
基于抽象语法树和XGBoost 的jsp_webshell 检测方法研究*
2020-12-23 06:12茅雨绮
通信技术 2020年10期
茅雨绮,施 勇,薛 质
(上海交通大学 电子信息与电气工程学院,上海 200240)
0 引言
随着互联网应用的不断发展,在以浏览器/服务器(Browser/Server,B/S)架构作为基础的Web应用逐渐成为主流的当下,Web 安全面临着更加严峻的考验。
国家互联网应急响应中心(National Internet Emergency Center,CNCERT) 发 布 的《2019 年我国互联网网络安全态势综述》[1]报告中提到,2019 年国家信息安全漏洞共享平台(China National Vulnerability Database,CNVD)收录安全漏洞数量创下历史新高,共计16 193 个,其中Web 应用漏洞排名第二,占18.7%。2019 年监测到境内外约4.5万个IP 地址对我国境内约8.5 万个网站植入后门,较2018 年增长超过2.59 倍。
Webshell 可以以多种语言编写,包括php、asp以及jsp 等。由于php 语言不需要特殊的开发环境,被大多数系统支持,且php 语言的安全隐患较多,故基于php 的webshell 最常见。此外,使用jsp 开发的网站也越来越多,许多银行、金融公司等均使用java 架构进行系统开发。在这种架构中,攻击者可以通过上传jsp_webshell 来远程访问并控制web 服务器,包括上传、下载、修改、删除文件,操作数据库,执行其他任意命令等,危害极大。因此,检测jsp 类型的Webshell 是否存在,对防止攻击者进一步控制服务器、保障Web 服务器安全非常必要且急迫。本文提出了一种基于抽象语法树和XGBoost 的jsp_webshell 检测方法,首次将抽象语法树序列特征和GloVe 词嵌入算法应用到Webshell检测,提取jsp 文件的java 抽象语法树(Abstract Syntax Tree,AST)序列特征,通过GloVe 模型得到词向量特征文本,最后使用XGBoost 分类器进行jsp_webshell 检测。
1 相关研究
Webshell 是在服务器上运行的可执行代码,可以视为一种远程访问工具(Remote Access Tool,RAT)或后门特洛伊木马文件。jsp_webshell 是用jsp 编写的Webshell,文件可能非常小,只需要一行代码,或者可以长达数千行,具有各种功能。有些是自给自足的,包含所有必需的功能;有些则需要外部操作或由“命令与控制”(Command&Control,C & C)客户端与之进行交互。攻击者上传Webshell 的常用方法是利用网站中常见的漏洞(如SQL 注入、文件包含和上传等)远程生成或安装Webshell 文件。一旦成功安装了Webshell,远程攻击者就可以使用嵌入命令直接向Webshell 发出HTTP 请求。该命令将被执行,就好像攻击者具有对Web 服务器的本地访问权限一样。
目前,国内外对于Webshell 检测的研究主要侧重于php 类型的Webshell,使用的方法主要有基于静态特征的检测、基于流量特征的检测、基于行为特征的检测以及基于日志的检测方法。
基于流量和行为特征的检测属于动态检测方法。Yang J 等人[2]提出了一种语义感知方法,通过分析Web 访问流量,提取URL 资源和URL 查询来检测恶意Web 流量。王应军等人[3]通过提取Webshell 流量中HTTP 请求的参数名和参数值作为特征,并使用机器学习模型对Webshell 进行检测。杜海章等人[4]针对php 类型的Webshell 进行实时动态的检测,在php 扩展中对php 代码编译和运行的过程进行监控,从而检测并阻止恶意的php_webshell。Wrench 等人[5]也提出了动态检测方法,通过去混淆和相似度矩阵分析方法提高了召回率,但误报率较高。Canali D 等人[6]通过构建蜜罐网站进行实时监测,解析恶意代码的行为,建立恶意行为库检测Webshell,但需要消耗大量资源,部署难度大,且只能检测处于活动状态的Webshell。
基于日志的检测方法可用于系统被入侵失陷后进行排查,通过区分正常Web 网页和Webshell 在日志文件中的不同特征检测是否存在Webshell。石刘洋等人[7]分析服务器的日志文本,通过文本特征、统计特征和页面关联特征的匹配进行检测,区分Webshell 和正常网页文件的日志文本。潘杰[8]使用单分类支持向量机和神经网络算法对日志进行了聚类,并通过遗传算法优化模型,提高了模型的准确率。Miao Xie 等人[9]通过K 最邻近(K-Nearest Neighbor,KNN)算法检测日志中的疑似Webshell行为。Yixin Wu 等人[10]从Web 日志中的原始序列数据中提取特征,通过基于时间间隔的统计方法识别会话,发现基于LSTM 的模型保持了较高的召回率和准确性,但基于日志检测的方法可能会产生大量误报,且由于日志数量庞大,大量的读写日志很可能会对服务器的性能造成影响。
基于文件特征的检测属于静态检测方法,通过文件的静态特征对Webshell 进行检测,检测速度较快,而且能够在攻击者利用Webshell 代码执行前进行检测,是目前检测Webshell 的最常见方法。Truong 等人[11]提出了基于最佳阈值的方法来识别包含来自Web 应用程序的恶意代码文件。利用统计学方法统计Webshell 文件中出现的恶意函数、命令执行函数等频率,但易被加密混淆的Webshell绕过。易楠等人[12]提出了一种基于语义分析的Webshell 检测方法,通过构建抽象语法树,使用节点评分表对语法树进行风险评估,对危险节点进行污点子树定位,最终通过构建风险模型进行匹配评估,实现对Webshell 的检测,但该方法对于变种的Webshell 的检测效果并不理想。随着机器学习模型的不断成熟,机器学习的方法被广泛运用于Webshell 的检测来提高有效性和准确性。文献[13]使用word2vec 模型将HTTP 请求中的每个单词表示为一个向量,并将Web 请求表示为固定大小的矩阵。使用基于CNN 的模型来对恶意Webshell 和普通Webshell 进行分类,实现了较高的精度。文献[14]使用了fastText 文本分类器和随机森林算法来构建php_webshell 的检测模型。文献[15-16]使用php 操作码序列作为特征,分别结合TF-IDF、Word2Vec和多层感知器(Multi-Layer Perceptron,MLP)神经网络对Webshell 进行检测。
2 基于抽象语法树和XGBoost 的jsp-webshell检测模型
目前,基于静态特征和机器学习的检测模型的研究主要针对php_webshell。为研究针对jsp 类型的Webshell 检测方法,本文提出了基于抽象语法树和XGBoost 的jsp_webshell 检测模型,训练框架如图1所示。本节先介绍jsp_webshell 的特征和jsp 代码的编译过程,获得jsp 文件执行的java 代码,然后介绍java 抽象语法树的特征提取及其对Webshell 检测的作用,阐述提取语法树词向量的GloVe 算法,最后介绍本文使用的XGBoost 算法。
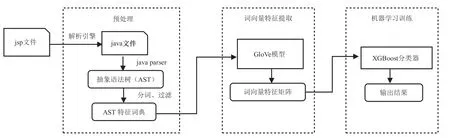
图1 基于抽象语法树和XGBoost 的jsp_webshell 检测模型训练框架
2.1 jsp_webshell 原理与特征
2.1.1 攻击原理
webshell 典型的功能包括文件操作、目录操作、对数据库的操作、端口扫描、注册表操作、查看系统信息、挂马功能、执行系统函数以及加密函数等敏感操作。图2 是一个简单的jsp_webshell 的源代码,其中的java 代码部分是将request 请求中的“cmd”参数的值作为系统命令执行的参数。攻击者可以通过GET 请求构造恶意的请求注入cmd 参数,从而实现远程调用服务器端的控制台,达到任意命令执行的目的。
2.1.2 静态特征
jsp_webshell的静态特征包括两个方面。一方面,危险函数的调用,如图2 所示的Webshell 代码中调用的getRuntime().exec(),可将函数内的命令行参数作为系统命令执行。为了绕过一些传统的静态特征检测机制,Webshell 会进行编码或加密,可能用到base64_decode 等函数,而这些都是正常页面文件很少用到的函数,可作为Webshell 检测的一个特征。另一方面,最长字符的长度,即文件中最长不间断字符串的长度。由于一些Webshell 会使用base64等编码或加密函数来进行混淆,从而绕过简单的特征码匹配检测方式,因此会产生较长的无空格间断的字符串,而正常的页面文件在对参数进行命名时几乎不会产生这样的字符串。因此,通过获取文本的最长字符串长度,也可以作为Webshell 检测的一个特征。

图2 jsp_webshell 源代码
由于jsp_webshell 主要通过嵌入其中的java 语句实现其功能,因此首先对jsp 文件进行预处理,将其转化为对应的java 文件后对其进行语法分析,剥离token、注释、字符串、变量以及语言结构,得到抽象语法树序列,包含了函数调用的名称、参数名以及参数类型等特征。为了避免一些Webshell为绕过检测而添加一些无用的不可读注释,通过语法树提取删除无用注释,最终得到了语法树结构序列特征。

图3 jsp 文件编译与执行流程
2.2 jsp 编译与执行
为提取java 抽象语法树特征,需要对jsp 源代码进行转换,得到对应的java 文件。jsp 文件无法直接运行,需要经过如图3 所示的编译与执行流程。当客户端访问jsp 文件时,jsp 引擎会将jsp 文件中的HTML 代码和Java 代码全部转换为java 代码,并编译生成class 文件。编译后的class 对象被加载到容器中,根据用户的请求生成HTML 格式的响应页面返回给客户端。
2.3 抽象语法树(AST)特征提取
抽象语法树是程序编译的中间表示形式,使用树状的形式直观标示出源程序的语法结构,具有较高的存储效率,在语义分析、程序分析等领域具有广泛应用。Java 语言的抽象语法树会把java 源代码中的各种元素,如类、属性、方法、代码块以及注释等定义成相应的对象。由于java 是一种强制类型的语言,与php 等弱数据类型语言相比,数据类型和语法结构定义更严格,因此通过提取java 文件的语法树序列特征,可以更好地表征jsp 执行的java代码结构,保留了代码的上下文语境信息,避免无意义的注释等Webshell 逃逸方法,从而分析其是否执行了恶意代码。
为了获取java 语法树的特征,需要对java 代码进行解析,包括词法和语法分析,得到java 抽象语法树。遍历该抽象语法树对其进行分词和过滤,删除对检测Webshell 无用的节点,如注释、html 语句等,得到抽象语法树的序列特征,其中包括调用函数名称、参数名称以及参数类型等。一个简单的helloworld 代码得到的语法树序列特征如图4 所示。

图4 helloworld 语法树序列特征
2.4 GloVe 模型
学习词向量表示的方法主要有以下两种。一是基于全局矩阵分解的方法,如LSA,对词汇-文本矩阵进行奇异值分解构造潜在语义空间,并得到文本在语义空间的表示。该方法虽有效利用了全局统计信息,但是在词汇类比方面能力较差。二是局部上下文窗口的方法,如Mikolov 在2013 年提出来的Word2Vec 算法,包括CBOW 和skip-gram 两种模型,能够较好地进行词汇类比,但未有效利用全局统计信息。为了结合以上两种方法的优点、克服其缺陷,2014 年Jeffrey Pennington 等人提出了一种新的基于词共现矩阵理论的GloVe 模型[17]。该模型基于全局词汇共现的统计信息来学习词向量,从而结合了全局统计信息与局部上下文窗口方法的优点,提升了应用效果。
使用GloVe 模型进行训练时,会将每个词降维表示为词向量。对于给定的特征词i,其词向量vi可以表示为:

其中,n为向量的维度,wj是特征词i的第j个维度。GloVe 模型构造了一个词共现矩阵的近似矩阵X。矩阵中的每一个元素Xij表示词汇j出现在词汇i的窗口大小固定的上下文中的次数总和。GloVe 模型使用的损失函数J如下:

(1)f(0)=0,当词汇共现的次数为0 时,此时对应的权重应该为0;
(2)f(x)必须是一个非递减函数,目的是保证当词汇共现的次数增大时,权重不会出现下降的情况;
(3)f(x)的值应较小,使得对于频繁的共现组合也不会赋予很大的值,从而防止过度加权。
综合以上3 点特性,提出了下面的权重函数:
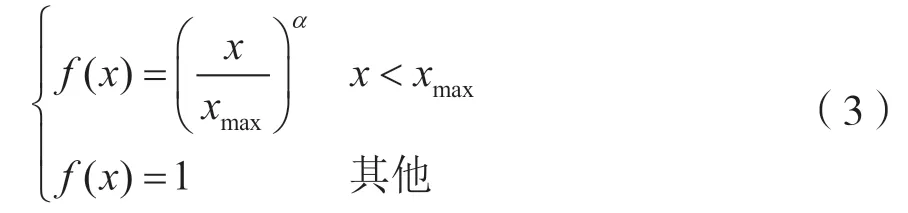
试验发现xmax=100、α=3/4 时效果较好。
本文设定维度n=100,特征词阈值m=800,将提取到的AST 特征文本进行分词,并视为一个句子s。若句子s中的特征词数量少于m,则取前m个特征词;若少于m,则以0 补全。使用GloVe 模型对语法树序列特征文本进行词向量提取,得到的m×n的特征矩阵如下:

2.5 XGBoost
梯度提升树(Gradient Boosting Decision Tree,GBDT)是Friedman 等人在2001 年提出的一种boosting 算法[18],采用加法模型(即基函数的线性组合),通过多轮迭代,不断减小学习过程产生的残差,从而对数据进行分类或回归。XGBoost(eXreme Gradient Bosoting)[19]是Tianqi Chen 在GBDT 的基础上提出的改进算法。与传统的GBDT相比,XGBoost 对损失函数进行优化,保留了二阶泰勒展开,并对树的复杂度项增加了一个L2 正则化项,还引入了缩减因子和列抽样,避免了过拟合。同时,该算法在寻找最优分割点的算法上加以改进,提高了分类的精确度。本文试验了KNN、支持向量机、随机森林和XGBoost 等几种机器学习算法对jsp_webshell 检测的性能,最终选取性能最优的XGBoost 算法作为机器学习检测模型的算法。
3 实验与结果分析
3.1 实验数据与过程
本文收集的jsp_webshell 样本和正常样本均来自github 等开源网站,共收集了2 137 个样本,其中Webshell 样本507 个,正常样本1 630 个。
对照实验中,分别选取KNN、支持向量机、随机森林和XGBoost 这4 种机器学习算法,并选取了Word2Vec 和TF-IDF 两种词特征提取方法和GloVe方法进行对比。具体实验过程如图5 所示,先将正常样本和Webshell 样本进行预处理,得到java 文件,并对其进行AST 特征提取;使用Word2Vec 和TFIDF 算法与GloVe 算法进行对比,提取词特征矩阵;为了验证XGBoost 算法的性能,分别使用python 的sklearn 模块中的KNN、支持向量机以及随机森林算法与XGBoost 算法进行对照实验。
3.2 模型训练与参数选择
本文通过4 折交叉法,将训练数据分为4 个子集。每次训练将其中一个子集作为测试集,剩余子集作为训练集。随机抽样训练4 次,取4 次训练的平均准确率作为参考指标进行模型参数的选择。最后,选取参数如下:KNN的邻居数n_neighbors 设为3;支持向量机的惩罚系数C 设为10;随机森林的决策树个数n_estimators 为200,最大深度max_depth 为37;XGBoost 的决策树的个数n_estimators 为125,最大深度max_depth 为5;TF-IDF 的最大特征数为500;Word2vec 和GloVe 的窗口大小为100。
3.3 实验结果与分析
使用机器学习算法进行二分类时,会产生4 种结果,即正样本被判定为正样本(True Positive,TP)、正样本被判定为负样本(False Negative,FN)、负样本被判定为负样本(True Negative,TN)和负样本被判定为正样本(False Positive,FP)。本文将Webshell文件定为正样本,将正常文件定为负样本。

图5 实验过程
本文选择机器学习中的准确率(accuracy)、精度(precision)、召回率(recall)以及F1 值(F1-score)4 个指标进行模型评价。其中,准确率表示预测正确的样本数占所有样本的比例;精度表示被预测为Webshell 的样本中实际为Webshell的比例;召回率表示Webshell 样本中被正确预测为Webshell 的比例,召回率越高,意味着漏报率越低;F1 值是精度和召回率的调和平均值。由于精度和召回率的度量角度是矛盾的,F1 值综合了两者的度量,因此F1 值是一个很好的综合性评价指标,能更好地表示模型的检测性能。以上4 种指标的计算方式如下:

使用4 折交叉验证法对以上4 种指标计算平均值,实验结果如表1 所示。

表1 jsp_webshell 检测模型的实验结果
从实验结果可得,使用GloVe 算法提取词向量特征比使用TF-IDF 算法和Word2Vec 算法的性能更优。在机器学习算法选取上,KNN 算法的性能最差;支持向量机和随机森林算法虽然精度很高,但是召回率较低,综合性能不高;XGBoost 算法虽然在精度上略低于随机森林算法和支持向量机算法,但在召回率、准确率和综合性能上均优于其他算法。综合以上结果,使用GloVe 算法提取词向量特征,结合XGBoost 分类器进行检测,综合性能最优,尤其在召回率方面,相比其他算法具有显著优势,对jsp 类型的Webshell 有更好的检测效果,准确率高达98.73%。
4 结语
本文提出的基于抽象语法树和XGBoost 的jsp_webshell 检测方法,首次针对jsp 类型的Webshell进行语法树特征提取,并首次使用了在自然语言处理中较为新颖的词向量训练方法GloVe,对jsp 文件预处理后提取的java 语法树序列特征进行词向量提取,结合XGBoost 分类器进行有监督的学习,从而检测jsp_webshell。通过与传统的机器学习模型和其他词向量特征提取方法进行对比实验,结果表明提出的jsp_webshell 检测模型性能得到了提升。后续工作是扩大训练数据的规模,并加入字节码的特征,使用深度学习算法改进模型的检测性能,并将该方法用于其他恶意代码的检测。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
华人时刊(2021年13期)2021-11-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
心声歌刊(2020年4期)2020-09-07
时代英语·高一(2019年1期)2019-03-13
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
时代英语·高三(2017年1期)2017-03-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
