
一种基于弱监督学习的线上借贷反欺诈方法*
2020-12-23 06:12郑忠斌胡瑞鑫周宁静王朝栋
通信技术 2020年10期
郑忠斌,胡瑞鑫,周宁静,王朝栋
(1.工业互联网创新中心(上海)有限公司,上海 201303;2.同济大学,上海 200092)
0 引言
近些年,随着网络通信技术的日新月异,人们能够高效收集到各种各样的信息,而各行各业也都已经完成了大量数据的积累。这些海量数据在极大改善和丰富人们生活的同时,不免让人们重新思考如何更好地进行信息组织、查找与分析。随着应用场景越来越复杂,人工方式已经不再能够面对如此庞大的信息。基于这些变化,处理数据的机器学习(Machine Learning)方法的地位迅速提升。目前,网络安全与金融经济等众多领域均非常关心机器学习相关的研究进展,其中网络借贷由于便捷性逐渐受到了广泛关注。但是,网络借贷中存在大量欺诈申请,若借贷人无法及时归还借贷金额,会造成借贷公司的经济损失。关于欺诈和欺诈活动有很多定义。注册欺诈审查员协会(Association of Certified Fraud Examiners)将“欺诈”定义为通过故意滥用或误用雇佣组织的资源或资产来占用他人个人资产的行为。文献[1]中提到欺诈的主要成因是通过非法手段获取虚假的利益,将对经济、法律乃至人类道德价值观产生巨大影响。文献[2]中提到涉及金钱和服务的几乎所有技术系统都可能受到欺诈行为的影响,如信用卡、电信、医疗保险、汽车保险和在线拍卖系统等。
反欺诈本质上可以表示为一个二分类的异常检测问题,其中正常数据为一类,欺诈和异常数据为另一类。反欺诈模型建立的目的是将欺诈数据从所有数据中区分开来。但是,与传统的二分类问题相比,该领域所使用的数据有很大不同。反欺诈领域中,数据集中的异常数据样例通常较少,而正常数据通常占据绝大部分,同时异常数据的某些或者全部特征通常与其他数据点差别较大。监督学习侧重于对有标签的数据进行训练,而对无标签样本逐一进行标记往往不现实,需要耗费大量的人力物力。面对这种标签数量缺失的情况,无监督学习应运而生。相比监督学习,无监督学习是一种无标签数据进行挖掘的学习模式。换而言之,无监督学习是在不需要给数据打标签的基础上进行数据挖掘工作。无监督学习的特点是在仅对其提供无标签的数据情况下,能够自动从这些数据中找出其潜在的类别规则,在学习完毕并经测试后应用到新的数据上。无监督学习模型在学习时并不知道其分类结果是否正确,也就是说没有标签告诉模型何种学习是正确的。
显然,如果只进行监督训练,使用少量“昂贵的”有标记的样本而抛弃大量“廉价的”无标记的样本,是对数据资源的一种极大浪费。如果使用无监督学习,则数据集中的标签不能被有效利用,同时训练出的模型具有很大不确定性。针对这两种情况,目前已有研究人员提出将少量的有标签样本与大量的无标签样本一起进行学习的策略,即弱监督学习算法。人们希望能够使用弱监督学习的办法,将有限的标签信息和大量未标记数据中的信息有效利用起来,结合少量有标签数据和大量未标记数据中的信息,达到相应的分类和预测效果。
在这个过程中,本文主要做出了以下贡献:基于借贷数据集构成的关系图,实现基于图的半监督算法。利用在数据集上构建关系图,并在关系图上用Louvain 算法进行社区发现,能够在大规模数据集上高效快速完成模型构建。其中,详细展示了Louvain 算法的实现、如何对社区发现结果进行标签传播以及使用K-S 值衡量反欺诈模型的效果并调整参数。
本文旨在研究分析弱监督算法在互联网金融反欺诈领域的应用,选取网络借贷场景进行研究。结合理论和实证分析,在借贷数据集上构建申请信息的关系图;结合借贷欺诈场景中非数值型数据集的特征,设计相应的弱监督反欺诈模型;在标签数量不足的情况下,基于图进行半监督反欺诈模型的构建,并评估相应算法在该数据集上的表现。实验表明,该算法能够在实际应用中有效识别出欺诈。
1 相关工作
最初的欺诈检测研究主要集中在统计模型,如逻辑回归和神经网络。1988 年,神经网络就被用在金融预测领域[3]。1995 年,Sohl 和Venkatachalam首先使用反向传播神经网络预测财务报表欺诈。2001 年和2002 年,Bolton 和Hand 用统计学习方法对欺诈检测进行了一些一般性分析。2006 年,Yang和Hwang 使用过程挖掘方法研究医疗保健欺诈。而在近期的相关研究中,Huang 使用逻辑回归和支持向量机调查了一系列台湾公司的财务报表欺诈行为。Soltani Halvaiee 和Akbari 利用人工免疫系统识别了一家匿名巴西银行的信用卡欺诈行为。Sahin等人使用决策树对欺诈用户建模,认为在模型评估上准确率和TPR 并不适合这种问题,并以此改进了决策树的损失函数[4]。Zareapoor 和Shamsolmoali利用集成学习分类器,对比朴素贝叶斯、支出向量机和K 近邻算法进行信用卡用户的反欺诈建模,发现集成学习的效果好于单一的算法[5]。West 和Bhattacharya 讨论计算机智能和云计算在金融反欺诈系统上的运用[6]。Gulati 和Dubey 等使用神经网络并引入用户地理位置信息建立反欺诈系统,效果能够提升80%[7]。
弱监督学习方法适用于在构建模型的过程中,使用的训练数据只有一小部分数据有标签,而大部分数据没有标签,且只用这一小部分有标签的数据不足以训练一个好的模型的情况[8]。弱监督学习是一个较为总括性的术语,涵盖了试图通过较弱的监督来构建预测模型的各种研究。其中,数据标签可能存在数量不足、粗粒度较大以及不够准确的情况。
在针对数据集标签数量不足的半监督学习中,有两个基本假设,即聚类假设(Cluster Assumption)和流形假设(Manifold Assumption)。这两个假设都是关于数据分布的。前者假设数据具有内在的聚类(Cluster)结构,处在相同聚类中的数据有较大的可能拥有相同的标记[8]。根据该假设,决策边界应该尽可能通过数据较为稀疏的地方,从而避免把稠密的聚类中的数据点分到决策边界两侧。后者假设数据分布在一个流形上,处于一个很小的局部邻域内的示例具有相似的性质。这一设定反映了决策函数的局部“平滑”性[9]。和聚类假设着眼整体特性不同,流形假设主要考虑的是模型的局部特性。这两个假设都揭示了数据分布信息与其类别标记相互联系[10]。利用未标注数据中的数据分布信息,可以更好地找到样本点之间的关联和预估样本点的标签,从而提高模型性能。
2 方法设计
Louvain 算法是一种基于模块度(Modularity)的社区发现算法,在效率和效果上都表现较好,并且能够发现层次性的社区结构。算法优化的目标是最大化整个图属性结构(社区网络)的模块度。Louvain 算法得到的社区结构是分层的,每一轮计算完成后得到的新图都是对一个大社区内若干细分社区发现的结果。这样的分层结构得到的是每个网络的自然属性,使人们能够深入了解某个社区的内部结构和形成机制。同时,Louvain 算法的性能较好,对图的大小几乎没有上限要求,并且能在迭代几轮后快速收敛,使得该算法有能力处理拥有百万级别以上节点的大型网络。
Louvain 算法主要包括两个阶段。第一阶段,不断遍历网络中的结点。假设每个节点为1 个社区,N个节点。初始化N个社区,尝试将单个结点加入能够使模块度提升最大的社区中,直到所有结点不再变化。第二阶段,处理第一阶段结果,将一个个小社区归并为一个超结点,重新构造网络。算法不断迭代这两个步骤,直至所有子社区模块度相加值不再变化。
模块度Q由Newman 等人[11]提出,能用来评估算法结果的好坏。模块度Q的公式定义为:

其中Ai,j代表节点连接节点i、j的边的权值;ki表示与节点i相连的所有边权值之和;ci为节点i所归属的社区;而δ(ci,cj)为一个关于节点归属社区的函数,函数中两个变量相同时取值为1,反之为0。Q值的取值范围为0-1,值越大,说明网络划分的社区结构准确度越高。
首先,假设网络中每一个节点归属于一个社区。对其中任一节点i,计算将其并入相邻社区后整个网络Q值的变化ΔQ:

找到Q值变化最大的社区(若计算得到ΔQ为负,则不改变i的归属社区)。按照Q值增加的方向,将一个社团的节点不断移至另一个社团,直至Q函数达到峰值。当Q值不再发生变化,即将一个节点转移到网络内的另一个相邻社区不能带来ΔQ的提升时,此时网络内所有节点不再移动,得到的各个社区将作为新图的节点。
当执行完Louvain 算法后,划分出若干个社区,其中每个社区可以看作是数据中的一个群体。到目前为止,需要对得到的社区中的节点进行分类,即为每个社区打上标签。
根据社区发现算法的原理,所得到的最佳划分的每个子簇都代表一个社区,每个社区内部的标签应该一致。根据每个子社区中有标签节点的标签对整个子社区进行标注。当存在标签为0 的节点时,将子社区其他未标记数据标为0,如图1 所示。

图1 标记过程示意1
当存在标签为1 的节点时,可以将子社区其他未标记数据标为1,如图2 所示。
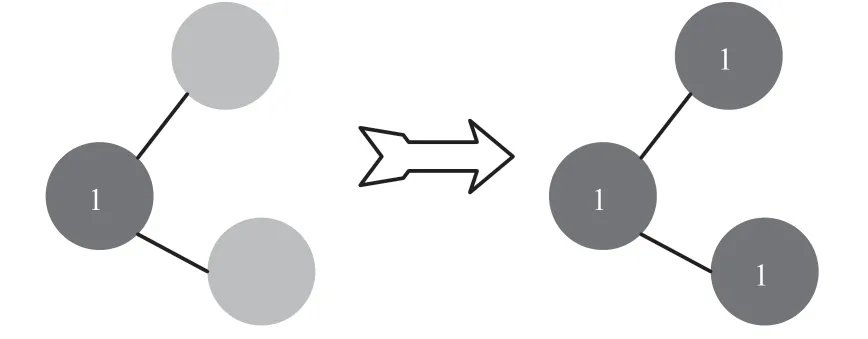
图2 标记过程示意2
当子社区中同时存在标签为0 和标签为1 的节点时,将子社区其他节点标为数量多的那方的标签,如图3 所示。

图3 标记过程示意3
3 实验验证
3.1 数据集简介
本实验中使用的数据集为某银行的借贷数据集,数据集已经过脱敏处理,不会泄露客户个人信息。该数据集是一个非常典型的非数值型数据集,共有38 个特征。除了label 特征用来表示每条数据的标签外,其余特征皆是字符串类型的数据。数据集共有229 407 条数据,其中包含了大量无标签数据。Label 为0,表示交易正常,共28 171 条数据;label 为1,表示交易存在欺诈申请,共2 546 条数据;label 为2 和空,表示交易无法判断是否存在欺诈申请,共198 690 条数据。
3.2 模型评估指标
KS值是一个常用来衡量风控模型优劣的指标[12],在模型中能够用于区分预测正负样本分隔程度,因此非常适合用于评估反欺诈分类的效果。
计算KS值时涉及到的各项指标、含义和计算方法,如表1 所示。
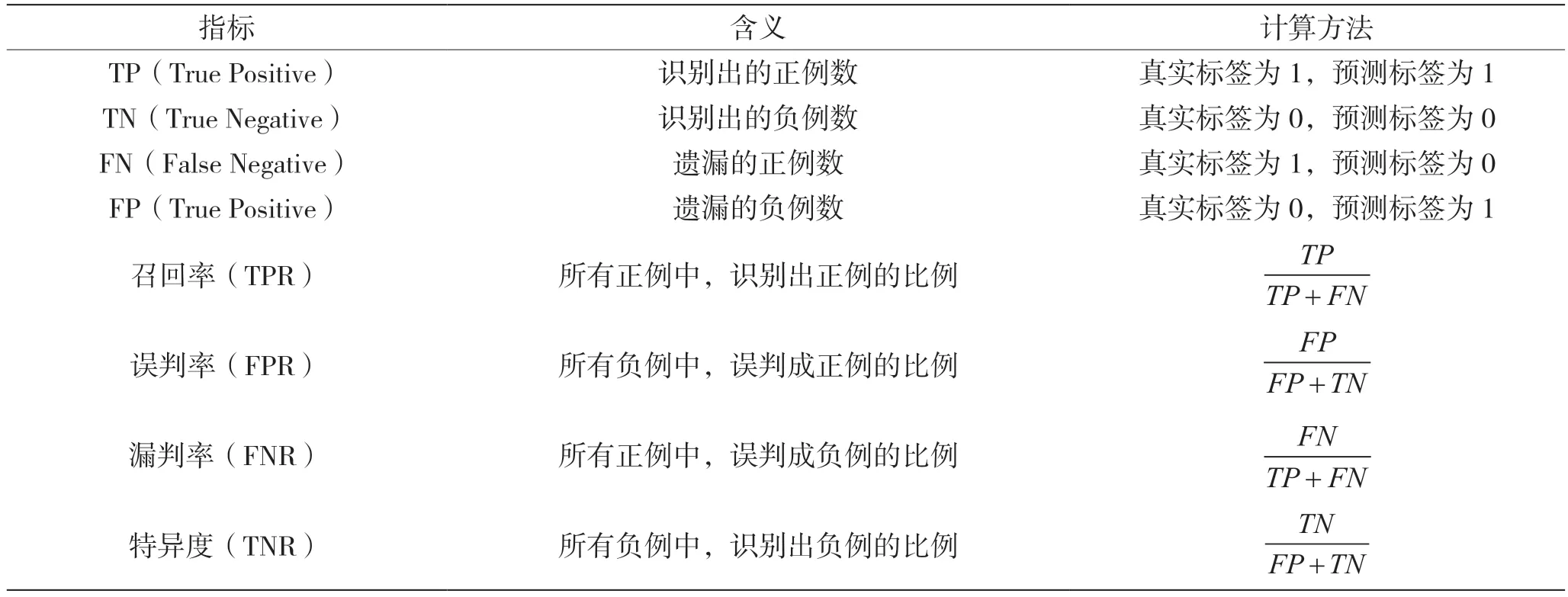
表1 模型评估相关指标描述
KS值的计算公式为:

KS值越大,说明模型区分正例和反例的效果越好。
3.3 实验性能
利用NetworkX 导出Neo4j 数据库中的图。在数据库中为每种关系都建立边,因而存在两个节点之间有多条边的情况。这里合并节点间的多条边,将关系图存储成无权图的格式。最终,所得无权图共含有197 862 条边。在关系图上运行Louvain 算法,得到的最佳划分的模块度为0.904 8。
执行完Louvain 算法后,得到了关于关系图的一个划分。对得到的社区中的节点进行分类,即为每个社区打上标签。标注过程结束后,在训练集对应的测试集上评估预测结果,得到的KS 值为0.446,混淆矩阵如表2 所示。

表2 Louvain 算法性能
通过调整标签标记的方式来提高模型的性能。在标签标记过程中,当一个子社区中同时出现标签为1 的节点和标签为0 的节点时,根据双方数量的多少来判断剩下节点的标签。现在改变这一判定标准,定义欺诈占比Fr:

根据Fr可以制定更精细的标注方法。首先,分别统计每个子社区中的欺诈占比Fr。其次,设定划分基准rate。当Fr>rate 时,子社区标签为1,否则标签为0。可知,当rate=0.5 时,根据1 和0的数量多少来判定标签,即式(3)中使用的方法得到的KS值为0.446。通过改变rate的值,可以得到KS关于rate变化的曲线。
根据图4,当rate设置在0.2 时,得到的KS值最高。因此,将模型的rate定为0.2,最终的KS能够提升到0.46。

图4 KS-rate 折线图
4 结语
本文基于现有的反欺诈和弱监督算法研究,探索了如何在银行借贷数据集上构建反欺诈模型,使得现实场景中在有标签数据不足时的情况下也能及时识别欺诈,取得较好的反欺诈效果。在互联网金融领域构建一个反欺诈模型,需要从实际的应用场景出发,结合数据集的特点全面判断合适的算法,不可直接生硬套用模型,同时需要从各种模型评估的角度选择相应的算法。未来将尝试构建性能更优的弱监督反欺诈检测方法,并将多种弱监督算法进行集成学习,从而进一步提高反欺诈的检测性能。
猜你喜欢
眼科新进展(2022年12期)2022-12-29
今日农业(2021年19期)2022-01-12
汽车维修与保养(2019年7期)2020-01-06
中国外汇(2019年16期)2019-11-16
中国外汇(2019年10期)2019-08-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
领导决策信息(2017年13期)2017-06-21
Coco薇(2015年11期)2015-11-09
商界(2015年9期)2015-10-15
