
基于数据挖掘的缺血性脑卒中患病风险预测
2021-01-06 09:41侯玉梅曾慧张晨阳张重阳张利军高秋烨
中国老年学杂志 2021年1期
侯玉梅 曾慧 张晨阳 张重阳 张利军 高秋烨
(燕山大学 1经济管理学院,河北 秦皇岛 066004;2理学院;3秦皇岛市第一人民医院)
在我国,脑卒中的死亡率远高于世界平均水平,成为居民第一大死亡原因,每年死于脑卒中的患者达188万〔1〕,是欧美等发达国家的4~5倍,甚至超越了发展中国家印度〔2〕。脑卒中的发病率也由1993年的0.40%上升至2013年的1.23%〔1〕,且以每年8.7%的速度持续增长;其再入院率大于30%,5年内再现率高达54%。同时,脑卒中的患病人群具有年轻化的趋势〔3〕。目前,脑卒中尚缺乏理想的治疗方法,高危个体的早期发现成为脑卒中防治的关键。相关研究表明,采取合理规范的措施控制脑卒中的高危因素,可以延迟或减缓脑卒中的发生〔4〕。
针对缺血性脑卒中,国外学者已经构建了稳定的评分方法与预测模型〔5~10〕,其中专家普遍建议选择改良的弗明汉脑卒中量表、汇集队列方程、脑卒中风险计算器等工具进行缺血性脑卒中风险评估〔11〕,但是这些模型主要适用欧美人群,对我国人群的风险预测效果不佳。国内学者更多是对脑卒中发病因素的探究〔12~15〕。本文利用数据挖掘的决策树与Logistic回归方法构建预测模型,以此发掘缺血性脑卒中的发病规律,为脑卒中的提前干预与控制提供依据。
1 资料与方法
1.1资料来源 研究资料来源于河北省合作医院开展的居民脑卒中基线调查数据。研究对调查范围内居民进行长期随访来收集数据,平均随访时间为18个月。缺血性脑卒中数据来自于随访时期内出现缺血性脑卒中疾病的患者档案。非脑卒中数据从同一调查中,抽取无心脑血管疾病的健康人群档案作为调查样本。
本研究收集的有效样本数据共计1 288例,包括缺血性脑卒中患者数据567例,非患者数据721例。其中,男性624例(48.4%),女性664例(51.6%),平均年龄(56.30±16.89)岁。调查内容主要涉及:性别、职业、年龄、心脏病史、高血压史、糖尿病史、家族史、吸烟史、饮酒史、高同型半胱氨酸症史、高脂血症史、高尿酸症史、动脉粥样硬化史、颈动脉狭窄史、体重指数(BMI)、心率、呼吸频率、收缩压、舒张压、腹型状况、精神状况。调查数据以最后一次调查时获取的资料为参考依据。
1.2研究方法 ①数据预处理:数据清洗:对原始数据集进行整理分析;剔除原始数据集中诊断不明,或患有缺血性脑卒中疾病但缺失重要资料而无法配合研究的数据。对于超出合理范围的取值用指定值替代;填补原始数据集中的空缺值,标称空缺值用众数代替,体重空缺值参考国际标准体重计算方法,其余空缺值用平均数代替。
数据变换:将原始数据转换为统一的,适合用于再处理的数据。变换后的数据可以提高挖掘的有效性和准确性。如:参照世界卫生组织订立的标准将身高、体重转换为BMI,变换后的BMI为中立可靠的指标,具有参考价值。
变量说明:吸烟史根据世界卫生组织(WHO)慢性病调查问卷定义,每天至少吸1支烟,且持续或累计1年以上;饮酒史定义,每周至少饮酒1次,且持续或累计6个月以上。
②算法选择:本文采用数据挖掘的决策树算法与Logistic回归算法构建预测模型,Logistic回归算法是预测自变量与因变量之间关系的新型回归技术,规避了传统回归中过于严格的问题;决策树算法是一种新的多因素分析方法,决策树构建的模型结果简单,易于解释,且决策树分析对于数据的分布没有要求。
③算法实现:本研究中两种算法均由SPSS23.0统计软件实现,其中,Logistic回归算法以是否患缺血性脑卒中(是=0,否=1)为因变量,其余样本变量为协变量,筛选缺血性脑卒中患病相关性变量。以P<0.05具有统计学意义,然后将筛选出来的相关性变量纳入Logistic回归中构建预测模型。决策树算法采用CHAID卡方自动交互法建立,在筛选缺血性脑卒中患病影响因素主效应的同时构建交互项,最终将主效应与交互项纳入回归算法中再次筛选,同时构建缺血性脑卒中患病风险预测模型。
将上述构建的两个模型进行对比分析,以预测概率为评判标准验证模型的准确率,进行受试者工作特征(ROC)曲线预测程度拟合。研究中变量赋值及人口统计学特征见表1。

表1 变量赋值及人口统计学特征〔n(%)〕
2 结 果
2.1Logistic回归分析 将收集的样本变量纳入Logistic回归方程中筛选出与缺血性脑卒中患病相关的危险因素,筛选结果(见表2)显示性别、职业、年龄、高血压史、糖尿病史、吸烟史、BMI、高同型半胱氨酸症史、高脂血症史、收缩压、舒张压、精神状况及心率是缺血性脑卒中发病的危险因素。据此,构建Logistic回归模型结果为:Logistic(Y1)=0.637X1-0.147X2-0.049X3+2.029X4-0.553X5+0.942X6-0.302X7-0.552X8+2.060X9-0.611X10-0.779X11-2.974X12+0.022X13。
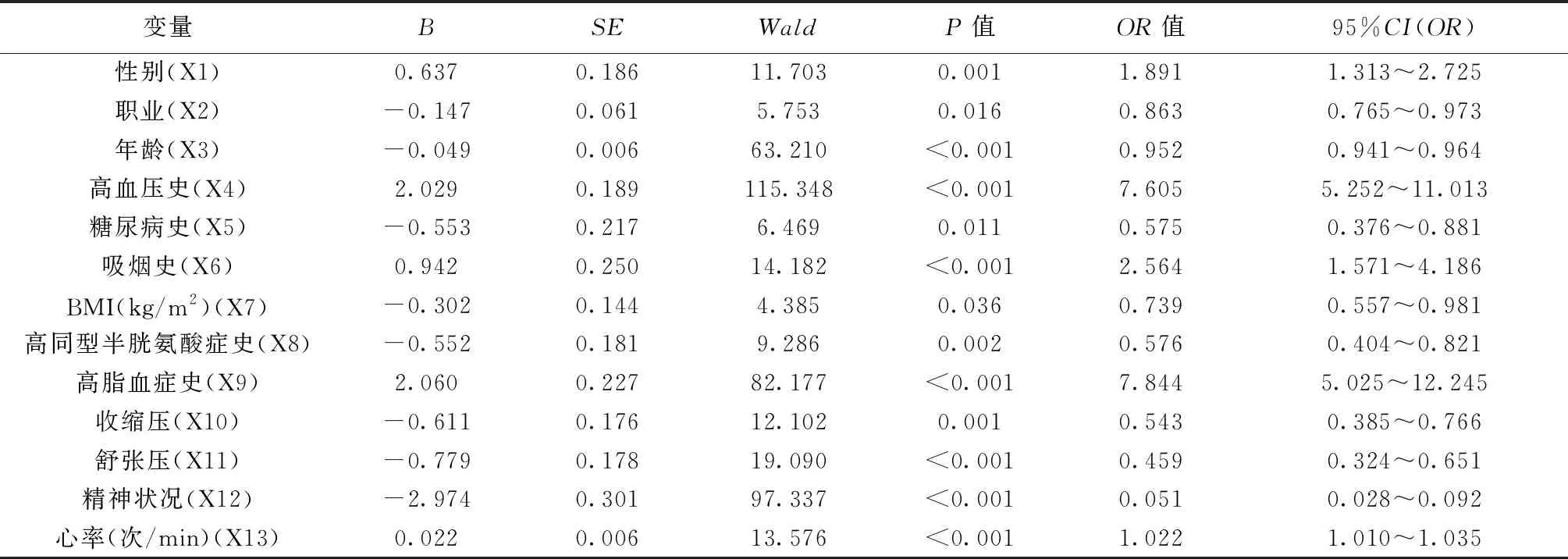
表2 Logistic回归筛选结果
2.2决策树分析 应用软件SPSS23.0中的决策树模型,以是否患缺血性脑卒中(是=0,否=1)为因变量,其余变量为协变量,生长法为CHIND,相关参数取默认值构建模型,同时采用CHAID卡方自动交互检查对所有的变量进行筛查,构建决策树(如图1)。
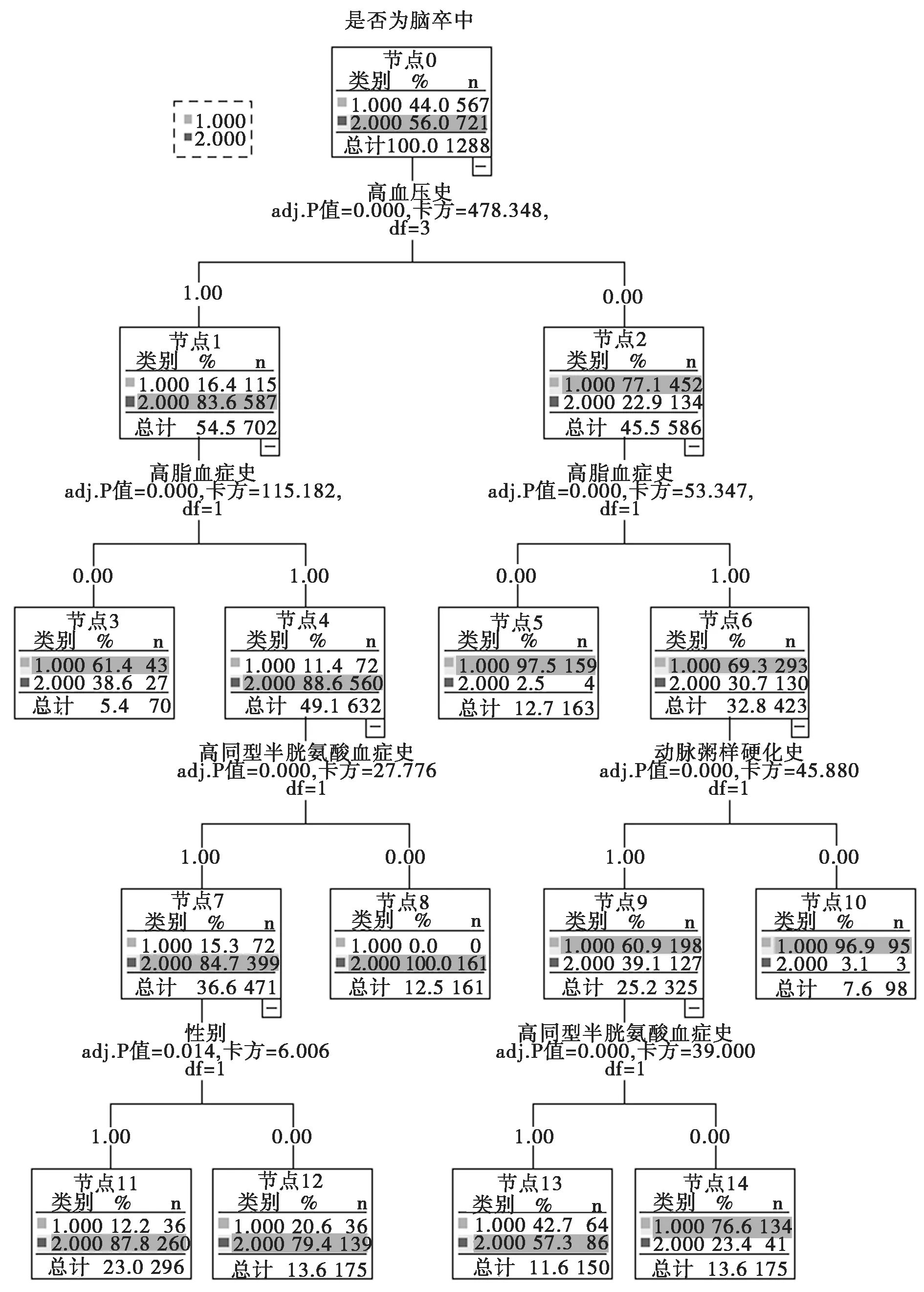
图1 决策树结果
决策树深度为4层,共计15个节点,8个终端节点。通过决策树可以得出各个变量之间的交互作用及患病危险因素的重要程度。决策树第一层按照是否具有高血压史进行划分,说明高血压史是缺血性脑卒中患病的第一大危险因素。决策树第二层无论是否患有高血压史(权“0”和权“1”),结果都显示高脂血症史为第二大危险因素,且高血压史与高脂血症史之间具有交互作用。决策树左侧分支中,不具有高血压史的人群分支(权“1”),高同型半胱氨酸症史是第三大危险因素,性别是第四大危险因素。同时决策树显示高脂血症史与高同型半胱氨酸症史,高同型半胱氨酸症史与性别之间存在交互作用。决策树右侧分支中,具有高血压史的人群分支(权“0”),动脉粥样硬化史是第三大危险因素,高同型半胱氨酸症史是第四大危险因素。决策树显示高脂血症史与动脉粥样硬化史,动脉粥样硬化史与高同型半胱氨酸症史之间存在交互作用。
利用构建的决策树可以发现主效应共有5项,它们是高血压史、高脂血症史、高同型半胱氨酸症史、动脉粥样硬化史、性别;存在交互作用发生的项有:高血压史与高脂血症史、高脂血症史与高同型半胱氨酸症史、高同型半胱氨酸症史与性别、高脂血症史与动脉粥样硬化史、动脉粥样硬化史与高同型半胱氨酸症史。以是否发生缺血性脑卒中(是=“0”,否=“1”)为因变量,决策树模型中的主效应及构建的交互效应为协变量,纳入Logistic模型中进行分析。分析结果见表3。结果发现缺血性脑卒中发病的主要危险因素是高脂血症史、高同型半胱氨酸症史及交互项高血压史与高脂血症史、高脂血症史与高同型半胱氨酸症史、高同型半胱氨酸症史与性别。据此,构建的回归模型为:Logistic(Y2)=-0.987X14-2.306X15+2.850X16+2.027X17+1.010X18。
2.3模型验证 为了验证上述构建的两个模型,绘制ROC曲线进行评估(见图2)。决策树模型ROC曲线下面积为0.840(0.817~0.862),标准误差为0.012,约登指数为0.750,对应的灵敏度为0.877,特异度为0.873。Logistic回归模型中ROC曲线下面积为0.914(0.899~0.930),AUC面积大于0.9,标准误差为0.008,约登指数为0.768,对应的灵敏度为0.861,特异度为0.907。

表3 决策树下回归筛选结果
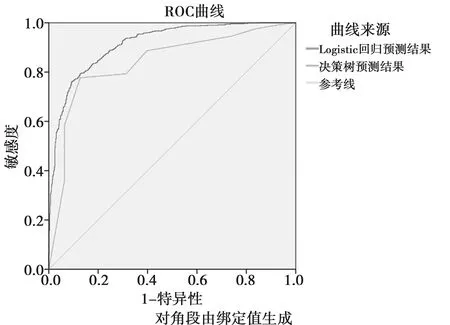
图2 两种不同方法模型分析拟合效果ROC曲线
3 讨 论
目前,国内的疾病预测方法使用较多的有神经网络法、KNN算法、马氏预测法等〔16~18〕。本文将决策树算法与Logistic回归分析方法运用于缺血性脑卒中患病风险预测中,在分析缺血性脑卒中患病影响因素的同时,构建不同的对比模型,进一步建立和完善了适合中国人群的缺血性脑卒中预防风险评估工具。与传统的评分法〔7〕相比,本文对缺血性脑卒中的危险因素进行量化,将评分等级转化为预测概率,使得缺血性脑卒中的患病风险预测更加科学;与神经网络法〔16〕相比,本文建立的模型简单明了,可以更好地探究发病规则;与KNN算法〔17〕相比,KNN算法需要剪辑样本点,计算量较大,而本文的方法计算简便,预测效率更高;与马氏预测法〔18〕相比,马氏预测是预测未来几年人群的发病概率,而本文是根据目前实际状况,及时预测发病概率,时效性更强。
从危险因素来看,高血压史与高脂血症史是影响缺血性脑卒中的最主要因素,控制血压与血脂对缺血性脑卒中的防治与预防起着非常重要的作用。另外,性别、高同型半胱氨酸症史等因素也是影响缺血性脑卒中患病的重要因素。从预测结果来看,Logistic回归模型中ROC曲线下的面积为0.914(0.899~0.930),表明该模型分类准确率较高,决策树模型ROC曲线下的面积为0.840(0.817~0.862),说明分类准确率良好;另外,决策树模型的灵敏度较高,说明决策树模型预测未来真正患者的能力较好,Logistic模型的特异度较高,说明Logistic模型预测未来非患者的能力更好。对比发现,两个模型的稳定性与预测准确率均较好,但Logistic回归分析构建的模型综合性能更佳。这是因为Logistic模型中包含决策树的建模变量,同时包含更多具有研究意义的变量,使得构建的模型更稳定。另外,本研究包含的数据量有限,可能会导致决策树结果不稳定,模型结果失真,研究认为〔19〕,决策树分析是将所有变量放在同一层面的固定分析,这种决策树结构的算法存在“顺序偏差”,建议决策树模型与其他模型结合使用。
综上所述,本文建立的模型直观简单,对发病规律的探究更加完善,居民可以根据自己的实际健康情况随时预测个人缺血性脑卒中患病风险概率,及时预防缺血性脑卒中的发生,具有很好的时效性与准确性。但是,由于时间与人力资源有限,所采集的医疗数据无法涵盖所有可能的危险因素,且SPSS中不利于对参数不断调整。因此,今后的研究中需要对所建立的模型进一步完善。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
现代检验医学杂志(2016年5期)2016-08-20
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
中国卫生标准管理(2015年24期)2016-01-14
中国当代医药(2015年22期)2015-03-01
中国当代医药(2015年21期)2015-03-01
郑州大学学报(医学版)(2015年1期)2015-02-27
西部中医药(2015年9期)2015-02-02
中国药业(2014年24期)2014-05-26
