
基于数据挖掘技术的学生成绩系统的设计与实现
2020-12-24 06:41刘思皖
无线互联科技 2020年20期
刘思皖
(宁夏财经职业技术学院,宁夏 银川 750001)
0 引言
学生成绩不仅是反映学生学习效果的重要指标,也是高校改进教学质量的重要依据。传统的学生成绩管理模式主要是利用计算机技术对学生的成绩进行排名,难以有效的挖掘出潜在的有用数据信息,而数据挖掘技术则可以利用关联规则等元素,实现对学生成绩的自动分析。因此本文详细阐述基于大数据技术的学生成绩分析系统。
1 数据挖掘技术的概述
数据挖掘技术是一种知识发现的技术,从大量的不确定、模糊的数据中寻找数据内在的特征和规律,从而发现潜在的有价值的信息,为决策者提供数据依据。一般而言,数据挖掘技术主要包括以下几种:一是分类技术,即从特定的数据群中找出特定类别的描述方法,以此将其进行分类,构造分类模型。例如我们常用的数理统计方法、神经网络模型等等。二是聚类技术,即将数据库中的数据集划分为若干子集,使得每个数据子集内部都具有较强的相关性。例如常见的K-Means、数据统计方法等。三是关联分析,即用于发现数据集合中数据项之间的某种关联和联系,发现其内在的规律性[1]。
数据挖掘技术的使用流程主要包括以下几个方面:(1)数据准备,它是数据挖掘的基础,主要是将数据进行集中汇总,该环节主要是消除数据中的噪声、消除数据间的不一致和模糊性。(2)数据发现,即选择合适的算法和恰当的分析方法将影响数据挖掘的结果。(3)结果表达和解释,它是数据挖掘的最后一个环节,也就是将挖掘的结果以可视化的方式进行展示。
2 基于数据挖掘技术的学生成绩系统设计的内在需求
构建基于数据挖掘技术的学生成绩系统设计必须要清晰地了解系统设计的内在要求,结合实践调查其内在需求主要表现为:一是传统的学生成绩统计模式存在时间长、效率低的问题。例如传统的学生统计模式主要是利用各种表格方式将学生的成绩进行排名,而没有对学生成绩的深层次问题进行准确分析。而利用数据挖掘技术则可以构建出学生成绩分析系统,实现对学生成绩的深层次分析。例如采取NET技术路线(ASP.NET)和Microsoft数据库进行开发,从而设计支持多人协作开发的系统。二是数据挖掘技术可以实现对学生成绩数据的自动化分析,挖掘出潜在有用信息。学生成绩来源渠道不同,而且差异性比较突出,因此在数据采集时需要考虑到数据的变量问题,而对于数据变量的分析则必须要通过数据挖掘技术实现[2]。
3 基于数据挖掘技术的学生成绩系统设计
3.1 体系结构设计
基于数据挖掘的高校学生成绩系统采用3层体系结构,结合上述学生成绩模型,三层体系结构设计如图1所示。3层体系结构将数据和业务逻辑以及系统实现分开,使得系统用户只需专注数据分析结果而无须理会数据的操作过程,具体分为:用户层、功能模块层和基础数据层。基础数据层为最底层的结构,它将基础数据存储于数据仓库中,对数据进行集中管理和处理,数据库中存储的数据包括学生成绩及相关数据、需求字典、数据挖掘方法模型库以及知识库等,系统通过数据库对数据进行读取和操作。功能模块层又称为业务逻辑层,主要由数据挖掘流程管理、数据挖掘需求管理、数据挖掘模型方法管理、数据挖掘结果分析、系统配置管理、数据源配置等功能模块构成。用户层为顶层结构,是系统的展示层,系统用户主要包括学校领导、系部主任、系部教师、在校学生以及系统管理员等。而系部主任和系部教师则是系统的主要用户,他们负责学生成绩数据挖掘并将结果展示给学校领导或相关用户。用户角色和用户权限通过系统配置管理实现。
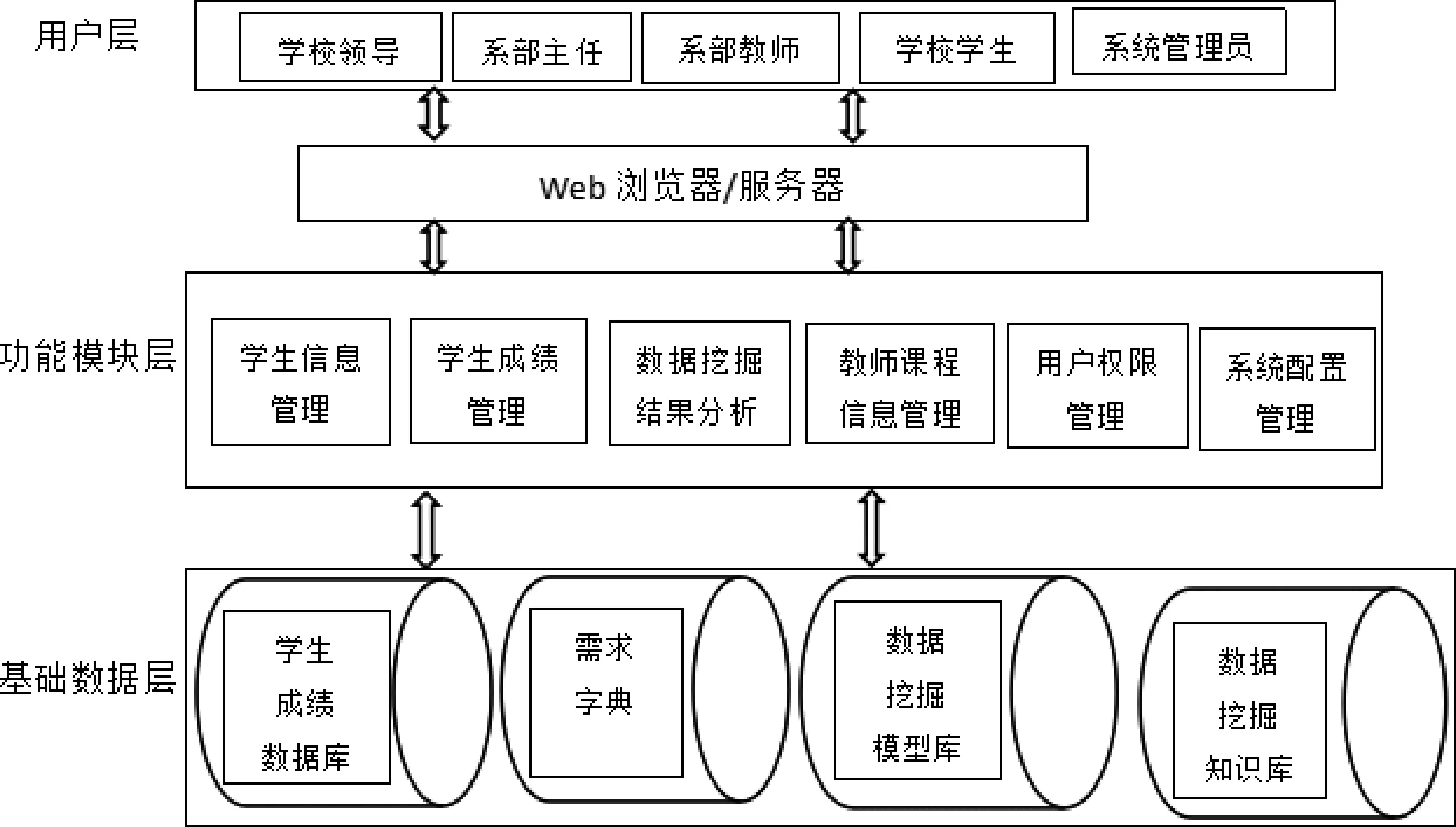
图1 数据挖掘学生成绩系统结构
3.2 功能模块设计
按照功能需求分析结果,系统划分为学生信息管理模块、学生成绩管理模块、数据挖掘结果分析模块、教师课程信息管理模块、用户权限管理模块和系统配置管理模块等6个模块。
3.3 数据库表设计
数据库是一个系统所有数据的集合,这些数据按特定的组织方式存储在一起,通过通用的存取方式合理而高效地完成系统所需要的各类功能。系统信息表主要由系统所有基本编码表组成,这些系统编码表是系统赖以运行的基本;教务信息表包含教学计划表、课程表、班级表、教学资源表等;人员信息表包括教师信息表、学生信息表和教职工信息表。
3.4 应用Apriori算法分析学生成绩
3.4.1 数据挖掘过程
数据挖掘过程是对相关数据进行预处理的过程,主要包括:(1)明确数据挖掘对象与目标。数据挖掘技术使用的关键就是要确定具体的挖掘数据,基于本文设计目标,数据挖掘的对象主要是学生的成绩,因此需要相关人员将涉及学生成绩的所有数据纳入到数据库系统中,为下一步的数据提取、清理工作打下基础。(2)数据预处理。数据预处理就是去除数据中的无关信息,即去除与学生成绩无关或者无效成绩的数据。(3)对数据进行挖掘。对数据库中的数据进行深入分析、挖掘,得出相应的分析结果,为用户提供有用信息。
3.4.2 学生成绩数据采集
为了更好地对学生成绩进行分析,本文以我院计算机专业学生4个学期的所有课程成绩数据作为研究对象,并结合学生的学习兴趣,对这些数据进行清洗、转换等,通过关联规则的算法挖掘出影响学生成绩的关键因素。依据学生的培养方案,学生在学习“必修”“限选”“任选”类课程时必须遵照培养方案中的学分下限要求。由于“限选”和“必修”类的课程囊括了在校学生的学科内部专业课程和基础课程两个方面,同时高校学生的专业课程成绩与学生最终的成绩联系最紧密,即:“限选”和“必修”类课程的重要程度比“任选”类课程高,因此,借助对学生“必修”和“限选”两类课程的成绩数据挖掘分析,忽略“任选”类课程。高校里不同专业开设的课程每学期都小幅度调整、更新,但是“必修”课程和“限选”课程变动情况却非常少,因此,数据库当中这两种类型的成绩出现率也是非常高的,数据存储的时间跨度最大。综合上述,把“限选”和“必修”类课程的成绩作为研究对象,采集数据预期分析效果较为理想,可以有效揭示学生考试成绩所蕴含的关联[3]。
3.4.3 数据预处理
考虑到学生成绩的差异性特点,本次设计将学生的每门成绩按照不合格率、合格率、中等率以及优秀率的等级进行划分,对原始数据进行离散化处理,对学生成绩当中的较高成绩与较低成绩进行深入分析。一方面分析学生考试成绩之间所隐含的影响因素,另一方面分析不同课程之间的关联。数据挖掘过程中应用的数据采集自高校的教学管理的成绩数据仓库:将数据存储在表格内的可以直接导出到CSV等数据集去,预处理阶段处理成绩缺失值等问题。
3.4.4 关联规则挖掘实施
关联规则的挖掘实施是数据挖掘算法实施的关键,本文选择的是关联规则挖掘Apriori算法,因此根据系统设计的原则要求,设置的最小支持度为0.2,最小置信度是0.5。首先需要建立健全Grade数据库,据库中的Course表是用来存储课程信息,Special畸Inf.o用来存储学籍信息,而且ade表是用来存储学生的考试成绩信息的;其次对数据库中的所有信息进行分析,并且对成绩超过80分的进行总结,同时将课程的支持度和课程名称的计数信息存放到频繁1项集的数据表格Frequentl中,Frequentl有两个关键的字段nem和SupCount。再次得到频繁项集之后,就可以计算出相应的候选项集生成相应的频繁项集。最后算出最终的频繁项目集中的非空子集所包含的置信度和支持度,并且拿它们与最小支持度和最小置信度进行比较,比较后删除那些小于最小置信度的记录,并且最终会产生关联规则。
4 系统的测试
为检验系统的各项性能在系统规定允许的软硬件环境下(包括服务器、客户机的各类机器指标如CPU主频、机器结构、硬盘速度、网络带宽、实际传输速率等)是否符合预期给定的指标,需要进行性能测试,主要测试软件在特定环境下的处理速度。而环境要尽量考虑实际运行状态下的环境,根据实际的测试结果分析可知,未发现本系统中存在严重等级较高的异常或错误,从整体上来讲通过了本次测试。
猜你喜欢
民用飞机设计与研究(2020年4期)2021-01-21
电子制作(2018年18期)2018-11-14
电力与能源(2017年6期)2017-05-14
山东工业技术(2016年15期)2016-12-01
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
