
基于稀疏降噪自编码器的水声目标噪声数值特征提取方法
2021-01-13 07:14:50陈卓
声学与电子工程 2020年4期
陈卓
(海装驻上海地区军事代表局,上海,200083)
随着信息技术的快速发展,各国对海洋开发、水下防卫能力需求不断提升,水下信息感知方法研究的热度有增无减,新兴技术联合传统水声技术的水下目标探测、识别等感知方法已成为水下探测领域的重要发展方向。水声目标识别作为水声探测的核心功能,其关键在于水下目标可分性特征的挖掘和提取。传统目标识别方法通常从目标噪声产生的物理机理出发,通过信号处理手段提取能反映目标本质属性的可分性特征并基于分类器或模板匹配方法实现识别[1-4]。但随着水下目标隐身性能的不断提升,以及水声目标发声机理的多样性、海洋信道时空多变性、平台噪声和强干扰等因素的影响,水声目标信号通常具有信噪比低、干扰成分强等特点,目标固有特征隐匿性强[5],并导致传统特征提取方法较难获取具有良好可分性的特征,识别正确率不高,方法泛化能力差。
近年来,深度学习模型受到广泛关注和快速发展,已涌现出大量适用不同场合的深度学习算法,涉及识别、预测、控制等多个领域,逐渐成为水下目标识别研究的重要方向和新技术途径。深度学习通过构建多隐层结构来增强计算能力,在图像、语音识别等领域已取得令人赞叹的效果[6-8]。本文针对被动目标辐射噪声信号特征提取与识别的特点,提出将深度学习中的稀疏降噪自编码器方法应用于水声目标噪声降维和数值特征提取。
1 原理方法
1.1 稀疏降噪自编码器
稀疏降噪自编码器的基础结构是自编码器(AutoEncoder, AE)。AE是一个中间层具有结构对称性的多层前馈网络,其训练目标是将输入信号从目标表达中重构出来。单个AE结构可分为编码器和解码器,前者完成从输入向量到输出表征的映射转换,后者实现输出表征逆向映射回输入空间,得到重构信号。训练目标是使重构信号尽可能接近输入向量。
降噪自编码器(Denoising AutoEncoder,DAE)与传统的AE具有相同的结构,只是在输入数据中加入一定的噪声,其学习的目标是从受污染的输入中重构出纯净的输入,从而增加输出特征的鲁棒性。将DAE逐层叠加,即将上一层DAE的输出作为当前AE的输入,得到堆叠降噪自编码器(Stacked Denoising AutoEncoder,SDAE)。为进一步优化算法的计算精度和泛化能力,在损失函数中加入稀疏约束项,通常可表示为
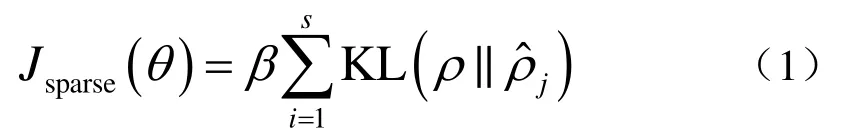
式中,β为稀疏约束项系数,ρ为设定的稀疏性参数,j为隐藏神经元j的平均活跃度,s为隐藏神经元数量,为j和ρ之间的KL 散度,可表示为

此外,为防止AE训练时的过度拟合,通常会在代价函数中增加权重衰减项Jweight(θ),通常可表示为

式中,λ为权重衰减项系数,nl为网络层数,sl为第l层网络的节点数量,为权值矩阵W中角标为j和i的元素值。稀疏降噪自编码器最终的损失函数可表示为
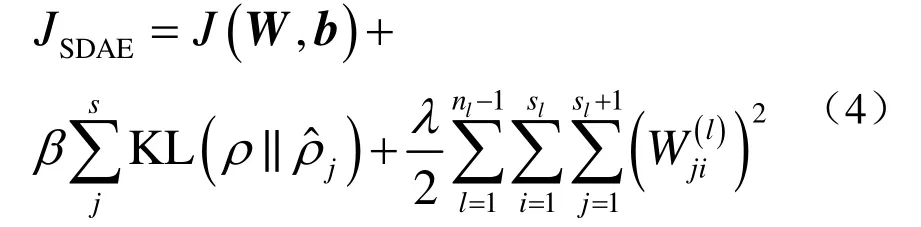
式中,J(W,b)为基本目标数据与重构数据之间的基本损失项。
1.2 数值特征评价方法
Fisher准则下的判别法是一种常用的线性判别方法,当高维空间的样本点投影到低维空间时,该方法使不同类的样本点在空间上的投影尽量分离,而同类的样本点则尽量聚集在一起。文中将类内距离和类间距离作为评价指标。类内散布矩阵为该类特征向量分布的协方差矩阵,反映了各样本点围绕均值的散布情况。类内距离是指同一类特征向量集内,各样本间的均方距离。特征向量集X内任意两个样本之间的距离可表示为:

当各样本相互独立时,类内距离为2倍的协方差矩阵C的迹(协方差矩阵主对角线上各元素之和),即

类间距离为各类特征向量在空间中距离,主要反映了各类特征向量之间的可分性。
2 仿真与试验数据分析
2.1 水下被动目标特征提取器设计
为验证稀疏降噪自编码器用于被动目标噪声特征提取的性能,构建了图1所示的基于多隐层稀疏降噪自编码器的水下被动目标特征提取器。该特征提取器以声信号功率谱为输入,通过多隐层结构进行降维与特征提取,输出能够反映目标固有属性的可分性数值特征,综合考虑AE方法特点及水声目标噪声的复杂性,中间隐层设置为2层。最后,在稀疏降噪自编码器模型顶部添加 Softmax分类器,以便基于梯度下降方法实现整个模型的有监督训练优化,通过结合带标签数据进行反向微调,对整个深度学习模型的性能提升起到决定性作用,图2为原理框图。

图1 水下被动目标噪声特征提取器原理框图

图2 多隐层稀疏降噪自编码器有监督训练原理框图
2.2 仿真数据处理结果
基于上述特征提取器模型开展了对商船和渔船两类目标的波束域仿真数据频域的特征提取与识别分析。训练数据信噪比为 3 dB,数据长度为384,其中两类目标的差异性主要体现在连续谱谱形、线谱幅度和频点等方面。与渔船噪声相比,商船线谱和连续谱的强度均更高,两类目标无标签数据各15 360组,用于模型的无监督预训练,带标签数据各128组,用于模型的有监督训练。处理模型共4层,基于每层节点数量逐级递减的原则设置中间隐层节点数量,通过测试多种节点参数组合,最终设置中间隐层节点分别为300和30,同时针对节点数量相对较多的隐层1加入稀疏约束,稀疏系数设置为0.05,同时设置噪声比例为0.2。
将上述稀疏降噪自编码器模型无监督预训练后的隐层输出数据基于 t分布随机近邻嵌入(t-distributed Stochastic Neighbor Embedding,t-SNE)算法进行投影,结果如图3所示(图中所示散点是对归一化目标数据进行提取特征和可视化的结果,无量纲。下文同)。可以看到,经过中间计算层对数据进行无监督预训练式的降维,得到的降维数据的分布特征发生变化,可分性提高。
对有监督训练后的稀疏降噪自编码器模型进行测试,测试数据信噪比为-3 dB。表1为评价结果(归一化目标数据进行提取特征和评价的结果,无量纲,下文同)。图4所示为部分数据及对应数值特征提取结果的 t-SNE投影,可以看到,和原始数据相比,降维得到数值特征的分布发生较明显变化,类内距离明显降低,类间距离大幅提升。

图3 无监督训练模型输出结果

表1 -3 dB信噪比测试数据数值特征评价结果


图4 -3 dB信噪比测试数据数值特征投影结果
采用信噪比为3 dB的仿真目标数据进行测试。图 5所示为部分数据及对应数值特征提取结果的t-SNE投影,表2所示为评价结果。可以看到,数值特征提取效果比信噪比为-3 dB时的结果要好。总的来说,稀疏降噪自编码器实现有效数据降维和数值特征提取。

图5 3 dB信噪比测试数据数值特征投影结果

表2 3 dB信噪比测试数据数值特征评价结果
为进一步验证稀疏降噪自编码器模型的特征提取能力,顶部添加SVM(Support Vector Machine)分类器输出分类结果。同时基于SVM方法对原始样本进行处理,输出对比结果,如表 3所示。可以看到,经过稀疏降噪自编码器降维后的分类器识别率比直接基于SVM的识别率要高,验证了特征提取的有效性。

表3 3 dB信噪比测试数据分类识别结果
2.3 实际数据处理结果
对包含2类目标的实际数据频谱进行降维与数值特征提取处理模型同样包含4层,中间隐层节点数量分别为500和200,噪声比例设置为0.2,隐层1稀疏系数设置为0.05。训练数据为波束域数据,训练样本包含无标签样本3500个,带标签样本1000个。表4和图6分别为评价结果和特征投影,可以看到,类内距离和类间距离的变化趋势和仿真数据处理结果类似。与原始数据相比,数值特征的可分性有了明显提升,特征类间距比原始谱数据提升超过500%,类内距离降低接近85%,验证了稀疏降噪自编码器在水声目标识别中应用的有效性。

表4 实际数据特征提取评价结果
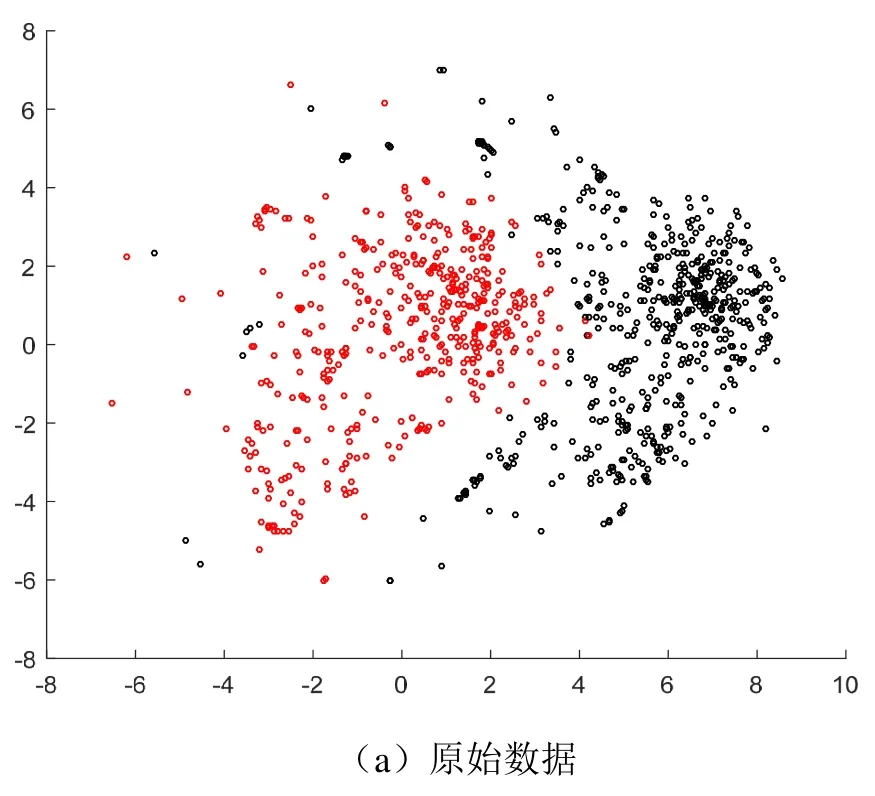

图6 实际数据特征提取投影结果
3 结论
本文针对水中目标辐射噪声,构建了含多隐层的稀疏降噪自编码器方法实现数值特征提取,采用类内距离和类间距离对提取的特征进行评价。仿真和实际数据的处理结果表明,提取的数值特征可分性较原始数据明显提升,特征类间距比原始谱数据提升超过500%,类内距离降低接近85%,验证了稀疏降噪自编码器用于水声目标辐射噪声特征提取与识别的有效性。
猜你喜欢
人民珠江(2019年4期)2019-04-20 02:32:00
电子制作(2018年19期)2018-11-14 02:37:08
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
自动化学报(2017年11期)2017-04-04 02:52:58
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
噪声与振动控制(2015年4期)2015-01-01 07:08:21
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
电测与仪表(2014年13期)2014-04-04 12:04:18
