
语音识别实现方法
2021-01-05 19:38李姝仪李云洁蒋昊轩郭宗昱吴可欣刘博
科技风 2021年35期
李姝仪 李云洁 蒋昊轩 郭宗昱 吴可欣 刘博
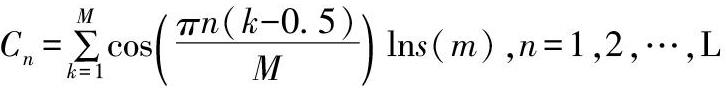
摘 要:语音识别(Automatic Speech Recognition,ASR)是人工智能领域里一个重要的研究方向。对于如何实现语音识别,将语音序列转化为文本序列,简单来说就是确定问题,选择一个模型之后再训练它。随着开源社区的不断扩大,加速了语音识别领域的研究进程,一些语音识别开源工具例如CMUSphinx、Julius、HTK、CMUSphinx、ISIP等也陆续兴起,被研究者们广泛运用。本文首先将介绍目前可以开发语音识别的工具CMUSphinx,Kaldi以及深度学习平台;然后简述CMUSphinx开源工具的实现流程;其次讲述运用Kaldi的语音识别实践过程;最后总结在语音识别实现中的一些问题以及未来的研究方向。
关键词:语音识别;CMUSphinx;Kaldi;深度学习
1 语音识别工具
1.1 CMUSphinx
CMUSphinx——一种Carnegun大学开发的所有研究语音信息识别技术系统。2000年,Sphinx小组在几个语音识别器组件中一直在做开源几个器组件的工作。包括声音解码器和模型还有程序、资源有声学模型训练软件、语言模型和字典编辑软件。
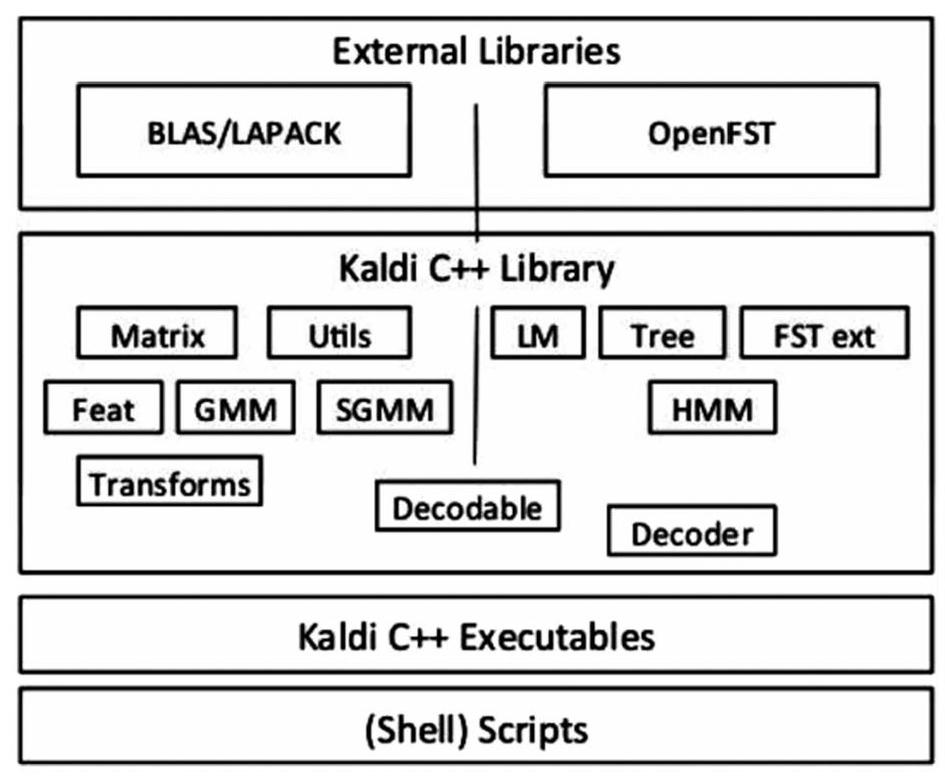
1.2 Kaldi
相较于早期开发的语音识别相关的开源工具包HTK,CMUSphinx等,Kaldi存在着自己的特性,例如代码容易阅读和理解;大量的线性代数支持利于其在不同线性代数库之间切换;尽可能通用的算法实现,避免使用只为特定任务服务的代码;有着非常完整的语音识别系统训练脚本;拥有繁荣的开源社区、开放的代码许可。这些优势都大大降低了kaldi作为语音识别工具包的门槛,也使得kaldi吸引了大批的用户,成为语音识别工具包中的佼佼者。
1.3 深度学习平台
近年来,由于深度学习的应用,使得语音识别技术也更加先进。一系列算法、技术的应用,也使得语音识别系统的建立并不局限于某个平台。当下受到广泛运用的深度学习框架有TensorFlow(Google首先开发并使用),PyTorch(Facebook首先开发并使用),CNTK(Microsoft首先开发并使用),MXNet(Amazon等使用)[1]。
通用深度学习框架的内核语言多为C++,前端接口语言多支持Python,这样的语言搭配使用方法让框架的运用既灵活又不失效率。相较于kaldi这样术业有专攻的平台,深度学习方法较多地作用于声学模型和语言模型部分(或者端对端模型),并且还能拓展应用于多种任务。
2 CMUSphinx实现细节
Sphinx是中国用于识别套件的领先语音识别工具包之一,有多种用于管理的工具和能用来建造语音应用系统程序。卡耐基-梅隆的斯芬克斯包含许多不同的任务和应用的开发包。选择有时是很难的。以下是每个开发套件的目的:
Pocketsphinx—C语言开发轻量级语音识别引擎的轻量级识别器库;
Sphinxtrain—声学模型训练工具;
Sphinxbase—Pocketsphinx和Sphinxtrain所需的支持库;
Sphinx4—用Java编写的可调节识别器。
(型号包括声学模型,语言模型以及拼音字典)
声学的特征都被声学模型所包含。其中n-gram是模型里最常用的,有限状态语言模型以及字令统计都被包含而且定义语音序列是通过有限的状态自动机(有时重量)来进行。如果想要高精度,模型的搜索空间限制必须非常成功。意思是它能比较好的推断出下面的一个词。语言模型通常限制注意到包括了的词语。对于这个问题,属于名称识别,模型可以包含小块,比如单词以及音素。需要注意的是,这个开发里面的搜索空间是很差的,其识别精度会低于前面的语言学习模型(基于单词)[2]。
字典包含单词至音素的映射,映射一般都不太有效果。不过字典并非是唯一一种把单词映射到电话的方法。我们也能通过机器学习算法来学习其他可能复杂一些的功能。
3 Kaldi语音识别实现基本流程
3.1 数据准备
在准备训练数据时,我们需要完成选择训练数据和将数据整理成工具可以支持的格式这两个任务。关于构建符合Kaldi脚本规范的数据资源文件,包括数据文件夹data和语音文件夹data/lang中。
3.1.1 基本数据
通常会将数据分为训练数据、开发数据和测试数据三个子集,分别用train、dev和test表示[3]。當kaldi使用thchs30(由清华大学语音与语言技术中心出版的开放式中文语音数据库)进行训练操作时,Thchs30经过初步处理后会得到四种文本文件,可以直接打开查看(比如训练集则放在data/train下)。而且utt2spk和spk2utt这两个文件是kaldi处理时必须存在的。需要注意的是对于不同数据源或任务,可能需要另外准备一些文件。
3.1.2 语言资料
语言资料方面kaldi需要将文件存放于data/dict下,其余数据整理详情可参考文献[1]。当用于语音识别实验训练的数据都准备齐全后,就需要Kaldi对这些数据进行处理。
3.2 语音信号特征提取
经过预处理的信号,已经是有一定纯度的音频信号,对于任何物体的识别或者是语音的识别,从机器识别的方向看,要抓住事物唯一的特征。[4]所以语音识别在进入声学模型训练之前是要对语音的特征进行提取,一段语音信号用特征值来表示,因为有很多的特征值,就用特征向量来表示。提取特征值最常用的是MFCC(梅尔频率倒谱系数)[5]。
接下来叙述MFCC的一般过程,第一步、将实际频率于Mel频率通过公式,第二步、在得到Mel频率之后进行傅里叶变换,通过傅里叶变换的目的是看到信号能量的具体分布。第三步、利用带有Mel尺度的三角滤波器过滤信号,第四步、因为过滤的信号是离散的数据,所以通过反离散余弦变换就得到了我们需要的MFCC[6],公式如下:
3.3 声学模型训练过程
3.3.1 获得语料集的音频集和对应的文字集
可以通过提供更精确的对齐,发音(句子)级别的起止数据时间,但这不是我们必须的。
3.3.2 将获得的文字集格式化
Kaldi需要各种格式。训练过程将使用每个句子的开始和结束时间、每个句子的说话人ID以及文本集中使用的所有单词和音素。
3.3.3 从音频文件提取声学特征
MFCC或者PLP被传统教学方法进行广泛使用。对于NN方法有所差异。
3.3.4 单音素训练
单个音素训练不使用当前音素之前或之后的上下文信息,而三个音素使用当前音素、前一音素和后一音素。
3.3.5 基于GMM/HMM的框架
(1)将音频根据声学模型对齐。声学模型的参数在声学训练时获得,然而,这个发展过程我们可以通过使用训练和对齐的循环系统进行管理优化。这也称为维特比(维特比)训练(包括前后向和期望最大化密集型计算过程)。通过对齐音频和文本,可以使用其他训练算法来改进和细化参数化模型。所以,每一个学生训练方法步骤会跟随自己一个对齐步骤。
(2)训练三音素模型。单音素模型仅表示单个音素的参数,但音素随上下文而变化。三音素模型使用上下文前后的音素来显示音素的变化。
并不是所有的单音素组合都存在于提供的文字集中,总共有3个可能的三音素,但是通过训练集所包含的是一个企业有限的子集,并且可以出现的三音素进行组合方式也要有一定的次数以方便学生训练,音素决策树方法会将我们这些三音素聚类成更小的集合。
(3)根据声学模型重新对齐音频以及重新训练三音素模型。重复上述步骤1和2,并添加额外和更精细的三音素模型训练,通常包括增量训练、lda mllt和sat。对齐算法主要包括学生说话人对齐和FMLLR。
(4)训练算法。增量算法计算特征的一阶和二阶导数,或动态参数,以补充MFCC特征。
LDA-MLLT(Linear Discriminant Analysis-Maximum Likelihood Linear Transform),LDA根据降维特征向量建立HMM状态。MLLT根据LDA降维后的特征空间获得每一个说话人的唯一变换。MLLT实际上是说话人的归一化。
Sat(speaker adaptive training)。Sat还使噪音正常化。
(5)对齐算法。实际的对齐进行操作是一样的,不同文集使用情况不同的声学分析模型。
3.4 解码实现——维比特算法
维比特算是经过一个T*S的矩阵实现的,T是帧数,S是HMM状态总数。按帧遍历声学特征,每一帧的每个状态,把前一帧的累积状态和这一这一帧的状态累加,选择这一帧代价最低的当成这一帧的最佳路径。Kaldi的解码器大多基于维比特算法,kald的解码器有很多例如Simple Decoder,Fast Decoder,这些都是以库的形式存在,在需要的时候选择合适的解码器[7]。
4 总结
Kaldi至今仍然是很强大的语音识别工具,由于代码是开源的,所以如今它在Github上也很活跃。Kaldi是由GMM-HMM模型发展起来的,虽有众多优势,但也存在着一些弊端,比如在声音嘈杂的环境下的语音识别,语音识别迁移功能的欠缺,以及此模型层次较浅以至于不能捕捉数据间的深层特性。所以,随着人工智能的发展出现了基于DNN—HMM的模型算法。
GMM—HMM是基于概率统计的方法,来得到参数模型的,这也就意味着原始数据需要的特别庞大,原始数据的多少,与最后识别的准确性是正相关的。HMM—GMM不能学习深层的非线性变换特征,而DNN—HMM可以。在如今语音识别领域又出现了端对端的语音识别,后一种的模型会将前一种的缺点加以改进,使得语音识别更加的简便,高效。虽然如今各种工具应接不暇,但是如果我们能善假于物,明了其中的原理,也能够提高语音识别技术研发的效率。
参考文献:
[1]汤志远,李蓝天,王东,蔡云麟,石颖,郑方.语音识别基本法[M].电子工业出版社,2021.
[2]csdn.语音识别基础篇(一)-CMU Sphinx基本简介[EB/OL].https://blog.csdn.net/itas109/article/details/78568591,2017-11-18/2021/8/28.
[3]陳果果,都家宇,那兴宇,张俊博.Kaldi语音识别实战[M].电子工业出版社,2020.
[4]王凯,马明栋.基于Kaldi的语音识别[J].计算机技术与发展,2021,31(01):13-17.
[5]章武峰.基于Kaldi的中文语音识别研究[D].华中师范大学,2020.
[6]杨胜捷,朱灏耘,冯天祥,陈宇.基于Kaldi的语音识别算法[J].电脑知识与技术,2019,15(02):163-166.
[7]朱春山.基于Kaldi的语音识别的研究[D].南京邮电大学,2018.
基金项目:空中交通管理学院创新创业实践基地,项目名称:基于深度学习的无线电陆空通话语音识别软件研究与开发(项目编号:202010059083)
作者简介:李姝仪(2000— ),女,汉族,云南人,本科,研究方向:语音识别;李云洁(1998— ),男,汉族,云南人,本科,研究方向:语音识别;蒋昊轩(2001— ),男,汉族,四川人,本科,研究方向:语音识别;郭宗昱(2000— ),女,汉族,湖南人,本科,研究方向:语音识别;吴可欣(2000— ),女,汉族,湖北人,本科,研究方向:语音识别。
*通讯作者:刘博(1985— ),男,汉族,陕西人,硕士,中级,研究方向:空中交通管理、机器学习。
猜你喜欢
中国新通信(2016年21期)2017-01-06
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年12期)2016-06-14
物联网技术(2015年9期)2015-09-22
现代电子技术(2015年11期)2015-07-28
