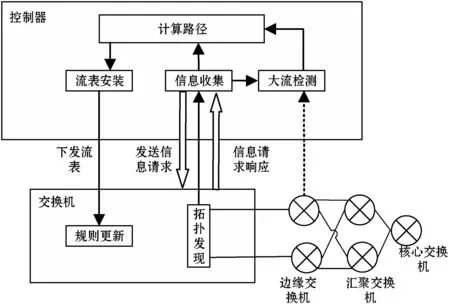
图1 总体架构
2.3 大流调度算法
大流调度的主要思想是结合网络中大流分布度和可用负载度对大流进行调度。其中大流分布度分为链路和路径两种,这里将链路上的大流分布度定义为流经链路的大流数量与网络中大流总量的比值,相应路径上的大流分布度即为所有组成路径的链路上大流分布度最大值。同样,将链路可用负载度定义为链路上剩余可用带宽和链路总带宽的比值,对应路径上其最大值即为路径可用负载度。具体大流调度算法执行流程如下:
(1) 由于大流流经链路越多,大流之间发生碰撞的次数就越多。为此,本文根据获取的网络统计信息,通过KSP算法[17]计算得出大流源主机和目的主机之间基于跳数的x条最短候选路径集合P={P1,P2,…,Px}。选择跳数较少的路径对大流进行调度可以有效降低大流之间产生冲突的概率和次数。同时,选择多条相对较短的路径作为备选,可以很好地避免遗漏较好的路径。
(2) 计算候选路径集合P中每个链路的大流分布度Ldegree,其具体计算方式如下:
(9)
式中:Lnum表示流经对应链路的大流数量。当网络中越来越多的大流流经当前链路时,相应的链路上大流分布度就会越高,对应链路上大流之间碰撞次数就会越多。
(3) 求出每条候选路径的大流分布度Pdegree,即当前路径所包括的全部链路上大流分布度中的最大值,其值代表了该候选路径大流分布度的瓶颈,具体求解方式如下:
(10)
(11)
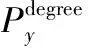
(4) 在这y条路径中找出可用负载度最高的路径,即满足式(12),对大流进行重路由。
max(δ1,δ2,…,δy)
(12)
(13)
(14)
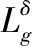
3 仿真与结果分析
为了展示所提出算法的优越性能,本文将对比在目前数据中心中应用广泛的ECMP算法,还有基于GFF算法的Hedera动态流量调度系统。分别从平均对分带宽、链路带宽利用率、端到端的往返时延这三方面进行测试验证。
3.1 仿真环境
本文采用两台安装有Ubuntu 16.04 LTS系统的服务器作为实验主机。其中:一台实验主机安装Ryu 4.3.0[18]控制器,并在上面实现了LRLB算法原型;另一台实验主机则安装Mininet 2.3.0[19]轻量级网络仿真工具,用于模拟真实数据中心网络环境。实验采用经典的Fat-Tree网络拓扑,Fat-Tree网络拓扑中包含(k/2)2个核心交换机,k个Pod,每个Pod连接(k/2)2个主机,同时,其内部包含有k/2个聚合交换机和k/2个边缘交换机,另外,每个交换机端口数量为k。这里取k=4,具体拓扑情况如图2所示。虚拟交换机采用支持OpenFlow 1.3协议[6]的OpenvSwitch 2.5.5,同时,设置其内部最大缓冲队列数为1 000。另外,设置链路带宽为10 Mbit/s,并且为全双工。每台虚拟主机使用Iperf 2.0.5流量生成工具生成实验所需网络流量。
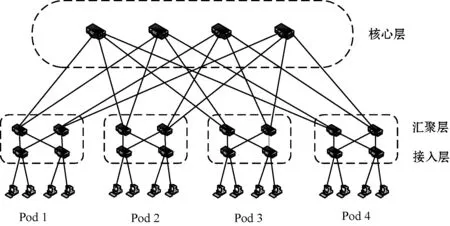
图2 Fat-Tree网络拓扑图
虚拟主机之间采用随机通信模式和交错通信模式进行通信。其中,随机通信模式Random表示网络中虚拟主机之间以相等的概率进行随机通信,交错通信模式Staggered(pEdge,pPod)中pEdge表示同一Pod内相同子网的流量占比,而pPod则为不同子网之间的流量占比,另外,不同Pod间的流量占比为1-pEdge-pPod。
为了实验测试的公平性,其中,针对交错模式本文采用两种具有不同特点的流量模型,分别为Staggered(0,0.5)、Staggered(0.3,0.5)。这里对每组流量模型重复测试20次,每次测试运行时间为60 s。其中控制器循环监控周期设置为5 s,设置基于跳数的候选路径数x=8,具体如表1所示。测试期间使用bwm-ng 0.6.1工具对网络带宽进行监测,最后将每组流量模型测试结果取平均值作为实验结果。
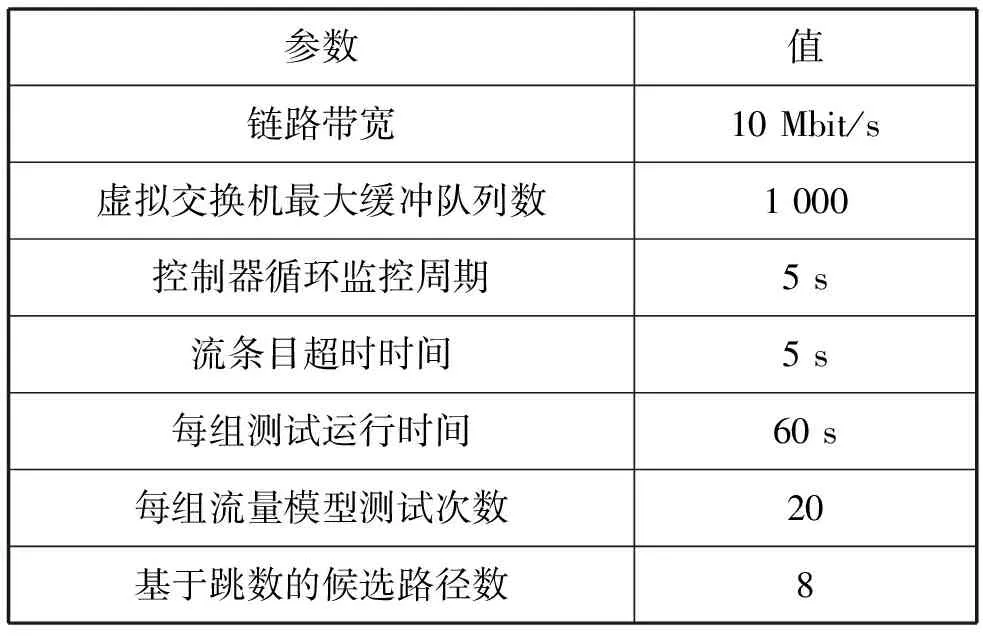
表1 实验环境参数
3.2 性能分析
平均对分带宽的实验结果对比如图3所示。从整体来看,当不同Pod间的流量占比较低时,网络对分带宽要高于其占比较高的时候。其原因是在Pod间流量占比较低的时候,即跨Pod间主机通信概率较低,相应地会导致网络中大流之间的冲突概率降低,从而使其获得相对更高的平均对分带宽。在随机的通信模式下,同一Pod内相同子网之间的通信量较低,与交错通信模式Staggered(0,0.5)的流量模型所产生的结果较为接近。通过对比可以看出三种算法的差距较为明显,其中,LRLB算法在平均对分带宽上较ECMP提升了19.21%,较GFF提升了8.17%。而在流量模型Staggered(0.3,0.5)的实验结果中,三种算法性能几乎差不多,LRLB算法只是略高于其他两种算法。这是由于此时Pod间通信量低,需要重调度的大流很少,以至于效果没有那么明显。由此可以看出Pod间流量占比越高,即需要重调度的大流越多,LRLB算法的优势就越明显。这是由于LRLB算法对大流进行了重调度,调度的同时综合考虑了候选路径的大流分布度和可用负载度,进而将多条大流从相对繁忙的路径调度到相对空闲的路径上,从而有效地减少了大流之间的冲突,最大限度提高了网络的平均对分带宽。
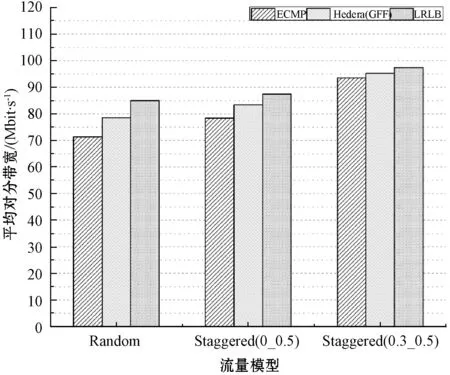
图3 平均对分带宽对比
图4、图5、图6分别为三种流量模型下的链路带宽利用率(CDF)对比实验结果。总的来看,LRLB算法相对另外两种算法,在低带宽利用率的链路中占比明显偏低。其中,在Random和Staggered(0,0.5)的流量模型内,LRLB算法中链路带宽利用率低于10%的仅占比约20%,而在ECMP和GFF算法中占比则分别约40%和50%。LRLB算法不仅减少了带宽利用率低的链路数量,同时也减少了带宽利用率高的链路数量。这是因为LRLB算法在对大流重调度时,选择将其调度到大流分布度相对较低的路径上,从而使得大流被尽可能均匀地分配到网络链路中,避免了部分链路上流经大流数目过多和过少的情况。同时,又由于大流所占带宽相对较高,所以大多数链路的带宽利用率相差不大,进而很好地降低了链路带宽利用率的离散度,使得全网链路负载更加均匀。
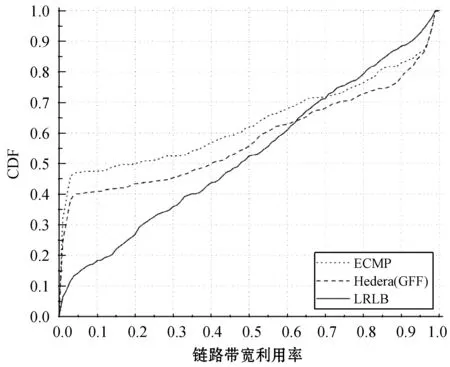
图4 Random下链路带宽利用率对比
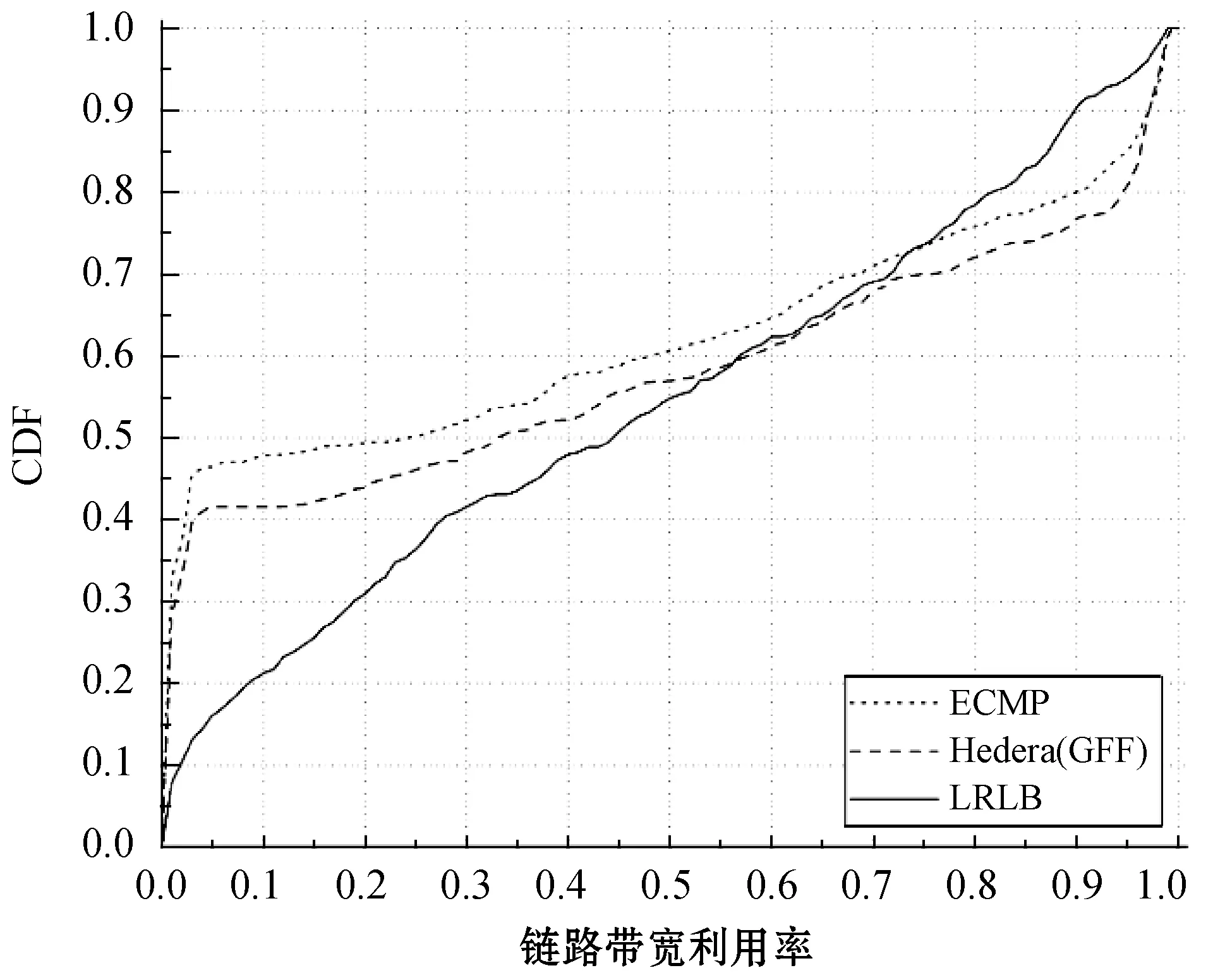
图5 Staggered(0,0.5)下链路带宽利用率对比
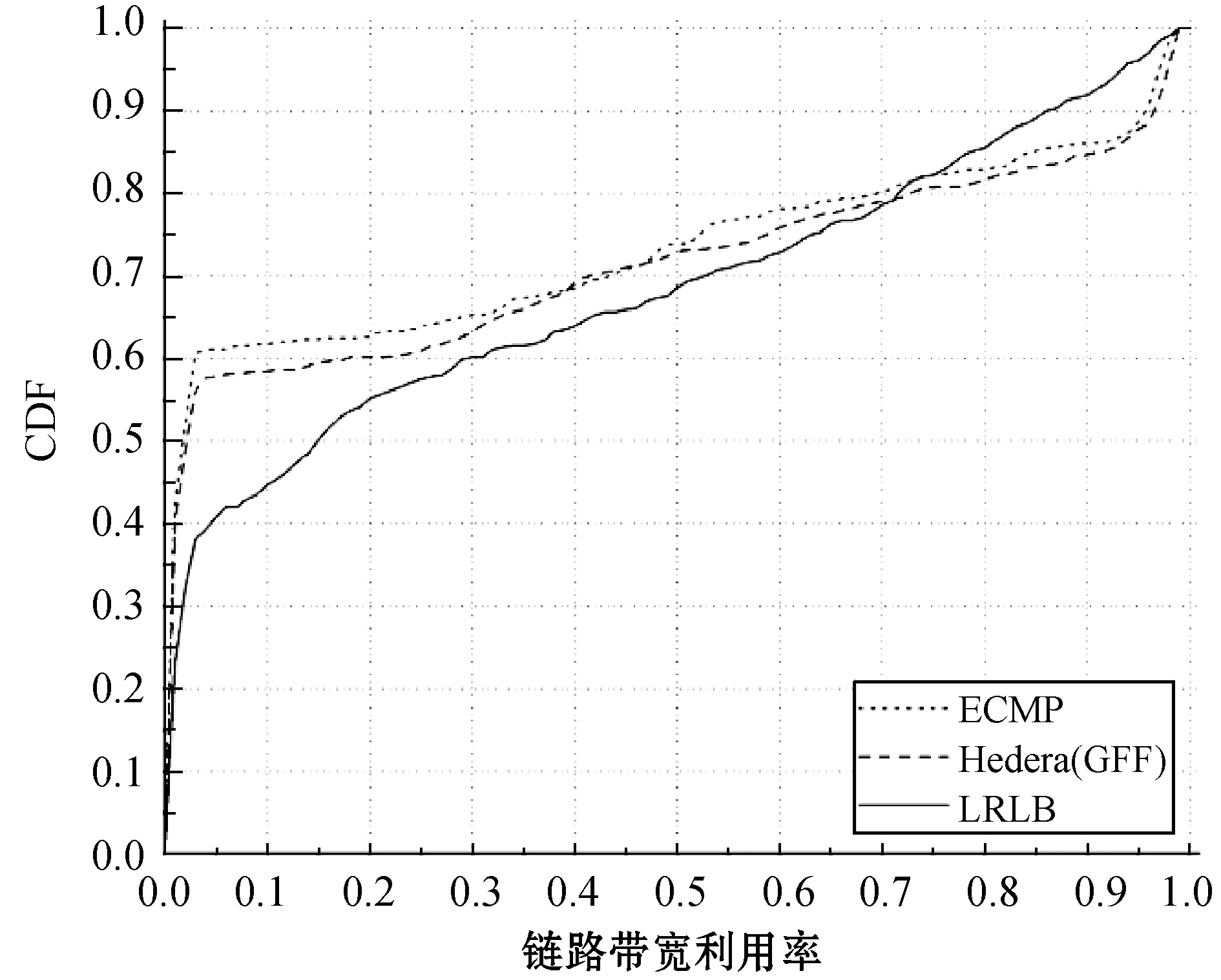
图6 Staggered(0.3,0.5)下链路带宽利用率对比
图7为包平均往返时延实验结果对比。通过三种流量模型的对比可以看出,LRLB算法通过将大流重路由到大流分布度相对较低的路径上,使得小流不总是排在大流后面,从而相对另外两种算法大幅降低了网络中数据包的往返时延。其中,相对GFF算法分别降低了约44%、39%、29%,相对ECMP算法分别降低了约47%、46%、37%。虽然基于GFF算法的Hedera动态流量调度系统也对大流进行了重路由,但是由于其只是从单一的带宽因素考虑进行的重调度,因此显得较为片面。而LRLB算法同时又考虑了大流在链路中的分布情况,所以LRLB算法要更优于GFF算法。
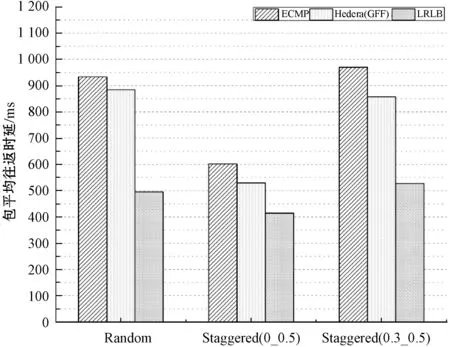
图7 包的平均往返时延对比
4 结 语
本文针对广泛应用的Fat-Tree数据中心网络,进行了相关负载均衡算法的研究。考虑到大流对网络的影响较大,结合大流在网络中的分布度和候选路径的可用负载度,设计了一种基于大流调度的LRLB算法。该算法对大流和小流分别采用了不同的路由方式,以实现全网流量的负载均衡。通过与经典的ECMP和GFF负载均衡算法的仿真对比,进一步验证了本文提出的LRLB算法通过合理地调度大流,不仅获得了在对分带宽上的提升,而且降低了网络传输时延,实现了更好的负载均衡效果。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
移动通信(2021年5期)2021-10-25
计算机与网络(2020年9期)2020-07-29
电脑知识与技术(2019年22期)2019-10-31
传播力研究(2019年24期)2019-10-21
科学与财富(2016年24期)2017-03-29
科技创新导报(2016年27期)2017-03-14
智能制造(2015年10期)2015-11-04
城市建设理论研究(2011年28期)2011-12-31
中国计算机报(2009年20期)2009-04-15
