
基于YOLOv3-tiny的船舶可见光图像细粒度检测*
2020-12-17 02:34梁月翔徐海祥
武汉理工大学学报(交通科学与工程版) 2020年6期
梁月翔 冯 辉 徐海祥
(高性能船舶技术教育部重点实验室1) 武汉 430074) (武汉理工大学交通学院2) 武汉 430063)
0 引 言
智能感知作为智能船舶的关键组成部分,为船舶的自主航行、避障和搜救提供重要的感知信息.由船载摄像头所采集的可见光图像进行目标识别与检测,可以检测出水面船舶的类别及位置等信息,从而为船舶的自主航行提供决策.
水面目标检测领域早期采用传统的图像处理方法来进行目标识别与检测.Jangal等[1]将小波分析应用于提高高频表面波雷达海洋遥感中的遥感参数和水面目标检测.刘宗昂等[2]利用目标梯度变化以及目标边缘灰度变化均方值,验证了对水面目标边缘的有效检测.Paes等[3]利用小波和决策树相结合的方法从SAR图像中检测舰船和其他海上监视目标.曾文静[4]基于对水面目标可见光图像的处理,得出水面有效信息(水线面等)和水面目标及障碍物的位置信息.张伊辉[5]对水面无人艇视觉系统采集到的视频进行预处理、目标图像分割、分割出的目标进行特征分析与提取、目标识别.传统的方法适用于特定的识别任务,泛化能力较差.近年来随着深度卷积神经网络的兴起,水面目标检测领域逐渐开始应用这种具有兼顾灵活性和泛化性的方法.李畅[6]将R-CNN(regions with CNN features)应用到水面目标的检测上,实现了检测军舰、邮轮、帆船和浮标等.王贵槐等[7]采集内河船舶图片数据库建立船只单次多重检测(single shot multibox detector,SSD)深度学习框架,通过使用预训练模型参数调优并微调分类框架实现较高的内河船舶检测准确度.Redmond等[8]提出的YOLO(You only look once)算法,到目前已历经三个版本的迭代.YOLO算法的特点是能保证图像目标识别精度的同时,加快检测效率.YOLOv3算法在目标检测与识别方面取得的成果斐然,但是网络结构的复杂化也导致算法计算时间复杂度较高[9].本文采用轻量化的骨干网络的YOLOv3-tiny算法进行船舶可见光图像的目标识别与检测,并在此基础上对算法进行改进以提高算法的识别精度和实时性,可以辅助船舶驾驶人员对水面目标进行识别,提高船舶航行的安全性.
1 YOLO算法
1.1 概述
YOLO目标检测算法是单阶段(one-stage)神经网络模型的经典算法,虽然在精度上略逊色于两阶段(two-stage)模型,但是其快速性是YOLO最显著的特点.近年来YOLO在吸取SSD[10]以及Fast RCNN[11-12]等算法的基础上,经过三个版本的更新换代,最新的YOLOv3在精确度和实时性上有显著提高.
1.2 基本思想
不同于两阶段模型采用区域建议与分类器结合的思想,YOLO算法运用回归的方法一次性得出目标物体的边界框、置信度和类别概率.YOLO算法的检测流程如图1所示.首先将输入图像划分为S×S的网格,然后在每个单元网格中定义B个边界框,每个边界框有一个置信度评分.所谓置信度评分是指每个边界框中包含物体的概率,为
(1)
式中:confidence为置信度评分;Pr(Object)为预测目标概率;pred为预测边界框面积;truth为实际边界框面积;IOU为它们的交集与并集的比值.
在最后对检测结果预测时,每一个种类的置信度分数由以上条件类别概率和目标置信度的乘积得到,为
classConfidence=Pr(classi|Object)×confidence
(2)
经过图1运算将得到一系列高维向量,设置一个阈值去除可能性比较低的目标窗口,最后利用非最大值抑制(non-maximum suppression)算法进行迭代-遍历-去除冗余窗口的过程,保留置信度最高的分数的预测窗口输出.
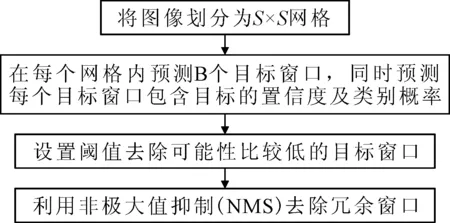
图1 YOLO算法流程图
1.3 边界框坐标预测
YOLO算法的边界框坐标预测使用锚框(anchor)来预测边界框,见图2,YOLOv3为每个目标边界框预测四个坐标:(tx,ty,tw,th).其中:tx,ty为预测的坐标偏移值;tw,th为边界框的宽和高.根据式(3)~(6)计算得到预测框的中心点坐标值(bx,by,bw,bh);bx,by为归一化后的相对于网格单元的值;bw,bh为归一化后相对于候选区域框的值.其中,cx,cy为特征图中网格的坐标偏移量;σ(·)函数为逻辑函数,将边界框坐标归一化到0~1之间;Pw,Ph为预设的候选区域框映射到特征图中的宽和高.
bx=σ(tx)+cx
(3)
by=σ(ty)+cy
(4)
bw=Pwetw
(5)
bh=Pheth
(6)
1.4 预测精度评估方法
预测精度的评估指标计算为
(7)
(8)
(9)
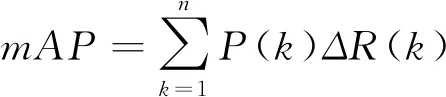
(10)
式中:P为查准率;R为召回率;F1为F度量值;TP,FP和FN分别为真正例、假正例,以及假反例数量;P(k)为阈值k处的精度;ΔR(k)为召回量的变化.
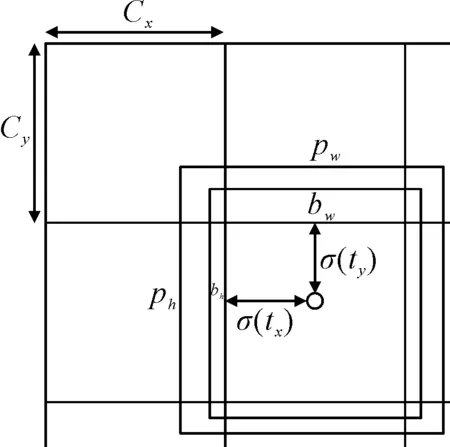
图2 边界框预测示意图
2 YOLOv3-tiny的网络结构
YOLOv3-tiny的计算耗时主要在网络的卷积部分,骨干网络见图3,可以观察到这个网络含有相对较多的卷积层.在卷积层假如输入的图片的维度是W×H×C,三个值分别为输入图片的宽度、高度,以及通道数.卷积核的维度为C×K×K.C为卷积核,即滤波器的通道数;K为卷积核的宽高.
YOLOv3-tiny采用的骨干网络类似于YOLOv3中darknet-19的网络结构,主干网络采用一个7层的卷积层和池化层网络来提取特征,嫁接网络采用的是13×13、26×26的分辨率网络,这两个分辨率网络分别表示小尺度YOLO层和大尺度YOLO层.小尺度的YOLO层输入13×13的特征图,一共1 024个通道,输出13×13的特征图,75个通道,在此基础上进行分类和回归.大尺度YOLO层的是将14层的13×13、256通道的特征图进行卷积操作,生成13×13、128通道的特征图,然后进行上采样生成26×26、128通道的特征图,同时与第9层的26×26、256通道的特征图合并最终输出26×26、75通道的特征图,在此基础上进行分类和位置回归.

图3 YOLOv3-tiny网络结构
3 自适应锚框聚类
目标检测任务的难点在于图像或视频中目标的类别、数量、位置和尺度的不确定性,通常的算法会采用特征金字塔的多尺度预测和遍历滑动窗口结合的方式逐尺度逐位置的进行判别,实际训练过程中不仅耗时,而且有可能会出现梯度不稳定的现象.
采用锚框(anchor)技术预测默认给定方框的偏移量.首先预设一组不同尺度不同位置的固定参考框,囊括图像中全部的位置和尺度,然后每个参考框负责检测与其交并比(IOU)大于预设阈值的目标.锚框技术将目标检测的问题进行了转化:即算法将多尺度遍历滑窗寻找判别目标的过程转变为判别给定的目标参考框中是否有目标以及目标框与参考的偏差值,从而不再需要算法采用多尺度遍历寻找目标,加快了检测速度.
锚框的尺寸要与检测的目标尺寸相近才能保证预测函数可以看作一个线性函数,从而保证检测结果的准确性.采用k-means算法来确定检测算法所需要锚框大小,步骤见图4.最终根据已有的船舶数据集计算所得的锚框尺度为(98×90),(224×140),(355×145),(206×306),(355×255),(368×366),见图5.
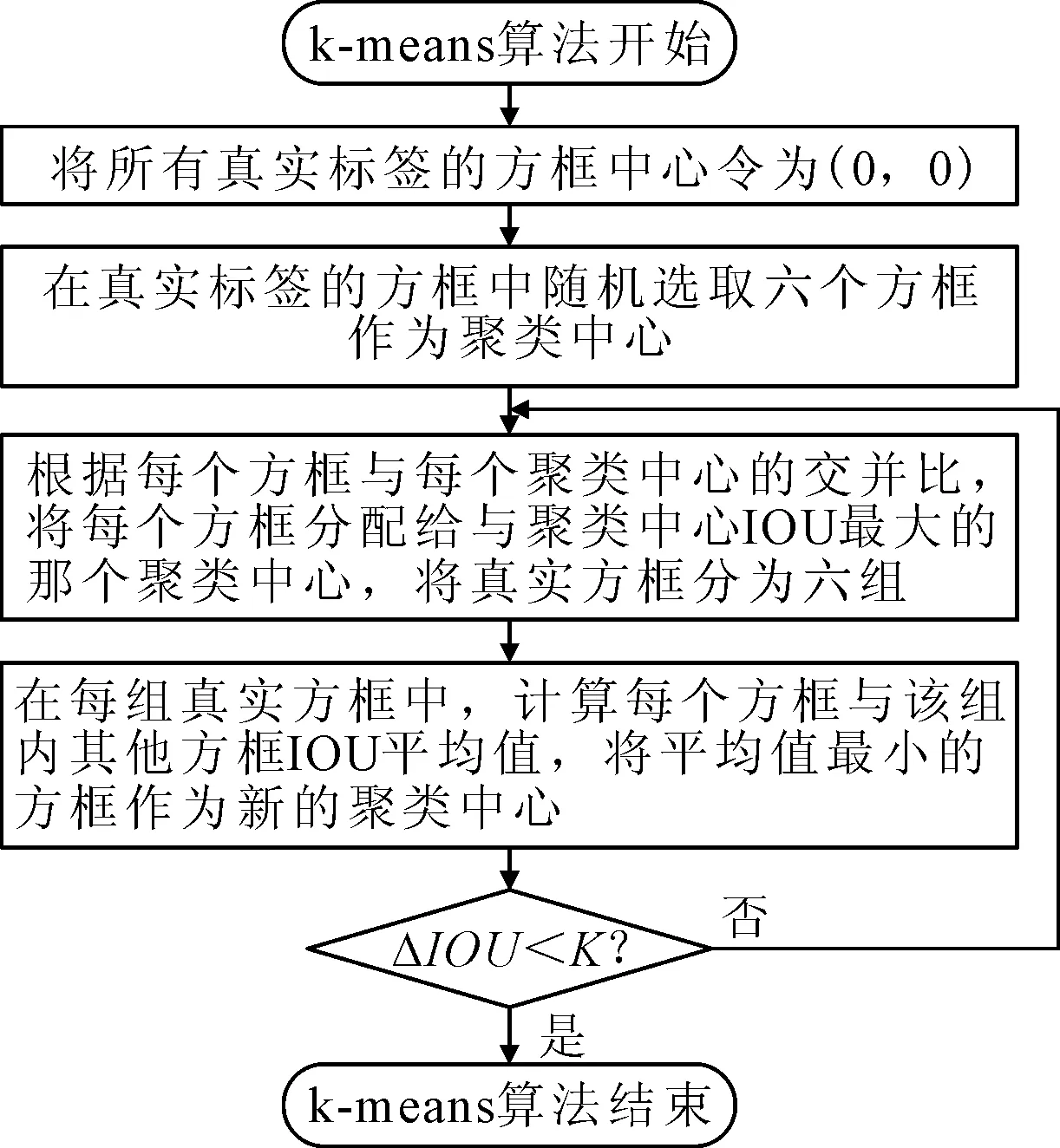
图4 k-means算法流程
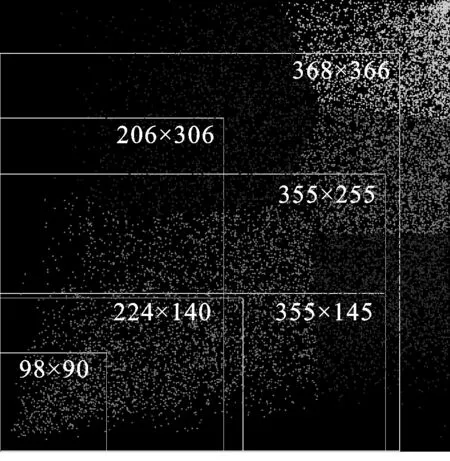
图5 k-means锚框聚类结果
4 数据增强
训练深度学习卷积神经网络的优化目标在于将网络的损失尽可能降低,即将网络中的参数以正确的方式调整,最终能够将输入映射到输出的过程.现在最先进的目标检测神经网络具有很高的复杂度,拥有数百万的参数,因此在训练过程中需要提供足够比例的数据.
深度学习卷积神经网络在训练的时候拥有更多的训练数据往往可以取得更为理想的检测效果,但在训练过程中数据量通常是有限的,需要通过数据增强技术来增加训练集的样本丰富性.数据增强的原理是通过随机改变训练样本来使检测模型的敏感性降低,最终使模型的泛化能力得到强化,即阻止神经网络学习不相关的特征,从根本上提升整体性能.
检测模型的敏感度主要分为两种,①模型对于所检测目标的位置敏感性;②模型对于所检测目标的色彩敏感性.通过翻转、旋转、平移、缩放、裁剪等数据增强技术可以降低模型对于所检测目标的位置敏感性,而通过改变图像饱和度、曝光率、色调等色彩属性可以降低模型对于所检测目标的色彩敏感性.图6为数据增强实例.

图6 数据增强实例
本文运用数据增强的方法,利用随机生成的样本来扩充数据集,可以提高目标检测模型的鲁棒性,增强模型的泛化能力.
5 仿真实验
5.1 船舶细粒度图像数据集
水面船舶目标检测需要有专门的船舶图像数据集来进行训练和测试,目前没有针对船舶的大型公开数据集.参照国内的船舶分类标准对网络上收集的船舶图片进行分类,建立了一个拥有9万张图片84个类别的船舶大型图像数据库.同时团队成员对船舶的边界框以及语义部件进行人工标注.图7为船舶数据集的展示.

图7 船舶数据集
图7展示的图片都具备整船显现、背景单一、分辨率较好的特点,为了增强目标检测算法的鲁棒性,在搜集图片的时候也挑选了具有不完整船舶、背景复杂、分辨率低等特性的船舶图片,这不仅增加了人工标注的难度,也增加了算法误检、漏检的概率.
实验中用于训练和测试的船舶图像按照民用船舶和军用船舶各取10类共计20类船舶作为目标检测细粒度图像数据集,具体分类见图8.

图8 船舶数据集具体分类
5.2 实验参数设置及实验配置
采用YOLOv3-tiny网络结构,其参数设置为batch=64,即每64个样本更新一次参数;设置subdivision(子batch)=8,将每个batch设置为8个子batch;设置动量值为0.9;设置权重衰减正则项为0.005,目的是防止过拟合;设置曝光量为1.5,图像的旋转范围为[0°,10°],饱和度为1.5,色调设置为0.1.
在设置预选框之前,最后一层的卷积层的卷积核个数为固定的,遵循以下基本公式:
Filters=(class+5)×3
(11)
因为本文的预测类别为20类,所以最后一层滤波器的个数为75.使用的训练集数量为13 568,测试集数量为3 418.
5.3 仿真实验结果及分析
对YOLOv3-tiny模型使用数据增强和锚框聚类作两大方面改进,结果见表1.

表1 不同算法的测试结果
在仅使用自适应锚框改进的YOLOv3-tiny算法中,模型的查准率和召回率均有1%的提高,识别帧率也由小幅提高,最终结果mAP值有1.85%的提升.而在仅使用数据增强的YOLOv3-tiny的算法中,模型的查准率提高了3%,IOU(交并比)提升了2.32%,其他评价指标并未发生变化,总体的mAP值提升了5.88%,提升较仅使用自适应锚框的模型更为显著.最后模型将两种改进方法集成到原有的YOLOv3-tiny模型中,模型的查准率提升了7%,IOU提升了6.39%,召回率小幅下降,帧率也小幅提升到136帧/s,最终平均精度mAP值提升了9.02%,说明两种方法改进之后的模型精度提升显著.
图9为采用锚框聚类和数据增强改进后的YOLOv3-tiny算法的成功检测结果.由图9可知,民用船舶的识别效果总体要好于军用船舶,这是因为民船功能性强,每一种船舶自身的特点显著,其中货船和客船的AP值最高,而军船由于作战的快速性以及结构的坚固性的需要,船舶图像中表示语义的纹理以及形状信息较民船更为相似,并且由于数据集中军用船舶的训练集和测试集数量小于民用船舶,导致检测效果整体略差于民用船舶,所以会经常出现误检漏检的情况.

图9 成功检测案例
综合以上结果可以得出结论,本文针对YOLOv3-tiny的改进使得模型的整体性能有了显著提高,在实时性和精确性方面基本满足了水面船舶可见光图像的识别要求,可以辅助驾驶人员对水面船舶的识别,船舶驾驶人员可以根据船舶种类做出合理的避让决策,保证船舶安全航行.
6 结 束 语
本文针对智能船舶目标检测算法在应用大多数机器学习方法时存在的实时性问题.提出了基于YOLOv3-tiny模型改进的船舶可见光图像细粒度检测算法,通过使用轻量化的网络结构,以及搭建船舶图像数据库并进行人工标注,针对水面船舶可见光图像进行目标检测,并采取了自适应锚框聚类和数据增强这两种改进算法,最终优化结果平均精度由51.11%上升到62.85%,实时检测帧率达到136帧/s,满足水面船舶实时目标检测的要求,在精确性和实时性上具备一定优势.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
北京航空航天大学学报(2021年9期)2021-11-02
船舶(2021年4期)2021-09-07
课外生活(小学1-3年级)(2020年2期)2020-03-09
电子制作(2019年13期)2020-01-14
水上消防(2019年3期)2019-08-20
船舶标准化工程师(2019年4期)2019-07-24
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
科普童话·百科探秘(2015年6期)2015-10-13
