
语义关系下英语复杂长句机器翻译算法优化
2020-12-29 09:21:06王红利
机械设计与制造工程 2020年12期
王红利
(陕西警官职业学院,陕西 西安 710021)
英语长句由于句式结构复杂,与汉语句式差异大,已成为机器翻译系统研究开发时的主要难题[1]。目前,关于英语复杂长句机器翻译算法有基于句法分析、多策略分析和语料库翻译等,主要侧重于词义排查、语义特征的处理等[2-4],但这些机器翻译算法翻译准确率偏低,且回收率较高,翻译结果可靠性差。英语复杂长、难句尽管句式复杂,但句内各语义层次相互关联,通过把握复杂长句内语义层次关系,掌握原句内部各层意思,从理论上讲,能够极大提高英语复杂长句机器翻译的准确率和可靠性。基于此,本文基于语义关系,优化英语复杂长句机器翻译算法,并对优化结果进行分析。
1 基于语义关系的英语复杂长句机器翻译算法
1.1 机器翻译算法
英语复杂长句在科技英语中非常普遍,有的甚至长达数十行,包括上百个单词,蕴含很多个从句和非谓语动词,这些从句和短语之间相互依存,具有非常鲜明的语义层次关系。因此在传统切分英语长句的基础上,分析各分句之间的层次关系,利用语义关系进行模型训练,构建语义网络模型进行机器翻译,是科学的且是容易实现的。基于语义关系的英语复杂长句机器翻译算法流程如图1所示。
图1中的机器翻译算法添加了语义关系部分,通过各层次语义关系训练语料库,可以有效避免翻译断层造成的翻译错误。基于语义关系的机器翻译模型的翻译结果更加精确,翻译速度更加快速。该算法利用余弦相似度[5]获得两向量的语义相似关系,通过带权向量加法[6]计算两个相似向量的区别,获得精准翻译结果,通过权重方式训练句子,获得关键短语。
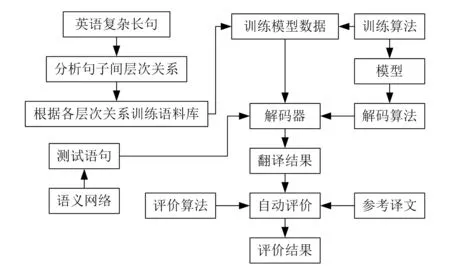
图1 基于语义关系的英语复杂长句机器翻译算法
英语复杂长句的切分简化处理方法为:输入原文句子,逐个扫描其各短语和分句,并通过该短语的基本语义,在实义语料库检索长句切分处理结果。由于长句的分句之间是通过关联特征词连接的,因此以句子的特征点为分界线,将句子分成前后两部分,分别进行翻译,再采用断句拼合的方法,给出整句的翻译结果。而对于句子中的修饰成分、特征关联词和特征标志词等,首先提取出来,并进行优先归约分析处理。
1.2 余弦相似度模型
余弦相似度模型是目前常用的衡量两短语词义差异的重要模型,其基于多维空间,通过两向量夹角的余弦值来表示两向量之间的差异。若两短语之间的余弦值越大,表明两语义向量夹角越小,两短语的词义越接近;相反,如果两短语之间的余弦值越小,则两短语的语义差异就越大。设相同语料库中两个短语为多维语义向量u,v,假定u=[a1,a2,…,an],v=[b1,b2,…,bn],n为向量的维数,则两短语之间的英语翻译相似度Sim(u,v)采用公式(1)进行计算。
(1)
1.3 带权向量加法
相同语料库中的单词可以通过多维语义向量合成语义向量p,具体合成方法如下:
p=u+v=[a1+b1,a2+b2,…,an+bn]
(2)
具体应用分析:短语“复杂长句”语义向量设置为6维向量u=[2,3,8,6,3,1] ,短语“机器翻译”的语义向量设置为6维向量v=[1,2,3,4,5,6],合成的语义向量“复杂长句机器翻译”的语义向量p=[3,5,11,10,8,7]。
直接利用向量合成会造成语义误差,导致翻译错误,为有效解决此问题,本文提出带权向量加法进行修正,具体如下:
p=αu+βv
(3)
式中:α为“英语长句”的权重,α=0.6;β为“机器翻译”的权重,β=0.4。则“英语长句机器翻译”的语义向量p=[2.4,3.2,4.8,6.4,6.2,3.0]。
如果把“英语长句机器翻译”当做新短语,并对“英语长句”、“机器翻译”进行新权重训练,设置新的权重α=0.7,β=0.3,可获得“英语长句机器翻译”新的语义向量为p=[1.7,1.4,5.1,6.8,6.3,2.5]。对比不同权重的两个语义向量,可以发现两个短语存在极大的差别。
英语复杂长句的合成语义向量遵循公式(4):
(4)
式中:ωi为各组合单元的单词语义向量;λi为各组合单词短语的权重。
2 实验分析
为检测本文翻译算法的可靠性和实用性,将其与传统的混合策略翻译算法[7]进行对比分析,混合策略翻译算法是目前常用的机器翻译算法。结果分析评价量包括测试集BLEU值、翻译实例对比、切分正确率、回收率以及交叉连接数。
2.1 实验数据
本文实验数据采用Chinese Treebank 6.0中文树语料库,其包含1 067个文件,20 367个句子,包括英文单词647 523个、汉字963 461个。实验的开发集选择NIST 05,中文句子有1 082句,每句有4个不同的翻译结果,即有英文句子4 328个。测试集采用NIST 06和NIST 08,其中,NIST 06有中文1 641句,即英文有6 564句;NIST 08有中文1 027句,即英文有5 428句。
解码器采用层次短语解码器C++版本。翻译的具体步骤为:英汉、汉英两方向的词语信息对齐采用GIZA++工具实现,主要利用grow-diagfinal-and的启发作用[7]实现多对词语的对齐。翻译结果中的词对齐交叉连接数越小,表明翻译结果准确率越高。英语语言模型获取方式是利用SRILM工具在Gigaword新华部分获取。因为MERT的不稳定性,本文采用Clark等提出的重复实验方法,求平均值作为最终的实验结果。
2.2 实验结果分析
表1为传统翻译算法和本文基于语义关系的英语复杂长句机器翻译算法对不同数据集的翻译评价结果,评价指标为BLEU值[8]。BLEU值是机器译文与参考译文的相似度,相似度越高,翻译质量越好。本文选用NIST 06和NIST 08测试集,获得其翻译评价结果,结果显示本文算法的BLEU值比传统翻译算法分别增加了0.35和0.23,说明采用本文算法获得的翻译结果准确率更高。显著性检验分析[9]结果满足P<0.05。
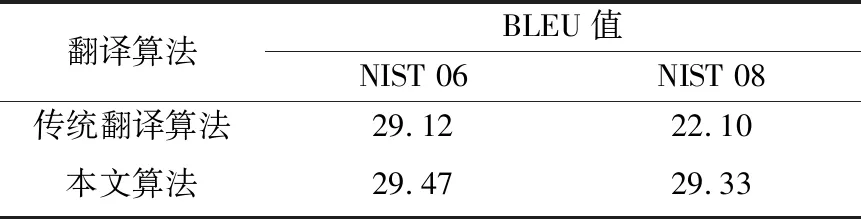
表1 不同算法BLEU值
对测试集中的语句“If the Olympic Games in the summer of 2008 could be hosted in China, which has one quarter of the world's population, it would help boost the popularization of Olympics among the masses” 进行翻译,其中 “ it would help boost the popularization of Olympics among the masses”采用了两种翻译算法,分别是传统的混合策略翻译算法和本文的基于语义关系的英语复杂长句的机器翻译算法。参考译文为“如果2008年奥运会能够在拥有世界人口四分之一的中国举办,将极大推动奥林匹克运动的大众化”,传统翻译算法译文为“如果2008年夏季奥运会能够在中国举办,中国人口占世界人口的四分之一,将有助于推动奥林匹克运动在大众中的普及”,本文算法的译文为“如果2008年奥运会能够在占四分之一世界人口的中国举行,将激发推动奥林匹克运动大众化”。由此可见,采用本文算法得到的译文与参考译文一致,表明基于本文算法的英语复杂长句机器翻译语言准确率更高,翻译结果更加可靠。
表2为传统算法与本文算法的切分正确率、回收率以及交叉连接数平均值对比表。切分正确率和回收率[10]分别表示英语复杂长句划分的准确率和具体翻译时的使用率,这是保证英语长句翻译准确的基础,也是重要的衡量指标。对于英语复杂长难句翻译,切分正确率越高,平均回收率越小,翻译正确率将越高。

表2 不同算法正确率、回收率及交叉连接数对比表
由表2可见:本文算法交叉连接数为16.4,相对于传统翻译算法,减少了12.8,表明本文翻译算法性能更优。与传统算法相比,本文翻译算法具有更高的翻译准确率和回收率,因此具有更高的实用性。
3 结束语
本文基于英语复杂长句各分句(短语)之间的语义关系,提出了一种新的机器翻译算法,该算法借助语义关系和传统切分算法,构建翻译相似度模型的语义网络模型,再利用余弦相似度和带权向量加法优化计算,获得翻译结果,利用权重训练获得关键短语。实验结果表明:
1)该算法具有更高的翻译结果准确率和回收率,既可以实现独立语义表达,还可以有效排除具有歧义的词语。
2)该算法具有更低的交叉连接数平均值和更高的BLEU值,翻译结果更加贴近参考译文。
因此,该翻译算法具有更好的实用性,应用于英语复杂长句翻译具有重要的实际意义。
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
高中生·天天向上(2016年5期)2016-11-21 05:44:58
现代语文(2016年21期)2016-05-25 13:13:46
语言与翻译(2015年4期)2015-07-18 11:07:45
——意群—动态对等法
长春大学学报(2012年9期)2012-09-19 08:00:00
当代外语研究(2010年3期)2010-03-20 14:36:38
中学教学参考·语英版(2008年8期)2008-11-26 10:42:12
