
基于最小和算法的QC-LDPC 译码器的FPGA 实现
2020-12-27 09:27李剑凌陈斌杰
应用科技 2020年5期
李剑凌,陈斌杰
1. 哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001 2. 北京遥感设备研究所,北京 100854
低密度奇偶校验(low density parity check, LDPC)码是一种校验矩阵具有稀疏奇偶特性的线性分组码,由Gallager[1]首次提出,经常用于通信系统和储存系统的纠错,在满足一定的假设条件下,LDPC码的性能非常接近香农容量极限[2]。
随机构造的LDPC 码虽然具有优良的性能,但由于其没有确定性结构,编译码复杂度较大,不利于硬件实现。Fossorier[3]提出的准循环低密度奇偶校验(QC-LDPC)码在译码性能与译码复杂度方面有良好的折中。译码方面,最小和算法由于NR 和LTE 译码模块之间具有可重用性、硬件实现复杂度低等优点成为了现代SoC 设计用于LDPC 译码中使用最多的译码算法。传统的译码结构横向更新与纵向更新是完全分开完成的,纵向更新需等待横向更新完成后才可以开始,这很大程度上限制了吞吐率的提高。本文设计了一种层间流水线结构的译码器,并以FPGA 作为实现平台,以WIMAX 标准[4](2304,1152)QC-LDPC码为例,设计仿真了基于最小和算法[4]的QC-LDPC码译码器,并提高了吞吐率。
1 QC-LDPC 码的校验矩阵
QC-LDPC 码的校验矩阵[5]是由一组循环子矩阵构成,子矩阵具有如下特点:
1)每一个子矩阵都是一个n×n大小的方阵;
2)循环子矩阵的任意一行(列)都是由上一行(列)向右(下)移动一位得到的,特别的,循环子矩阵的第一行(列)由循环子矩阵的最后一行(列)向右(下)移动一位得到。
QC-LDPC 码的校验矩阵可定义为
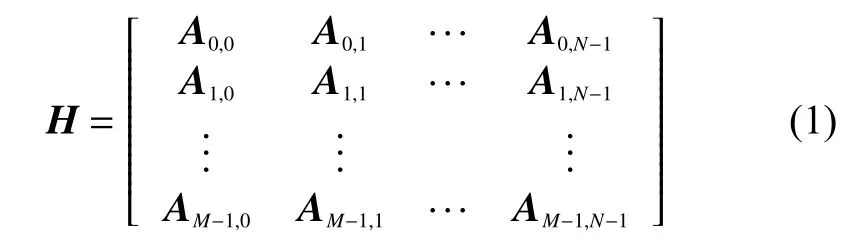
式中:M,N为正整数,Aij是n×n大小的子矩阵,由全零矩阵或单位循环移位矩阵组成。根据式(1)可知,QC-LDPC 码的校验矩阵由M×N个n×n大小单位循环方阵组成。WIMAX 标准(2304,1152)QC-LDPC 码的基矩阵如图1 所示。

图1 WIMAX 标准(2304,1152)QC-LDPC 码的基矩阵
2 QC-LDPC 码的分层最小和译码算法
分层最小和译码算法[6]是分层算法与最小和算法的结合。最小和算法是BP 译码算法的简化版本,对校验节点传递给变量节点的对数似然比概率信息进行近似运算,该算法不需要信道估计,将复杂的双曲正切运算转化为比较(取最小)运算和加法运算,与BP 译码算法相比大大减少了计算量,降低了硬件实现难度。分层算法则是将校验矩阵H以行为基准分为若干层,每层列重最大为1。首先基于第一层进行校验信息的更新;其次将更新后的校验信息代入到变量节点中进行变量信息的更新,当第一层信息更新完成后,即将更新后的信息传递给下一层,继续进行下一层的校验信息和变量信息的更新,直至所有分层都完成信息的更新;最后对得到的后验概率信息进行硬判决并进行校验,如符合判决条件则停止译码,不符合则重新开始直至符合判决条件。在非分层算法中,信息是双向传递的,变量节点需要等待校验节点完全更新后才能开始更新,反之亦然。而在分层算法中的变量信息是用后验概率信息与校验信息来表示的,因此无需储存变量信息;横向更新使用的信息都是上一行或上一次迭代纵向更新的信息。分层译码算法与非分层算法相比,减少了单次迭代所需时间,信息迭代过程中分层译码算法简化了储存器与数据交换网络,降低译码复杂度和链路延时。
具体分层最小和译码算法如下:
1)初始化
利用初始信道信息解调后得到的对数似然比序列对后验概率信息进行初始化:
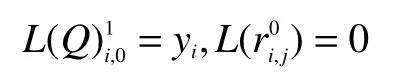
2)分层更新
①根据上一层得到的后验概率信息和校验节点信息更新变量节点信息:式中:n为当前迭代次数;m为当前层数。

②根据更新后的变量节点信息更新当前层的校验节点信息:

式中α为归一化因子,是一个小于1 的常数。
③根据更新后的变量节点信息与校验节点信息更新后验概率信息,作为下一层的后验概率信息:

式中m=m+1,重复步骤①~③,直至最后一层。3)译码判决
则Zi=1;若则Zi=0。
将矩阵H与序列Zi相乘得到校验结果,若校验结果为0 或者达到最大迭代次数,停止迭代;若校验结果不为0 且未达到最大迭代次数,重复步骤2)、3)。
3 QC-LDPC 码译码器的FPGA 设计
本文选择WIMAX 标准(2304,1152)QC-LDPC码来设计层间流水线结构译码器。根据QCLDPC 码的校验矩阵特性可知,该结构十分适合使用水平分层译码算法进行译码,将WIMAX 标准(2304,1152)QC-LDPC 码的校验矩阵分为12 层,每次迭代信息从顶层到底层垂直传递。本文所设计的译码器采用分层最小和算法,既拥有分层算法的高速收敛特性,又具有最小和算法的低复杂度特性。该译码器结构框图如图2 所示。

图2 层间流水线结构译码器结构框图
本文设计的译码器主要包括初始信道信息接收模块、后验概率信息储存模块、节点信息更新模块、校验信息储存模块、控制模块以及判决模块。其主要特点有:
1)优化译码策略,设计流水线结构,通过修正校验矩阵克服了数据冲突的问题,使层间可以并行,有效提高译码器工作效率与吞吐率。
2)优化校验节点更新过程中取最小值与次小值的结构,使其在更短的时间内完成比较功能。
3.1 译码策略
常用的分层译码策略有2 种:1)以层数为并行度的策略,每次迭代所需时间与子矩阵大小n有关;2)以子矩阵大小n为并行度的策略,每次迭代所需时间与层数S有关。对于WIMAX 标准(2304,1152)QC-LDPC 码来说,分层数最小为12 层,子矩阵大小n为96,因此采用以子矩阵大小n为并行度的策略实现的译码器会获得更高的吞吐率。传统的分层译码算法的时序如图3 所示。
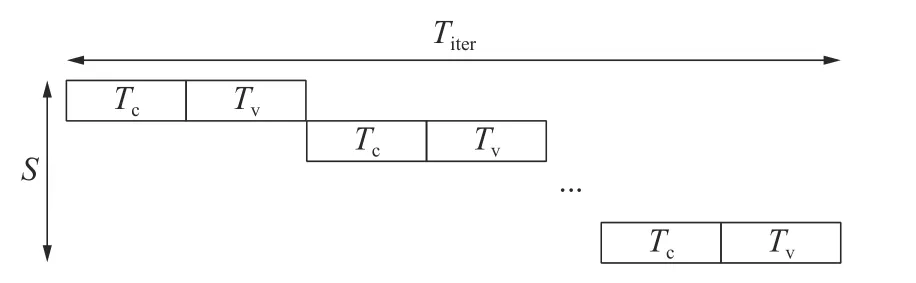
图3 传统分层最小和算法时序示意
图3 中,Tc表示一层校验节点信息读写计算所占用的时间,Tv表示一层变量节点信息读写计算所占用的时间,S表示所分层数。于是一次迭代所需时间Titer=(Tc+Tv)×S。从图3 可以看出,传统的分层译码算法层与层之间是串行进行的,校验节点处理过程和变量节点处理过程是分开的。传统的分层译码算法采用层间串行策略是因为WIMAX 标准(2304,1152)QC-LDPC 码的校验矩阵上下层间都有共用的校验节点,而迭代过程中每次传递的后验概率信息必须是已完成的更新值,否则校验节点会同时处理来自同一变量节点的多个数据,数据冲突导致译码性能急剧下降。为了实现层间并行,需要对校验矩阵进行修正,使上下2 层不共用校验节点。根据这一修正条件,本文将WIMAX 标准(2304,1152)QC-LDPC码的校验矩阵修正为如图4 所示。
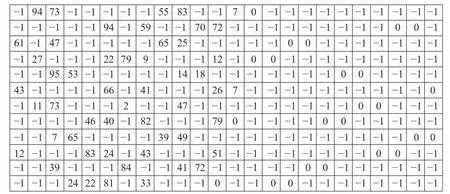
图4 修正后(2304,1152)QC-LDPC 码的基矩阵
从图4 中可以看出,修正后矩阵上下两层不再有共用的校验节点。为了得知修正对WIMAX标准(2304,11452)QC-LDPC 码的影响,对原始的QC-LDPC 码和修正后的QC-LDPC 码进行仿真,并将结果进行比较。仿真条件译码算法采用分层最小和译码算法,最大迭代次数设定为10 次,量化方案采用浮点数量化,得到原始的QC-LDPC 码和修正后的QC-LDPC 码性能如图5 所示。图5中比较结果显示,修正后的QC-LDPC 码译码性能比原始QC-LDPC 码译码性能略有下降,但几乎可以忽略,采用修正后的QC-LDPC 码校验矩阵进行译码可以使层与层间进行交替计算,提高了吞吐量。
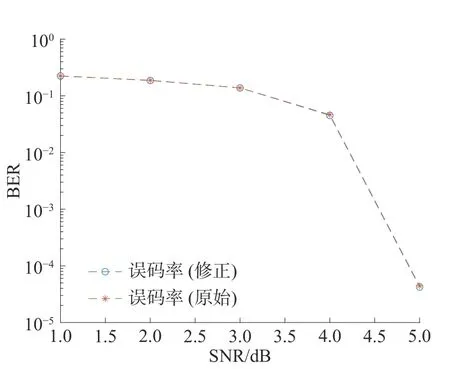
图5 原始译码性能与修正后译码性能比较
本文采用层间流水线策略进行译码,时序图如图6 所示。
图6 中,Tc表示一层校验节点信息读写计算占用的时间,Tv表示一层变量节点信息读写计算占用的时间,S表示所分层数。由于修正后的QCLDPC 码的校验矩阵上下两层不共用校验节点,使得校验节点和变量节点可以并行更新信息,于是一次迭代所需时间Titer=(Tc+Tv)×(S/2+1)。与传统分层译码相比节约了每次迭代的时间,提升了吞吐率。

图6 层间流水线策略分层最小和算法时序示意
3.2 比较模块结构
校验节点信息处理模块是节点信息处理模块中的核心处理单元,它主要完成对从校验节点传输过来的信息的处理。在校验节点更新的过程中,校验节点反馈给变量节点的信息的最小值是不包括该变量节点传递给校验节点的信息的,因此需要比较与校验节点相连的变量节点所含信息的最小值与次小值。比较模块是校验节点信息处理模块中最核心的部分,对于WIMAX 标准(2304,1152)QC-LDPC 码来说,与校验节点相连的变量节点为6 或7 个。文献[7]中使用的是最通用的串行比较器,将输入信息的前2 个值进行比较并将比较结果按最小值(min)和次小值(smin)的顺序储存到寄存器中,并将剩下的信息按顺序与储存的最小值与次小值进行比较,并更新最小值与次小值直至最后一个信息。对于七输入的比较器来说,该方法共需要进行11 次比较,并需要6 个时钟完成比较计算。文献[8]对串行比较器进行改进,使用如图7 所示的结构。
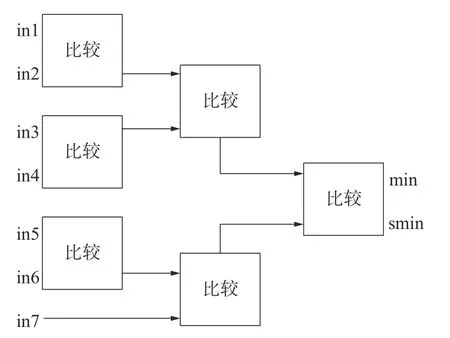
图7 文献[8]中比较模块结构
文献[8]的比较结构将输入信息两两分为一组进行比较,再将比较后的最小值与次小值输入到下一级比较器中进行比较,完成7 个初始信息的比较只需要3 个时钟,该方法也需要进行11 次比较。文献[9]使用了一种交叉比较结构,如图8所示。

图8 文献[9]中比较模块结构
文献[9]中的比较器同样需要进行11 次比较,流水线长度为3 个时钟周期。
本文使用一种树状比较结构,其结构如图9所示。
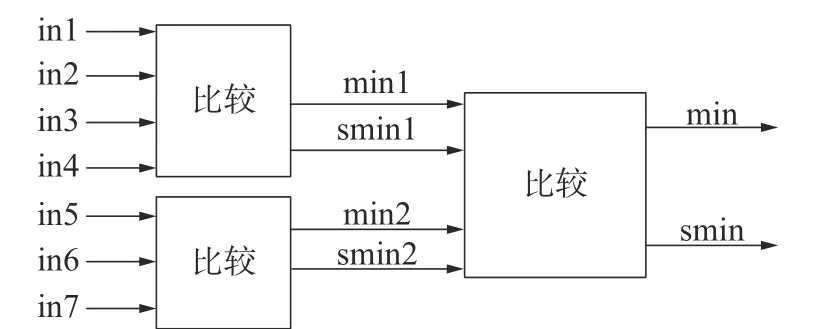
图9 本文比较结构
图9 中,将7 个输入信息分为4 个信息和3 个信息共2 组,分别求最小值和次小值,再将2 组最小值和次小值进行比较得出结果,该结构同样需要进行11 次比较,流水线长度为2 个时钟周期,在不增加计算量的情况下缩短了比较计算所消耗的时间。在硬件资源充裕的情况下可改为组合逻辑电路,在一个时钟周期下完成七输入求最小值与次小值的计算。
4 实验结果及分析
系统在AWGN 信道下测试,调制方式为QPSK调制,采用WIMAX 标准(2304,1152)QC-LDPC 码,译码算法为分层最小和译码算法,最大迭代次数设置为10 次,对基于最小和算法的QC-LDPC 译码器的FPGA 平台进行Modelsim 仿真,流程如图10所示。

图10 LDPC 译码器系统流程
测试流程如下:由Matlab 软件模拟高斯白噪声信道环境产生不同信噪比下的噪声加入到初始信息中,传递给FPGA 的译码器进行译码,译码结束后将结果输出到Matlab 软件中测得译码器性能,再与理论性能比较,比较结果如图11 所示。
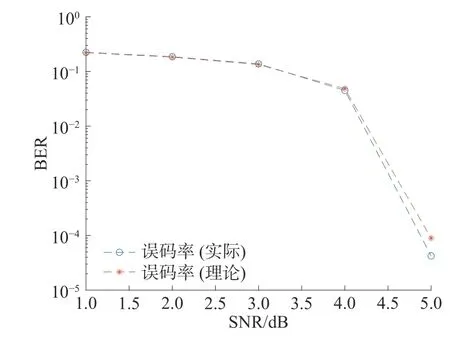
图11 LDPC 译码器实际性能与理论性能比较
通过仿真发现,实际系统与理论相比由于数据量化精度和数据截位等原因会有大约0.1 dB 的性能损失,基本不影响译码器的整体性能,很好地完成了译码的功能。译码器吞吐率公式为

式中:f为时钟频率;N为码长;t为单次迭代所消耗的时钟周期数;i为最大迭代次数。当时钟频率为200 MHz、最大迭代次数为10 时,吞吐量可达1 Gb/s。将本文设计的译码器与其他文献设计的译码器进行对比,其性能如表1 所示。

表1 FPGA 实现的译码器性能比较
从表1 可以看出,与文献[10]、[11]、[12]提出的译码器相比,本文提出的译码器吞吐量最大。
5 结论
QC-LDPC 码由于其校验矩阵的准循环特性使得其硬件实现具有比较低的复杂度,如何提升吞吐率则成为重点。本文针对现有的译码器,从以下2 个方面提出如下改进:
1) 从译码策略角度,针对分层最小和译码由于层间串行限制吞吐率的问题,本文设计了一种层间流水线结构译码器,很好地解决了层间串行的问题,同时提高了吞吐量。
2) 从比较模块结构角度,优化校验节点更新过程中取最小值与次小值的结构,使其在更短的时间内完成比较功能,提高吞吐量。
改进后的译码器大幅提升了吞吐量,但仍有不足,这种改进方法仅适用于基于基矩阵扩展而来的QC-LDPC 码。随着硬件的发展,基于最小和算法的QC-LDPC 译码器在对吞吐率要求高的情况下,会有很好的应用前景。
猜你喜欢
沈阳工业大学学报(2021年6期)2021-11-29
石油沥青(2021年4期)2021-10-14
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
山东交通科技(2020年1期)2020-07-24
振动工程学报(2019年2期)2019-05-13
科技视界(2018年27期)2018-01-16
时代英语·高一(2017年5期)2017-11-14
科教导刊·电子版(2016年36期)2017-04-22
遥测遥控(2015年2期)2015-04-23
