
探究公安工作应用局部人脸及高分辨率图像场景的人脸检测算法
2020-12-29 11:56许鲲
电脑知识与技术 2020年30期
关键词:人脸检测
许鲲

摘要:随着公安立体化防控体系建设的逐步深入,视频监控系统以其数据量大、实时等特点已经成为社会治安综合治理防控体系中的重要组成部分。在视频大数据技术成熟应用发展的背景下,图侦工作相关的涉案人、车的特征信息较之以前单纯利用原始视频图片更能满足快速检索、高效研判的需要。其中人脸深度研判全新的图侦业务系统需具备人脸图片结构化管理与结构化信息检索应用能力,要做人脸图片的深度应用,首先要解决的就是人脸图片的采集工作,人脸采集的全面准确与否直接影响后续的人脸应用。在人脸采集过程中,一方面需要最大限度地覆盖需要的场景,另一方面需要从根本上提升人脸检测算法,提升在高分辨率图像及高密度人群下的适应性。通过人脸检测算法的研究,把控人脸采集数据源,以适应摄像机分辨率不断提升导致的图像尺寸变化及适应诸如三场一站等高密度人群、遮挡人群的人像采集,为人脸布控、人脸比对、人脸检索以及基于人脸的分析研判提供高可用的人脸图片数据。
关键词:人脸深度研判;人脸检测;尺度变化
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2020)30-0198-04
1 背景
随着公安立体化防控体系建设的逐步深入,视频监控系统以其数据量大、实时等特点已经成为社会治安综合治理防控体系中的重要组成部分。至今,天津市在全市视频监控建设联网工作上取得了长足的进展,已经建成了11万路一类高清视频监控点位,初步实现了视频监控的全域覆盖。在应用方面已经初步构建了人脸与车辆的辅助办案系统,实现了1.168亿车辆分析能力与2000路人脸分析能力。
在视频大数据技术成熟应用发展的背景下,图侦工作相关的涉案人、车的特征信息較之以前单纯利用原始视频图片更能满足快速检索、高效研判的需要。因此图侦工作信息化需求因全市公共安全视频监控网建设规模化而成为下列一种可能甚至是现实,即创建街头路面视频捕获的人、车特征大数据库,实现图侦视频图像大数据的深度应用。其中人脸深度研判全新的图侦业务系统需具备人脸图片结构化管理与结构化信息检索应用能力,要做人脸图片的深度应用,首先要解决的就是人脸图片的采集工作,人脸采集的全面准确与否直接影响后续的人脸应用。在人脸采集过程中,一方面需要最大限度地覆盖需要的场景,另一方面需要从根本上提升人脸检测算法,提升在高分辨率图像及高密度人群下的适应性。
2 概述
本次论文的主题是人脸检测(Face Detection),人脸检测是人脸识别的第一站,尤其针对公安遇到的比如由于逐步采用超高清摄像机(如400万、800万、1600万等像素)带来的人脸尺度变动。以及高密度人群或故意遮挡等实际场景问题,通过针对性的算法模型设计实现速度与精度的双重提升。
人脸检测的目的是,给定任意图像,返回其中每张人脸的边界框(Bounding Box)坐标,由于人脸检测是所有人脸分析算法的前置任务,诸如人脸对齐、人脸建模、人脸识别、人脸验证/认证、头部姿态跟踪、面部表情跟踪/识别、性别/年龄识别等等技术皆以人脸检测为先导,它的好坏直接影响着人脸分析的技术走向和落地,也同时影响着人脸识别技术在公安实战应用效果。
尺度变化是人脸检测不同于通用物体检测的一大问题。通用物体的尺度变化范围一般在十几倍之内;与之相比,人脸的尺度变化范围由于摄像头不断升级,在 4K 甚至更高分辨率场景中可达数十倍甚至上百倍,针对高分辨率场景我们不能采用图像压缩(如压缩到200万像素),这样就失去了高分辨率摄像机建设的意义,也起不到实战效果。面对这一问题,已有学者已尝试通过寻找最优尺度多次采样原图或者利用不同深度的特征图适应不同尺度的人脸解决这一问题;而此论文从另外一个角度切入更好地解决这个问题。
和尺度变化一样,遮挡也是人脸检测面临的常见挑战之一。实际场景中的高密度人群、眼镜、口罩、衣帽、头盔、首饰以及肢体等皆会遮挡人脸,拉低人脸检测的精度。对此,已有学者尝试通过提升神经网络适应遮挡情况的能力,或者将问题转化为遮挡与非遮挡人脸在向量空间中的距离这一度量学习问题来解决。而此论文针对人脸遮挡问题创立一套全新算法针对性地解决这个问题。
3 尺度变化图像人脸检测算法
目前的人脸检测方法仍无法很好地应对大范围尺度变述,基于图像金字塔的方法理论上可覆盖所有尺度,但必须多次采样原图,导致大量重复计算;而基于特征金字塔的方法,特征层数不宜加过多,从而限制了模型处理尺度范围的上限。是否存在一种方法,图像只通过模型一次,同时又覆盖到足够大的尺度范围呢?
目前,单步检测方法大致可分为两类:(1)Anchor-based 方法。(2)Anchor-free 方法。Anchor-based 方法处理的尺度范围虽小,但更精准;Anchor-free 方法覆盖的尺度范围较大,但检测微小尺度的能力低下。一个非常自然的想法就是,两种方法可以融合进一个模型吗?理想很丰满,现实很骨感,Anchor-based 和 Anchor-free 方法的输出在定位方式和置信度得分方面差异显著,直接合并两个输出困难很大,具体原因如下:
其一,对于 Anchor-based 方法,ground truth IoU ≥ 0.5 的锚点将被视为正训练样本。可以发现,正负样本的定义与边界框回归结果无关,这就导致 Anchor-based 分支每个锚点输出的分类置信度实质上表示的是“锚点框住的区域是人脸”的置信度,而不是“网络预测的回归框内是人脸”的置信度。故而分类置信度很难评估网络实际的定位精度。对于在业务层将 Classfication Subnet 和 Regression Subnet 分开的网络,情况将变得更为严重。
其二,对于 Anchor-free 方法,网络训练方式类似于目标分割任务。输出的特征图以边界框中心为圆心,半径与边界框尺度成比例的椭圆区域被定义为正样本区域,特征图其他位置(像素)被视为背景。通过这种方式,Anchor-free 分支的分类置信度得分实质为“该像素落在人脸上”的置信度,而且该分类置信度与定位的准确度的关联同样很弱。
总而言之,Anchor-based 方法和 Anchor-free 方法的分类置信度都与回归定位精度关联甚微,其置信度得分也分别代表着不同的含义。因此通过分类结果直接合并两个分支输出的边界框是不合理的,并且可能导致检测性能的急剧下降。
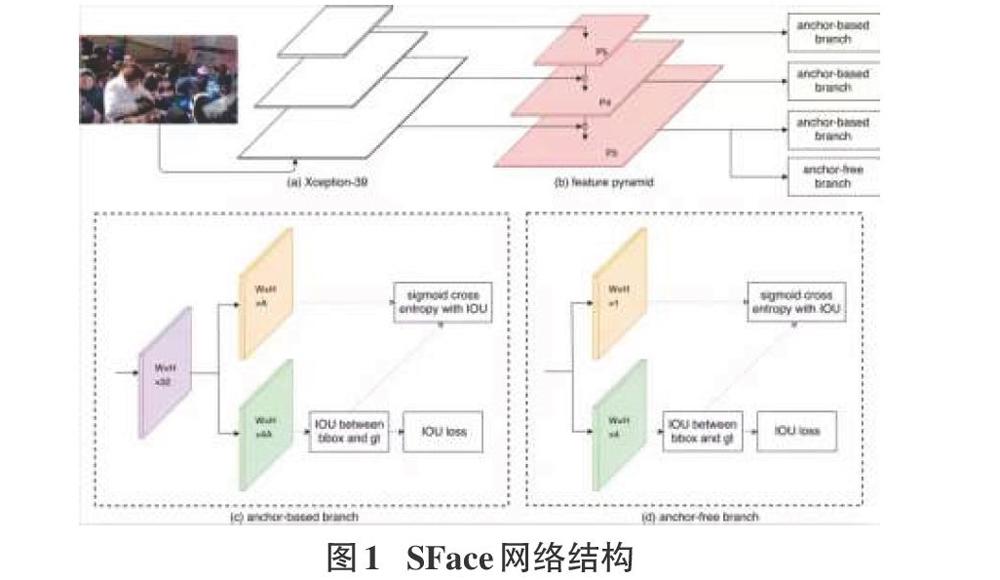
因此,可以将回归的边界框和 groundtruth 边界框之间的 IoU 当作 Classfication Subnet 的 groundtruth,这正是 SFace 所做的事情。
具体而言,SFace 设计了Anchor-based 和 Anchor-free 两个分支,前者基于RetinaNet,后者基于 UnitBox;两个分支都在训练第一步通过 Regression Subnet 生成边界框;接着计算边界框和 groundtruth 边界框之间的 IoU;(Anchor-based 分支的)锚点和(Anchor-free 分支的)像素中 IoU≥0.5 的结果将视为Classfication Subnet 的正样本,其他则视为负样本,Classfication Loss 采用 Focal Loss。我们还尝试过直接回归 IoU,然而实验结果表明,相较于采用 Sigmoid Cross Entropy 或 Focal Loss,直接回归 IoU 所得结果方差较大,实际效果欠佳。
Anchor-based 分支和 Anchor-free 分支都使用 IoU Loss 作为 Regression Loss。这种调整有助于统一两个分支的输出方式,优化组合结果。通过以上修正,两个分支的分类子网络的实质含义得到统一,分类置信度的分布得到一定程度的弥合,从而 SFace 可有效融合两个分支的结果。
此外,SFace 必须运行很快才有实际意义,否则大可以选择做图像金字塔。为此,基于Xception,SFace 采用了一个 FLOPs 仅有 39M 的 Backbone,称之为 Xception-39M,每个 Block 包括 3 个 SeparableConv 的 Residual Block。Xception-39M 运算量非常小,感受野却高达 1600+,十分适合处理更高分辨率图像。
4 遮挡图像人脸检测算法
遮挡问题是公安动态人脸应用中最为常见的问题,尤其现如今犯罪嫌疑人的反侦察能力越来越强,伪装遮挡是基本手段,因而如何有效解决因遮挡带来的人脸识别精度问题,是摆在公安用户以及学者专家面前的一道难题。针对该问题,我们在此提出一种专门针对人脸遮挡的算法模型。
我们可以从另一个角度考虑遮挡问题。一个物体在清晰可见、无遮挡之时,其特征图对应区域的响应值较高;如果物体有(部分)遮挡,理想情况应是只有遮挡区域响应值下降,其余部分不受影响;但实际情况却是整个物体所在区域的响应值都会降低,进而导致模型 Recall 下降。
解决这个问题大概有两种思路:1)尽可能保持住未遮挡区域的响应值;2)把无遮挡区域降低的响应值弥补回来;前者较难,后者则相对容易。一个简单的做法是让检测器学习一个 Spatial-wise Attention,它应在无遮挡区域有更高的响应,然后借助它以某种方式增强原始的特征图。
那么,如何设计这个 Spatial-wise Attention。最简单考虑,它应当是一个 Segmentation Mask 或者 Saliency Map。基于 RetinaNet,FAN 选择增加一个Segmentation 分支,对于学到的 Score Map,做一个 exp 把取值范围从 [0, 1] 放缩到[1, e],然后乘以原有的特征图。为简单起见,Segmentation 分支只是叠加 2 个 Conv3x3,Loss 采用 Sigmoid Cross Entropy。
这里将面对的一个问题是,Segmentation 分支的groundtruth 是什么,毕竟不存在精细的 Pixel-level 标注。由于人脸图像近似椭圆,一个先验信息是边界框区域内几乎被人脸填满,背景区域很小;常见的遮挡也不会改变「人脸占据边界框绝大部分区域」这一先验。基于这一先验可以直接输出一个以边界框矩形区域为正样本、其余区域为负样本的 Mask,并将其视为一个「有 Noise 的 Segmentation Label」作为实际网络的 groundtruth。我们也尝试根据该矩形截取一个椭圆作为 Mask,但实验结果表明基本没有区别。
这样的groundtruth真能达到效果吗?通过可视化已学到的 Attention Map,发现它确实可以规避开部分遮挡区域,比如一个人拿着话筒讲话,Attention Map 会高亮人脸区域,绕开话筒区域。我们相信,如果采用更复杂的手段去清洗 Segmentation Label,实际效果将有更多提高。
5 结语
本论文旨在通过人脸检测算法的研究,把控人脸采集数据源,以适应摄像机分辨率不断提升导致的图像尺寸变化,及适应诸如三场一站等高密度人群、遮挡人群的人像采集,为人脸布控、人脸比对、人脸检索以及基于人脸的分析研判提供高可用的人脸图片数據。
参考文献:
[1] 赵昕晨,杨楠.基于头部姿态分析的摄像头视线追踪系统优化技术[J].计算机应用,2020(7).
[2] 杨思燕,苗凯彬,王锋,等.视频图像中人脸自动检测与统计算法[J].电子科技,2020,33(8):1-9.
【通联编辑:代影】
