
基于深度学习的印刷体文档字符识别的研究
2020-12-23 04:33徐长英赖伟财陈英
现代电子技术 2020年23期
徐长英 赖伟财 陈英


摘 要: 针对传统基于模板匹配光学识别效果存在不理想的状态,提出改进的深度学习模型的印刷体文档字符识别算法。首先,生成包括一级字库、部分二级字库、英文大小写字母和标点符号的图片数据集,其数量大约为500万张;然后,在Lenet?5网络模型的基础上进行改进和重新构造,提出一种增强型的深度学习模型Lenet?5Pro,该模型可提高印刷体文档的识别率;最后,对比实验结果表明,该模型可以更加有效地提高印刷体字符识别的准确率,其字符识别准确率达到98%以上。
关键词: 印刷体字符识别; 深度学习; 图片数据集; Lenet?5Pro; 字符增强; 仿真分析
中图分类号: TN911.73?34; TP391 文獻标识码: A 文章编号: 1004?373X(2020)23?0072?04
Abstract: In view of the unsatisfactory effect of the traditional optical recognition based on template matching, a printed document character recognition algorithm based on improved deep learning model is proposed. A picture dataset including the first?level font library, part of the secondary font library, English upper and lower case letters, and punctuation marks is generated, in which about 5 million pieces of pictures are collected. An enhanced deep learning model Lenet?5Pro, by which the recognition rate of printed documents can be improved, is proposed based on the improvement and reconstruction of Lenet?5 network model. The comparative experimental results show that the accuracy of character recognition can be improved by the proposed model, and its character recognition accuracy is over 98%.
Keywords: printed document character recognition; deep learning; image dataset; Lenet?5Pro; character enhancement; simulation analysis
0 引 言
印刷体文档字符识别是光学字符识别(Optical Character Recognition,OCR)技术的重要组成部分,印刷体文档的识别基本用途是把图片输入计算机,计算机输出识别字符,实现人与计算机信息的交互。文献[1]利用卷积神经网络构建了印刷体汉字识别模型,使用集成了传统OCR识别技术的MODI(Microsoft Office Document Imaging)进行身份证汉字识别。文献[2]提出了一种基于深度信念网络融合模型对手写汉字识别的方法,简单的汉字使用基于SVM(Support Vector Machine)的二次判别函数分类器识别,使用深度信念网络模型处理较为复杂的汉字图像。文献[3]使用基于神经网络反馈的方法对所提取的文本行基于像素点进行判断而进行二值化,结合垂直投影方法对字符切分,提高OCR识别率。文献[4]提出了一种无分割的端到端神经模型,用于离线光学字符识别,结合卷积神经网络(Convolutional Neural Network,CNN)和长期短期记忆(Long Short Term Memory,LSTM)复发网络,使用CNN进行特征提取,并使用堆叠的双向 LSTM进行序列建模。文献[5]提出了一种基于前馈人工神经网络(Artificial Neural Network,ANN)的OCR算法,使用神经网络训练的对象特征数据集改进基于OCR的车牌识别技术。文献[6]提出了STN?OCR,以半监督方式从自然图像中检测和识别文本,STN?OCR是一个集成并共同学习的空间变换器网络,可以学习检测图像中的文本区域,以及识别文本区域并识别其文本内容的文本识别网络。文献[7]提出一种CRNN模型,采用深度卷积神经网络,并行密集层和基于分量连接的检测流水线,采用连接时间分类,结合OCR技术,通过赋值操作和计算公式识别更复杂的图像。文献[8]通过图像处理从所需图像中提取字符区域,并使用深度学习作为学习数据来提高韩文OCR的准确性。文献[9]提出了一种新的OCR加速方法和避免文本欠拟合的方法,建立了一个基于转换传递学习的模型,以实现从文本到图像的域适应,将字符顺序关系从文本转移到OCR。文献[10]提出了深度卷积网络和LSTM网络的组合,并结合投票机制,在运行时间相近时稳定提高了OCR的准确度。
综上所述,各种深度学习的框架和网络模型的提出和建立为图像识别和字符识别提供了一种更高效的方法,但是太复杂的网络时间复杂度高,针对该情况,本文提出一种改进型的深度学习模型,该模型属于轻量级,能够在满足提高识别准确率的基础上降低时间复杂度。
1 基础理论
1.1 卷积神经网络基础
卷积神经网络一般由卷积层、池化层和全连接层构成,其中还有可能包含激励函数层、正则化层。卷积层的主要作用是提取特征。相比于全连接层,卷积神经网络训练的参数将减少许多,降低了网络训练的难度,这个特征简称为局部特征。卷积层参数多少和图片的尺寸无关,它只与卷积核大小、深度以及当前输入图片的深度有关。池化层可以有效地减少矩阵的大小,从而减少最后全连接层中的参数。在卷积神经网络中池化层不是必须的,在有些特殊的卷积神经网络中,可以用卷积层代替池化层。Dropout是为了解决过拟合,它的主要思想在训练时以一定的概率切除输入神经元和输出神经元之间的关联,保留剩下神经元之间的关联,输入和输出保持不变,使用Dropout减少了神经元之间的关联,降低了权重连接,使网络模型更具健壮性。
1.2 Lenet?5
Lenet?5网络相对简单,只有7层,前5层卷积层和池化层交替,3层卷积层,2层池化层,最后2层是全连接层,卷积层使用的过滤器大小为5×5,步长为1,池化层使用的过滤器大小为2×2,使用最大池化进行池化操作,总的参数个数为61 706,步长为2。Lenet?5网络模型如图1所示。
2 改进的Lenet?5
本文在Lenet?5的基础上进行改进(简称为Lenet?5Pro),使用3×3的卷积核,卷积核个数逐层递增,且网络层数增至11层,其中第6层为池化层,第7和第8层为卷积层,第9层为池化层,最后两层为全连接层,并且在网络中加入了BN算法以加速训练。Lenet?5Pro网络模型如图2所示。
在搭建网络模型过程中,模型训练使用的损失函数是交叉熵损失函数,优化算法是BN算法和Adam算法。本文搭建的Lenet?5模型的设置如下:输入图片的分辨率为100×100,全连接层使用ReLu激活函数,正则化层使用Dropout函数来防止过拟合,训练时的Dropout比率为0.8,验证时Dropout比率为1.0,使用BN算法和Adam算法加速训练,Batch_size设置为128,训练的次数为12 000步,每100步进行一次交叉验证,每2 000步保存一次模型。Lenet?5Pro模型的设置与Lenet?5基本相同,但是训练的次数增至16 000步。
3 生成带标注的印刷体字符图像库
国家标准汉字库定义了3 755个一级字库汉字,3 008个二级字库汉字。由于二级字库中较少被日常使用,所以本文采用的数据集包括一级字库3 755个汉字、二级字库1 125个汉字、52个英文大小写字母和38个标点符号,总共4 970类字符。
3.1 生成字符
生成字符的具体过程如下:
1) 对本文所采用的4 970类字符进行标注,建立好每类生成字符和标注文件的关联性,生成标注文件。
2) 确定需要生成字符的字体种类。本文总共采用了黑体、楷体、仿宋体、mingliu体、思源黑体bold、思源黑体black、思源黑体light、思源黑体thin、思源黑体regular模式,总计9种字体。
3) 利用Python中的PIL库生成字体图片。
3.2 增强字符
为了增大数据集,本文在原图片的基础上,采用数据增强的方式增大数据集,数据增强的主要方式包括倾斜、添加椒盐噪声点、膨胀和腐蚀等操作。
倾斜的增强方式是以图片中心为旋转中心,首先进行顺逆时针旋转30°。本文中,旋转的步长为1°,即旋转的幅度由0°~30°以1°递增,由0°~-30°递减,然后从旋转后的图片以图片中心切割出原图片尺寸大小。通过数据增强,每个字符的数据集从9张图片增加到1 098张,扩大了122倍。其中,图片旋转扩大了61倍的数据集,添加噪声是随机的,膨胀和腐蚀是在添加噪声点的基础上进行二选一的操作。以汉字“啊”为例,增强后的图像如图3所示。
经过上述增强操作后,总共生成的图片总量为5 457 060张,字符样本集统计如表1所示。
4 实验结果及分析
4.1 实验准备说明
本文实验在深度学习框架TensorFlow上运行,实验设备为32 GB内存的英特尔酷睿i9?7900x CPU和11 GB内存的英伟达1080Ti GPU。
实验中,所采用的数据集是自采集的字符图片数据集,采集的过程如前文所述,其中,数据集中约80%的数据作为训练集数據,剩下的20%作为验证集数据。另外,本文还使用了基于OpenCV程序裁剪的测试图片集。本文所使用程序全部由Python语言编写,主要包括5个模块:数据传输模块、网络搭建模块、模型训练模块、模型验证模块和测试模块。数据传输模块主要将数据从硬盘读写到内存进行训练;网络搭建模块主要搭建卷积神经网络;模型训练模块主要用于模型的训练与生成;模型验证模块使用测试集进行验证;测试模块用于测试识别印刷体文档图片内容。
训练时采用GPU加速,每100步进行交叉验证,模型训练完成后,进行一次完整的验证,验证时分别计算Top1,Top5和总体识别准确率。
4.2 印刷体文档的识别结果对比
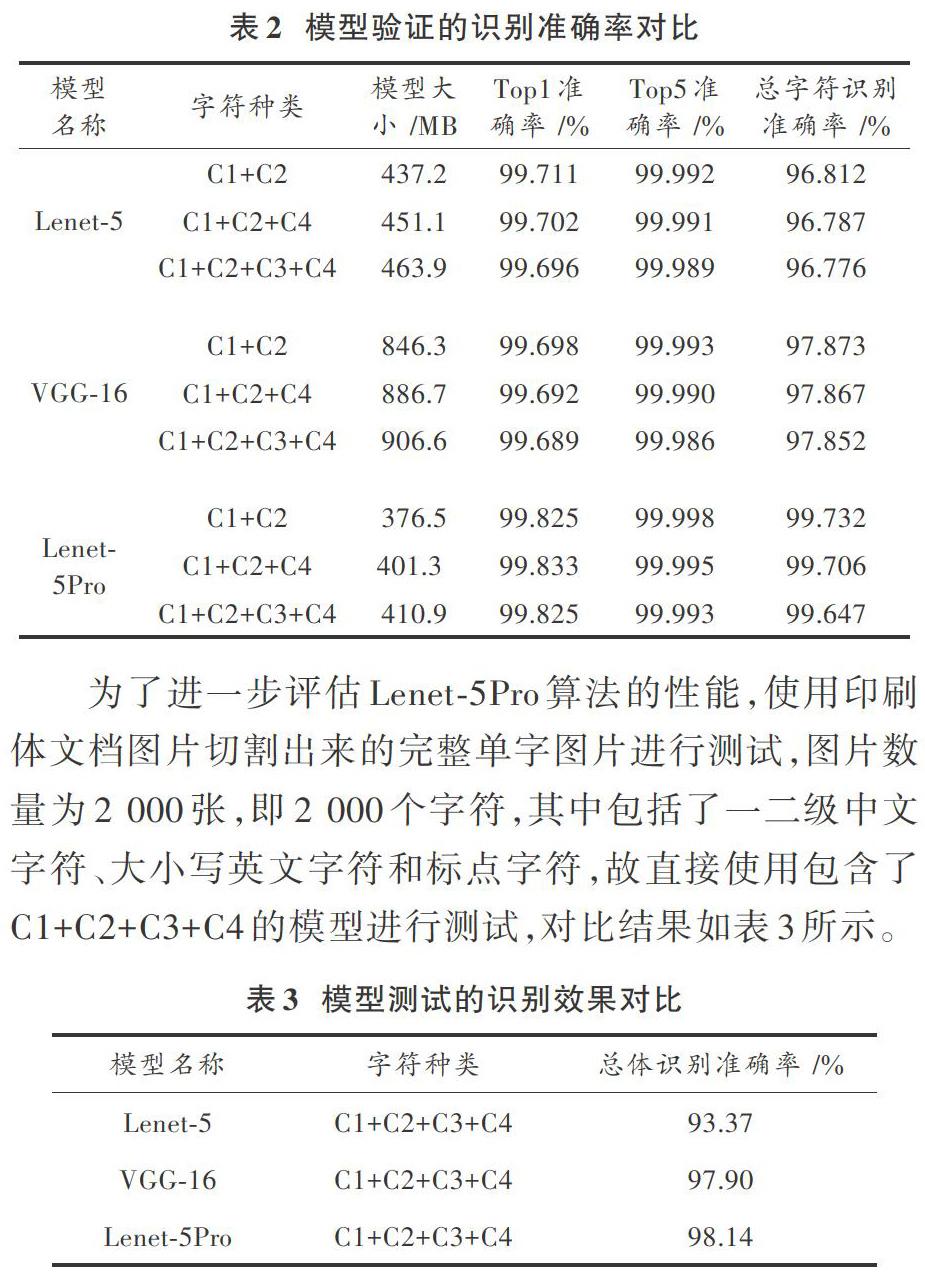
分别使用3个模型进行测试,其中准确率=正确个数/测试个数,总字符指的是所有字符均被正确识别的结果,时间表示平均每个字符被识别的平均时间。验证模型的识别准确率统计后如表2所示。
为了进一步评估Lenet?5Pro算法的性能,使用印刷体文档图片切割出来的完整单字图片进行测试,图片数量为2 000张,即2 000个字符,其中包括了一二级中文字符、大小写英文字符和标点字符,故直接使用包含了C1+C2+C3+C4的模型进行测试,对比结果如表3所示。
从表3中可以看出,Lenet?5Pro的识别效果比其他两个模型的效果要好。综合表2和表3的结果可以看出,Lenet?5Pro模型无论在验证集还是测试集的准确率都比其他两个模型高,尤其是在测试集上的准确率比其他两个模型均要高,主要原因是这些模型在识别切割太碎的汉字时,识别率下降,从而导致识别率整体偏低。同时,VGG?16模型无论从卷积层的层数以及参数个数和训练难度上都比Lenet?5Pro模型要高,理论上VGG?16模型测试集准确率应该要比Lenet?5Pro要高,但实际效果有一定的差距,整体来说,Lenet?5Pro的识别效果达到了预期水平。
5 结 语
本文从印刷体字符识别技术入手,提出了改进的Lenet?5Pro模型对字符进行识别,所做的工作包括:生成大量用于训练的印刷体汉字等字符的图片集以满足本文所改进的深度学习模型,同时,数据集可以扩展到其他文字和其他语言,扩展性强。对经典的深度学习网络进行了一定的改进,实验结果表明本文网络模型的有效性和准确性。但由于改进后的网络相对简单,针对较相似的字符识别容易发生错误,今后将尝试采用不同的网络来训练,以达到更好的鲁棒性。
参考文献
[1] 刘冬民.基于深度学习的印刷体汉字识别[D].广州:广州大学,2018.
[2] 孙巍巍.基于深度学习的手写汉字识别技术研究[D].哈尔滨:哈尔滨理工大学,2017.
[3] 汪一文.深度卷积神经网络在OCR问题中的应用研究[D].成都:电子科技大学,2018.
[4] RAWLS S, CAO H, KUMAR S, et al. Combining convolutional neural networks and LSTMs for segmentation?free OCR [C]// 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). Kyoto, Japan: IEEE, 2017: 155?160.
[5] KAKANI B V, GANDHI D, JANI S. Improved OCR based automatic vehicle number plate recognition using features trained neural network [C]// 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT). Delhi, India: IEEE, 2017: 1?6.
[6] BARTZ C, YANG H J, MEINEL C. STN?OCR: a single neural network for text detection and text recognition [EB/OL]. [2017?07?27]. https://deeplearn.org/arxiv/11984/stn?ocr.
[7] JIANG Y X, DONG H W, EI SADDIK A. Baidu Meizu deep learning competition: arithmetic operation recognition using end?to?end learning OCR technologies [J]. IEEE access, 2018, 6: 60128?60136.
[8] KANG G H, KO J H, KWON Y J, et al. A study on improvement of Korean OCR accuracy using deep learning [C]// Proceedings of the Korean Institute of Information and Communication Sciences Conference?The Korea Institute of Information and Communication Engineering. [S.l.: s.n.], 2018: 693?695.
[9] HE Yang, YUAN Jingling, LI Lin. Enhancing RNN based OCR by transductive transfer learning from text to images [C]// Thirty?second AAAI Conference on Artificial Intelligence. New Orleans, Louisiana, USA: AAAI Press, 2018: 8083?8084.
[10] WICK C, REUL C, PUPPE F. Improving OCR accuracy on early printed books using deep convolutional networks [EB/OL]. [2018?02?27]. https://www.researchgate.net/publication/323444203.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
美与时代·美术学刊(2020年7期)2020-10-13
校园英语·月末(2020年4期)2020-06-08
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
成都信息工程大学学报(2017年3期)2017-11-09
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
中学生天地(C版)(2016年4期)2016-09-16
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
