
基于新离散公式和OpenMP优化的有限差分声波数值模拟
2020-12-16 00:45:00郑如秋王波涛冯永照余卫江
世界地质 2020年4期
郑如秋, 王波涛,冯永照, 余卫江
中海油田服务股份有限公司 特普公司, 广东 湛江 542051
0 引言
有限差分算法是偏微分方程的主要数值解法之一,是最早的数值模拟方法。该方法的基本原理是采用离散后的差分算子取代相应的连续微分算子,具有计算效率高、占用内存相对较小的优势,并且对于近远场及复杂边界都有广泛的适用性,能够准确地模拟波在各种介质及复杂结构地层中的传播规律,是勘探地震学中应用最广泛的数值计算方法[1]。
目前,国内外学者对基于波动方程的地震波正演模拟技术进行了大量的研究工作,地震波正演模拟技术十分成熟。但在模拟计算过程中由于传统的弹性波动方程数值模拟存在参数繁多、计算量大、耗时长和占用内存空间大等问题,因而声波方程数值模拟得到广泛应用[2]。1971年,Claerbout et al.将有限差分法在波场模拟中的应用做了很大改进,提高了模拟效率[3];1974年,Alford et al.研究声波方程数值模拟,给出精度与差分阶数和网格步长关系[4];1976年Madariaga首次提出交错网格差分算法[5];1984年,Virieux et al.推导了一阶应力--速度方程有限差分算法,提高了计算精度[6];1986年,Dablain et al.给出声波方程交错网格算法差分格式[7]; 1997年, Clayton将吸收边界应用到声波方程数值模拟当中[8]; 2001年,Collino et al.将PML边界应用到应力--速度方程的数值模拟当中[9];2004年,Saenger将交错网格进一步发展,提出了旋转交错网格法,这一方法对复杂介质体的模拟精度有显著提高[10];2000年,董良国等详细给出了基于交错网格的一阶应力--速度的弹性波方程有限差分法[11];2004年,裴正林等进一步研究了空间任意偶数阶精度的交错网格差分法,使其更加适应不同复杂介质的数值模拟[12]。
通过对有限差分声波波场数值模拟研究的分析发现,基于一阶应力--速度方程的有限差分声波模拟是业界应用最为广泛的算法,很对学者对其进行优化,例如优化差分系数的求解方法,使用旋转网格代替常规网格。虽然这些方法可以提高模拟精度,不容易出现频散现象,但是计算效率会降低,而在工业生产中计算效率更为重要。通常情况下可以通过使用高阶有限差分算法来提高计算精度,克服频散现象,因此,常规网格下有限差分算法是保证较高的模拟精度条件下,计算效率最高的算法。随着计算机水平的发展,利用OpenMP并行计算可以大大提高数值模拟速度,但是常规网格下的有限差分算法的PML边界公式复杂,包含三阶偏导数,需要将计算区域分为有效计算区域和边界区域,不利于实现并行计算,容易产生内存错误。对此,模仿一阶应力--速度方程PML边界公式格式,改进不含有三阶偏导数倒数的PML边界。保证了计算区域和边界区域计算代码统一,并行计算编程易于实现,对OpenMP的制导语句参数进行测试优化,进一步提高了计算效率。
1 声波方程有限差分算法原理
利用有限差分法进行数值模拟,对空间采用高阶差分离散,而在时间上只采用二阶中心差分,推导出常规网格条件下计算区域与边界区域一致的离散公式,使得OpenMP并行计算过程中效率提高,所以对于方程离散原理,差分系数计算,频散问题不做详细论述。
标准二维声波方程可以表示为:
(1)
式中:P=P(x,z;t) 表示声波波场;V=V(x,z)表示模型速度;ρ=ρ(x,z)表示模型密度。相应的PML边界条件下边界区域计算方程是包含三阶偏导数的复杂方程组,以右边界为例[13]:

(2)
其中:
(3)
式中:L为PML区域宽度;R为反射系数;lx为该点到边界的距离。通过公式(2)可以得出,对于模拟的边界区域要分别判断所属区域,左、右边界使用水平方向的衰减系数d(x),而对于上、下边界需要使用垂直方法的衰减系数d(z),对于四个交点有的学者提出对以对角线进行划分成两部分,上部分使用d(z),下部分使用d(x),但是这些都将导致需要对计算区域进行判定,导致编程实现过程繁琐,不利于并行计算。
通常情况下实现编程计算是通过对方程(1)进行离散可以得到空间2N阶精度的计算区域的波动方程有限差分格式。
(4)

Collino提出将二阶声波方程转换为一阶应力--速度方程后,再加入PML边界。这个方法大大降低了直接对二阶声波方程加载PML边界而增加的复杂度。一阶应力--速度方程加载PML边界条件的控制方程具有如下形式:

(5)
其中vx和vz是质点震动的速度分量,离散公式如下:
(6)
一阶应力速度方程有限差分算法其相应的PML边界区域离散公式与计算区域离散公式相同,只有阻尼系数在边界区域d(x)≠0,d(z)≠0 ,而计算区域阻尼系数为0。编程过程中不需要对模型进行区域划分,有利于OpenMP并行计算。但由于引入中间变量vx和vz,相比于常规网线条件下的有限差分算法,增加了大约两倍的计算量。
目前关于数值模拟中PML边界加载方式十分成熟,但是绝大部分都是基于一阶应力--速度方程,交错网格框架下的研究。笔者研究了一阶应力--速度方程PML边界离散过程,SPML和NPML的推导原理,结合参考文献[14--15],引入二阶阻尼系数,给出直接对常规网格下二阶声波方程加载PML边界的方法:
(7)

(8)
(9)
Px项经过数值模拟测试,不需要展开为 0.5×[(Px)k+1+(Px)k-1],直接保留为原型,此时来自边界反射能量最小。
最终获得边界反射能量最小的常规网格二阶声波方程离散公式为:
(10)
计算机实现代码:
/*波动方程计算函数 定义*/
void wavequ( int i, int j, int k, double *cm, double (*u1t0)[XN], double (*u2t0)[XN], double (*u1tp1)[XN],double (*u2tp1)[XN], double (*u1tn1)[XN], double (*u2tn1)[XN], double (*u1tmp)[XN], double (*u2tmp)[XN],double (*ut0)[XN], double (*utp1)[XN], double (*dx)[XN], double (*dz)[XN], double (*v)[XN])
{
int s;
double sumequ1,sumequ2;
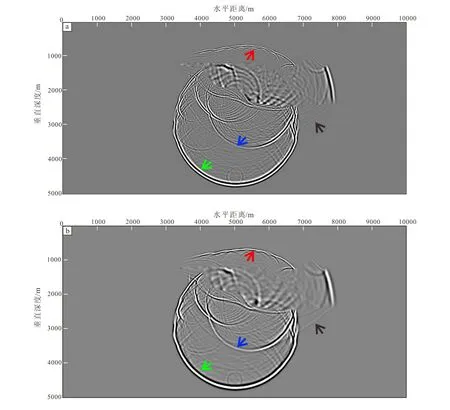
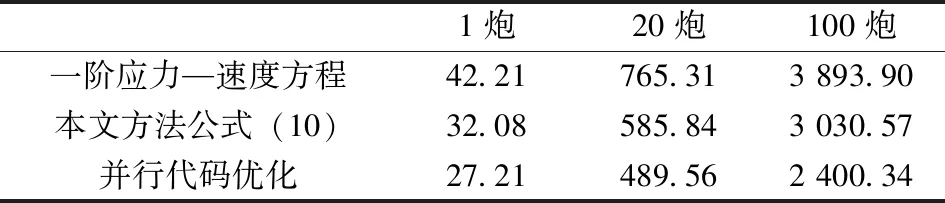
for(s=0,sumequ1=0.0,sumequ2=0.0;s { sumequ1=sumequ1+cm[s]*(v[i][j]*v[i][j]*ut0[i][j+s+1]+v[i][j]*v[i][j]*ut0[i][j-s-1]-v[i][j]*v[i][j]*2*ut0[i][j]); sumequ2=sumequ2+cm[s]*(v[i][j]*v[i][j]*ut0[i+s+1][j]+v[i][j]*v[i][j]*ut0[i-s-1][j]-v[i][j]*v[i][j]*2*ut0[i][j]); } u1tmp[i][j]=DT*DT/DH/DH*sumequ1; u1tp1[i][j]=1/(1+2*dx[i][j]*DT)*((2-dx[i][j]*dx[i][j]*DT*DT-2*dx[i][j]*DT)*u1t0[i][j]- u1tn1[i][j]+u1tmp[i][j]); u2tmp[i][j]=DT*DT/DH/DH*sumequ2; u2tp1[i][j]=1/(1+2*dz[i][j]*DT)*((2-dz[i][j]*dz[i][j]*DT*DT-2*dz[i][j]*DT)*u2t0[i][j]-u2tn1[i][j]+u2tmp[i][j]); utp1[i][j]=u1tp1[i][j]+u2tp1[i][j]; } 推导出来的离散有限差分公式(10),在计算过程中计算区域与边界区域计算机实现代码统一,不需要对边界进行判断而改变计算公式,更加有利于并行计算。推导的公式(10)与不含边界的有限差分公式(4)相比,只是增加了阻尼系数的计算,这个阻尼系数在速度模型确定时候即可计算,不需要每次都特殊计算。 本文提出基于OpenMP及改进的常规网格有限差分声波数值模拟优化,在第1章中主要通过改进边界条件,从算法原理上是代码简洁为并行计算奠定基础,提高计算效率。本章主要对于OpenMP制导语句、子句等细节进行调整,可以进一步提高计算效率。 OpenMP标准通过定义编译制导、库例程和环境变量规范的方法,基于fork-jorn的并行执行模型,将程序主体划分为并行区和串行区,不同线程之间可以通过共享变量实现数据交换,多核CPU进行并行运算时,多个CPU可同时对程序各个不相关进程进行运算,从而提高程序的运行效率。OpenMP可直接在串行代码上通过编写并行制导语句实现程序的并行,以良好的简洁性和可移植性成为并行编程的工业标准。需要并行化的程序如果比较复杂,需要注意程序内部结构和变量之间的逻辑关系,以防止并行后内存读写冲突。 本章主要分析讨论利用OpenMP技术进行并行设计的两个关键问题:一是如何将原来的串行程序改为并行程序,避免内存读写冲突;二是如何更为有效地使用制导语句,提高并行效率。声波波场数值模拟过程当中,任意一点下一时刻的波场值的计算是通过当前时刻的波场值、前一时刻的波场值和当前时刻波场在空间方向的导数获得的,这三个变量之间互不相关,计算过程中不会产生影响,可以共享至全部线路,具有可并行性。但是控制波场点位的变量i,j只能对应于对应线路计算的波场值,需要进行私有变量处理。 OpenMP使用C编辑器的#pragma扩展机制来定义制导,基本格式为: #pragma omp directive-name[clause[[,]clause]…] new-line 其中,每个制导均以#pragma omp开始,directive-name是制导名,[]可以加入相应功能的子句。OpenMP最基本的单元是parallel结构,由parallel制导。使用OpenMP中private数据子句解决简单变量的内存读写冲突问题。private子句可将简单变量声明为本线程的私有变量,每个线程都存有变量的副本,其他线程无法访问。即使在并行区域外有同名的共享变量,此共享变量也不会对并行区域造成影响,且并行区域内部计算也不会改变外部共享的变量值。因此在并行起始语句中加入private(i,j)即可以解决简单的内存读写冲突问题。 OpenMP采用fork-join(分叉--合并)的并行执行模式,在运行过程中,遇到并行开始代码(由parallel制导),计算机的主线程则调用多个线程来执行并行任务。如果没有nowait子句,所有线程在共享计算结构的结束处隐式同步。为了提高并行计算效率,子句需要使用nowait,使参与计算的线程无需同步而继续执行随后的程序段,减少多余的同步以提高计算效率。OpenMP的调度模式使用静态调度schedule(static),同时仍然需要使用num_threads()子句保证并行区域的占用线程不会影响主线程的计算效率,减少线程调度的时间消耗。通过测试以计算机总线程数为8为例,在并行时尽量不要使用全部线程数量,在并行制导语句中加入num_threads(7),保证并行过程最多使用7个线程,以保证主线程的计算效率。 本文中的有限差分算法,计算每一时刻的波场快照需要通过for循环结构完成,需要使用parallel for制导,OpenMP对程序的循环部分进行并行化,要求用于并行的循环部分每次循环互不相关。二维模拟的计算任务分为三层循环(最外层是时间,内层依次为x,z方向上的空间循环),由于每个时间切片上的当前循环,依赖于上两个时间切片上的计算结果,即时间循环中各个时间切片存在相关性,因此对于时间不适合使用OpenMP并行而对于x,z方向上的空间循环,具备应用OpenMP并行计算条件,因此每一次空间循环都可以被指定进行并行计算。 使用有限差分算法进行地震波场声波数值模拟区域时,需要在边界加入特殊的边界条件,以消除来自边界的虚假反射问题。使用上一节推导出的有限差分公式,在空间循环外层加上并行制导指令即可。并行计算核心代码结构如下所示: for(k=0;k { #pragma omp parallel num_threads(7) { #pragma omp for private(i,j) schedule(static) nowait for(i=M;i for(j=M;j 逐点计算的波动方程计算函数代码 } } 波场转存储代码 } } 本章主要为了验证两个问题:①改进的离散的波场模拟公式在任何模型中可以准确模拟波场;②结合OpenMP可以进一步提高计算效率。目前一阶应力--速度方程时声波模拟的标准方法,为了证明改进的离散公式(10)可以准确模拟波场,以下的试验将从波场模拟的准确程度和计算效率与其对比。 试验1: 使用一个500×500,dx=dz=10 m,dt=800 ms,速度为4 000 m/s的均匀速度模型,震源放置在中心(250,250)。分别使用本文方法进行模拟并与一阶应力--速度方程的模拟结果进行对比。如图1所示,在t=0.56 s,波场未到达边界,模型为均匀模型,因此波场快照表现为圆形,两种方法波形一致。在t=0.8 s时,波场触碰到人工边界,均为产生反射现象,说明改进的离散计算公式可以正确模拟波场,并且在边界处无明显反射。值得注意的是,由于波场传播的控制方程和模拟过程的差分格式差异,波场在能量振幅存在差异。 a. 本文方法(t=0.56 s);b. 本文方法(t=0.8 s);c. 一阶应力--速度方程(t=0.56 s); d. 一阶应力--速度方程(t=0.8 s)。图1 简单模型的波场快照Fig.1 Snapshots of wavefield of a simple model 为进一步证明推导出的公式(10)在复杂模型中也可以准确模拟波场,使用Sigsbee模型进一步验证。模型大小为1 001×501,dx=dz=10 m,dt=0.001 s。速度模型和波场快照如图2所示,sigsbee速度模型中包含一个高速盐体,盐体上表面起伏,容易产生绕射波场,将震源放置于模型中间(5 000,2 600)位置。理论上,震源上方的崎岖界面会产生一系列绕射波,而盐体的下界面由于界面平缓,界面处速度差异明显,会产生强反射波和沿着界面滑行的折射波,折射波的波前表现为直线。选择t=0.8 s时的波场快照进行展示,两种算法的波场快照中都可以看到震源激发的透射波场波前(绿色箭头所指)、盐体界面产生的反射波(蓝色箭头所指)、折射波(黑色箭头所指)和绕射波(红色箭头所指)。通过对于sigsbee模型进行模拟可以充分说明所推导的离散公式(10)可以准确模拟波场。 图2 Sigsbee速度模型Fig.2 Sigsbee velocity model a.本文方法; b.一阶应力--速度方程。图3 t=0.8 s时的波场快照Fig.3 Snapshots at t=0.8 s 试验2: 该实验中的程序均为并行程序,使用Linux系统机群的一个节点进行并行计算效率测试对比。节点主频2.4 GHz,十六线程。分别使用基于一阶应力--速度方程,本文方法公式(10)和并行代码优化后的程序进行计算效率测试。测试使用上一个试验Sigsbee模型进行模拟,总采样点数设置为1 000,总炮数设置为1炮、20炮和100炮。测试结果如表1所示。 表1 计算效率对比表Table 1 Comparison of computation efficiency /s 从试验结果可以看出,本文改进的有限差分公式(10)相比于一阶应力--速度方程的计算效率已经有所提高。而对于并行代码优化后的就算效率进一步提高,计算时间只需要一阶应力--速度方程的60%。 (1)规则网格下的有限差分算法,适当提高差分阶数,既可以满足模拟精度要求,相比于一阶应力--速度方程的计算效率更高。通过改进边界条件公式,推导出新的离散公式,相比于传统二阶声波方程的PML边界控制方程,边界计算区域中不再包含波场的三阶偏导数和阻尼系数的一阶导数。并且,新的离散公式在计算区域与边界区域公式一致,计算机实现过程中不需要加入条件语句判断。相比于一阶应力--速度方程,减少中间变量引入,模拟的控制方程只需要3个,可以提高计算效率。 (2)通过结合OpenMP并行计算,可以进一步提高计算效率。并行过程容易产生变量的内存问题,串行代码转换为并行代码后对程序变量优化,减少内存访问。通过OpenMP制导语句中使用适当的参数,可以进一步加快计算效率。2 OpenMP多核并行算法
3 数值模拟计算


4 结论
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46石油地球物理勘探(2018年4期)2018-07-16 11:48:28中国宝玉石(2018年3期)2018-07-09 03:13:58小猕猴智力画刊(2017年6期)2017-07-03 09:19:12西南石油大学学报(自然科学版)(2016年2期)2016-12-01 06:01:47地震学报(2016年1期)2016-11-28 05:38:36地球物理学报(2016年11期)2016-11-23 05:59:21发明与创新(2016年26期)2016-08-22 03:23:26信息安全研究(2015年3期)2015-02-28 20:17:57物探化探计算技术(2015年2期)2015-02-28 17:42:53
