
基于网络爬虫的搜索引擎的设计与实现
2020-12-29 11:56高文超李浩源徐永康
电脑知识与技术 2020年30期
高文超 李浩源 徐永康
摘要:随着信息量的增多,为用户提供便捷的搜索服务也更加具有挑战性。大规模存储信息并精确搜索的代价是巨大的,人们需要在信息搜索的快捷性与成本中找到平衡。系统实现一个基于网络爬虫的搜索引擎。软件结构分为爬虫部分,数据库部分,前端显示部分。同时,描述了扩展成分布式爬虫的方法。硬件方面需要多台主机,软件方面包括Scrapy爬虫、数据库、Django框架。最终设计并实现了一个具有良好的健壮性和扩展性的网络爬虫系统。
关键词:爬虫;信息;搜索引擎;数据库;Web框架
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2020)30-0006-04
Abstract: In the Internet era, with an increasing amount of information, it is more challenging to provide users with convenient search services. The cost of storing information on a large scale and searching accurately is huge, and people need to balance the speed and cost of information searching. This system implements a search engine based on a web crawler. The software structures are divided into the crawler part, database part, and front-end display part. At the same time, it describes the method to expand into a distributed crawler. In terms of hardware, multiple hosts are needed. In terms of software, Scrapy crawlers, databases, and the Django framework. Finally, a web crawler system with good robustness and expansibility is designed and implemented.
Key words: Reptile; information; Search Engines; database; web framework
1 背景
身處于信息时代,数据共享与查询越来越便捷,基于数据的服务也越来越多,各行各业越来越依赖于爬虫对数据进行提取[1]。但是,随着信息数据量迅速增长,这些数据中包含着许多模糊不清的信息,构成了一个庞大的网络资源库。因此人们需要从海量数据中提取所需要的信息,同时平衡成本。爬虫能够将用户所需要的数据提取出来,但是仅仅依靠单机爬虫,采集速度难以处理繁多的页面,而硬件的发展也无法跟上信息量的增长。因此,合理限定抓取范围,开发面向与各个领域的轻量化搜索引擎,扩展单机爬虫为分布式爬虫都是可行的解决方法。
2 总体设计与功能
2.1 功能设计
一个单词在不同领域具有不同含义,用户直接在通用搜索引擎上搜索可能会显示完全不同的结果。需要精细化搜索引擎范围,本系统开发一套面向于某一领域和中小企业的搜索引擎,具有数据范围相对较集中,数据量相对较小的特点。
通过对需求的分析,将该搜索引擎分为两个页面。其一是搜索网站搜索主页,包括搜索分类选择、输入框输入信息并搜索、热门搜索与搜索记录共同组成了搜索门户方便用户搜索,其二是搜索网站结果显示页,在该页面上显示搜索的相关信息,搜索输入框,满足用户信息浏览和继续搜索的需求。第一部分,将搜索的信息分为几个板块,用户可以选择不同板块来进行对应的搜索。第二部分,在页面上显示热门搜索和历史记录,用户可以点击对应的关键字进入对应的结果页链接。在显示搜索结果的时候,显示搜索标题、简介、结果数据统计信息等,方便用户浏览。
2.2 模型设计
本系统采用B/S架构,服务器作为核心事物的重要部分[2]。后端框架选用Django搭建,前端页面通过嵌入来显示网页,并在Django框架中设置数据处理函数处理数据库中的信息。
本系统设计针对某领域提供信息,不同用户搜索的内容可能有不同的爬虫爬取,相同的搜索领域由同类型的爬虫抓取数据。所有抓取的数据信息根据不同数据库的特点分别保存。
作为一个系统,稳定是最重要的因素,因此需要考虑稳定运行,数据备份等因素,此外需要具有良好的可拓展性,能够随着用户增长的需求来扩充数据的范围,因此代码的编写需要规范化,方便后期维护升级。
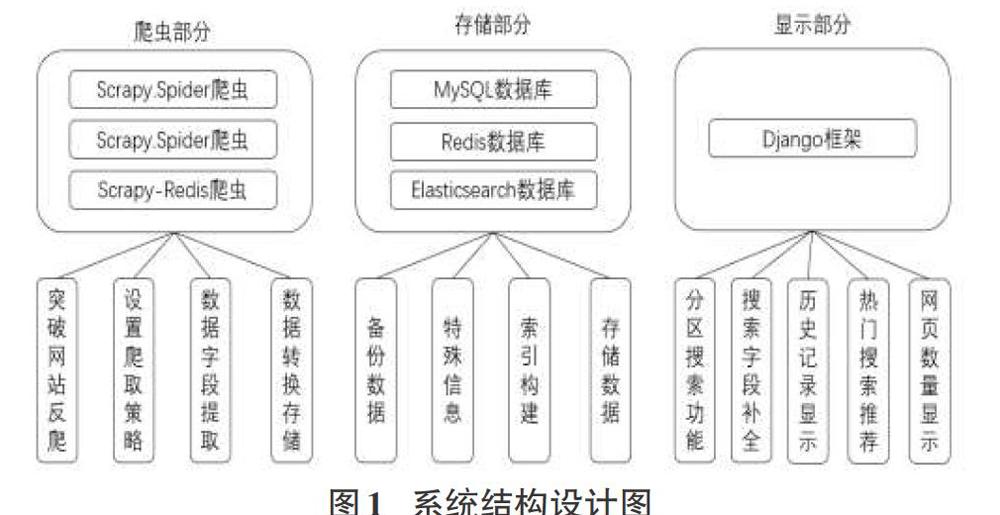
本系统分为三部分,包括爬虫部分,存储部分和显示部分。各部分功能与主要技术设计如图1所示:
1)爬虫部分:该模块用于爬取目标网站信息,包括实现自动登录,设置措施突破反爬限制,设置网页爬取策略根据不同网站特点爬取对应信息,数据字段提取与保存信息等功能。
2)存储部分:该模块的功能是将爬虫爬取的信息分别存储到不同的数据库中。MySQL数据库用来存储单机上爬取的信息,并作为备份。Elasticsearch数据库用于汇总存储数据并构建索引。Redis数据库是内存数据库,存取数据十分迅速,用于保存常用信息,同时作为分布式爬虫队列管理工具。
3)显示部分:本模块设置服务端处理数据的过程,使用基于Python的Django框架。选择B/S架构,同时将处理后的数据在浏览器页面上显示。后端框架选取MVT模式。
3 详细实现
3.1 爬虫的实现
1)爬虫规则设计
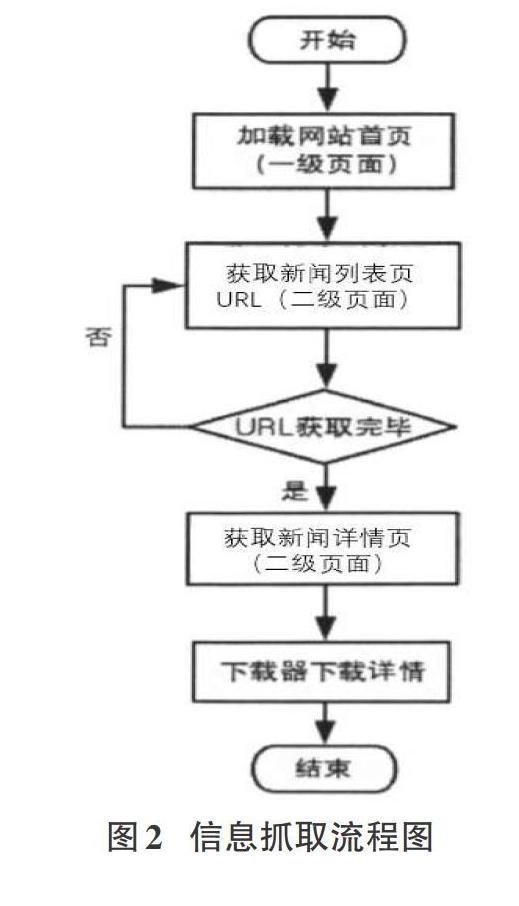
本系统实现的爬虫基于Scrapy框架,在爬虫模块中主要完成爬取目标网站的功能。根据不同网站的结构,选取深度优先策略和广度优先策略[3]。设计信息解析模块,对目标网站的布局与逻辑进行分析,发现网站网页结构主要可以分为主页、列表页、详情页。网站的主页设为网站的一级页面,是用户进入网站的入口。所有内部页面可以通过主页上的链接进行访问。网站的列表页是二级页面,负责网站某一分类下的所有相关页面的URL信息。详情页定义为三级页面,是用户访问该网站的目标页面,同时也是爬虫主要抓取对象和信息提取页。整个过程如图2。
2)数据处理模块
首先定义爬虫名称,爬取的域名和起始页面。其次,获取网页列表页URL,下载后使用parse函数处理,同时定理next_url来循环爬取其他URL。然后在详情页面上具有大部分的目标信息,针对这些信息,使用CSS和XPATH选择器提取页面详细信息。部分字段提取样式如表1:
①动态页面加载:部分网页并不会一次性显示全部数据信息,需要通过鼠标下滑或者点击对应按钮才能够查看并显示更多内容。编写process_request函数,调用browser.execute_script方法控制网页下滑来进行动态网页解析。
②存储部分:爬虫在一段时间内访问网站次数过多,其IP地址会被网站识别重定向或封禁。使用IP代理池随机更换IP地址防止网站识别[4]。定义GetIP类来实现对IP地址的控制,此类包含两个函数,delete_ip(self,ip)用来从数据库中删除无效IP。judge_ip(self,ip,port)用来判断IP是否可用。
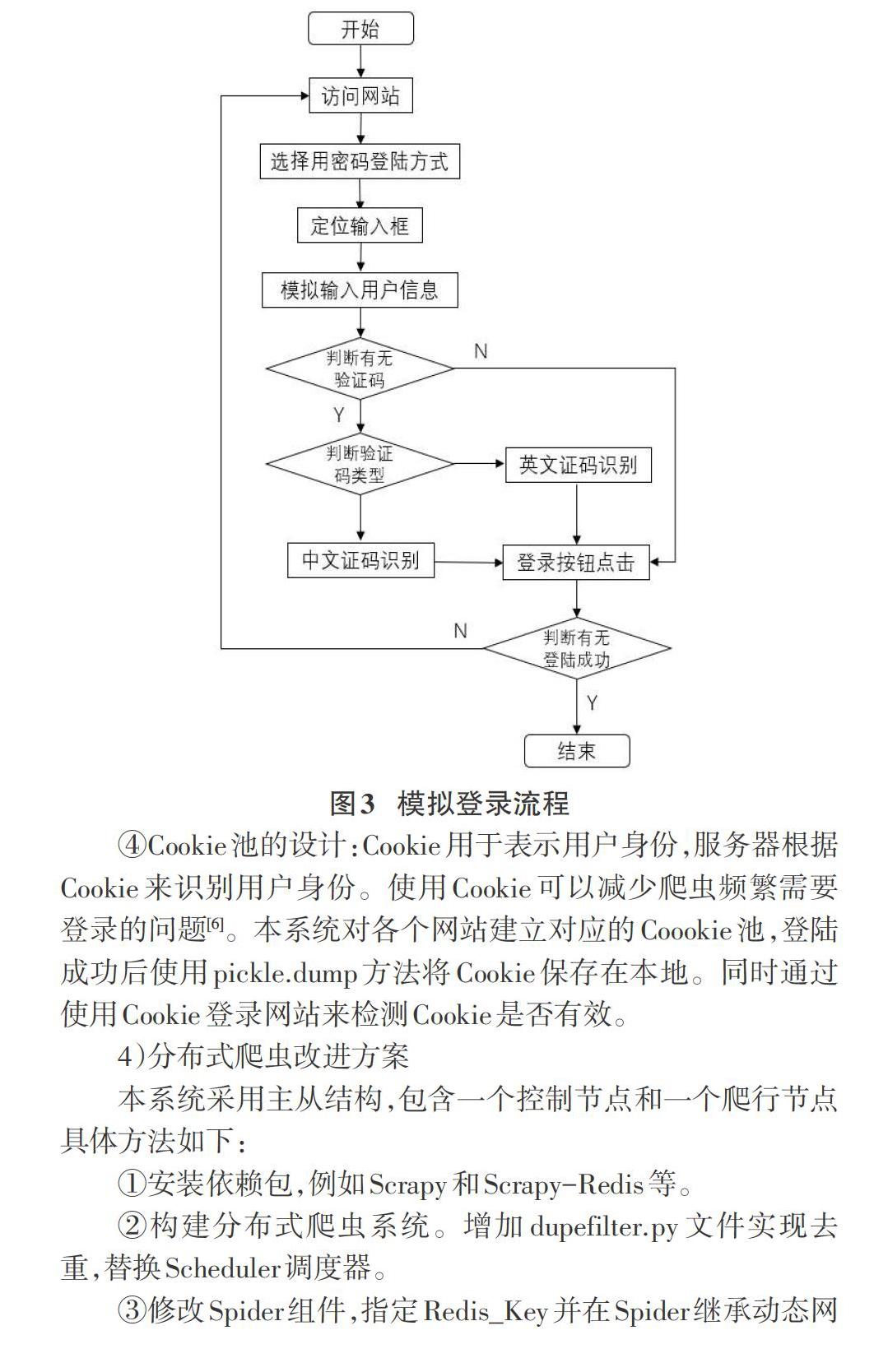
③模拟登录的设计:部分网站需要进行登录才能访问网站信息,同时登录过程中可能会需要输入验证码。对于针对这一部分网站,首先在CMD中启动远程调试打开浏览器防止识别出WebDriver。加载浏览器驱动启动浏览器。最大化界面并定位输入框与按钮,在登录界面使用选择器定位登陆元素和查找用户名密码输入框,使用Selenium自动输入预设信息并登录[5]。最后,如果在网页上找到对应信息则判断登陆成功。具体登录流程如下:
4)分布式爬虫改进方案
本系统采用主从结构,包含一个控制节点和一个爬行节点具体方法如下:
①安装依赖包,例如Scrapy和Scrapy-Redis等。
②构建分布式爬虫系统。增加dupefilter.py文件实现去重,替换Scheduler调度器。
③修改Spider组件,指定Redis_Key并在Spider继承动态网页加载功能。
④修改配置文件,添加数据连接功能,配置本机端口和地址。修改Pipeline.py在ITEM_PIPELINES中添加scrapy_redis.pipelines.RedisPipeline,将爬取的信息存入Redis 数据库。
⑤集成BloomFilter过滤器,在大型爬虫中用于URL去重[7]。本系统中过滤器通过add函数添加元素,is_exist函数查询,get_hashs函数用来取得哈希值。
3.2 数据库的实现
1)数据库总体设计
部分本系统数据库分为三种,MySQL数据库负责单机爬虫数据的备份。Redis内存数据库负责保存与修改常用数据。Elasticsearch数据库负责人构建索引,支持搜索引擎功能。三种数据库共同构成本项目的数据库模块。
2)数据库表的设计
以某网站新闻板块为例,通过分析爬取目标来设置数据库的字段。同时实现数据存储的安全性,设置Mysql Twisted Pipeline使用异步入库方式。以新闻模块为例,数据库表如下所示:
3)ES数据库建立
①在数据库中,定义数据库的名称,分片数量[8]。然后建立索引,通过Mappings函数将输入数据转变成可以搜索到的索引项,通过Kibana调试。
②建立索引与映射,在工程中的Models包里的es_type.py来建立的,它可以用来控制数据向ES的写入。设置Meta信息。在其中定义这些数据存储的索引index名并设置文档类型doc_type方便前端网页分类。在pipelines.py中定义ElasticsearchPipeline类将数据写入ES中。在这个类下定义process_item函数实现将item类转换为ES数据。
4)Redis數据库建立
为了加快对常用数据的存取速度,本系统将统计各网站爬取页面的计数器存入Redis数据库中。在Scrapy框架中Redis数据库的主要工作是统计网页总数。在items.py文件中设置,在每次往ES存入一个数据的时候,使用redis_cli函数中incr方法,对不同类型的文章存储时进行计数,使得Redis中存储了每种类型文章的数量。
对于Scrapy-Redis框架,修改对应的措施,实现分布式爬虫的要求。首先在Scrapy-Redis功能配置的defaults文件中设置REDIS_CLS=redis.StrictRedis可以提供对Redis集群操作的方法。然后添加Redis配置,对DOWNLOADER_MIDDLEWARES,SCHEDULER和ITEM_PIPELEINES分别设置对应的措施满足分布式爬虫的要求。最后在connection中添加Redis集群实例化的措施。
3.3 服务端的实现
本系统中,服务端作为关键模块之一,负责对输入文本进行处理,与数据库进行交互,处理数据并返回结果到前端页面上。主要流程如下:
1)导入静态页面,搭建两个静态页面模板,命名为index和result放入新建工程的templates文件夹下,将图片资源放入static文件夹。在urlpatterns中配置静态页面的路径。
2)实现搜索推荐功能。在index页面完成搜索建议函数,使用get方法获取输入文本,与搜索类型s.type共同组成请求。在视图中定义SearchSuggest类在类中处理文本,后端根据输入内容匹配补全字段。
3)搜索结果显示。在view.py定义SearchView类,将后台信息传递给前端,取得关键词匹配高亮处理,设置每页显示结果数。并将数据库中主要信息传给前端页面对应位置显示。
4)搜索记录与热门搜索显示。定义add_search函数存储搜索数据,把数组存储到浏览器本地。统计搜索次数并按照时间顺序显示历史记录。热门搜索需要调用Redis数据库中的sortedSet集合,通过ZINCRBY命令实现搜索数量记录。最后返回高频搜索关键字。
4 系统结果展示
4.1 开发环境的展示
本系统中,主要工具的版本号如下表所示:
4.2 门户起始页展示
用户进入搜索引擎起始页面index.html,可以选择搜索模块,并在搜索框中输入文本,文本内容每次变化则会触发一次搜索,在数据库中查找匹配项并显示。也可以浏览并点击热门搜索和搜索记录中的关键词。
4.3 搜索结果页展示
点击搜索按钮之后网站转到结果显示界面result.html。信息按照相关度得分排序,同时将匹配字符标红。
点击搜索按钮之后网站转到结果显示界面。信息按照相关度得分排序,将匹配字符标红。同时显示网站数量和搜索附加信息。
4.4 后台数据展示
MySQL数据库保存各台主机爬取信息,作为备份保存数据。以职位网站为例,单机抓取有效网页数量600余条,本系统随机抓取延迟时间范围5-15秒。理论上每小时可抓取360个网页,2小时可抓取720个网页。但由于网络带宽和随机延迟,导致抓取数量减少。存储数据如下所示:
5 总结与展示
本文主要实现基于Scrapy网络爬虫的搜索引擎。该系统可满足中小企业或某一领域范围内的搜索需求。本系统具有扩展性强、稳定性高等特点。但是,本系统在单机上搭建了分布式爬虫,并未考虑实际中不同服务器节点性能存在差异等问题,同时针对部分网站,应该基础研究设置更加合理的爬取策略,降低网站反爬侦测的概率,提升系统的性能。
参考文献:
[1] 樊宇豪.基于Scrapy的分布式網络爬虫系统设计与实现[D].成都:电子科技大学,2018.
[2] 王贵智.基于B/S智慧教务综合管理系统的设计与实现[D].长沙:湖南大学,2019.
[3] 王芳,张睿,宫海瑞.基于Scrapy框架的分布式爬虫设计与实现[J].信息技术,2019,43(3):96-101.
[4] 余豪士,匡芳君.基于Python的反爬虫技术分析与应用[J].智能计算机与应用,2018,8(4):112-115.
[5] 冯兴利,洪丹丹,罗军锋,等.基于Selenium+Python的高校统一身份认证自动化验收测试技术研究[J].现代电子技术,2019,42(22):89-91,97.
[6] 梁浩喆,马进,陈秀真,等.现代浏览器中Cookie同源策略测试框架的设计与实现[J].通信技术,2019,52(12):3039-3045.
[7] 孟慧君.基于Bloom Filter算法的URL去重算法研究及其应用[D].开封:河南大学,2019.
[8] 王磊,王胤然,徐寅,等.一种ElasticSearch分片扩展方法:CN108509438A[P].2018-09-07.
【通联编辑:谢媛媛】
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
中国卫生(2015年12期)2015-11-10
警察技术(2015年3期)2015-02-27
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
技术经济与管理研究(2014年11期)2014-03-11
