
基于Spark平台的电子商务实时推荐系统建设和应用
2020-12-21 12:26蒋丛萃陈巧灵
电子商务 2020年11期
关键词:电子商务
蒋丛萃 陈巧灵
摘要:随着大数据时代的到来,大数据机器学习已然成为当前研究的一项热点。但是现如今的电商推荐系统存在着不同程度上的计算缓慢,无法根据根据用户的实际需求进行实时推荐。在这一背景下,本研究基于Spark平台建设和实现电子商务实时推荐系统。相较于传统的推荐系统,本研究的系统通过以Spark平台为基础,构建了分布式日志采集和传输模块,希望通过该系统来解决电子商务跨系统数据源的收集问题。其次,基于Spark平台的矩阵分解推荐模型进行离线训练,以此来提高离线训练的效率。最后,对电子商务网站的实时推荐系统进行试验。
关键词:Spark平台;实时推荐系统;电子商务
★基金项目:2020年度广西高校中青年教师基础能力提升项目“基于大数据技术的快递与电子商务产业联动模型构建”阶段性成果(2020KY47014);2017年度广西高校中青年教师基礎能力提升项目“‘一带一路战略背景下广西商务服务业创新创业的路径研究”阶段性成果(2017KY1267)。
近几年以来,随着电子商务的发展,大数据成为了各个电商平台发展的重点。电子商务平台上所拥有的大量商品种类和大概的商品分类导致用户在选择商品时无法实现高效快速,所以,如何使用户可以更加高效的选择所需商品已经成为当前电子商务平台的研究重点。在这一背景下,电子商务推荐系统出现在人们的视线中,该系统可以根据用户以往的搜寻记录准确的推荐商品,提高了电商的商品转化率。虽然传统平台的推荐系统已经可以处理绝大部分的问题,但是其问题在于离线训练速度慢。而在Spark平台的基础上进行研究,其计算能力更为强大,可以更加快速的处理并行数据。
1、基于Spark平台的系统架构
1.1 系统架构
1.1.1 设计理念
电商平台中含有大量的用户隐式行为,并且因为电商系统规模的扩大化,导致系统的日志文件四处分散。而传统的推荐系统无法对于用户隐式行为日志进行汇总,更别提进行分析,所以无法实现实时推荐的目的[1]。本文设计理念是采用用户隐式行为进行用户评分的构建,并基于隐式数据源,将传统平台上的推荐系统转移到Spark平台,通过结合用户实时点击流,对于用户行为进行分析,将适合用户的实时反馈到推荐列表。
在上图中,基于Spark平台的电子商务实时推荐系统可以分为三层,第一层为离线处理层,第二层为服务层,第三层则是实时处理层。在服务层中,系统会将请求下发,而采用网关集群前,利用HTTP服务器负载均衡之后,构建分布式日志框架,并将分布式日志采集Agentility安装到网关服务器上,以此来对于各业务系统的日志信息进行采集、访问。因为电子商务平台的日志具有海量的产出,所以必须要有可靠地信息传送出中间件,将其作为模型训练和数据源采集之间的桥梁,实现日志数据的统一下发。因为日志数据中不仅含有众多业务系统日志,还具有用户点击流日志,所以在进行实时推荐的过程中,需实施统一的数据清洗。本系统基于Spark平台中的相关技术来对于日志进行处理,对于在固定时间间隔所收集到的数据,Spark Streaming技术能够根据时间分片进行处理,以此来实现实时处理的目的[2]。
其次,在离线处理层中,对于数据源中的用户行为分级权重,该方式可以获得用户对商品的基本评价。传统方案是通过利用离线推荐模型训练,但是其问题在于:抽象层次低,需要编写冗余代码;传统平台仅仅能够提供两个操作,分别为Map、 Reduce,所以在表达能力方面十分缺乏。而本研究则是通过利用Spark平台进行抽象,所得到的数据逻辑要更加的间断,并且还可以提供多种操作和转换,表达力相对较强。除此之外,Spark平台相较于传统平台,其中间计算结果能够缓存到内存中,从而提高计算效率。
离线处理层中,系统需及时处理用户行为,同时还需要与离线推荐结果相结合,从而提高电商的实时推荐效果。由于传统平台只适合应用在批处理的场景中,基于Spark平台针对用户访问,可以实时过滤针日志信息,并在过滤过程中收集所需信息。另外,通过采取混合处理的方式,对于该商品类似的商品列表可以进行重新排序,可以使电子商务平台得到用户最新行为,从而提高电子商务平台的转化率。
基于Spark平台的实时推荐系统相较于传统的离线推荐系统,能够得到更快的训练速度以及反馈速度[3]。
1.1.2 实时推荐系统环节
在Spark Streaming端获得数据之后,系统通过数据聚合、传输以及过滤等环节,实现离线和实时推荐,最终返回到推荐列表中,而该推荐列表中融合了离线推荐和实时推荐结果。
首先,计算隐式评分。电子商务平台根据配置规则来分发用户请求,但是需要分发给多台应用网关,并通过应用网关来调用各业务系统的请求。在应用网关中植入分布式日志采集工具,然后收集日志信息,将信息进行汇集发送到消息及群众。而集群可以接入Spark Streaming,并进行日志过滤,在过滤期间同样可以得到用户的商品浏览和交易行为的数据,然后利用Shark来对于商品评分计算。
其次,离线推荐模型训练。对于隐式评分计算结束后,能够得到用户ID、商品ID以及评分。而这些信息同样也是离线推荐模型的数据源,因为在同一个电商平台上,用户的购买数据总量较低,所以采用交替最小二成算法来计算隐式因子,经过训练后能够得出离线推荐模型。
再次,生成离线推荐列表。在模型中依次放入电子商务平台中的用户,该步骤可以得到注册用户的离线推荐列表。为了可以有效的降低数据库访问压力,可以将全部的推荐列表转移到缓存系统[4]。
最后,形成实时推荐列表。通过Spark平台,将日志信息进行过滤,得到日志点击流,从其中抽取商品ID和用户ID。已经训练好的离线推荐模型来对于商品根据相似程度进行排序,经过排序后能够得到商品中排名靠前的商品。根据推荐列表来进行列表的构建工作,对于系统的实时响应速度加以优化,推荐列表为用户id和商品ID。
1.2 系统的架构设计
1.2.1 实时采集分布式日志
如下图二所示为分布式日志采集模块。电子商务平台中的实时推荐系统中必须要具有大量隐式的用户行为,而其主要是基础数据。因为源日志信息会在众多系统中分布,因此需要构建分布式系统,基于这一方式来进行日志的收集工作。通过利用分布式日志收集工具Logstash来收集各业务子系统的日志[5]。
在下图二中,系统置入应用在日志监控方面能够对于日志文件发生的变化情况进行实时监测,同时还可以根据偏移量来读取最新的日志信息,最后将日志进行缓存。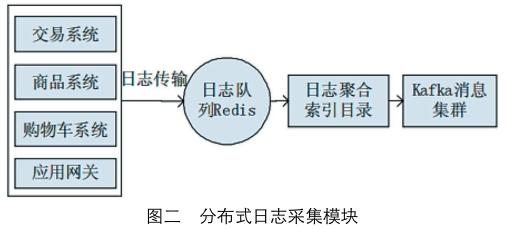
1.2.2 基于Kafka集群的数据传输
实时采集模块可以采集用户行为日志,但是日志在进行过滤前,因为日志流的数量非常大,所以饮食用户行为日志数据的收集过程中,如何保障数据的实时性、避免数据丢失问题等,成为了关键问题。而Kafka是一种分布式消息订阅和发布的系统,基于电子商务平台实时推荐系统,为了可以承载大量的用户行为日志信息,所以选择构建Kafka集群,为日志过滤提供了可靠的传输[6]。
而Kafka集群的组成可以分为三个部分。分别是生产者、消费者以及代理。其中,生产者意味着日志来源;消费者代表消费的使用者;而代理则表示消息的中间存储层。其中,生产者回收集消息,并推送到代理中,而带列在接收消息之后会对消息进行本地持久化,消费者才是消息最终的使用人员。Logstash日志监控将会把处理好的日志传送给Logstash日志聚合索引,最终根据实时推荐需求采取不同的过滤处理措施。
1.2.3 基于Spark Streaming的日志过滤
在进行数据传输后,系统可以通过Spark Streaming来统一过滤日志,从而具有实时推荐的日志过滤模块。Spark Streaming能够接收到的日志信息中的噪声数据非常多,所以要在其中选择有效的信息。如下表一所示为Logstash的格式化日志。在实时推荐流程中,在点击流日志数据选择商品以及用户的ID。利用电机商品调用的接口获取商品详情信息,并在代理层拉取日志信息,此时将会把用户请求调用的接口记录下来[7]。
因为该表一中仅仅只是Logstash所提供的前端,所以仍旧需要调用Spark Streaming对接收的日志调用filter函数,过滤出其中所含有的商品详情方法的日志,从而得到请求日志,并在消息中对于变量字段相对应的内容展开解析工作,这一步骤能够获得商品id,从而得到关键信息,为电子商务平台的实时推荐提供了数据源。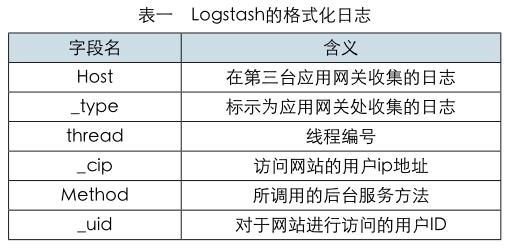
2、实验分析
因为Spark平台在對于人物进行处理时具有着良好的效果,本文基于Spark平台构建电子商务平台的实时推荐系统。为了对于Spark平台和传统平台在对于任务处理计算过程中的性能差异,本次对于两种平台在作业执行方面的性能上进行对比。
其中,Spark平台在计算不同作业类型时,性能平均的提升速度为4倍。ALS模型训练时,由于需进行多次迭代计算,所以,性能提升的效果十分明显。这意味着Spark平台的优越性[8]。这意味着基于Spark平台的电子商务网站的实时推荐系统可以承载日志信息,并且还可以根据用户行为进行及时推荐,有效的促进网站的销售提升,并且还提高了用户的购物体验。
3、结语
当前,几乎所有的电商网站都在应用推荐系统,该系统可以针对用户的需求进行反馈,从而提高电子商务平台的服务水平。本研究基于Spark平台对于电商网站的实时推荐系统进行了设计,提出来实时推荐的相关流程,并且设计了分布式日志采集、传输模块。通过利用Spark平台来设计实时推荐系统,Spark平台在粗粒大数据上具有非常高的运算性能,所以具备一定程度上的可行性,并且相较于传统的平台其运行速度明显更高,所以在电子商务网站中的实时推荐系统的设计中,Spark平台的使用价值非常高。
参考文献
[1] 岑凯伦,于红岩,杨腾霄.大数据下基于Spark的电商实时推荐系统的设计与实现[J].现代计算机,2016,(24):61-69.
[2] 刘志强,顾荣,袁春风,等.基于 SparkR 的分类算法并行化研究[J]. 计算机科学与探索,2015,9(11):1281-1294.
[3] 童启,刘强,许赛华, 等.基于相关物品的电子商务智能推荐系统研究[J].企业科技与发展,2019,(12):79-80.
[4] 张光.基于离群数据挖掘的电子商务推荐系统研究[J].自动化与仪器仪表,2017,(8):21-22,25.
[5] 曾贤灏,赵锡英.基于关联规则和 ART 的电子商务推荐系 统应用研究[J].自动化与仪器仪表,2016,(12):109-111.
[6] 程芳.农业电子商务中基于用户兴趣变化的协同过滤推荐技术研究[J].农业网络信息,2016,(5):41-44,47.
[7] 陈虹君.基于Hadoop平台的Spark框架研究[J].电脑知识 与技术,2014(12X):8407-8408.
[8] 胡德敏,龚燕.基于Spark的混合推荐算法研究[J].计算机应用研究,2017,34(12):3585-3588.
作者简介:
蒋丛萃,硕士,柳州城市职业学院讲师,研究方向:电子商务、软件开发。
陈巧灵,硕士,柳州城市职业学院讲师,研究方向:物流管理。
猜你喜欢
计算机应用文摘·触控(2022年8期)2022-05-25
智富时代(2019年3期)2019-04-30
智富时代(2019年3期)2019-04-30
新农业(2017年3期)2017-05-17
时代金融(2017年1期)2017-02-13
科技与企业(2015年18期)2015-10-21
信息化建设(2014年11期)2014-12-30
共产党员·上(2014年5期)2014-05-27
决策与信息·下旬刊(2013年1期)2013-03-11
中国计算机报(2005年60期)2005-09-22
