
基于零膨胀广义Poisson回归模型的广义估计方程方法及其应用
2020-12-29 02:15殷明娥
辽宁师范大学学报(自然科学版) 2020年4期
殷明娥, 于 洋
(辽宁师范大学 数学学院,辽宁 大连 116029)
自Lambert[1](1992)开发了零膨胀Poisson回归模型,将Poisson回归模型与零退化分布相结合分析产品在生产过程中所包含有的瑕疵数量之后,零膨胀模型在经济科学、金融保险等领域有了广泛应用.Gupta等[2](2004)和Famoye等[3](2006)推广为零膨胀广义Poisson回归模型,对过多零、过度分散或压缩的计数数据进行建模,使模型能够适用于更多的计数数据.但是,对于纵向观测数据,当来自同一集群的观测值之间存在相关性时,如果忽略这个因素可能会导致无效的统计推断.目前,已有多种统计方法被用于纵向数据分析中,其中,Liang和Zeger[4](1986)提出的广义估计方程方法是最具有代表性的和应用最广的方法.它是通过响应变量的一阶矩和二阶矩刻画集群水平上响应与协变量之间的关系,而且只要响应变量的矩被正确地指定,广义估计方程的估计量具有一致性和渐近正态性.
对零膨胀特征的纵向计数数据建模包括了两部分,一部分是普通的计数部分建模,一部分是零膨胀部分的建模,并不能直接应用广义估计方程方法来建模. Hall和Zhang[5](2004)对一种通用算法的自适应,称为期望求解(Expectation Solution)算法来估计模型参数. 通过引入隐变量,显示响应变量是来自零退化分布还是来自标准的计数的分布,将广义估计方程的方法推广到零膨胀计数模型的应用中.
Kong等[6](2015)考虑了一个零膨胀负二项模型对零膨胀纵向计数数据进行统计推断,模型分别对零膨胀部分与标准负二项模型部分区分建模,在Hall和Zhang[5](2004)方法基础上,允许指定了一个工作相关矩阵和边际关系. 此后,Hyoyoung和Datta[7](2018)将广义估计方程方法用于零膨胀Conway Maxwell Poisson模型中, 可以灵活处理数据散度和纵向数据的集群性特征,并分析了基因数据.
在本研究中,参考了Hall和Zhang[5](2004)的思路,基于零膨胀广义Poisson回归模型拟合具有零膨胀特征的纵向计数数据,既考虑了数据过度分散和零过多的计数性质, 同时也考虑了纵向数据个体内部间的相关性,并且分析了一组Iowa氟化物研究数据, 探讨氟化物与龋齿及其影响因素之间的关系.
1 零膨胀广义Poisson回归模型与估计方法
1.1 广义Poisson分布
假设随机变量Wij~fGP(wij|λij,φ),i=1,…,N,j=1,…,ni,根据Consul和Jain[8](1970)定义的广义Poisson分布,概率分布律为
P(Wij=wij)=fGP(wij|λij,φ)=
(1)
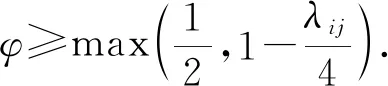
当参数φ<1时,m是使λij+m(φ-1)>0的最大正整数值,且Wij的均值和方差分别为
E(Wij|λij,φ)=λij,
Var(Wij|λij,φ)=φ2λij.
当参数φ=1时,式(1)退化为Poisson分布;
当参数φ>1时,其均值要小于方差,此时数据中会出现离差偏大;
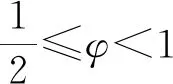
1.2 零膨胀广义Poisson回归模型
如果随机变量Yij服从零膨胀广义Poisson分布,记为Yij~ZIGP(λij,pij,φ),λij、pij、φ为参数,其概率分布律为
则其均值和方差分别为
E(Yij)=(1-pij)λij,
Var(Yij)=(1-pij)λij(φ2+pijλij).
零膨胀广义Poisson回归模型与广义线性模型的构成类似,模型结构如下:
(ⅰ) 模型的响应变量为Yij,Yij~ZIGP(λij,pij,φ),且Yij相互独立,i=1,…,N,j=1,…,ni.

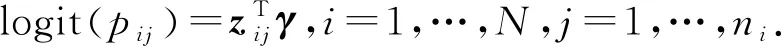

1.3 模型参数的估计
零膨胀广义Poisson回归模型中回归系数β和γ满足的广义估计方程为
(2)
其中,Yi=(Yi1,Yi2,…,Yini)T,μi=E(Yi)=(μi1,…,μini)T,
由Hall和Zhang[5](2004)知,由于参数β和γ分别出现在零膨胀模型的两个部分,不能直接用广义估计方程(2)估计,只能通过引进隐变量uij,i=1,…,N,j=1,…,ni分别估计回归系数β和γ.

γ的广义估计方程为
(3)

则

同理,β的广义估计方程为
(4)
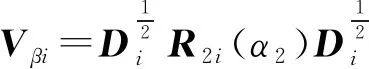
注意到,由广义估计方程(4)中矩阵diag(1-ui)可知,只是来自广义Poisson分布中的观测值Yij参与广义估计方程(4)的计算,而来自零退化分布的观测值Yij不参与其中的计算.
若隐变量uij给定,γ和β的估计值可用常规的Fisher得分法通过迭代求解估计方程(3)和方程(4)获得.但是在每次迭代时,需要估计uij的值. 在假设给定y,γ,β,φ的条件下,用EM算法获得uij的估计.
假设用γ(b),β(b),φ(b)分别表示γ,β,φ第b次迭代时的估计值,uij可由如下式子迭代,得到估计值.
(5)
其中,
γ和β可由如下迭代式子得到
(6)
(7)
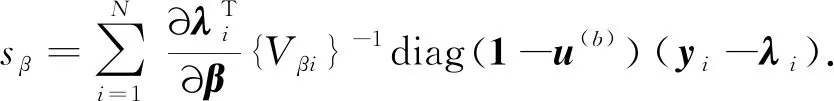
散度参数φ的估计:

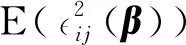
λijφ2=vij.

故当Yij服从ZIGP分布时,参数φ只与Yij的方差函数有关,与均值函数无关,因此,通过求解以下估计方程估计参数φ,
(8)
其中,
Hi=diag((1-ui1)2,…,(1-uini)2).
由式(8)可得如下方程
(9)
由vij(φ)=φ2λij可得
则
(10)
相关参数α1,α2的估计:
估计α1的值,令
(11)
且
Uγi=(Ui12,Ui13,…,Uini-1,ni)T,ργi(α1)=E(Uγi)=(ρi12,ρi13,…,ρini-1,ni)T.
因此,α1可由如下估计方程估计
(12)
其中,
Wγi是Uγi的协方差矩阵.如果将Wγi设定为单位矩阵,并且假设Rγi(α1)是等相关可交换矩阵,α1常见的一个估计可以通过下式估计,
(13)
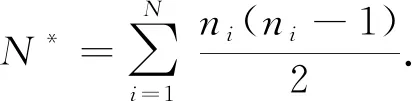
(14)

同理,对于α2的估计值,令
ρβi(α2)=E(Uβi)=(ρi12,ρi13,…,ρini-1,ni)T.
由于Yi服从广义Poisson分布,则α2可由如下方程估计
(15)
其中,
且
Hβi=diag{(1-ui1)(1-ui2),…,(1-uini-1)(1-uini)}.
若假设Wβi是单位矩阵,Rβi(α2)是等相关可交换矩阵,α2的估计为
(16)
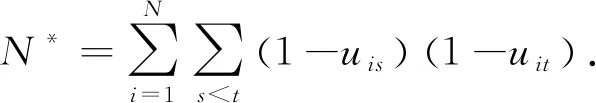
标准化α2的估计为
(17)

本文中对α1,α2的估计分别用的是式(14)和式(17).
为获得参数β,γ,φ,α1,α2的估计值,需要迭代求解.给定参数φ,α1,α2的估计值,由式(5)、式(6)和式(7)迭代,分别得到隐变量和参数β和γ的值. 再作为给定值,由式(10)、式(14)和式(17)得到参数φ,α1,α2的值. 重复上述过程,直到收敛为止.
1.4 模型参数的方差估计
Liang和Zeger[4](1986)表明,在正确指定回归模型的前提下,对于任意选择的工作相关矩阵,广义估计方程估计量都具有一致性和渐近正态性.然而,标准的广义估计方程估计不含有隐变量,如果忽略隐变量所引起的变化,则回归参数估计量的方差会小于真实方差.所以,当估计方程中含有隐变量时,基于响应变量的前二阶矩以及回归参数的当前估计,期望求解算法将隐变量替换为它的条件均值.
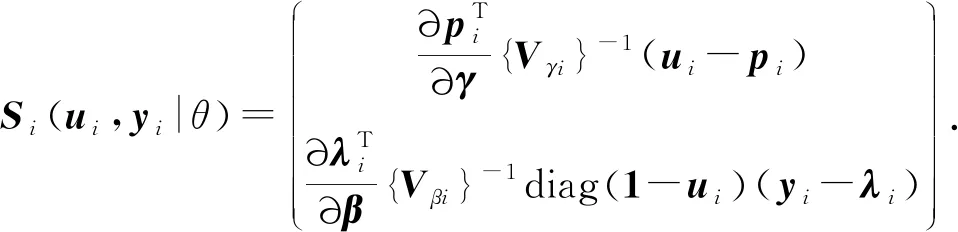

参数θ的渐近协方差由以下sandwich形式给出



2 实例分析
本文使用的数据集是从Iowa氟化物研究数据中收集的一部分数据(http://www1.dentistry.uiowa.edu/preventiing-fluori-study),这是一项研究儿童龋齿的数量与氟暴露关系的纵向数据,目的是从饮食和非饮食两方面说明氟化物来源,识别儿童龋病的危险因素.该研究是在美国Iowa州,从1992—1995年间,每隔1.5—6个月时间,通过牙科医院向儿童父母定期发送问卷,获取健康和饮食方面的数据,包括氟化物摄入量数据. 再通过牙医对所调查儿童牙齿健康和龋齿的程度的诊断,对每颗牙齿进行0、1或2的评分,然后将这些分数相加得到每个儿童龋齿数量评分(CES),将CES作为计数数据进行分析.显然,0在数据集中占主导地位,过多的0提供了零膨胀的证据. 由于儿童不同牙齿的CES有潜在的相关性,一个基于广义估计方程方法分析龋齿是否与不同的暴露和治疗有关是适合的. 模型的响应变量是龋齿数量评分(CES),协变量为受试者牙齿检查时的年龄(Age)、受试者从饮食中摄入的氟化物(AUC)、受试者每次观察时间点前6个月牙医就诊次数比例(Dental Visit)、受试者每次观察时间点前6个月牙齿接受专业氟化物治疗平均次数比例(Flouride Treatment)、受试者平均每天刷牙频率(Brushing),去除变量缺失的观察结果后,研究子集包含352名儿童,总计4 353个观测值.
通过广义估计方程方法,对零膨胀广义Poisson回归模型中广义Poisson计数模型和零膨胀的logit模型分别建模,两个回归模型的协变量分别都使用上述的5个协变量,回归系数(β,γ)的估计值、标准误及Wald检验的P值见表1的上半部分.模型的其他参数(φ,α1,α2)估计结果见表1的下半部分.

表1 基于估计方程方法分析数据的结果
在表1中计数模型部分的结果显示,协变量中牙齿检查时的年龄(Age)、受试者从饮食中摄入的氟化物(AUC),受试者就诊次数比例(Dental Visit)、受试者接受治疗次数比例(Flouride Treatment)4个因素是显著的.其中,受试者从饮食中摄入的氟化物(AUC)与龋齿数量呈负相关,其他因素与牙与龋齿的数量呈正相关.
在表1中零膨胀部分的结果显示,受试者每天平均刷牙频率(Brushing)因素是显著的,而且与零膨胀部分呈正相关,说明刷牙频率越大,零计数就越多,龋齿的数量就越少.
3 讨 论
通过对Iowa州的氟化物研究数据的实例分析,得到了儿童龋齿的影响因素,对实施儿童的预防保健措施提供了依据.本文所得结果与Kong等[6](2015)研究得到结果相仿,说明数据拟合的效果较好,说明本文提出模型与估计方法是合适的. 事实上,具有零膨胀特征的纵向计数数据很多,采用哪种模型拟合,哪种估计方法,还需要进一步深入探讨.本文尝试的基于零膨胀广义Poisson模型的广义估计方程方法,分析实际数据,为今后类似的数据建模提供一个新的路径.
猜你喜欢
价值工程(2022年19期)2022-06-14
数学物理学报(2022年3期)2022-05-25
饮食保健(2019年15期)2019-08-13
中国中医急症(2019年10期)2019-05-21
汉字汉语研究(2018年1期)2018-05-26
小学生学习指导(低年级)(2018年5期)2018-04-24
中国工程咨询(2017年10期)2017-01-31
文理导航·趣味课堂(2016年6期)2016-09-09
文理导航·科普童话(2016年3期)2016-04-26
云南化工(2015年4期)2015-01-11
