
多光谱面部识别系统研究综述
2021-01-05 12:31陈丽李志红李艳萍任晓光包长春
科技风 2021年35期
关键词:神经网络
陈丽 李志红 李艳萍 任晓光 包长春

摘 要:多光谱面部识别系统基于不同光谱图像开发,近年来取得了快速进步。本文首先介绍了多光谱面部识别系统的组成,然后在检索相关研究论文并分析的基础上,介绍了用于面部分析的公共多光谱数据库,识别系统的性能评价方法,分析了对面部识别系统的实现方法及应用,最后对多光谱面部识别系统的发展趋势给出了相关分析。本文旨在为多光谱面部识别系统的研究提供参考。
关键词:面部识别;多光谱图像;神经网络
中图分类号:TN707
当今社会,面部识别系统的应用越来越广泛,例如企业收集员工信息(如上下班打卡),或是智能手机进行用户身份验证。在检测图像时,传统的面部识别系统仅使用可见光谱(visible spectrum,VIS),越来越多的研究发现这些系统存在一定的局限性,如面部有遮挡、姿势发生变化、被检人员不配合,以及光线变化时,其识别精确度会受到不同程度的影响[1]。
为了提高面部识别效率,基于多光谱图像的面部识别系统被开发出来。红外光谱,包括近红外(Near Infrared,NIR)、短波长红外(Short Wavelength Infrared,SWIR)、中波长红外(Medium Wavelength Infrared,MWIR)和长波长红外(Long Wavelength Infrared,LWIR)光谱,已成功地用于面部识别系统。与VIS光谱相比,红外光谱基本不受光度差异等不利条件的影响,使得多光谱面部识别系统适应性更为广泛。
本文首先介绍了多光谱面部识别系统的组成,然后在检索并分析相关文献的基础上,介绍了图像数据库、性能评价和识别系统实现方法,并对其发展趋势进行了分析,旨在为相关研究提供借鉴。
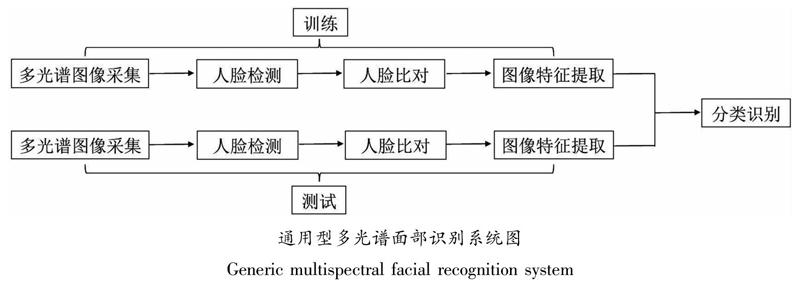
1 多光譜面部识别系统的基本组成
多光谱面部识别系统由5个部分组成(见下图),即图像采集、人脸检测、人脸比对、特征提取和分类识别,具体地说,其过程为:利用相机采集多光谱图像;对图像进行人脸检测,获得人脸边界框,并对图片进行裁剪,去除与被检测人员无关的背景;提取面部地标,如鼻子、眼睛、下巴和耳朵等,利用其位置信息,系统即可自主进行面部对齐,需要指出的是面部检测和面部地标提取可在所有光谱图像上进行,但一般优先使用可见光图像,再使用其他光谱图像辅助;面部特征提取,具体提取哪些特征取决于所用的模型方法,且提取的面部特征包含或嵌入了表征被检测人员身份的深度信息;对提取的面部特征按照一定的算法进行分类,最终确定图像中人员的具体身份。相比于仅使用VIS光谱的面部识别系统,多光谱面部识别系统能够更准确地识别被检测人员,尤其在访问高安全级别场所时,能确保只有授权人员允许进入。
2 发表论文概况
对多光谱面部识别系统的研究论文进行检索,具体做法为:利用艾斯维尔的ScienceDirect数据库检索有影响因子的期刊上发表的、光谱面部识别相关的所有研究论文,并排除会议论文,时间范围限定在2000—2020年之间。通过检索发现,一共315篇论文发表在132种学术期刊上,且2016—2020年间多光谱人脸识别的报道呈指数增长,归纳起来有三个因素促进了其发展:(1)近红外和长波红外光谱波段的相机价格显著降低,大大推动了其普及性;(2)为增强识别系统的效率,需要减少系统中的人为干预,这就要求增加新的技术手段分摊原来人的工作任务;(3)深度学习在人脸识别系统中的实现,进一步推动多光谱识别的应用,使其具有了良好的应用前景。
3 图像数据库分类
多光谱图像数据库有公共数据库和个人数据两种。对论文中涉及的多光谱图像数据库进行分析,显示公共数据库最为常用,因为这些数据库允许数据库之间的性能比较,使得研究人员更容易的选择最适合的数据库,以实现其最佳设计功能。个人数据库一般由论文作者自行开发并使用,没有功能比较模块。大多数论文使用中国科学院的NIR-VIS 2.0、Oulu-CASIA NIR-VIS和中国科学技术大学的USTC-NVIE),且CASIA NIR-VIS 2.0数据库使用频率最高,原因主要包括两点:(1)该数据库的数据集协议已提前定义,即在训练和测试阶段已确定使用哪些图像,易于实现方法比较;(2)数据库由两个子数据库组成,其中一个子数据库含有原始图像,另一个子数据库包含分辨率为128×128像素的图像,且已进行了面部检测和面部对齐,该子数据库更加直观,能帮助研究人员更容易实现其设计目的。
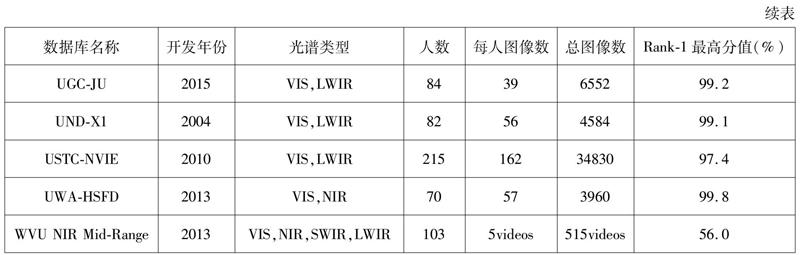
进一步按照名称、创建年份、使用的光谱波段、人数、图像数量等对数据库进行分析。从下表可以看出,大多数据库都已有若干年的历史;数据库中的平均人数为138人,人少远远小于仅含VIS图像的数据库,数据库图像少,不利于深度神经网络的训练和学习。对公共多数据库中光谱图像的光谱波段分析发现,联合使用SWIR和MWIR光谱图像的数据库数量非常少,分别为11%和7%,其原因可能是与NIR或LWIR相机相比,SWIR和MWIR相机的价格仍然十分昂贵,不适于大规模普及。
4 多光谱面部识别系统性能评价方法
面部识别系统主要用于人员身份识别和验证。身份识别是指确定一个人身份的过程,通过与数据库中的大量身份信息进行一对多的比较来确定;身份验证指比对被识别人员与其提供的身份信息,确认其是否允许进入或通过的过程,是一对一的比较。如果数据库容量很大,身份识别过程将非常耗时,此时需要使用一系列标准对多光谱面部识别系统进行性能评价,其中最常用的是Rank-N分值、验证率、误报率(FAR)和算法计算时间[2]。
识别系统的性能可利用身份识别预测返回值在N范围内(即Rank-N)结果的百分比来衡量。Rank-1是指预测返回值为正确(即最高分)的百分比,其计算方法为:身份识别正确的图像数除以要识别的图像总数。Rank-10是指在预测返回值排名前10的图像所占的百分比。Rank-N可作为Rank-1的拓展和补充,但它不用于验证哪张图像最有可能正确,而是验证正确图像是否在这N张最可能的图像之中。
身份识别可分为两种类型,如果我们事先知道要识别的人存在于数据库中,称之为闭集识别,如果事先不知道这个人是否存在于数据库中,称之为开放集识别。在闭集识别过程中,经常使用累积匹配(Cumulative Match Characteristic,CMC)曲线进行性能评价,CMC曲线根据Rank-N范围内图像的识别正确率绘制而成,其中最常用的N值是5和10。在开放集识别中,通常使用受试者工作特征(Receiver Operating Characteristic,ROC)曲线进行性能评价,从ROC曲线可以计算得到ROC曲线下的面积(即AUC),AUC越接近1.0(即100%正确),那么应用该图像数据库进行身份识别的精准度越高,性能越好。
如果用TP代表系统识别为正确、实际为正确的图像数,FN代表系统识别为错误、实际为正确的图像数,那么验证率(真阳性率)即可表示为:TP/(TP+FN)×100%。如用FP代表系统识别为正确、实际为错误的图像数,TN为系统识别为正确、实际为正确的图像数,那么FAR(误报率,也可称为假阴性率)即可表示为:FP/(FP+TN)×100%。在门禁系统中,FAR用于衡量识别系统(如面部识别系统)允许未经授权用户访问的可能性,FAR值越低,门禁系统越安全可靠。然而实际应用中,FAR值降低会伴随验证率降低,这就需要对算法进行微调,以在FAR和验证率之间取得权衡,从而满足面部识别系统的性能要求。
算法计算时间也可用于性能评价,使用多种方法获得的Rank-N分值相差不大,或系统要求固定FAR时,可通过计算识别所需的时间,来衡量多光谱面部识别系统的性能。
5 多光谱面部识别系统的实现方法
5.1 方法分类
对现有论文中多光谱面部识别系统进行分析,按照系统训练和测试阶段的圖像通道数量,可分为三种方式:
(1)多通道到多通道;
(2)多通道到单通道;
(3)单通道到单通道,其中每个通道可以是某个确定的光谱波段或某光谱范围内的光谱。
多通道到多通道方法是在训练和测试阶段使用相同的通道,使用这种方法,可以获得更多的图像信息,但缺点是设备成本较高。多通道到单通道方法是在训练阶段使用多个通道,而在测试阶段只使用一个通道,使用该方法可显著降低实现人脸识别系统的成本。最后一种方法使用频率最低,在训练和测试阶段仅使用一个通道。
按照图像特征提取和分类,又可将多光谱面部识别系统分为特征表征、耦合子空间学习、图像合成、图像融合和深度神经网络五种方法。
5.2 特征表征方法及典型应用
特征表征方法是在图像特征提取阶段,提取出不同光谱图像的最佳特征,通过特征提取,减少了初始图像信息量,简化了分类器的计算难度,也降低了不同光谱波段的图像间隙。但特征提取方法有一个明显的缺点,即忽略了人脸的空间结构,而空间结构是在异质人脸识别系统(包括多光谱面部识别系统)中取得良好性能的关键信息。
Nicolo等利用Gabor滤波器提取图像的幅值和相位,然后分别用简化韦伯局部描述符、LBP和广义LBP这三种局部特征描述子进行特征提取,每个局部特征描述子生成一个包含135个bins的直方图,然后将三个直方图合并为单一的特征向量(或直方图),并使用相对熵比较信息损耗,建立基于SWIR与VIS光谱通道的面部识别系统,在TINDERS数据库上取得97.8%的Rank-1评分[3]。
Cao等使用复合多瓣描述子对NIR和VIS光谱图像提取特征,并用相对熵比较信息损耗,建立了多光谱面部识别系统,在TINDERS数据库上测试,1%误报率(FAR)下的验证率达91.54%,Rank-1评分为70.14%。对SWIRI和VIS光谱图像,则取得1% FAR下的验证率为99.46%,Rank-1评分为78.65%。Peng等开发了一种基于高帧率的图像表征方法,该方法使用马尔可夫网络模型描述不同光谱图像,并考虑了相邻图像之间的空间兼容性。在CASIA NIR-VIS 2.0和USTC-NVIE数据库上进行识别系统测试,Rank-50评分分别为83.32%和95.38%[4]。
5.3 耦合子空间学习及典型应用
耦合子空间学习方法是指将不同光谱图像的特征投射到一个公共子空间中,这个子空间允许在不同光谱图像共有的冗余特征中,识别出最相关特征,该方法可减少多光谱图像间隙。该方法也有明显的缺点:一是当图像间隙较大时,公共子空间的辨别能力会大大减弱;二是在向子空间上投射图像特征不可避免地发生信息损耗,从而降低面部识别系统的性能。
Huang使用判别性谱回归的图像特征提取方法,将VIS和NIR的面部图像投射到一个公共判别式子空间,以进行面部识别,在CASIA-HFB数据库上获得了95.33%的Rank-1评分[5]。
Hu等在预处理阶段使用高斯差分滤波器,以减少VIS图像的光度变化和LWIR图像的位置变化的影响,并降低VIS和LWIR图像之间的模态间隙,提取图像特征后采用16×16像素的梯度直方图描述,最终建立了基于偏最小二乘法模型的一对多面部识别模型。利用NVESD数据库在1米、2米和4米进行VIS和LWIR光谱图像的面部识别,得到的Rank-1评分分别为82.3%、70.8%和33.3%。在距离1m、2m和4m处也进行了MWIR和VIS光谱图像的面部识别,分别获得了92.7%、81.3%和64.6%的Rank-1评分[6]。
5.4 图像合成方法及典型应用
图像合成方法是将图像从不同光谱统一转换至VIS光谱后,再应用为VIS图像设计的面部识别系统进行识别,该面部识别系统的性能高度依赖于合成的图像的准确性。
Litvin等使用卷积神经网络将LWIR光谱图像转换合成为VIS光谱图像,同时修改了FusionNet架构及其训练算法,以减少过拟合、增加桥联、初始化有泄露的线性修正单元函数(ReLUs)和正交正则化后的Dropout。利用该方法对RGB-D-T数据库中有姿势、位置和光度变化的三种图像进行了测试,分别产生了86.94%、97.52%和99.19%的Rank-1评分。
He等使用生成对抗网络方法将NIR光谱图像转换为VIS光谱图像,该方法使用了一个图像修正组件,可将任意姿态的NIR图像转换为正面姿态的VIS图像,生成兼具NIR和VIS纹理特征的图像,然后,采用图像扭曲程序将图像集成到一个端到端的深度网络中,最后使用卷积神经网络模型LightCNN进行面部识别。在CASIA NIR-VIS 20、Oulu-CASIA NIR-VIS和 BUAA-VisNir数据库上进行测试,Rank-1评分分别为98.6%、99.9%和99.7%,1% FAR下的验证率分别为99.2%、98.1%和98.7%,0.1%FAR的验证率分别为97.3%、90.7%和97.8%[7]。
5.5 图像融合方法及典型应用
图像融合方法包括两种方法:特征融合和分值融合。特征融合将特征提取器获得的多个图像特征,例如边缘、角度、线条和纹理等,合并为一个特征向量,用于执行图像切割或面部检测。分值融合则联合使用多个分类器和全局分类器,提高了分类器的整体性能,最常用的分值融合方法是多数投票法,即选择所有分类器给出的最高频率的分类,并将其分配给全局分类器;另一种分值融合方法是自适应加权法,指每个分类器按照性能高低,被分配一个动态加权值。使用图像融合方法的面部识别系统,可联合使用多个低成本摄像机,在降低错误率的同时,还可减低应用成本。
Singh使用粒度支持向量机(Granular SVM,GSVM)计算动态和局部加权值,从而将VIS和LWIR光谱图像进行融合,采用二维Log-Polar极坐标变换提取全局面部特征,采用局部二值模式(LBP)提取局部面部特征。在UND-X1和NIST Equinox数据库上进行系统性能测试,0.01%FAR下的验证率分别为99.91%和99.54%。
Kanmani对融合方法进行了三种优化,来解决异质面部识别问题。前两种优化方法为:将输入图像通过双树离散小波变换分别分解为高频系数和低频系数,采用群体优化技术寻找最优加权值,以进行VIS和LWIR光谱图像的融合。第三种优化方法采用自适应粒子群优化算法,避免了粒子群算法的过早收敛,该算法采用曲波变换对图像进行分解,并采用头脑风暴优化算法改善最优加权值的搜索过程。对基于三种优化方法的识别系统在IRIS数据库上进行测试,分别获得94.17%、94.50%和96.00%的Rank-1评分[8]。
5.6 深度学习网络方法及典型应用
随着人类神经网络研究的深入,人工神经网络方法开始应用于面部识别系统中,且逐渐超过其他方法。面部识别系统中的神经网络的基本过程是:将图像发送给神经网络,提取一组图像特征,當接收到来自同一个人的另一幅图像时,神经网络产生一组相似的特征信息,反之则产生不同的特征信息。目前最常用的神经网络是深度神经网络,它比传统的人工神经网络包含更多的决策层。然而,需要指出的是,训练时间是现有的深度神经网络的短板,很大程度上依赖于图形处理单元的性能。基于神经网络的识别系统在不同数据库上进行性能评价,可使用Rank-N分值、验证率和FAR衡量,如果这些指标结果类似,则可通过训练和分类阶段的算法计算时间进行衡量。
Sarfraz利用深度神经网络捕捉LWIR和VIS光谱图像之间的非线性关系,减少了异质图像间隙。经测试,与偏最小二乘模型相比,该方法在UND-X1数据库上提高了10%的Rank-1评分,在NVESD数据库上提高了15%~30%的Rank-1评分[9]。
Hu等开发了具有散射损耗和分集组合的多重深度网络,其中散射损耗可减少不同模态间隙,保留被检人员的身份鉴别信息,而分集组合(DC)自适应调整各深度网络的加权值。在CASIA NIR-VIS 2.0数据库上进行测试,获得Rank-1评分为98.9%,1%和0.1%FAR时的验证率分别为99.6%和97.6%。在Oulu-CASIA NIR-VIS数据库上进行测试,得到的Rank-1评分为99.8%,1%和0.1%FAR下的验证率分别为验证率为88.1%和65.3%。
Peng等使用深度局部描述子学习框架建立了面部识别系统,该学习框架能直接从面部图像中学习具有鉴别性和紧凑的局部信息,并使用一种新的交叉模态枚举损失算法来消除局部斑块层面上的模态间隙,然后将其集成到卷积神经网络中,利用深度局部描述子进行特征提取。在CASIA NIR-VIS 2.0数据库上进行测试,该系统获得9668%的Rank-1评分[10]。
He等在卷积神经网络中使用Wasserstein distance函数计算概率分布差异,减少了VIS和NIR图像之间的模态间隙,建立多光谱面部识别系统。在CASIA NIR-VIS 2.0、Oulu-CASIA NIR-VIS和BUAA-VisNir数据库上测试,获得Rank-1评分分别为98.7%、98.0%和97.4%,1%FAR下的验证率分别为99.5%、81.5%和96.0%,0.1%FAR下的验证率分别为98.4%,54.6%和91.9%。
Bae等引入了两个模块提高同质面部识别。第一个模块包括三个子模块:
(1)预处理链,可保证平移后的图像与原图像光度相似;
(2)CycleGAN函数,用于NIR到VIS的图像转换;
(3)二元神经网络,用于在映射函数的学习过程中添加约束的同时学习隐空间。
第二个模块则使用数据库中的图像及相应转换图像,对主干模型进行优化,获得512维的嵌入向量。使用CASIA NIR-VIS 2.0数据库进行测试,没有预处理模块的系统,Rank-1评分为99.07%,01%FAR下的验证率为98.67%,使用预处理模块的系统,Rank-1评分为99.40%,0.1%FAR下的验证率为98.74%[11]。
6 结论和展望
经过系统的分析研究,我们发现最常用的面部识别方法和取得最佳效果的方法都是基于神经网络的。事实上,至少36%的研究论文使用神经网络建立了多光谱面部识别方法。值得注意的是,自2019年以来,由于使用神经网络(主要是生成对抗网络)来进行图像合成,图像合成方法再次得到大量使用。
经过综合分析研究,还发现在不同的数据库中比较方法性能时,最常用的指标是Rank-1评分。目前多光谱人脸识别系统性能还受限于多光谱数据库是否能够使用。通过分析研究发现,目前应用最广泛的公共数据库是CASIA NIR-VIS 2.0。然而,与可见光波段的图像数据库相比,目前公共的多光谱数据库容量(图像总数)非常小,这可能导致神经网络在训练阶段出现过拟合。总之,多光谱数据库有几个局限性,如图像数量较少,没有公共数据库提供同一个人在不同光谱波段的面部图像,同一数据库中图像之间不存在位姿、光度和距离变化。
与仅使用可见光波段图像的面部识别系统相比,多光谱面部识别方法可取得更好的性能。通过多光谱图像在面部识别中的应用,可以克服某些光谱波段的图像间隙,例如LWIR光谱图像可不受光度差异的影响,能够补充VIS图像的缺点。然而,由于目前多光谱数据库中图像数量少,使用深度神经网络进行多光谱面部识别系统仍受到限制,有很大的发展和改进空间。多光谱面部识别系统的主要目的仍然是安全和监视,特别是在机场或军事机密地区等关键地点,但随着人工智能的发展和技术水平的进步,该系统将快速进入现代生活的方方面面,为人们提供更为优质便捷的服务。
参考文献:
[1]Zhang W,Zhao X,Morvan J M,et al.Improving Shadow Suppression for Illumination Robust Face Recognition[J].IEEE Trans Pattern Anal Mach Intell,2019,41(3):611-624.
[2]Wu F,Jing X Y,Dong X,et al.Intraspectrum Discrimination and Interspectrum Correlation Analysis Deep Network for Multispectral Face Recognition[J].IEEE Trans Cybern,2020,50(3):1009-1022.
[3]Peng C,Gao X,Wang N,et al.Graphical Representation for Heterogeneous Face Recognition[J].IEEE T Pattern Anal,2017,39(2):1-16.
[4]Huang X,Lei Z,Fan M,et al.Regularized discriminative spectral regression method for heterogeneous face matching.[J].IEEE T Image Process,2013,22(1):1-15.
[5]Zhifeng L,Dihong G,Qiang L,et al.Mutual Component Analysis for Heterogeneous Face Recognition[J].ACM T Intel Syst Tec,2016,7(3):1-18
[6]Hu S,Choi J,Chan A L,et al.Thermal-to-visible face recognition using partial least squares[J].J Opt Soc Am A,2015,32(3):431-442.
[7]Nnamdi O,Thirimachos B.Bridging the spectral gap using image synthesis:a study on matching visible to passive infrared face images[J].Mach Vision Appl,2017,28(5-6):1-15.
[8]Andre L,Kamal N,Sergio E,et al.A novel deep network architecture for reconstructing RGB facial images from thermal for face recognition[J].Multimed Tools Appl,2019,78(18):1-13.
[9]Ayan S,Debotosh B,Mita N.Human face recognition using random forest based fusion of à-trous wavelet transform coefficients from thermal and visible images[J].AEU-Int J Electron C,2016,70(8):1-9.
[10]M S S,Rainer S.Deep Perceptual Mapping for Cross-Modal Face Recognition[J].Int J Comput Vision,2017,122(3):1-13.
[11]Weipeng H,Haifeng H.Discriminant Deep Feature Learning based on joint supervision Loss and Multi-layer Feature Fusion for heterogeneous face recognition[J].Comput Vis Image Und,2019,184(1):1-18.
基金項目:河北省高等学校科学技术研究项目(基于SOPC的人脸检测系统的设计,项目编号:QN2019176)
通讯作者:陈丽(1987— ),女,硕士,助理研究员,研究方向:数字图像处理。
猜你喜欢
客联(2022年3期)2022-05-31
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2022年1期)2022-04-15
计算技术与自动化(2021年2期)2021-11-10
西部交通科技(2021年9期)2021-01-11
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
