
火电厂煤场作业人员的多模态检测方法
2020-12-23 12:59:44唐晓萌程豪豪岳益锋张剑华
天津理工大学学报 2020年6期
张 琨,金 坤,张 方,唐晓萌,程豪豪,岳益锋,张剑华
(1.华电电力科学研究院有限公司新技术研发中心,杭州310030;2.浙江工业大学 计算机科学与技术学院,杭州310023;3.福建华电可门发电有限公司,福州350512)
国内煤炭价格上涨以及煤炭供应紧张导致大多数燃煤发电企业无法燃用设计煤种,掺烧价格低廉的劣质煤是目前普遍采用的入炉方式.为满足火电厂配煤掺烧制度的要求,入厂煤种类复杂、来源广、煤质差,导致煤场日常储煤管理工作日趋复杂,混配煤不合理导致入炉煤质偏差,煤堆自燃发热导致燃煤热值损失,并伴随火灾及作业人员伤亡等高风险的安全隐患,对电厂运行安全及经济性带来了巨大挑战.
目前,煤堆温度监测仍然依靠传统人工手段,尤其是煤堆内部温度监测,需要燃管人员爬上煤堆将手持式测温热电偶插入煤堆内部,就地读取数据.此外,煤场大型堆取料设备的定期维护和消缺工作也需要作业人员频繁出入煤场.为了保障作业人员安全,通过图像识别技术对其进行精确检测显得尤为重要,便于随时掌握作业人员实时位置,预留安全距离并预知危险.现阶段基于传统可见光图像的人员检测方法主要有基于RGB颜色空间的运动目标检测[1]、以混合高斯背景建模为核心的基于视频的行人检测[2]和基于机器学习的人员检测[3]等.上述方法在封闭煤场光线差、粉尘大的恶劣环境下,难以有效提取RGB颜色空间或通过高斯分离前背景.由于深度学习在计算机视觉领域取得的惊人成绩,目标检测领域涌现了大量优秀的基于深度学习的算法.针对目标检测的算法主要分为两大类:一步(one stage)检测和两步(two stages)检测.一步检测代表为SSD[4]及YOLO[5],上述算法将卷积神经网络的输出直接进行分类和回归,从而得到检测结果.两步检测代表为Faster R-CNN[6],该算法首先生成预选框,然后将框体映射至特征图中,最后分类回归输出检测结果.以上算法均基于可见光图像进行目标检测,导致其无法直接应用于封闭煤场这种高粉尘、低光照环境.基于此,本文提出一种改进的基于YOLOv3[7]的封闭煤场作业人员检测算法,在双光(红外热成像及可见光)相机配合下,该算法将可见光与热成像图片有效融合并进行特征提取,分不同尺度进行一步分类和回归,最后生成检测结果.本算法具有速度快、检测精度高等特点,在封闭煤场恶劣环境下,依然能够取得较高的人员检测精度.
1 模型设计
本算法实现流程如图1所示,首先通过双光相机获取可见光图像(RGB Image)与热成像图像(Thermal Image),然后进行双光融合(Fusion),并将融合图像送入卷积神经网络(CNN)进行特征提取,接着将卷积结果与锚点框(Anchor Box)进行拟合(对数变换),最后生成预测结果(Result).

图1算法实现流程Fig.1 Algorithmic implementation flow
2 双光融合
传统可见光图像在电厂煤场恶劣作业环境下,无法有效提取图像信息.因此本文首次将双光融合方法应用于检测,将可见光图像与热成像图像进行有效融合,以此来丰富特征信息.融合方法分两步.
2.1 相机标定
相机标定有助于减少图像畸变引起对后续检测的影响.相机标定过程如图2,热成像和可见光镜头(左图为热成像,右图为可见光)分别计算角点.标定前后对比如图3,标定前有明显镜头畸变(左图),标定后畸变已消除(右图).

图2标定过程Fig.2 Calibration procedure

图3标定前后对比Fig.3 Comparison before and after calibration
2.2 双光融合
首先采用非下采样剪切波变换(NSST)方法对可见光图像和热成像图像进行分解,分别得到对应的基础部分(低频)和细节部分(高频)子带图像;从源图像中提取的基础部分包含共同特征和冗余信息,为了保留这些信息,本文采用加权平均的策略融合可见光与热成像的基础部分子带图像;对于细节部分子带图像,先使用深度学习网络来提取多层特征,即使用L1范数得到细节部分的多层特征候选者,对于这些候选者,使用最大选择策略来获得最终的融合细节部分子带图像;最后,将融合的基础部分子带图像与融合细节部分子带图像相加,得到最终的双光融合图像.融合过程如图4所示.

图4融合过程Fig.4 Fusion procedure
3 人员检测
人员检测方法基于YOLOv3算法.YOLOv3采用图片网格化检测,输入图像中包含真值(Ground Truth)中心的网格作为负责预测对象的单元格.YOLOv3选取3个特定尺度特征图(Feature Map)进行预测,特征图上的每个网格预测3个框,最后通过非极大值抑制(NMS)得到结果.
上述设计虽然能在一定程度上提升检测目标的能力,但仍然无法满足恶劣环境下的精确检测,因为包含更多细节的低层级特征未被有效提取.故本文采用改进的4尺度的特征预测,算法模型如图5,其中绿色部分为新增尺度.
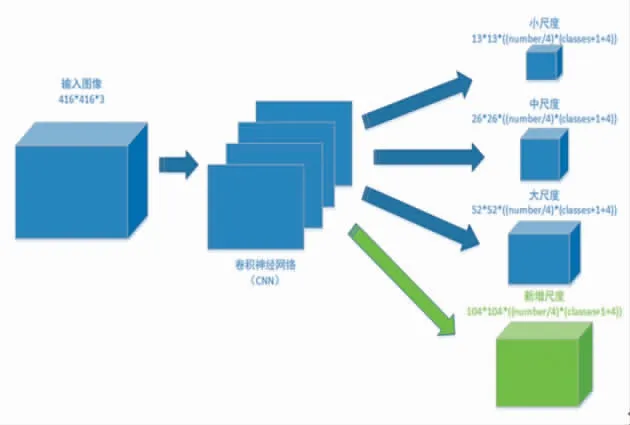
图5改进YOLOv3模型Fig.5 Improved YOLOv3 model
图5中预测层特征图的通道数计算方程为
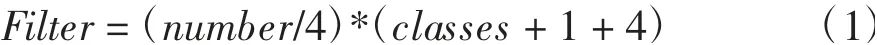
式中,Filter为通道数;number为锚点框数(YOLOv3设定9个锚点框,本文采用12个锚点框);第一个为检测尺度个数;classes为数据集分类数;1为一个置信度分数,第二个4为预测值的个数.
3.1 锚点框(Anchor Box)选取
如果直接通过卷积神经网络得到预测框坐标,会有低召回率(Recall)的问题(只有目标中心点网格负责预测该目标),也不利于模型收敛.为避免该问题,YOLOv3通过卷积神经网络来预测结果框相对于锚点框(Anchor Box)的偏移(tx,ty,tw,th),然后将该结果和锚点框作对数变换,得到最终的预测,原理如图6所示.
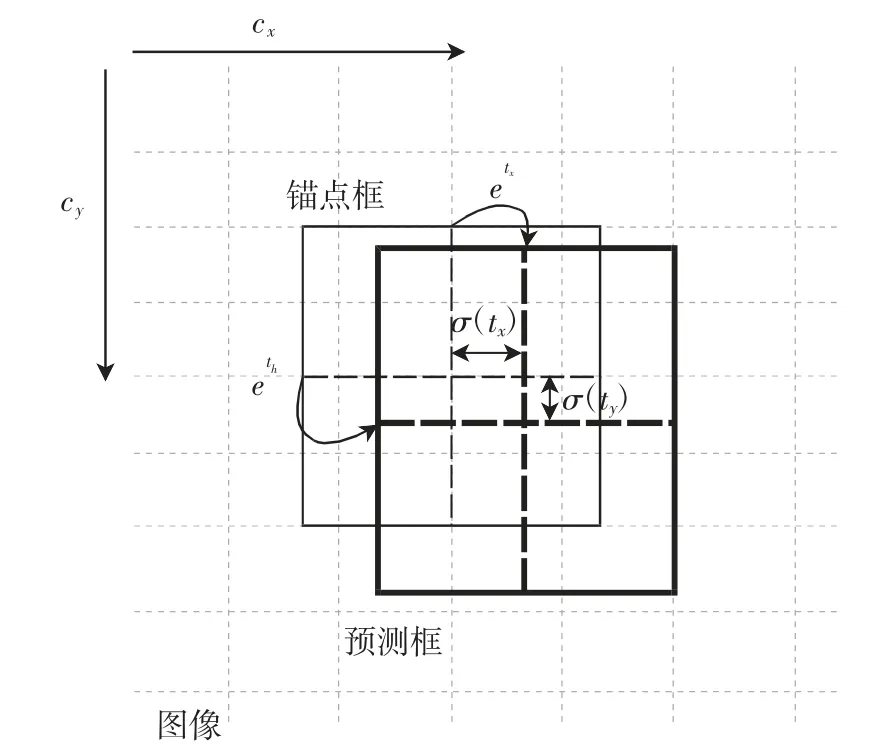
图6对数变换原理Fig.6 Logarithmic transformation principle
对数变换方程如下:


式中,bx为预测框的中心点x坐标;σ为sigmoid函数;tx为预测的中心点x坐标相对于该中心点所在网格左上角点x坐标的偏移;cx为预测的中心点所在网格的左上角点距原点的x距离;by为预测框的中心点y坐标;ty为预测的中心点y坐标相对于该中心点所在网格左上角点y坐标的偏移;cy为预测的中心点所在网格的左上角点距原点的y距离;bw为预测框的宽;pw为锚点框的宽;tw为预测的宽;bh为预测框的高;ph为锚点框的高;th为预测的高.
本文采用4个不同尺度进行预测,每个尺度对应3个锚点框.所有锚点框均采用K-MEANS算法对数据集进行计算并得出,本文制作的数据集采用的12个锚点框大小如表1所示.
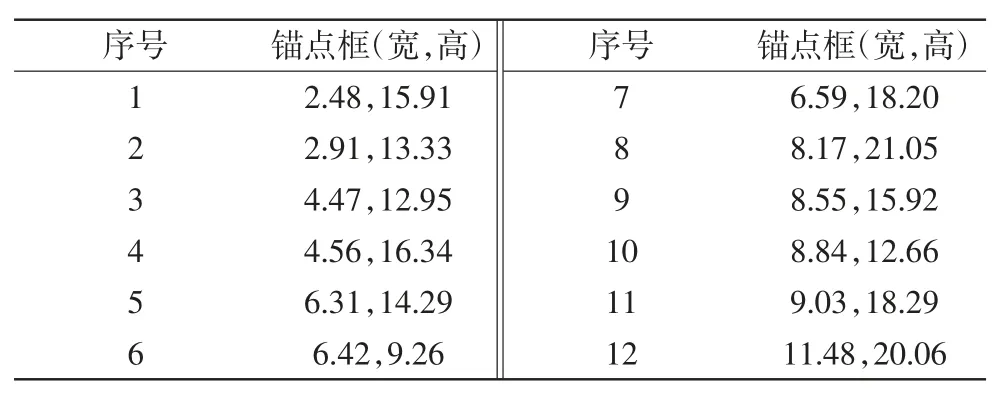
表1锚点框尺寸Tab.1 Size of anchor boxes
3.2 网络结构
改进后的YOLOv3整体网络包括骨干网络和预测网络2个部分,如图7所示(红色虚线框为改进部分),各层解析如表2所示.
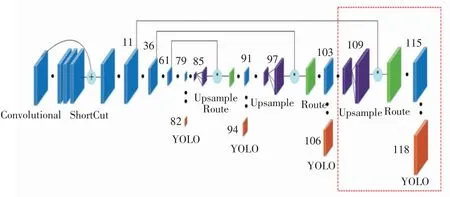
图7整体网络图Fig.7 Network structure

表2各层解析Tab.2 Explaination of layers
骨干网络网络结构本文不作改变,预测网络包含4个预测尺度:第一个预测尺度:骨干网络卷积后得到的13×13×18特征图;第二个预测尺度:首先将79层特征图卷积,接着上采样,然后与61层的特征图叠加(通道累加),最后卷积得到23×23×18特征图;第三个预测尺度:首先将91层特征图卷积,接着上采样,然后与36层的特征图叠加(通道累加),最后卷积得到52×52×18特征图;第四个预测尺度(新增):首先将103层特征图卷积,接着上采样,然后与11层的特征图叠加(通道累加),最后卷积得到104×104×18特征图.
预测网络详细参数如表3所示(红虚框区域为新增尺度).
3.3 损失函数
损失函数由回归损失、分类损失和置信度损失3个部分组成.
1)回归损失函数采用均方误差(MSELoss),方程为

式中,Lossx为预测框中心点x坐标偏移量的损失值;tx为预测的中心点x坐标相对于该中心点所在网格左上角点x坐标的偏移;gx为根据Ground Truth计算出的目标框中心点x坐标的偏移;Lossy为预测框中心点y坐标偏移量的损失值;ty为预测的中心点y坐标相对于该中心点所在网格左上角点y坐标的偏移;gy为根据Ground Truth计算出的目标框中心点y坐标的偏移;Lossw为预测框宽度的损失值;tw为预测的宽度;gw为根据Ground Truth进行对数变换后的宽度;Lossh为预测框高度的损失值;th为预测的高度;gh为根据Ground Truth进行对数变换后的高度.
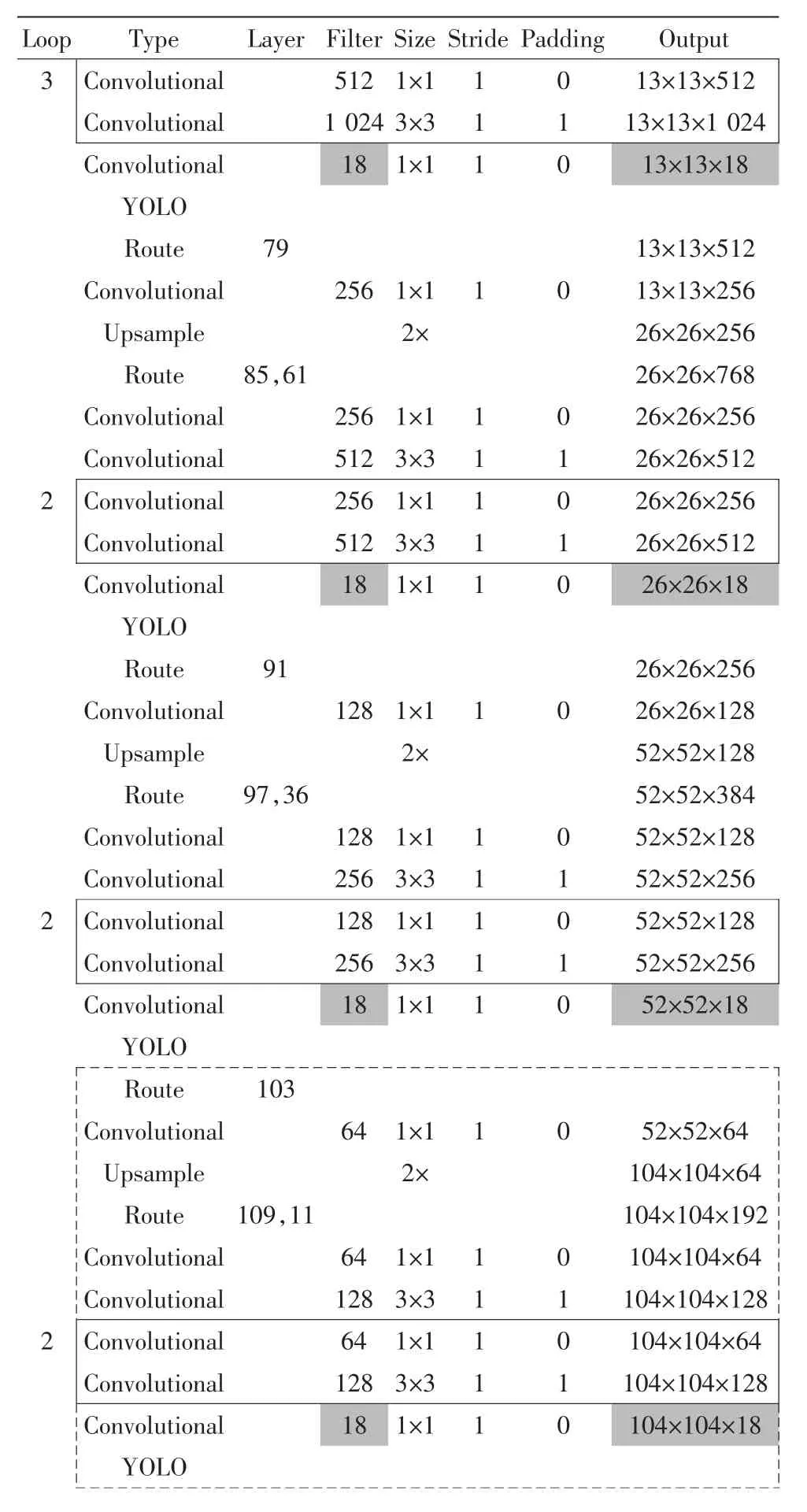
表3预测网络参数表Tab.3 Prediction network parameters
2)分类损失函数采用交叉熵(CrossEntropy-Loss),方程为

式中:x为Ground Truth,记做[N,C],其中N为x的总维度数,C为类别总数;class是预测出的分类的索引,j是x中的具体一个维度,j∈[1,N].
3)置信度损失函数采用带sigmoid的二分类交叉熵(BCEWithLogitsLoss),方程为
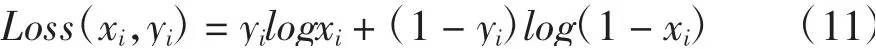
式中,xi表示第i个样本预测为正样本概率;yi表示第i个样本的分类.
最后的损失为三部分损失总和.
4 实验
4.1 数据集制作
本实验共计标注3 840张图像(1 920张可见光图像,1 920张热成像图像),融合后的1 536张图像设为训练集,384张可见光图像设为测试集,数据集样本如图8所示.

图8数据集样本Fig.8 Dataset samples
4.2 预训练
通过ImageNet的1 000分类数据集对骨干网络进行预训练,预训练损失及精度如图9所示.
4.3 训练
将预训练参数载入骨干网络,作为网络初始化权重.训练过程中,设置迭代次数30,批量大小8,采用Adabound[9]算法作为优化器.实验框架为PyTorch 1.0,显卡为Nvidia GeForce RTX 2080 Ti,训练损失及精度如图10所示.
4.4 评价指标
评价指标采用检测通用的AP(AveragePrecision),包含准确率(precision)和召回率(recall).准确率用于衡量一个结果的准确度,也称为PPV(positive pre dictive value);召回率用于衡量一个结果的完整性,也被称为TPR(true positive rate).
准确率方程为

式中,TP为正样本被预测为正例个数;FP为负样本被预测为正例个数.
召回率方程为

式中,TP为正样本被预测为正例个数;FN为正样本被预测为负例个数.

图9预训练损失(左)及精度(右)Fig.9 Pre-training loss and accuracy
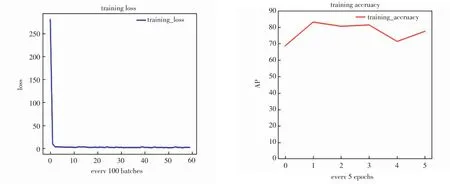
图10训练损失(左)及精度(右)Fig.10 Training loss and accuracy
Precision和Recall曲线面积即为AP值.
4.5 实验结果
图11结果表明,在封闭煤场低光照、高粉尘,高干扰的情况下,通过本检测算法可以实现人员(小目标)在煤场内移动场景下的自动捕捉,表明本模型能实现对煤场作业人员的精确检测.

图11实验结果Fig.11 Experimental result
将改进YOLOv3算法与原始YOLOv3算法进行精度对比,如图12所示.

图12精度对比结果Fig.12 Comparison result of accuracy
从图12可以看出,改进YOLOv3算法检测平均精度比原始YOLOv3提升22%,表明改进YOLOv3算法新增的尺度对本数据集小目标检测有较好的精度提升效果.
5 结论
为降低火电厂煤场存在的人员作业安全风险,本文提出一种基于双光相机的多模态检测方法.本方法创新地提出采用双光融合图像提取丰富特征信息,并通过增加YOLOv3预测尺度,解决低层细节缺失问题,在封闭煤场光线差、粉尘大和视角广的环境下,实现了煤场作业人员的高精度、实时检测.
猜你喜欢
通信电源技术(2021年2期)2021-05-21 02:33:46
电子技术与软件工程(2020年22期)2021-01-30 05:29:42
数字技术与应用(2020年12期)2021-01-22 13:40:40
电脑报(2020年12期)2020-06-30 19:56:42
移动通信(2020年5期)2020-06-08 15:39:51
电脑报(2019年4期)2019-09-10 07:22:44
电站辅机(2017年3期)2018-01-31 01:46:44
动漫星空(兴趣百科)(2017年3期)2017-11-07 01:15:00
电站辅机(2016年4期)2016-05-17 03:52:42
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
