
基于超限学习机的深度网络时间分组行为识别
2020-12-24 07:47裴永强王家伟汤雪芹
吉林大学学报(信息科学版) 2020年6期
裴永强, 王家伟, 汤雪芹
(重庆交通大学 信息科学与工程学院, 重庆 400064)
0 引 言
伴随信息化水平的提升, 视频行为识别已成为国内外人工智能领域研究热点, 在智能家庭设计、 无人驾驶方面均有广泛的应用[1-2]。时间信息是行为识别的重要组成部分, 对识别系统性能的好坏有决定性作用。但因为姿态、 视角等元素的影响, 高效率提取信息具备一定的挑战性, 所以规划涵盖视频语义的精准表达形式是十分必要的。
针对行为识别的相关问题, 王萍等[3]提出一种基于视频分段的实时双通道卷积神经网络行为识别方法。首先将视频划分为多个等长不重叠的分段, 对各个分段随机采样获得代表视频静态特征的帧图像和代表运动特征的堆叠光流图像, 将两种图像依次输入空域和时域卷积神经网络进行特征提取, 在两个通道分别融合各视频分段特征, 获得空域和时域的类别预测特征, 集成双通道的预测特征实现视频行为识别。但该方法识别结果精度较低, 很难应用于真实场景。鹿天然等[4]提出一种线性序列差异分析方法, 应用ViBe算法对视频帧进行背景减除操作, 得到行为区域, 在该区域内提取稠密轨迹特征去除背景数据干扰。使用Fisher Vector对特征编码后进行线性序列差异分析, 采用动态线性规整算法计算序列类别间相似度, 将特征从高维空间投影至低维空间, 利用降维后的特征训练支持向量机, 达到人体行为识别目标。但该方法识别效率较低, 即时性不高。
总结上述方法不足, 笔者提出一种基于超限学习机的深度网络时间分组行为识别方法。建立基于多尺度特征行为识别模型, 获取大致的人体运动行为特征; 利用视频分组稀疏抽样手段, 防止时间建模过程产生信息丢失; 应用超限学习机方法实现深度网络时间分组行为的准确识别。
1 基于多尺度特征的行为识别模型
为得到人体运动行为的简略特征, 降低方法复杂度, 将行为运动轨迹当作大尺度特征, 择取每个瞬时运动人体剪影的最小外接矩形框的中心[5], 模拟人体轨迹坐标。在每个瞬间时段, 一个轨迹相对的是人体质心方位的x、y坐标构成的二维N元矢量{(Xk,Yk),k=1,2,…,N}。使用统一模式编码轨迹, 关于n帧序列, 各个帧的运动人体都是通过二维图像坐标(xi,yi)进行表达, 并满足
fi=(xi,yi)
(1)
将人体运动行为轨迹的流矢量序列记作
T0={f1,f2,…,fi,…,fn-1,fn}
(2)
目标轨迹基本可以形成一个二维信号, 视频持续帧内的运动目标是一个参数曲线。
关于一个完整轨迹划分获得的5条子轨迹拥有不同的序列长度li。假设m是各个子轨迹内的采样点个数, 且li>m, 则在此段子轨迹内均匀收集m个坐标点, 即m帧的图像序列。若li 利用边缘轮廓小波矩特征表示在小尺度内一个姿态的细节特征, 此特征构建在多段定向距离向量傅里叶因子的前提下, 具备平移、 缩放及旋转不变形特性。 按照行为的相关特性, 每个行为事件均是通过诸多主要姿态进行表示的, 这些主要姿态平均分布在一个行为事件每段子轨迹构成的子事件内, 剩余姿态就是主要姿态的过渡[6-8]。主要姿态数量在一定意义上决定了识别率的高低及计算量的多少, 若主要姿态数量太少, 就不能准确表示出人体的行为特征, 从而降低行为识别精度; 若主要姿态数量太多, 则计算数量会成倍增长, 对计算的稳定性造成威胁。因此, 笔者将行为划分为5个主要姿态, 它们依次源于5段子轨迹。 λ(1,2)=(A(1),B(1),π(1),A(2),B(2),π(2),H(1,2)) (3) 式(3)是行为识别模型的无回路无状态拓扑结构, 每个状态都不具备返回前一状态的功能,A(i)、B(i)和π(i)依次是相对层的状态移动矩阵、 原始状态分布概率矩阵。以下为具体运算过程。 (4) (5) (6) 前向变量αt(i,j)是t时段在某个状态(i,j)内生成观察序列的概率, 使用前向方法计算 (7) (8) (9) 通过式(7)~式(9), 可得模型的似然概率 (10) (11) (12) 时间建模方式有两种: 短期建模与长期建模[9]。 长期建模针对某些时间跨度较长的复杂动作具有较优表现。现阶段, 深度网络中最关键的问题就是无法对长时间结构实施模型构建, 这是因为在设计过程中, 仅在单个帧或短片段内进行运作, 致使时间覆盖程度拥有较多的局限性[10]。关于某个时间跨度较长的复杂动作, 想要解决其识别性能较差的问题, 笔者使用视频分组稀疏抽样方法, 能在不受序列长度制约的状态下, 达到对全部视频采取长期时间建模的目标。 将视频V进行等时长分组, 分组个数是K, 即将视频分割成K个相同时长的片段{S1,S2,…,SK}, 对该片段集进行建模 M(T1,T2,…,TK)=H(g(F(T1,W),…,F(TK,W))) (13) 其中(T1,T2,…,TK)是一个片段序列, 各个片段TK均为其相对分段SK内的随机部分,F(TK,W)是使用W当作参数的卷积网络作用在短片段TK时, 返回全部类型片段分数的比例, 共识函数g将作用于多个片段级判断分数聚合, 从而产生视频级判断分数。H是预判函数, 该函数能对全部视频相对的各个动作类别概率进行预判, 概率最高的类型就是视频的所属类型。 值得注意的是,K个分组之间的参数存在交互关系, 在引入H函数前, 需要融合视频级空间与时间的判断结果[11-14], 代入标准分类交叉熵损失原则, 将损失函数解析式描述为 (14) 其中C是动作类型数量,yi是第i类的实际标签。将片段数K设置为3, 则共识函数为 G=g(F(T1,W),F(T2,W),…,F(TK,W)) (15) 采用标准反向传播方法[15], 通过多个片段融合优化模型参数W, 在进行反向传播时, 可将模型参数梯度记作 (16) 应用随机梯度下降优化方法进行模型参数优化时, 式(16)可确保参数更新是通过从全部片段级预判结果中获取的分数。 通过上述过程, 可最大限度保证时间建模过程中信息的完整性, 减少动作识别计算成本, 使所提方法更具优越性。 ELM(Extreme Learning Machine)的数学公式为 (17) 其中L是隐含节点个数,ai∈Rn与bi∈R分别是隐含层参变量,βi∈Rm是第i个隐含节点关于输出节点的权值系数[16],G(ai,bi,x)是第i个隐含节点的输出函数。因此, 将加性隐含节点函数定义为 G(ai,bi,x)=g(aix+bi) (18) 其中ai是第i个隐含节点的输入权重,bi是第i个隐含层节点的误差,g(·)是激活函数。 (19) 将式(19)变换成矩阵模式, 将其描述为 Hβ=Y (20) 其中 (21) (22) (23) 其中训练误差εl能防止出现过拟合问题, 按照相关定义, 将式(23)的求解过程变换为双重优化问题, 具体描述为 (24) 同时按照式(24)推算β最优解 (25) 通过式(25)可知, 超限学习机内的β关键是通过式(22)内的两个矩阵H、Y和正则化因子λ决定的[18],H的维数取决于训练样本个数N及隐含节点数量L,Y是训练样本相对的输出。N与Y都是已知的, 但隐含节点数量及正则化因子需要人为计算, 这两个值对RELM(Regularized Extreme Learing Machine)的性能具备关键作用。 如果RELM是一个二分类问题, 则其决策公式的解通过 (26) 进行推算。假设RELM是一个多分类问题, 则其决策公式解的计算解析式为 (27) 针对RELM, 除了正则化因子外, 隐含节点数量L也会对其行为识别精度产生较大影响。所以, 设计一个可以反映出RELM不同隐含节点关键性的灵敏度推导公式, 再按照不同隐含节点的灵敏度参数对隐含节点进行排序, 继而剔除次要节点[19-20], 得到最优的RELM隐含节点数量L, 增强深度网络时间行为识别准确性。 如果剔除第j个隐含节点, 1≤j≤L, 则可将式(19)转换为 (28) 其中kpi对照于式(19)内的G(ap,bp,xi)。 (29) 关于第i个样本, 去除第j个隐含节点生成的偏差是kji的绝对值和βj的乘积。所以, 针对全部样本N, 将残差对照的第j个隐含节点的灵敏度记作 (30) 其中Rj的值越大, 即证明第j个隐含节点引发的残差越高, 也就是该隐含节点的关键性越强。 通过上述过程, 可进一步提升网络表达能力, 完成深度网络视频行为动作的准确、 高效率识别。 图1 行为识别精度对比示意图 为验证笔者方法的可靠性, 将笔者方法与文献[3]、 文献[4]方法进行仿真实验对比。实验所用的运动数据均源自CMU(Carnegie Mellon University)运动数据库, 识别的行为主要包含以下几种: 行走、 弯腰及跳跃。为了降低训练复杂度, 且保证不丢失行为特征, 对运动捕捉数据根据15帧/s进行稀疏采样。 图1是3种方法的行为识别精度对比。从图1可以看出, 笔者方法行为识别正确率明显优于文献方法, 且伴随实验次数的增加, 曲线依旧呈现较为稳定的状态, 证明笔者方法具备较高的准确性和稳定性, 可适用于多种复杂环境下的视频行为动作识别。文献[3]方法识别精度约为70%, 略逊于笔者方法, 文献[4]方法在初始阶段与笔者方法性能相差不多, 但在后续实验次数增多的情况下, 其算法稳定性逐渐降低。 表1是3种方法行为识别时间均值对比, 从表1中可知, 笔者方法的行为识别效率最高, 用时最短, 而文献[3]与文献[4]方法在行为识别过程中, 所耗时长均高于笔者方法。综合比较而言, 笔者方法实用性最强, 鲁棒性能优良。 表1 行为识别消耗时间均值对比 为了有效提升视频行为识别正确率, 提出一种基于超限学习机的深度网络时间分组行为识别方法。通过模拟人体轨迹坐标, 并对处理后的子轨迹数据分别进行主成分分析, 获取人体运动行为简略特征, 降低算法冗余度; 采用视频分组稀疏抽样方式, 大幅提高时间建模过程中信息完整性; 运用基于超限学习机的深度网络时间分组行为识别方法, 改善视频行为动作识别精度不高的问题, 为行为识别领域的发展提供参考与借鉴。






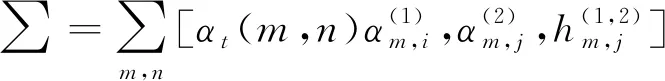



2 视频分组稀疏抽样


3 超限学习机下深度网络时间分组行为识别
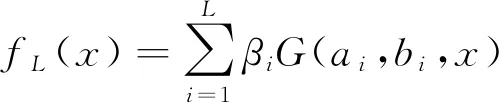

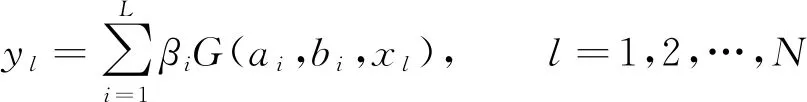

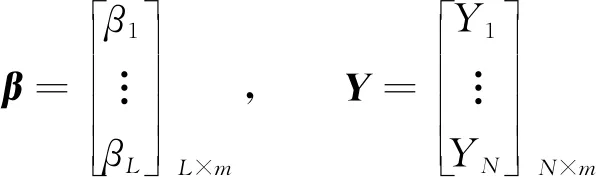
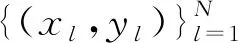







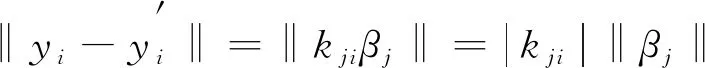

4 仿真实验


5 结 语
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
现代装饰(2018年5期)2018-05-26
自动化学报(2018年2期)2018-04-12
北京航空航天大学学报(2017年6期)2017-11-23
制造技术与机床(2017年4期)2017-06-22
小学生导刊(低年级)(2017年1期)2017-06-12
中国三峡(2017年2期)2017-06-09
