
基于LSTM 的交互式神经机器翻译方法研究
2020-12-22 10:36田红楠
机电产品开发与创新 2020年6期
田红楠, 郭 欣, 袁 伟
(1.河北工业大学 人工智能与数据科学学院, 天津300130; 2.国家康复辅具研究中心秦皇岛研究院, 河北 秦皇岛 066000)
0 引言
在过去的几年里,机器翻译领域取得了很大的进展,这主要归功于基于双语语料的机器翻译的进步。现在,机器翻译系统是许多用户和公司有用的工具, 自动提供质量可接受的翻译结果[1]。 系统仍然会产生错误的翻译,这是一些特定领域翻译是不允许的。例如,医疗记录的翻译必须准确无误。 此外,翻译问题有许多微妙之处,使得机器难以处理:话语充分性、照应清晰度、特定领域的意义、文体形式等等。
在需要高质量翻译的场景中, 系统的输出通常由翻译人员检查,由翻译人员纠正机器翻译系统所犯的错误,这就是所谓的译后编辑模式。在这样的背景下,研究人员开始将目光转换到交互式翻译系统上,一方面,不同于普通的译后编辑模式,在交互式机器翻译系统中,翻译人员在翻译过程中与系统不断交互直到生成译员满意的结果[2]。另一方面,通过交互的过程,机器翻译系统可以自适应修改参数,提高模型的翻译效果。
1 神经机器翻译
统计机器翻译的原理是找出给定语言s,求解在给定源语言的情况下,目标语言t 的概率最大的值p(t|s)。通过大规模双语平行语料学习,生成模型参数,当输入源语言时,通过优化条件概率的最优结果,生成译文[3]:

神经网络方法在计算机视觉和自动语音识别方面取得了成功,在机器翻译中得到了应用。 与统计机器翻译的离散表示方法不同, 神经机器翻译采用连续空间表示方法表示词语和句子。直接从源语言映射到目标语言。大多数NMT 系统依赖RNN 编解码框架:在编码过程中,源语句被映射成分布式表示,模型如图1 所示。
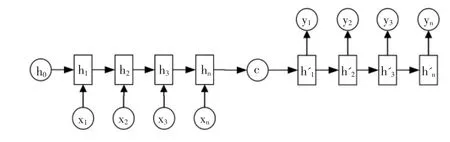
图1 编码器-解码器模型
1.1 循环神经网络(RNN)
传统的神经网络里,相互的输入没有关联,例如输入为X=(x1,x2,…,xn),其中x 之间相互不影响,无论以何种方式进行输入,都不会对最终的结果产生影响。但是对于机器翻译来说,翻译一句话必须要考虑词之间的联系,从整体进行把握。 RNN 是处理序列数据的神经网络, 每进行一次计算的时候, 都会考虑前一刻的所包含的信息内容,其展开网络结构如图2 所示。
其中当前时间为t,输入为xt,当输入xt和ht-1进行变换后得到ht, 在经过处理得到输出Ot,同时将ht作为下一次的输入,进行计算,这里的三个权重矩阵U、V、W 在每一个时间步的计算中都是完全相同的:

通过公式我们可以发现,RNN 中的输出Ot, 是之前每一时间步影响的累加,通过将前一时刻的时间步ht-1作为输入来进行记忆。

图2 RNN 展开图
1.2 长短时记忆网络(LSTM)
循环神经网络在实际操作中却有一个很大的问题:当模型需要处理的任务比较简单时,环神经网络就可以很好的利用到以前记忆的信息学习;当模型需要处理的任务比较复杂时, 循环神经网络就很难利用之前记忆的信息,这时翻译任务的效果就会比较差甚至会导致翻译失败。
由公式(4)可知,在训练RNN 的时候,损失函数的公式为(5),由此可知,损失函数为每一时刻损失值的累加,在进行反向传播的时候会出现梯度爆炸和梯度消失的情况,很难对RNN 进行训练。

为了解决RNN 很难进行训练的问题, 由Hochreiter和Schmihuber 于1997 年提出LSTM[4]。 将其引入标准RNN中解决梯度爆炸和梯度消失的问题, 在机器翻译任务上取得了较好的表现。
如图3 所示为LSTM 网络内部结构图,LSTM 与RNN具有相同的连接结构, 标准RNN 隐藏层中有一个网络层,但是LSTM 在隐藏单元中使用三个门来控制信息。 每一个LSTM 中有三个输入:当前输入xt,上一步的细胞状态Ct-1,上一步隐藏层状态ht-1。 σ 是激活函数sigmoid。
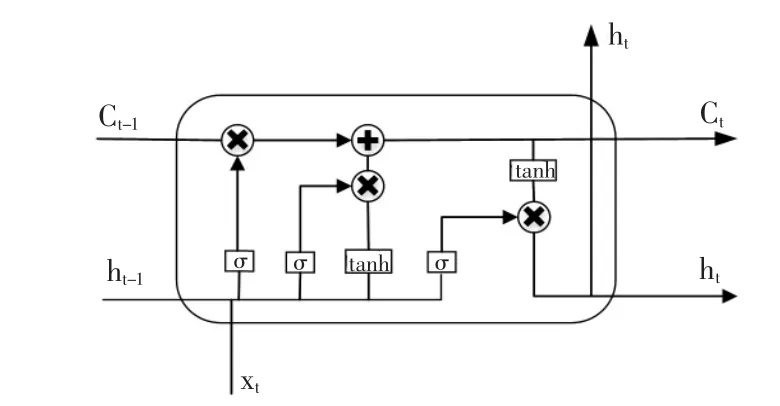
图3 LSTM 内部结构图
(1)遗忘门:决定会从细胞状态中丢弃什么信息,见图4。


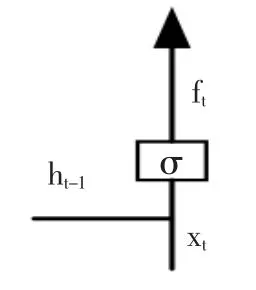
图4 遗忘门

图5 输入门

图6 输出门
根据ht-1和xt判断储存信息与当前输入的关联,决定输出哪些信息。 首先用sigmoid 来确定细胞状态的哪个部分将输出去。然后将状态Ct通过tanh 处理,得到一个在-1 到1 之间的值,然后和sigmoid 输出相乘,最终会输出我们确定输出的那部分。

LSTM 能够解决传统标准RNN 中训练时的梯度爆炸和梯度消失问题,并且在翻译任务上表现不错。
2 交互式神经机器翻译
交互式机器翻译作为经典的后编辑模式阶段的一种替代,在交互式机器翻译系统中,人类以一种解耦的方式纠正交互式翻译系统的输出。 在交互模式下,后编辑阶段变成了一个迭代的人机协作过程:每次用户做出修改,系统就会根据用户的反馈生成新的翻译。 交互式翻译系统将翻译引擎的效率与翻译人员的知识相结合[5]。
如图7 所示,在交互式机器翻译的总体框架中,将源句输入系统,输出翻译结果。 接下来,翻译人员修订译文并提供反馈信号。 交互式翻译系统输出一个新的翻译结果,考虑到用户的反馈。预计这个新的翻译结果比之前的翻译结果更好,因为系统有更多的信息。 然后,一个新的迭代开始。 这个迭代过程一直持续到用户接受交互式翻译系统输出的译文。

图7 交互式翻译总体过程

在标准的解码翻译过程中, 常常用束搜索(beam search)来提提高译文质量。 我们将讨论在交互式机器翻译中束搜索和贪婪搜索的区别:
(1)贪婪搜索:在贪婪搜索算法中,在翻译每个字的时候, 直接选取当前概率最大的候选项作为当前的最优值。在贪婪搜索算法中,从局部最优解出发不一定能产生全局最优解。
(2)束搜索:束搜索算法是对贪婪搜索算法的一个改进,将贪婪算法的搜索空间扩大。束搜索方法对所提供的前缀译文进行强制解码,然后对翻译器进行波束搜索,以选择最优的翻译。相对于标准翻译的束搜索,在神经交互翻译中,波束搜索将使用相同的前缀翻译。
众所周知,束搜索比模型能产生更好的翻译质量,如果没有束搜索,计算成本会更高。
2.2 融合先验知识的交互式机器翻译
在神经机器翻译中, 译员翻译后的标准翻译内容是宝贵的资料, 在交互式翻译框架中融合译员的先验知识对于提升交互式机器翻译效果具有重大意义。 从这个意义上说,以前修改过的句子对以后的翻译有很大的帮助。使用在线学习方法在同一个会话中从之前更正过的句子中学习[6]。
在线学习模式下,数据是按顺序提供的,模型是递增更新的。 典型的交互式翻译场景与这些阶段相适应:
(1)一个新的源句t 进入交互式翻译系统。
(2)交互式翻译系统生成一个译文yt。
(3)译员修订译文,纠正系统所犯的错误,以交互的方式翻译源句,生成一个正确的翻译。
(4)系统使用修正后的样本来调整其模型,提高模型的准确率。
如果训练语料库足够大, 机器翻译就会有很好的效果[7]。但是获得大量的平行语料库是一个困难的。此外,对于特定领域的翻译,我们需要该领域的数据,但是获取特定领域的数据也是很困难的。 一种常见的方法是在一个大型通用语料库上训练一个模型, 然后使用特定领域内的数据对其进行微调。 但是有时候这种方法可能是无用的,例如还不知道应用到哪些领域的情况下。 因此,在机器翻译系统上应用在线学习功能对于特定领域翻译具有特殊意义。
神经网络最常见的训练方法是SGD, 可以直接应用于在线学习。 机器翻译系统的在线适应可以使用MBGD优化器来进行在线学习。
对于一个训练样本, SGD 根据目标函数相对于权值θt的梯度方向更新参数:

式中:▽1θt是1 相对于θt的梯度,并且ρ 是控制步长的学习速率。
这个更新规则依赖于对ρ 的仔细选择。因此,所说的自适应SGD 算法试图通过动态计算学习率来克服这种依赖性。
本文在在线学习中采用MBGD 优化算法, 在修订后的历史译文积累到一定量的时候,进行模型参数优化,做增量训练。MBGD 每一次利用一小批样本,即n 个样本进行计算,和SGD 的区别是每一次循环不是作用于每个样本,而是具有n 个样本的批次。
3 实验分析
3.1 实验数据及处理
在数据集上选取UNv1.0 中英双语平行语料集,该平行语料库由六个联合国手册手工翻译而成, 选取其中大约10000 句作为测试集,10000 句作为验证集,500 万句作为训练集。由于其中的语料是双语的平行语料,需要对齐进行标准化处理。
对中文语料需要对其进行分词处理, 本文采用jieba分词工具对中文语料进行分词处理。 由于英文本身就是按照单词进行分隔的,所以不需要进行分词。但是需要将标点符号用空格进行分隔。 将中文和英文的词表规模分别设置为3 万。
3.2 实验设置
实验环境如表1 所示,实验采用openNMT 开源机器翻译框架,采用pytorch深度学习框架搭配GPU 进行实验环境搭建和计算。在实验模型中,采用seq2seq(序列到序列) 作为基础架构,其中的编码器和解码器军采用LSTM。
在线学习部分采用MBGD 算法, 当译员修订了一批语料之后,采用这一批样本进行参数更新。译员每次修改的历史句子都会被存在MYSQL 数据库中,当检测到积累的句子达到100 句的时候进行增量训练, 并且把这一批句子进行标注,防止下次再次运用进行训练。
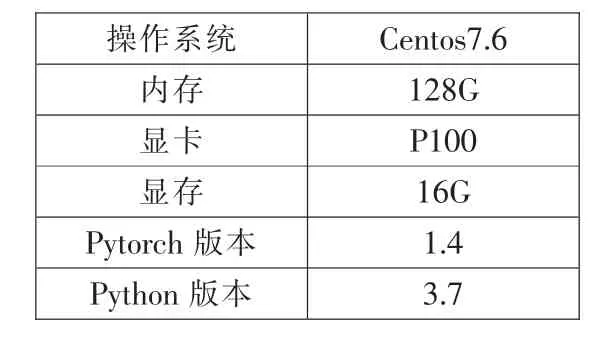
表1 实验环境
3.3 实验结果

表2 模型效果测试
在交互式翻译中, 经过译员修改后的内容在和系统交互之后, 翻译的质量有明显的提升, 在进行两轮修改之后, 翻译质量已经达到了很好的效果,见表2。
4 结束语
在交互式机器翻译的过程中, 通过译员修改过的错误, 在放进交互式翻译系统进行重新解码后可以提高翻译的质量。 通过对翻译人员修订过的内容对模型进行增量训练,可以提高模型的效果,可以有效利用翻译人员的先验知识,更好的时间人机协同。在交互式机器翻译领域还有很有的领域需要研究, 利用记忆库和交互式翻译进行协作,实现翻译人员、先验知识、神经网络三方面进行协同。
猜你喜欢
数学物理学报(2022年1期)2022-03-16
通信技术(2021年12期)2022-01-25
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
开封文化艺术职业学院学报(2020年9期)2020-01-10
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
英语学习(2017年3期)2017-04-10
英语学习(2016年12期)2017-02-28
天中学刊(2015年4期)2015-08-15
民族古籍研究(2014年0期)2014-10-27
