
基于GATE的中文时间信息抽取方法
2021-01-08 11:40宋国民张三强贾奋励
测绘工程 2021年1期
宋国民,张三强,2,贾奋励
(1.信息工程大学,河南 郑州 450001; 2.69340部队,新疆 伊犁 835000)
随着互联网技术、信息技术的飞速发展,人类正逐渐步入信息社会。如何快速、自动地从各类纷繁复杂的媒体数据中获取用户关注的信息,已成为人类有效利用海量数据的关键。信息抽取(Information Extraction)作为从文本中自动获取信息的一种重要手段[1],已成为自然语言处理领域的重要研究内容。它是指从自然语言文本中识别并抽取出用户感兴趣的信息[2],多以结构化的形式对抽取结果进行描述和存储,以便用户查询和分析使用。信息抽取利用自然语言处理技术,通过对文本进行一系列处理,从中抽取出相关信息。信息抽取是与领域密切相关的,只能抽取系统预先定义的有限种类的信息[3]。
时间信息抽取是事件信息抽取的一项重要工作,在时空泛在信息、地理空间情报等信息获取与处理、关联、聚合和内容服务中具有重要作用。其作为信息抽取的一个重要研究内容,一直受到国内外学者的关注。常用抽取方法主要有基于规则匹配的方法和基于机器学习的方法两种[3-9]。基于规则匹配的方法是指在掌握各种时间信息表达规律的基础上,通过人工或半自动方式编制时间信息抽取规则,并基于这些规则实现时间信息的抽取。这种方法使用简便,易于理解和扩展,且抽取效率及准确率很高,但这些规则往往只面向特定语言和文本形式,人工工作量较大;基于机器学习的方法是指通过对标注时间信息的语料库的学习,训练各种机器学习模型,并基于该训练模型实现时间信息的抽取。这种方法可以充分利用语料库中己标注的上下文信息,获得较高的召回率,但该方法过分依赖标注语料的质量,受训练语料的范围和规模限制。
本文在分析时间信息抽取常用方法特点的基础上,提出利用GATE软件(General Architecture for Text Engineering)进行中文文本的时间信息抽取。介绍GATE的基本框架及各部分的功能作用;分析GATE用于中文时间信息抽取存在的不足,提出具体的改进措施;围绕基于GATE进行时间信息抽取的主要步骤,具体阐述各项改进内容;利用已标注时间信息的实验数据,对中文时间信息抽取进行实践检验,并对实验结果进行分析和总结。
1 GATE简介
GATE是英国谢菲尔德大学于1995年开始开发的、基于JAVA的、开源的自然语言处理框架,现已广泛应用于多语言信息抽取。其作为一个自然语言处理框架,将其框架内所有的自然语言处理资源划分为不同功能类型组件。CREOLE(Collection of REusable Objects for Language Engineering)作为GATE的核心组件之一,将可重用的处理资源进行了组合。CREOLE组件主要有三种样式:语言资源组件(Language Resources,LRs)、处理资源组件(Processing Resources,PRs)和可视化资源组件(Visual Resources,VRs)。语言资源组件是指与信息抽取有关的各种资源,如语料库、文档、词表和本体等;处理资源组件是指信息抽取过程中的不同数据处理模块,如分词模块、分句模块、词性标注模块和命名实体识别模块等;可视化资源组件是指构成GATE可视化操作界面的各种资源。
GATE除了提供CREOLE组件之外,还提供了一些专项功能组件,如用于英文信息抽取的ANNIE(A Nearly-New Information Extraction system)组件,用于建立信息抽取规则库的语法工具JAPE(a Java Annotation Patterns Engine)组件,用于支持不同语言文本(如中文、法语、德语、印度语,等等)信息抽取的组件。ANNIE是一个基于规则的、用于英文文本资源信息抽取和实体标识的组件,使用JAPE语言及其它处理资源来实现各种不同的信息抽取任务。其按照分词(tokeniser)、词表查询(gazetteer lookup)、分句(sentence splitter)、词性标注(POS tagger)、语义标注(semantic tagger)、命名实体识别(named entity recognition)、共指消解(ortho matcher)等信息处理顺序,实现英文文本的信息抽取[10]。JAPE是GATE的信息抽取规则定义语言。可结合不同语言特点编写JAPE规则,利用GATE自带的编译器,将其编译成可实现命名实体识别的数据处理模块。一个JAPE文件由若干条语法句子组成,每条语法句子又由一条或若干条规则构成。
2 基于GATE的中文时间信息抽取
GATE提供了中文信息抽取组件,用于中文文本信息的处理和抽取。但直接利用该组件进行中文时间信息抽取,其抽取效果并不理想,主要表现在:①对中文文本分词处理不够专业,无法实现真正意义上的中文分词;②中文时间领域词表不够完善,其定义的时间类型不完整,收集的时间词汇数量较少;③基于英文语法特点编写的JAPE规则没有结合中文时间表达特点进行改造,不能有效支持中文时间信息的识别和抽取。
为此,利用GATE进行中文时间信息抽取,需要针对以上三个方面问题分别开展工作:①引入优秀的中文分词软件,解决中文文本分词不专业的问题;②梳理中文时间类型,收集中文时间词汇,形成专业、完备的中文时间领域词表;③围绕扩展后的中文时间领域词表,结合中文时间表达特点,重新编写JAPE抽取规则,提高中文时间的识别和抽取准确率。
2.1 抽取流程
基于GATE 的中文时间信息抽取流程如图1所示,其主要步骤包括:①利用NLPIR/ICTCLAS 2015分词软件对原始中文文本进行分词和词性标注;②在第一步文本处理的基础上,删除中文文本的词性标注项;③扩展并完善GATE中的中文时间领域词表;④针对中文时间信息表达规律,重新编写GATE的中文时间信息抽取规则(JAPE);⑤将处理后的中文文本导入GATE中,利用修改后(扩展词表、抽取规则)的中文抽取组件(Chinese NE),识别并抽取中文时间信息。
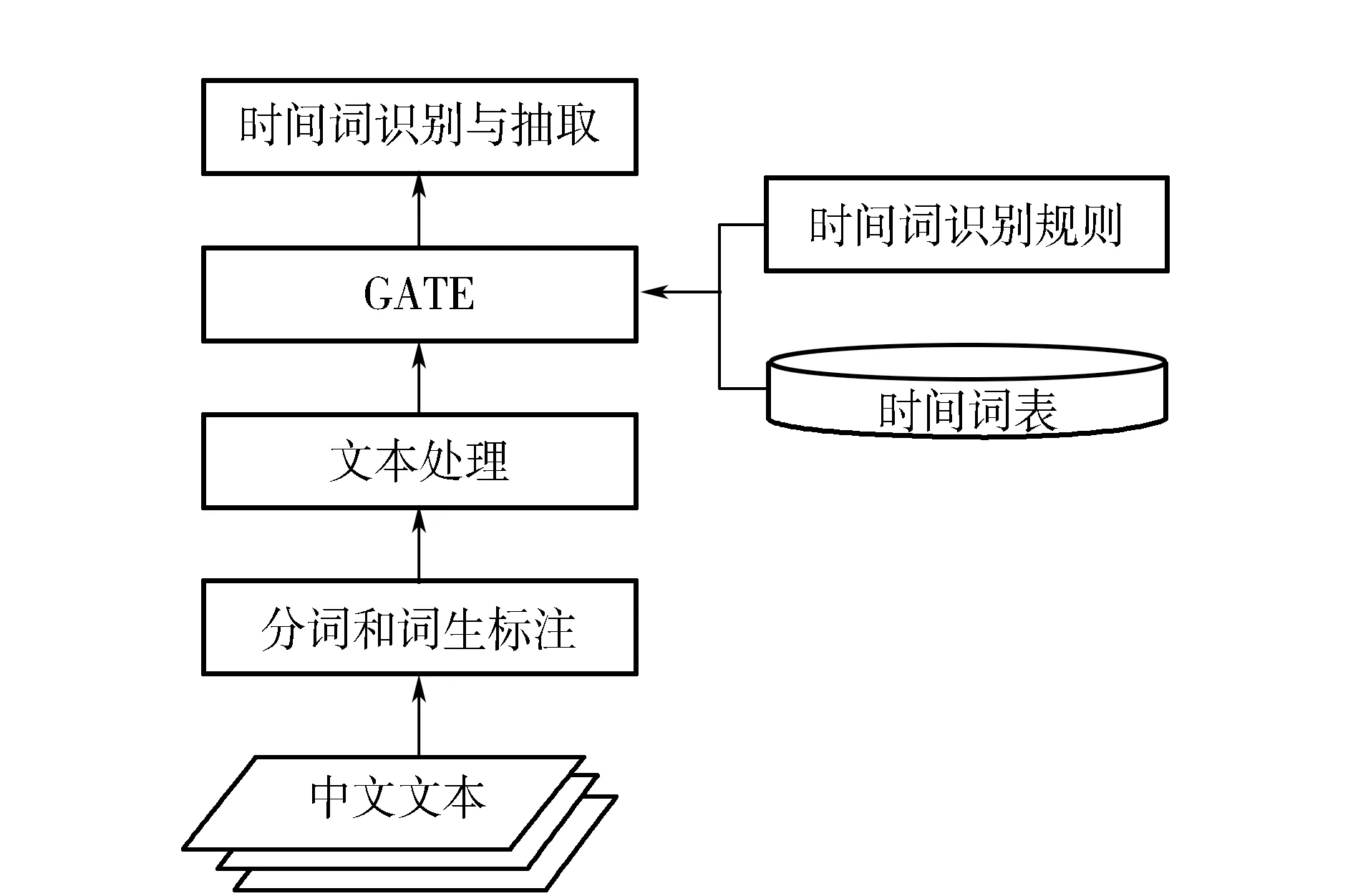
图1 基于GATE的中文时间信息抽取流程
2.2 分词及词性标注
对文本进行信息抽取,首要工作是对其进行分词和词性标注。英文以单词为基本单元组织的,不存在分词问题。中文文本的词汇之间并无明确的分割标识,必须进行分词处理。词性标注是指对分词后的每一个词增加词性标记,说明其词性类型,如名词、动词、副词等,为后续的命名实体识别和共指消解打下基础。但GATE对中文分词处理不够专业,无法实现真正意义上的中文分词,故需利用专业的中文分词软件对原始中文文本进行分词处理。
本文利用张华平博士团队的NLPIR/ICTCLAS 2015分词软件,对中文文本进行分词与词性标注处理。NLPIR/ICTCLAS是张华平博士团队在自然语言处理领域十多年研究工作积累的基础上研制出的分词软件,具备中英文混合分词、词性标注、命名实体识别、新词识别、关键词提取等功能,同时支持用户专业词表与微博分词。系统支持多种字符编码、多种操作系统、多种开发语言及平台。2006年推出的ICTCLAS 3.0分词正确率就高达98.13%。
基于GATE进行中文信息抽取时并没有用到词语的词性信息。利用NLPIR/ICTCLAS分词软件对中文文本进行分词与词性标注后,需将文本中的词性信息删除,只保留用空格隔开的分词信息,这样就与英文的分词形式保持一致。GATE中文信息抽取组件的chinese tokeniser(中文分词器)可将分割后的词语作为一个Token(标记),以进行后续的信息抽取工作。
2.3 扩展时间领域词表
词表是GATE进行信息抽取的基本语言资源,词表类型的完整性及词表内容的完备性直接影响着命名实体的识别效果[11-12]。GATE的词表由两类文本文件组成:一类是以lst作为后缀的词典文件,每个文件代表着一个实体类型,在文件中列举了该实体类型的各种概念形式[1],如day.lst文件列举了星期的表达形式;另一类是以def作为后缀的索引文件,其记录了词典文件中定义的实体主类(majortype)、子类(minortype)及相互间的关系。
GATE 8.0提供的中文时间词表文件主要由century(世纪)、decade(年代)、year(年)、season(季度)、month(月)、date(日期)、day(星期)、festival(节日)等8个词典文件及相关附属文件组成,每个词典文件分别对应1个时间类型。将其直接用于中文时间信息抽取存在两方面的问题:一是时间类型不完整,GATE 8.0只能识别上述8种时间类别,无法识别时钟时间、模糊时间、周期时间、时间段、农历时间、我国朝代及帝王年号时间等比较常用的时间类型;二是时间内容不完备,词典文件中提供的中文时间词汇较少。为此,在充分分析现有时间词典文件的基础上,围绕其存在的两方面问题有针对性地开展了以下工作:一是通过调整、增加中文时间词典文件,丰富时间类型。GATE 8.0自带8个中文时间词典文件,对应了8类中文时间类型。本文在其基础上,调整、拆分了个别时间类型,将原有的年、月、日、节日等4种时间类型分别拆分为公历和农历两种形式,形成8种中文时间类型;增加了时钟时间、模糊时间、周期时间、时间段、我国朝代及帝王年号时间等时间类型及对应的中文时间词典文件。通过调整与补充,使得系统可识别的时间类型达到20种,表1是调整、扩展以后的主要的时间词典文件及对应的时间类型;二是扩充现有词典文件的时间词汇,补充新增加时间词典文件的时间词汇,完善了中文时间词表文件。对于GATE 8.0已有的中文时间类型,通过补充其时间词汇,丰富了时间词典文件内容,如“月份”这一时间类型,原中文时间词典文件收录词汇75个,通过拆分为公历月和农历月两个时间类型,并扩充其时间词汇后,收录了与公历月相关的时间词汇297个,与农历月相关的时间词汇204个。对于新增加的中文时间类型,通过收集、分析、整理资料,形成其对应的中文时间词典文件,如中国朝代词典文件收录我国朝代词汇70个、我国帝王年号词典文件收录中国帝王年号词汇600余个,等等。通过补充与新增,使得中文时间词典文件收录的时间词汇由原来的365个扩充到2 400余个。
2.4 编写时间信息抽取规则
GATE是基于JAPE规则进行命名实体识别的。如果规则设置合理、完备,则可有效提高信息抽取的准确性。GATE的JAPE规则在后缀为jape的文本文件中进行定义。每个文件定义了一个实体类型的抽取规则,列举了在领域词表中定义的该类实体主类、子类及附属信息的抽取规则,如location.jape文件定义了地点的抽取规则,person.jape文件定义了人物的抽取规则。
GATE中文信息抽取组件自带的date.jape文件定义了中文日期的抽取规则,基于该文件可抽取出世纪、年代、年、季度、月、日期、星期、节日等日期实体的信息。但该规则编写较为简单,无法有效支持中文时间的命名实体识别,主要存在两方面的问题:一是因GATE8.0自带的时间领域词表所对应的时间类型有限(只有8种),故只能支持该部分类型的时间实体识别;二是因编写的时间实体抽取规则较为简单,只能对由这8种时间类型定义的基本时间单元实体进行识别(如“2019年9月2日”,系统将其识别为“2019年”“9月”“2日”三个独立的时间实体,而无法作为一个整体加以识别),且对系统自带时间领域词表所定义的时间实体识别率也不高。因此,本文在扩展时间领域词表、分析中文时间信息表达规律的基础上,对GATE中文信息抽取组件自带的日期抽取规则文件(date.jape)进行了修改和扩展,主要包括:一是针对扩展的时间类型,增加识别这些时间类型实体的抽取代码,使得系统可以识别时钟时间、农历时间、我国朝代及帝王年号时间等各种新增时间类型的时间实体;二是修改、扩展完善原有时间抽取代码,使其不仅能够识别由表1所列举的各种基本时间单元及多个时间单元组合的时间实体,还能识别时间段、周期时间、模糊时间等复杂类型的时间信息。图2是识别时间段的JAPE规则节选,通过该段抽取规则的定义,系统可识别诸如“今年1到3季度(月)”“2019年5~8月”等多种形式的时间段实体。
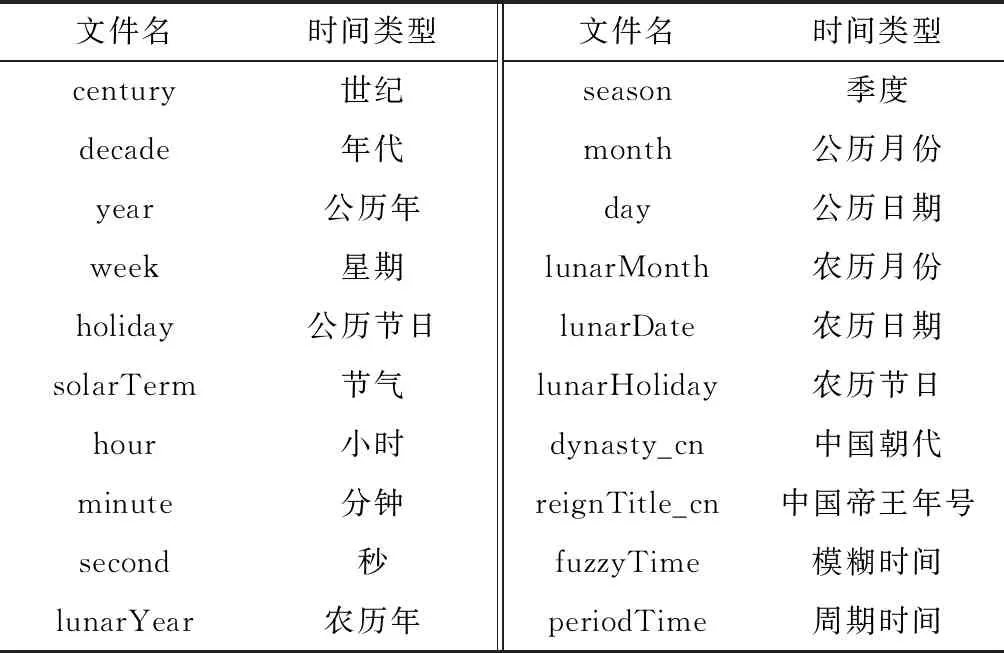
表1 主要的时间词典文件及时间类型

Rule: DateSpan( (({Lookup.majorType == date_pre } // 时间前缀,如“前”“后”“最近的” |{Lookup.minorType == year_spec} // 相对时间(年),如“今年”“前年” |{Lookup.minorType == season_spec}// 相对时间(季度),如“上季度”“本季度” |{Lookup.minorType == month_spec} // 相对时间(月),如“当月”“次月” |((YEAR_DIGITS)(YEAR)) // 年 |{Lookup.minorType == month})? // 月 ({Lookup.majorType == number })? // 数字 {Lookup.majorType == to } // 时间连接词,如“至”“到”“-” {Lookup.majorType == number } // 数字 {Lookup.majorType == time_unit} // 时间单位,如“年”“季度”“月” ) … …) :tag→ :tag.DateSpan = {kind = DateSpan, rule = DateSpan}
3 实验与分析
3.1 实验数据
本文实验数据采用了2010年SemEval-2010测评TempEval-2任务提供的中文训练语料,该任务训练语料包含了44篇中文文章和766个中文时间词,时间词基本涵盖表1列举的时间类型。
3.2 实验测评标准
采用常用的准确率P(Precision)、召回率R(Recall)和F1值(F-measure)作为时间信息抽取的评测标准,三者的计算式如下:
3.3 实验结果与分析
实验按照图1所示的流程,对44篇中文文章进行了分词处理,在对GATE 8.0进行中文时间领域词表扩展及重写中文时间信息抽取规则后,基于修改后的中文抽取组件(Chinese NE),识别并抽取文章中的中文时间信息(图3)。通过对实验数据中的时间信息抽取结果进行统计分析,可以计算得到准确率P、召回率R和F1值分别为94.9%、93.1%、94%,可见该方法具有较好的时间信息识别和抽取能力。同时,发现影响时间信息抽取及识别准确率的主要原因有:①时间领域词表没有记载的时间词类型或样式,系统将无法识别;②时间信息抽取规则中没有定义到的、复杂的、特殊的时间表达式,系统可能会将其识别成多个独立时间词,如“星期五(四月五日)上午八时”;③对于没有时间单位的时间词,系统将无法识别,如歌曲“我的一九九七”中的“一九九七”;④一些即可以作时间词、又可以作副词的多义词语(如一直、同时),被系统错误识别为时间词,如“加工贸易在广东外经贸发展中占有举足轻重的地位,同时也是粤港澳台经贸合作的重要内容”中的“同时”;⑤语料中将时间段标注为两个独立时间词,本文通过制定时间段抽取规则,将其标识为时间段,如“一九九六至二○○○年”。
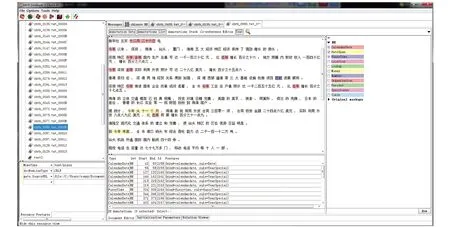
图3 中文时间信息抽取示例
4 结束语
利用GATE的自然语言处理框架,通过引入外部工具进行中文分词、扩展中文时间领域词表、重新编写中文时间抽取规则,实现了中文时间信息的识别和抽取,达到较好地抽取效果。由于时间和精力的原因,对事件时间、外国历史朝代及年号等领域时间尚未建立词表,也没有利用中文词性标注信息抽取时间信息。后续可围绕这些方面开展工作,以提高时间命名实体识别、抽取的准确率和召回率。
猜你喜欢
能源工程(2022年2期)2022-05-23
校园英语·月末(2021年13期)2021-03-15
英语世界(2021年13期)2021-01-12
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
国家图书馆学刊(2016年2期)2016-10-09
太阳能(2015年11期)2015-04-10
图书馆建设(2012年3期)2012-10-23
