
基于知识图谱的新疆旅游自动问答系统设计
2021-01-14 00:45孙晶郭成艳毛臣胡玉叶
现代信息科技 2021年12期
关键词:知识图谱
孙晶 郭成艳 毛臣 胡玉叶



摘 要:近年来,新疆旅游业发展趋势越来越好,优美的风光,丰富的物产,受到国内外游客的喜爱。由于新疆地大物博,导致多数游客不能准确找到目的地。建立了一個新疆旅游知识图谱结构描述和形态分析的可计算方法体系,提出将自动问答系统运用于新疆旅游。创建新疆旅游知识图谱并构建基于新疆旅游知识图谱的自动问答平台,目的是使游客在存放着海量结构化知识的图谱上快速获取正确答案,为游客游览景区时减少不必要的时间消耗。
关键词:知识图谱;Neo4j数据库;自动问答系统;新疆旅游
中图分类号:TP182 文献标识码:A 文章编号:2096-4706(2021)12-0026-04
Abstract: In recent years, the development trend of Xinjiang tourism is getting better and better. The beautiful scenery and rich products are loved by tourists at home and abroad. Due to the vast territory and abundant resources in Xinjiang, most tourists can't find their destination accurately. A computable method system for structural description and morphological analysis of Xinjiang tourism knowledge graph is established, and the application of automatic question answering system in Xinjiang tourism is proposed. The purpose of creating Xinjiang tourism knowledge graph and constructing an automatic question answering platform based on Xinjiang tourism knowledge graph is to enable tourists to quickly obtain correct answers on the graph with a large amount of structured knowledge, so as to reduce unnecessary time consumption of tourists when they visiting scenic spots.
Keywords: knowledge graph; Neo4j database; automatic question answering system; Xinjiang tourism
0 引 言
早期自动问答系统大都针对特定领域构建,需要领域专家撰写大量领域相关的规则用于问题理解和答案生成,极大地限制了该类自动问答系统的规模和通用性。20世纪60年代,Green等人提出BASEBALL系统,Woods提出使用自然语言检索NASA数据库,Winograd提出SHRDLU系统。自动问答内容系统START是由MIT麻省理工学院1993年研究开发并发布使用的从此自动问答进入开放领域问答时代。Evi是2005年上线的基于知识图谱(knowledge graph)核心技术的问答型搜索引擎。斯坦福在2016年发布了SQUAD数据集。2018年3月百度发布了中文机器阅读理解数据集DuReader,与中国中文信息学会和中国计算机学会共同举办了“2018机器阅读理解技术赛”。新疆丰富的旅游资源吸引着全国的游客来观光,但仍缺乏一个能够随时随地解答新疆旅游问题的自动问答系统来帮助游客解决心中的疑惑。近年来,随着人工智能的飞速发展,自动问答技术也取得了突飞猛进的发展,如果将自动问答技术应用于回答旅游爱好者在新疆旅游遇到的问题,新疆旅游将会有更好的发展前景。
1 知识图谱
知识图谱这个理论是以20世纪50年代末60年代初的语义网络(semantic net)为原型提出来的。知识图谱这个概念Google在2012年提出来的一个新概念。知识图谱把一个叫做三元组(triple)的数据结构作为知识存储和表示的基本单元。现在,国际上流行的的知识图谱有Freebase、DBPedia,YAGO和Satori等等,他们的主要内容还是源自于早期一些大型平台Wikipedia、NNDB、Musicbrainz以及这些平台的社区用户的贡献。2012年,从Google开始发布基于知识图谱的语义搜索和自动问答服务以后,学术届开始研究知识图谱的典型应用。慢慢的,业界学术研究团队对垂直知识图谱进行有针对性的研究,针对某些特定领域特定专业知识为基础创建的垂直知识图谱,其创建过程依赖特定专业领域的行业数据的依赖度非常高,在知识领域各专业的全领域覆盖范围较窄。当前如何脱离专业领域数据库使得知识图谱能够进行自动获取和实际应用是目前各领域中最重要的两个课题。
2 知识图谱语料库创建
本文研究多源异构方式建立新疆旅游实体生成资源技术,本文研究的数据从一开始的设计由百科网页中用爬虫来进行爬取,由于爬虫的设计和数据清洗技术熟练度好,所以在后续的应用中沿用了爬虫爬取百科网页结构化数据,在爬虫过程中主要应用传统方法就是Partial Page Rank策略,该策略的优先度设计为重要程度较高的网页爬取有限权重系数较高。爬取好网页数据后,使用人工数据清洗的方法将爬取到的实体、属性及相互关系等知识手工摘取出来,然后存储到文本文件当中,使用程序算法再辅以数据提取以三元组的形式储存到图数据库中。这种爬虫框架辅助人工筛选的方式可以非常有效的达到获取新疆旅游词条的目的,并且能够极大的丰富数据库资源。各数据资源名词性对象会生产等实体,各实体间存在的位于和属于关系,我们会以<实体1,关系,实体2>三元组形式进行数据库依存关系储存。实体的属性是我们数据库中每个词条中特定位置对应的,这个词条中实体属性的表格能够自动抽取出实体的属性,生成<实体,属性名称,属性值>三元组形式进行数据库储存。本文为了构建旅游知识图谱从结构化知识库和垂直旅游信息数据库及网站以及百度百科中抽取旅行景点信息,进行旅游领域知识数据库创建。本文研究的新疆旅游知识图谱数据库只要包括地区节点知识图谱和景点知识图谱两部分构建的关键技术。
3 Neo4j数据库
本文使用Neo4j数据库来创建知识图谱,实现图数据库数据呈现。Neo4j是近年来非常流行的用于存储知识图谱节点和节点关系的NOSQL图形数据库。作为一个高性能的图数据库存储和检索的图引擎,该数据库引擎具有常用数据库与专业数据库所具备的所有成熟特性。使用Neo4j图数据库的一个优势就是在对数据进行存储的同时也是一个知识图谱的构建过程。通过对前面各种算法抽取的名词性实体、名词性实体的属性以及名词性实体间依存关系的存储,就能够生成一张知识图谱。
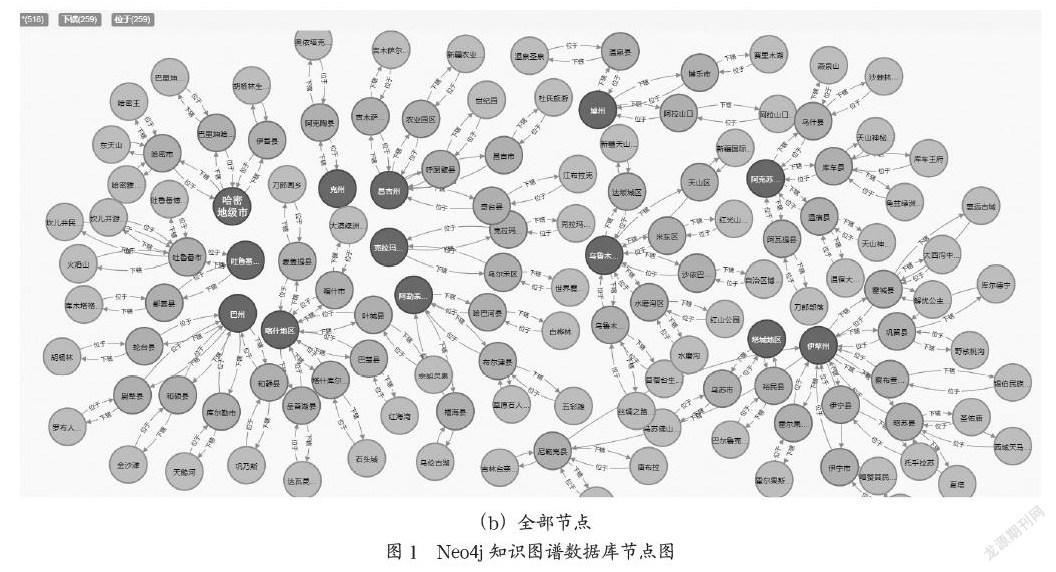
我们使用py2neo,python驱动引擎实现对数据库的一系列操作。对新疆旅游知识图谱数据库中的区、市、县、景点等层级节点数据进行创建、读取、更新、删除的操作。然后在已创建的数据节点上创建下辖和位于等数据依存关系。Neo4j数据库呈现的新疆旅游知识图谱数据库节点及其依存关系图如图1所示。
Self.g = Graph(‘http://localhost:7474’,username = ‘neo4j,password=‘neo4j’)
elif question_type == ‘city_have’:
sql=[“MATCH ( m:‘县市’)-[r1:‘下辖’]->(k:‘景区’) where m.name = ‘{0}’”\ “return m.name,k.name”.format(i) for i in entities]
for query in queries:
ress = self.g.run(query).data()
在图数据库中,图1中心部分表示的是哈密地级市的县和市,与县和市连接的是县和市中的景区,县和市中的景区外侧连接的是新疆维吾尔自治区对应的各个地区,数据库中有地区位于县(或市)和县(或市)下辖地区两种关系,如哈密市位于哈密地级市,哈密地级市下辖哈密市。景区与县(或市)同样也有位于和下辖两种关系,如东天山位于哈密市,哈密市下辖东天山。如果想做多种关系,也可在数据库中进行添加。
4 基于图数据库的自动问答设计
本系统对新疆旅游知识图谱数据库当中的区、市、县、景点以及位置关系进行抽象,归纳出概念间的体系结构,进行本体三元组抽取,构建知识图谱。构建知识图谱图数据库,对用户所提取的问题进行命名实体识别、关系抽取,然后到图数据库中进行答案匹配,如图2所示。
4.1 问题解析
自动问答系统的问题处理流程有:
(1)提前对问题分类。要对用户的问句即系统接收到的问题进行分类,如表1所示,提前将旅游中所有可能涉及的问题分为了九大类。
(2)提取问题的关键词。对用户所提问题进行关键词提取,即地区名称和主要问题,如东天山和通信地址,并过滤掉重复的、无用的信息:
#问句疑问词
self.telephone_number_qwsd= [‘联系电话’,‘咨询电话’,‘电话号码’,‘电联’,‘电话号’]
Self.leve_qwds=[‘级别’, ‘啥级别’, ‘几A级’,‘几a级’, ‘4A级’, ‘4a级’, ‘什么级别’]
(3)确定问题的类型。将关键词与问题的分类结果进行匹配,确定问题的类型。if question_type == ‘area_have’:
sql = [MATCH (m: ‘地区’)-[r1: ‘下辖’]->(n:‘县市’)-[r2: ‘下辖’]->(k:‘景区’)”\
“where m.name = ‘{0}’”\ “return m.name,k.name”.format(i) for i in entities]
elif question_type == ‘telephone_number’:
sql = [“MATCH (m: ‘景區’) where m.name = ‘{0} return m.name,”\
“m.telephone”.format(i) for i in entities]
elif question_type == ‘AAAA_fare’:
sql = [“MATCH (m: ‘景区’) where m.name = ‘{0} return m.name,”\
“m.name,m.off_season_fare,m.peak_season_fare”.format(i) for i in entities]
4.2 答案抽取
答案抽取作为自动问答系统的收尾步骤,但它却是最关键的一步,针对用户的问题类型属性到数据库中进行二次匹配,生成问题的答案。经过答案抽取这一过程后,用户所提出的问题的答案将以最简洁易懂的形式回答,如果答案抽取过程不能将正确答案准确的抽取出来,那么将会严重影响整个自动问答系统的准确性。在新疆旅游项目中,我们以模式匹配的形式进行答案抽取。
根据上文中问题解析的结果,我们将所确定的问题类型与图数据库中的数据进行匹配,如果匹配成功,将反馈的内容生成对应的回答:
'''根据对应的qustion_type,调用相应的回复模板'''\n",
if question_type == 'area_have':
desc = [i['k.name'] for i in answers]
subject = answers[0]['m.name']
final_answer = '{0}有如下4A级景点:{1}'.format (subject, ';'.join(list(set(desc))[:]))
5 程序结果验证
最后我们根据用户所提问题关键字查找图数据库中的数据,根据反馈结构生成对应的回答,生成回答程序验证结果如图3所示。
6 结 论
随着互联网数据的海量增长、硬件计算能力的飞速提高以及自然语言处理和深度学习技术的长足进步,自动问答方法的应用也比以往任何一个历史时期都更贴近人们的日常生活。本文设计和构建了新疆维吾尔自治区旅游景点信息的知识图谱,创建了Neo4j语料库,针对新疆旅游业问答系统的不足,设计了自动问答系统,并对自动问答系统中的问题解析和答案抽取方法进行了研究,最后并进行了结果验证。将自动问答系统应用于新疆旅游领域,可以促进新疆旅游信息的智能化管理发展,提升服务水平,这个价值是具有较大影响的。最近这几年推荐系统不管是研究还是发展都愈发的得到社会的关注,知识图谱建立的理论以及技术都愈发的完善,知识图谱包含的语义信息可以在很大的程度上对旅游景点相关信息进行健全,提高推荐系统的性能。
参考文献:
[1] 徐增林,盛泳潘,贺丽荣,等.知识图谱技术综述 [J].电子科技大学学报,2016,45(4):589-606.
[2] 刘知远,孙茂松,林衍凯,等.知识表示学习研究进展 [J].计算机研究与发展,2016,53(2):247-261.
[3] 刘峤,李杨,段宏,等.知识图谱构建技术综述 [J].计算机研究与发展,2016,53(3):582-600.
[4] ARTZI Y,LEE K,ZETTLEMOYER L. Broad-coverage CCG Semantic Parsing with AMR [C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing.Lisbon:Association for Computational Linguistics,2015:1-6.
[5] LI J H,ZHU M H,LU W,et al. Improving Semantic Parsing with Enriched Synchronous Context-Free Grammars in Statistical Machine Translation [J].ACM transactions on Asian language information processing,2017,16(1):6.1-6.24.
作者簡介:孙晶(1978—),女,回族,新疆新源县人,讲师,硕士,主要研究方向:机器学习、最优化算法、音频信息处理、自然语言与信息处理;郭成艳(2002—),女,汉族,陕西延安人,本科在读,主要研究方向:机器学习、最优化算法、音频信息处理、自然语言与信息处理;毛臣(1999—),男,汉族,河南南阳人,本科在读,主要研究方向:机器学习、最优化算法、音频信息处理、自然语言与信息处理;胡玉叶(2001—),女,汉族,新疆哈密人,本科在读,主要研究方向:机器学习、最优化算法、音频信息处理、自然语言与信息处理。
猜你喜欢
现代情报(2016年11期)2016-12-21
现代情报(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
现代情报(2016年10期)2016-12-15
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
中国远程教育(2016年9期)2016-11-19
商场现代化(2016年23期)2016-11-17
中国教育信息化·基础教育(2016年9期)2016-10-18
电脑知识与技术(2016年7期)2016-05-19
