
基于LSTM的中文文本多分类应用研究
2020-12-25 10:00:08梁登玉
上海电力大学学报 2020年6期
梁登玉
(上海电力大学 计算机与科学技术学院, 上海 200090)
随着人工智能的发展,大数据、云计算、机器学习与深度学习已经成为当前的主流技术,随之而来的是对传统纸质文档的颠覆性挑战,电子化、数字化开始占据主导地位。面对海量的数据和信息,采用计算机对数据和信息进行处理,不但可以提高相关操作的效率,还可以在一定程度上提高其准确度。信息挖掘和检索、自然语言处理是目前数据管理的关键技术,而文本分类则是这些技术进行操作的重要基础,因此是目前研究的热点和难点[1]。传统的文本分类主要依靠人工完成,费时费力。为提高文本分类的效率、降低成本,可利用朴素贝叶斯、随机森林和逻辑回归等进行文本分类,但机器学习方法需要进行复杂的人工设计特征和提取特征过程[2]。近年来,深度学习算法在语音和图像领域取得了较大突破,将深度学习方法应用于自然语言处理领域也获得了较大的关注[3]。将深度学习应用到文本分类成为趋势[4-8]。本文采用深度学习的循环神经网络中的长短期记忆网络(Long Short Term Memony,LSTM)实现对商品信息的中文文本多分类,主要研究基于Keras的Embedding的词嵌入方法结合LSTM的文本多分类模型的应用。
1 分类模型
1.1 分类流程
文本分类(Text Categorization)基本流程如下:首先确定分类类别,即文本共分为哪几类;然后对文本作清洗、分词等准备工作;继而将文本向量化处理;再应用具体分类模型训练文本分类器;最后评价分类器性能并进行文本分类。文本分类流程如图1所示。
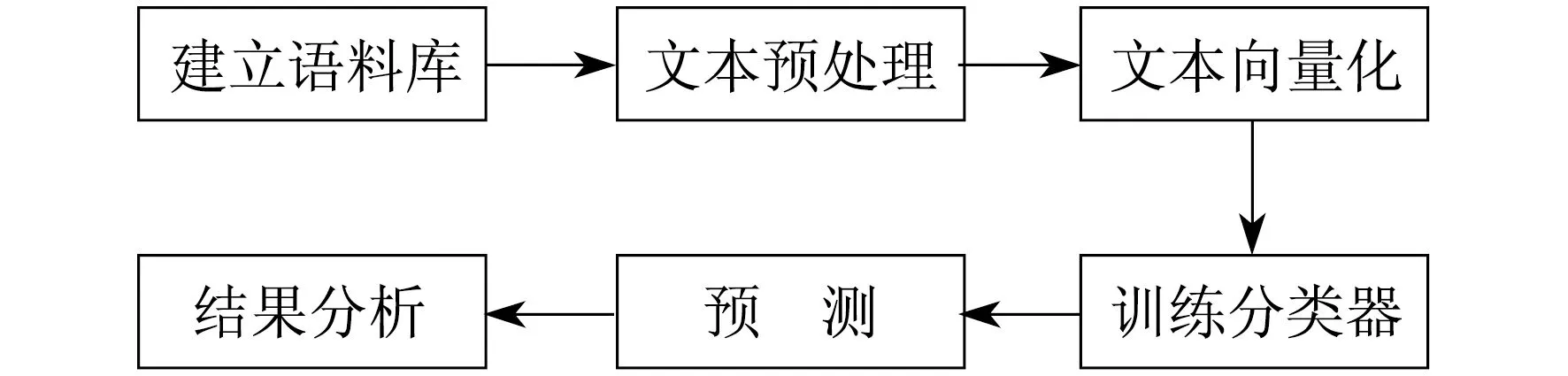
图1 文本分类流程
1.2 文本预处理
中文文本分类先要对中文文本进行预处理,包括删除文本中的标点符号、特殊符号及一些无意义的常用词。因为这些词和符号对系统分析预测文本的内容没有任何帮助,反而会增加计算的复杂度和系统开销,所以在使用这些文本数据之前必须将其清理干净。本文使用jieba分词处理,并过滤无意义的常用词。
在文本处理中,首要的问题就是将人类的语言文本转化为计算机可以理解的计算机语言,把句子用矢量的形式有效地表达出来。这一步的顺利完成将大大降低文本分类的复杂程度。本文使用keras的Tokenizer进行文本预处理,将其序列化和向量化。首先用Tokenizer的 fit_on_texts 方法学习出文本的字典,得到word_index,即对应的单词和数字的映射关系dict,通过dict将每个string的每个词转成数字,再用texts_to_sequences得到序列化文本数据,然后通过padding方法补成同样长度,再用Keras中自带的Embedding层进行向量化处理,并输入到LSTM模型中。
1.3 LSTM网络结构
LSTM控制单元示意如图2所示。

图2 LSTM控制单元示意
根据LSTM网络的结构,设Wf,Wi,Wc,Wo,bf,bi,bC,bo为带角标的模型参数。每个LSTM单元的计算公式为
ft=σ(Wf[ht-1,xt]+bf)
(1)
it=σ(Wi[ht-1,xt]+bi)
(2)
(3)
(4)
Ot=σ(Wo[ht-1,xt]+bo)
(5)
ht=Ottanh(Ct)
(6)
式中:ft——遗忘门限;
σ——Sigmoid激活函数;
xt——当前记忆时刻单元的输入;
it——输入门限;
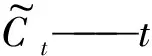
Ct——cell状态;
Ot——输出门限;
ht,ht-1——当前和前一时刻单元的输出。
1.4 基于LSTM的中文文本多分类模型结构
本文采用的基于LSTM的中文文本多分类模型结构如图3所示。
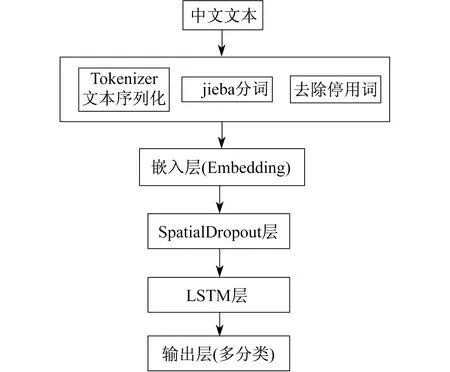
图3 基于LSTM的中文文本多分类模型结构
步骤1 文本预处理。文本预处理包括删除文本中的标点符号、特殊符号及一些无意义的常用词,在使用文本数据之前必须将它们清理干净。然后使用jieba分词。jieba提供了3种分词模式,分别为:精确模式,试图将句子最精确地切开,适合文本分析;全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词。然后对分词结果进行序列化,转化成统一序列的长度,再将序列化的结果输入嵌入层(Embedding)。
步骤2 Embedding层处理。Embedding是一个将离散变量转为连续向量表示的方式。在神经网络中,Embedding非常有用,不仅可以减少离散变量的空间维数,还可以有意义地表示该变量。Embedding有3个主要目的:在Embedding空间中查找最近邻;作为监督性学习任务的输入;用于可视化不同离散变量之间的关系。One-hot 编码是一种常见的表示离散数据的方式。首先计算出需要表示的离散或类别变量的总个数N;然后对于每个变量,用N-1个 0 和单个1组成的 vector 来表示每个类别。这样做有两个明显缺点:一是对于具有非常多类型的类别变量,变换后的向量维数过于巨大且稀疏;二是映射之间完全独立,不能表示出不同类别之间的关系。考虑到这两个缺点,表示类别变量的理想方案是通过较少的维度表示出每个类别,并且表现出不同类别变量之间的关系,因此本文使用Embedding层进行文本的向量化处理。
Embedding可以看作是数学上的一个空间映射(Mapping):map[lambday:f(x)]。该映射的特点是单射、映射前后结构不变。对应到word Embedding概念中可以理解为寻找一个函数或映射,生成新的空间上的表达,把单词one-hot所表达的X空间信息映射到Y的多维空间向量。即将one-hot编码矩阵乘以一个随机初始化的权重矩阵,映射成为一个新的词向量。Embeding层映射关系如图4所示。
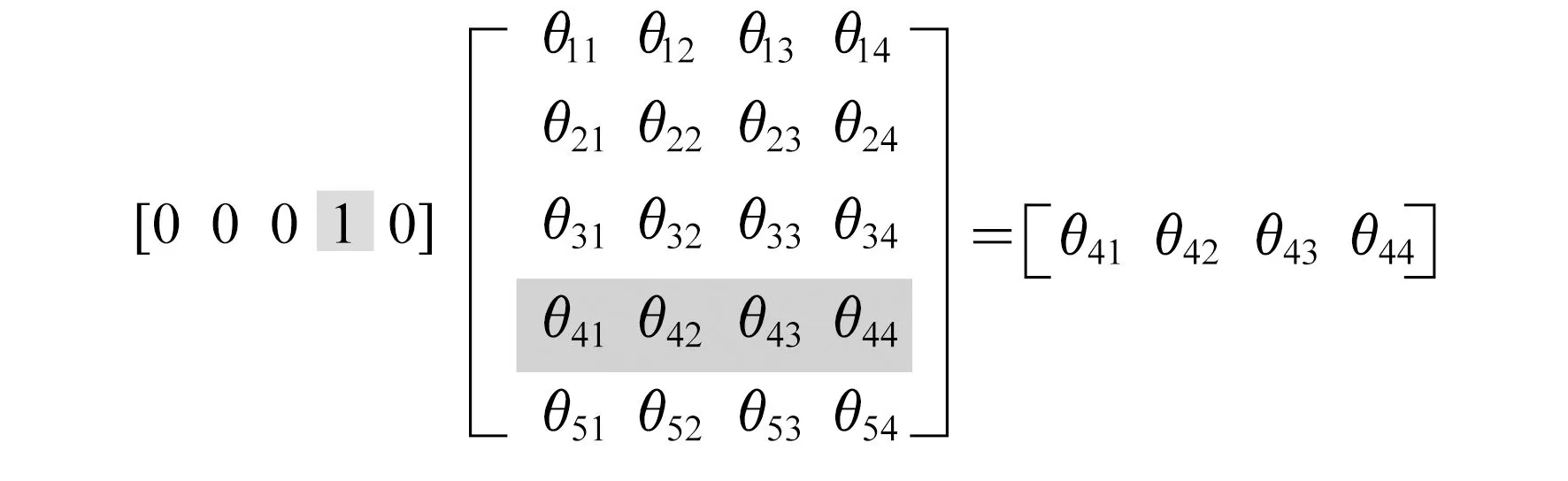
图4 Embeding层映射关系
步骤3 SpatialDropout层。本文使用Keras提供的SpatialDropout1D方法。SpatialDropout1D会随机对某个特定的纬度全部置零,用来防止过拟合。普通的dropout会随机独立地将部分元素置零,而SpatialDropout1D会随机地对某个特定的纬度全部置零。
步骤4 输出层,也就是Dense层(全连接层)。本文使用Keras提供的Dense方法,由于是多分类问题,激活函数采用Softmax,损失函数为分类交叉熵(cross entropy)。Softmax将神经网络的输出变成一个概率分布,表示一个样例为不同类别的概率大小,从而把神经网络的输出也变成了一个概率分布,然后通过交叉熵来计算预测的概率分布和真实的概率分布之间的距离。
Softmax函数的计算公式为
(7)
式中:ai——模型的第i个标签的原始输出;
n——标签个数。
经Softmax函数归一化处理后得到向量s作为预测的概率分布。已知向量y为真实的概率分布,交叉熵的函数为
(8)
式中:si——Softmax函数作用之后的输出;
yi——第i标签的真实分类结果。
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,交叉熵的值越小,两个概率分布就越接近。
2 实验结果与分析
本文的数据集是利用网络爬虫爬取的某购物网站的商品信息数据,数据集中包含10个商品类别(书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店),共6万多条数据。通过LSTM模型将数据划分到不同类别中,且每条数据只能对应10个类中的一个类别。
嵌入层(Embedding)使用长度为100的向量表示每一个词语。SpatialDropout1D层在训练中每次更新时,将输入单元的按比率随机设置为0。LSTM层设置100个记忆单元,输出层为包含10个分类的全连接层,激活函数设置为Softmax,损失函数为分类交叉熵。
本文设置了5个训练周期。将该模型与逻辑回归、朴素贝叶斯、支持向量机、随机森林模型的效果进行对比,通过求混淆矩阵和F1分数进行模型评估。
损失随训练周期变化情况如图5所示。
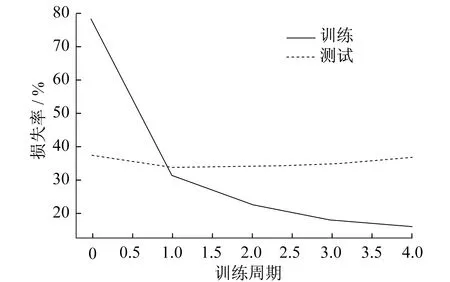
图5 损失随训练周期变化情况
由图5可以看出,在训练集中,随着训练周期的增加,模型在训练集中损失越来越小,这是由于过拟合而导致的;在测试集中,损失随着训练周期的增加由一开始的从大逐步变小,再逐步变大。
准确率随训练周期变化情况如图6所示。

图6 准确率随训练周期变化情况
从图6可以看出,在训练集中,随着训练周期的增加,模型在训练集中的准确率越来越高,这是典型的过拟合现象;在测试集中,准确率随着训练周期的增加由一开始的从小逐步变大,再逐步变小。
多分类模型一般不使用准确率来评估模型的质量,本文借助于F1值来评估模型。评估结果如表1所示。
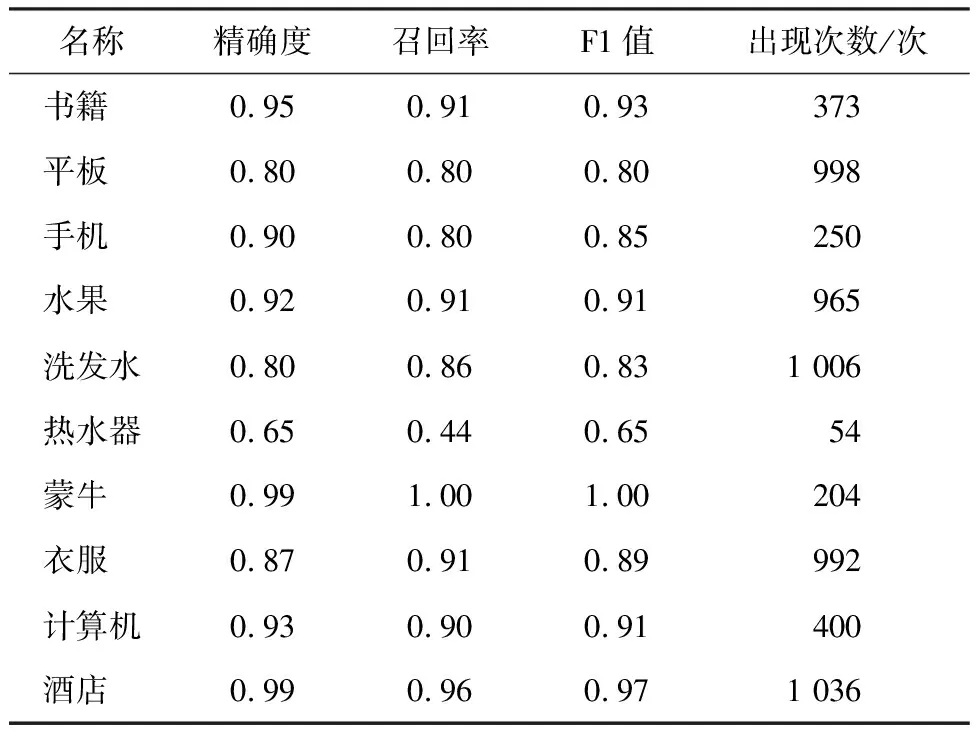
表1 模型评估结果
从F1-score来看,"蒙牛"类的F1分数最大(100%),“热水器”类F1分数最小只有65%,原因可能是因为“热水器”分类的训练数据最少,使得模型学习不够充分。
本文还将该模型与线性支持向量机(Linear Support Vector Machine)、逻辑回归(Logistic Regression)、多项式朴素贝叶斯(Multinomial Naive Bayes)、随机森林(Random Forest)模型作对比,各模型的准确率如表2所示。

表2 各模型准确率对比 单位:%
从表2可以看出,LSTM模型的多分类效果优于其他模型。
3 结 语
本文主要设计了一个基于LSTM模型的中文文本多分类模型,以TensorFlow为框架,使用Keras API实现分类模型,其中使用了 Tokenizer,Embedding,SpatialDropout1D等方法,且用多分类交叉熵评估预测结果。将该模型与线性支持向量机、逻辑回归、多项式朴素贝叶斯、随机森林模型作对比发现,本文的分类模型具有更好的分类效果。不足之处在于,“热水器”类别的训练数据相对较少,使得模型训练不够充分。后期需对模型的参数调优做进一步尝试,以期取得更好的训练结果。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
装备制造技术(2020年3期)2020-12-25 05:22:02
中国交通信息化(2018年5期)2018-08-21 03:37:40
科技视界(2016年19期)2017-05-18 10:18:46
中国工程咨询(2017年3期)2017-01-31 05:29:50
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
