
高性能CPU 核频率提升和功耗优化物理设计方法∗
2020-12-23 11:50何小威
计算机与数字工程 2020年11期
何小威
(国防科技大学计算机学院 长沙 410073)
1 引言
高性能CPU 核的物理实现一直是微处理器设计的难点,CPU核实现频率的高低直接影响到微处理器的性能好坏[1~2]。随着芯片工艺进入到超深亚微米阶段,工艺参数对器件延时的影响日益凸显,先进工艺下的金属线宽度降低到只有几十纳米,同时线电阻急剧增大,这给高性能CPU核的时序收敛带来不小的麻烦[3],必须从流程和设计方法学上进行改进[4],如何从物理设计方法学的角度实现将CPU 核的频率提升是一个值得研究的课题。近年来,为了提升高性能CPU核的频率涌现出不少新的实现技术,例如定制部分数据通道[2],网格(Mesh)时钟树或者混合时钟树[5]等,这些新技术难免有实现上的困难和局限性,很少有研究从布局布线流程和物理设计方法学本身的角度以最小的代价、最大限度地提升频率的同时保持实现面积和功耗可控。而且,高性能CPU核的随着频率的提升功耗问题变得愈发突出,近年来不少文献对物理设计的功耗优化进行了研究[6~7]。在不关断时钟的情况下,如何既保持性能又能最大化地降低功耗也是非常有挑战性的课题。对此,本文从物理设计流程的角度提出了提升频率或者降低功耗的物理设计方法。流程上,在布局阶段就进行时钟树预综合,在布线完之后进行电阻电容系数(RC Factor)校正,然后重新执行带时钟树预综合的布局-时钟树综合-布线。方法上,在布局布线过程(带时钟树预综合的布局、时钟树综合、布线)中均使用有用偏斜(Useful Skew)和 先 进 片 上 变 化(Advanced On-Chip-Variation,AOCV),并且全流程都不修复保持时间(hold)违例。实验结果显示,采用新的物理设计流程和方法可以实现CPU 核更高的频率或者更低的功耗,加快多模式多端角下的时序收敛速度,同时满足其他签核(Signoff)条件。
2 原有的设计
原有的设计模块采用先进工艺节点流片之后,经过测试模块的频率可达2.2GHz,模块布局分布如图1(a)所示,模块总单元数目为1.7M。而相同的面积下使用本文所提的物理设计方法经过频率提升之后的设计如图1(b)所示。可以看出,在module 的布局分布上二者基本一致,但是图1(b)的设计signoff频率却提升到2.4GHz。
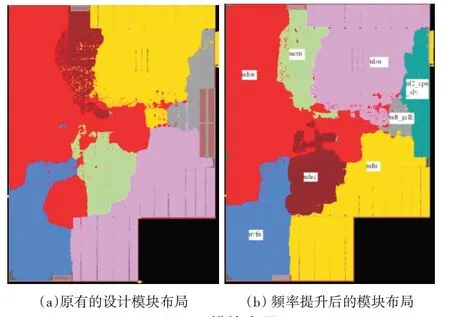
图1 模块布局
3 提升频率的物理设计方法
为了解决一般的布局布线流程和方法难以最大化提升CPU核的频率问题,本文基于业界主流的EDA 布局布线工具提出了一种适用于CPU 核频率提升的物理设计方法。主要包括以下内容。
1)采用Extreme 流程。对高性能CPU 核的设计来讲,一般的流程难以实现出极限性能。必须打开布局布线工具的Extreme 属性,能将核的时序优化到极致。
2)布局(Placement)阶段采取high effort 布局策略,让工具最大限度优化时序,这个和打开Extreme属性是同一个道理。
3)整个物理设计流程均使用Useful Skew。当前高性能CPU 核的设计由于要追求性能一般都会想方设法将时钟频率提升,如果物理实现还是采用传统的布局布线方法把时钟树做平衡,势必会限制频率的提升。随着EDA 工具的发展,使用Useful Skew 来提升频率的技术越来越成熟,主流的EDA工具都具备这种技术。CPU 核有些寄存器之间的逻辑非常多,路径延时较大,必须借助Useful Skew来满足高性能实现要求,即Placement/CTS/PostRoute全程使用Useful Skew。
4)EarlyClock流程助力频率提升。时钟树综合(CTS)作为物理设计中非常重要的一个步骤,通常在布局完成之后才开始进行。CPU 核的物理设计频率高、密度大,传统的物理设计流程在布局阶段并不考虑时钟树单元插入对布局位置和绕线资源的影响,因而布局阶段的时序结果和时钟树综合阶段的时序结果并不完全一致,很有可能在布局阶段发现时序已经收敛,但是等执行完时钟树综合之后发现时序恶化不少,因此EarlyClock 流程正好解决了布局和CTS之间的时序一致性问题,即在布局阶段就进行时钟树预综合,得到更加准确的时序信息。
5)整个物理设计阶段全程使用AOCV,避免时序过优化导致密度过大。早期工艺下物理设计都采用固定的值来反映片上工艺变化(On-Chip-Variation,OCV)对单元和线延时的影响。当前主流工艺已经进入纳米阶段,采用固定的片上变化值来约束时序进行布局布线会导致时序过度悲观,从而影响CPU核频率突破。
6)CTS 和Route 阶段都不修hold 违例,避免过修而导致密度过大。传统的布局布线流程除了集中修复建立时间(setup)违例之外,在执行完时钟树综合之后、或者布线时一般都会修复保持时间(hold)违例。先进工艺下hold 的不确定性随着单元阈值的变化而变化,一般布局布线工具所报出的hold 违例和时序签核工具报出的hold 违例存在不小的差异,因此在时钟树综合或布线阶段修复hold可能会导致过修、布局布线密度过大、功耗过大等一系列问题。
7)布线完成之后,提取绕线后金属线的RC 值并和绕线前的RC 值进行比较产生RC Factor,将RC Factor 反标到设计输入上,重新开始执行带时钟树预综合的布局、时钟树综合和布线,这样EDA工具在时序优化时更加精准,也就能达到频率提升的效果。RC factor的校正对16nm 及以下工艺的时序收敛非常有帮助。
8)细分更多的Path Group。将影响频率提升的关键路径提炼出来形成多个PathGroup,设置适当的权重,这样布局布线工具能加大优化这些关键路径的力度,这对提升频率非常有帮助。
将上述方法融合到传统的物理设计流程中,我们可以得到如图2 所示的提升频率的优化设计流程。这些物理设计方法可将原来的设计模块在实现面积不变的情况下频率提升10%。

图2 CPU核频率提升的物理设计流程和方法
4 降低功耗的物理设计方法
对于多核微处理器来讲,CPU核的功耗大小直接关系到整个微处理器的功耗大小。维持CPU 核的频率不变,最大化地降低CPU核的功耗是非常值得研究的方向。如上节所述,原来设计模块CPU核的频率可再提高10%,这说明原来的设计中时序是有余量的,挖掘这些余量从而降低核的功耗是切实可行的。我们从以下几个方面对原来设计的CPU核的功耗进行了优化改进。
1)开启功耗优化选项(动态功耗+静态功耗)。原有的设计为了追求CPU核的频率,在物理实现流程中并没有打开功耗优化选项,由于时序有余量,有些时序路径并不需要工具费多大精力就可以满足时序要求,所以打开功耗优化选项能够让工具从布局布线一开始就兼顾频率达标和功耗优化,能够更好地降低动态功耗和静态功耗。
2)在整个布局布线阶段全程使用AOCV,避免时序过优化导致密度过大。如果还是采用固定的OCV值来约束必然导致大部分时序路径过度约束,工具会插入更多的单元来修复时序,这必然不利于整体功耗的优化。
3)在整个布局布线阶段全程使用Useful Skew。如上节所述,为追求高性能CPU 核的频率提升,我们在整个布局布线阶段均使用Useful Skew。为了降低功耗,我们同样在整个布局布线阶段全程使用Useful Skew,目的是通过借Useful Skew来尽快达成时序收敛从而不插入过多的逻辑单元。插入的单元数目减少了,功耗相应地就降低了。由于Useful Skew 并不会对所有的时序路径起作用,所以由Useful Skew所引起的hold违例并不会比不使用Useful Skew 的多太多,可通过插入功耗较低的延时单元来修复。
4)在布局布线工具中不修复hold 违例。如上节所述,传统的布局布线流程除了集中修复建立时间(setup)违例之外,在执行完时钟树综合之后、或者布线时一般都会修复保持时间(hold)违例。先进工艺下hold 的不确定性随着单元阈值的变化而变化,一般的布局布线工具所报的hold违例和时序签核工具报出的hold违例存在不小的差异,因此在时钟树综合或布线阶段修复hold可能会导致过修、布局布线密度过大、功耗过大等一系列问题。我们的功耗流程在整个布局布线阶段都不修复hold 违例,只是将局部密度控制适当,待签核工具报出hold违例之后再通过时序收敛工具一次性修复,这样不会出现过修而插入过多的单元,相应地就达到了降低功耗的目的。
根据同样条件生成的VCD 文件,原来设计核的功耗为1.061W@dhrystone64 VCD,如图3(a)所示。采用上述功耗优化方法之后,核的功耗降低为0.855W@dhrystone64 VCD,如图3(b)所示。可以看出,无论是漏流功耗(leakage power),还是开关功耗(switching power)和内部功耗(internal power)都有了明显的降低,其中漏流功耗几乎降低了一半。

图3 CPU核的功耗
5 结语
本文针对高性能CPU 核的物理设计提出了一种提升频率或者降低功耗的物理设计方法,能最大化地提升CPU核的实现频率,或者在保持频率不变的前提下最大化地降低CPU核的功耗,同时保持实现面积不变。该方法易于集成到传统的物理设计流程中,可操作性强,具有较强的工程实践意义。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2022年7期)2022-08-06
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
家庭影院技术(2020年2期)2020-03-25
环球市场信息导报(2018年21期)2018-07-27
科技创新导报(2016年28期)2017-03-14
个人电脑(2016年12期)2017-02-13
微型计算机(2009年12期)2009-12-21
