
数字人文项目中的数据众包运作策略研究
2020-12-15 10:55岑炅莲欧阳剑曾辉
图书与情报 2020年5期
关键词:数字人文
岑炅莲 欧阳剑 曾辉

摘 要:数据驱动研究成为人文学科研究的主流,数据是数字人文项目实施的基础和核心之一。文章分析了新网络环境下数字人文数据众包的概念和现状,从数据众包发起者的角度出发论述了数据众包项目的运作模式及任务,并针对性地提出数字人文数据众包的实施方式、数据管理、质量管理、激励政策、诚信问题和成果发布及版权等问题的应对策略。研究认为,数字人文数据众包对人文数据的建设是有益的补充,数据众包给数字人文工作提供了数据化的平台和工具,数字人文数据众包可以加深公众对文化和历史的理解。
关键词:数字人文;数据众包;人文数据;众包策略
中图分类号:G255 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2020090
Abstract Data-driven research becomes the mainstream of humanities research. And data is one of the foundation and core of digital humanities project implementation. This paper analyses the concept and status of data crowdsourcing in digital humanities research under new network environment. From the perspective of data crowdsourcing initiators, this paper analyses the operation mode and tasks of data crowdsourcing, and proposes the corresponding strategies for implementation methods, data management, quality management, incentive policies, integrity issues, achievement publication and copyright issues of digital humanities data crowdsourcing. Digital humanities data crowdsourcing is a useful supplement to the construction of humanities data. Data crowdsourcing provides data platform and tool for digital humanities work. Digital humanities data crowdsourcing deepens the public's understanding of culture and history.
Key words digital humanities; data crowdsourcing; humanities data; cowdsourcing strategies
1 引言
數字人文是充分运用计算机技术开展的合作性、跨学科的研究、教学与出版的新型学术模型和组织形式[1]。数字人文最显著的特点就是借助计算机进行量化分析,数据是数字人文项目实施的基础和核心之一,数据驱动研究成为人文学科研究的主流。目前大部分人文数据由图书馆和数据供应商所拥有,由于人文数据建设需要花费大量的时间及经费,因此学者能自由使用的人文数据非常有限,人文数据匮乏已成为数字人文研究者的共识。面对人文数据匮乏的局面,近年来,数字人文研究者尝试了多种人文数据建设的方式,数据众包就是帮助数字人文研究者获取人文数据的有效方式之一。
随着信息技术的发展,新的网络环境不断演进,形成了一个分散式共享、合作和传播的全球化、网络化的世界。在新的网络环境下,公众通过社交互动、参与式的知识创造形式来表达他们的需求。然而,目前对于数字人文类众包项目的研究侧重于用户参与数字人文众包的意愿、绩效影响因素、运作流程和平台,缺少对人文数据特点的分析,数据众包的整体运作策略研究较少,对数据众包过程中负面问题的解决策略研究也相对匮乏。因此有必要对数字人文数据众包的运作策略进行研究,了解新网络环境下数字人文数据众包的主要任务,分析数据众包发起者如何选择实施方式、实施平台和任务发布方式,以及对运行管理、成果管理中可能遇到的问题提出应对策略,从而为今后的数字人文数据众包项目提供一定的借鉴意义。
2 数字人文数据众包的概念和研究现状
2.1 数字人文数据众包的概念
杰夫·豪[2]于2006年6月在《连线》杂志的一篇文中首次正式提出“众包”一词,并指出众包是一个公司或机构将过去由员工执行的工作任务以自由自愿的形式外包给非特定(通常是大型的)大众网络的做法。众包是利用大型在线社区对特定任务进行创建内容或收集想法的实践,它是互联网技术关键文化转变的产物,也适用于数字人文的数据众包项目。
数字人文数据众包是一种创新实践活动,它根据数字人文项目的需要,采用大众共建的方式,实现定制化的数据获取与数据加工方案设计与执行服务,为数字人文项目提供标准化、结构化的可用数据,其中数据采集及数据标注的类型涵盖文本、图像、音频、视频、网页等。数字人文项目的主要工作量消耗在数据处理上,仅仅依靠有限的项目人员无法完成大规模数据整理、加工及组织工作,因此有必要利用大众智慧进行数据众包来共同完成数字人文项目研究。
2.2 数字人文数据众包的研究现状
学术领域的众包可以称为公众科学,目前公众科学研究引起不少学者关注。而数字人文类众包属于公众科学的一种,研究主要集中在四个方面:(1)用户参与数字人文众包的意愿和影响因素研究。如张轩慧等[3]通过S-O-R理论构建公众参与数字人文类众包动因的实证模型,提出志愿者的感知有用性、自我效能、娱乐享受和使命感是参与众包的主要动机;Seitsonen和Oula[4]通过对芬兰的文化遗产机构的众包案例分析发现用户的自我满足感是主要参与动机;(2)数字人文众包绩效的影响因素研究。如韩文婷等[5]提出任务复杂度和领域知识水平是影响数字人文类众包任务绩效的主要原因;(3)数字人文众包的运作流程研究。如赵宇翔[6]在传统的众包活动的三个主体(发包方、平台和接包方)基础上加入第三方组织机构,构建矩阵式项目管理机制,指出公众科学项目运作基本流程包含八个行动;Oomen和Aroyo[7]利用数字内容生命周期模型提出了数字人文领域众包的运行包括筛选、创造、管理、发现、使用和保存;(4)数字人文众包平台研究。如肖奕[8]以数字人文项目在线合作平台DHCOMMONS为例,提出资助机构、学科领域、隶属机构、合作类型与合作者类型影响数字人文项目合作平台的发展。
综上所述,目前学者对于数字人文类众包研究主要集中在公众参与意愿、绩效影响因素、运作流程和平台方面,然而缺少对于人文数据的分析,以及人文数据如何进行众包,人文数据众包过程中可能出现的数据管理、质量管理、激励政策、诚信和版权等问题和障碍提出的应对策略研究较少。因此有必要对数字人文数据众包的运作策略进行研究。
3 数字人文数据众包主要任务
数字人文项目中的人文数据具有的特点及人文学者研究对人文数据的需求构成了人文数据组织及重构的基本要素,其中主要有人文数据的完整性、可计算性、可用性及重用性、可发现及获得性等[9]。数字人文項目对人文数据提出了独特的要求,人文数据的构建很大程度上由学科规范和方法论所决定,人文数据的组织通常需要有人文素养的介入,即需要了解人文数据特点及符合人文学者研究的需求才能确保人文数据的有效性。
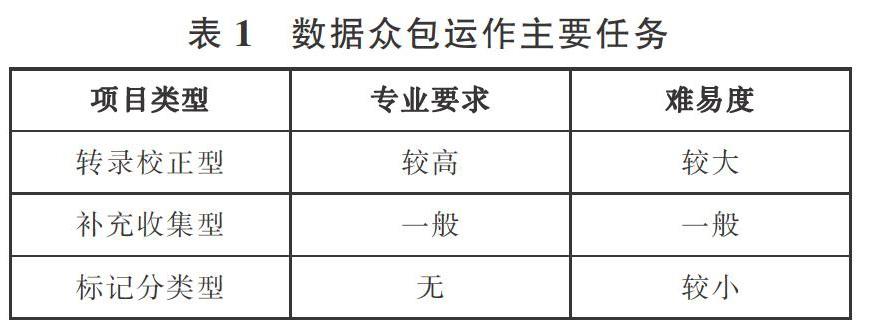
开展数字人文数据众包,首先要从人文数据研究者的需要去界定任务类型,不同的数字人文研究者或研究机构有不同的数据众包需求,Oomen和Aroyo[7]从文化遗产机构的大量众包实践中,提出了美术馆、图书馆、档案馆及博物馆(GLAMs)存在校正和转录任务、语境化、补充收藏、分类、联合策展、众筹等六种众包类型。借助数据生命周期模型可以帮助我们更好地理解数字人文数据众包不同阶段的活动。典型的数据生命周期模型包括数据的创建/收集、描述、存储、发现、分析和重用[10]。目前,在数字人文数据众包实践活动中,多数志愿者参与了人文数据的创建/收集和描述工作,其可以利用数字人文研究者提供的原始人文资料进行人文数据的创建,或者自行提供原始人文资料,并转化为完整的人文数据,此外他们还积极利用Web2.0技术对一些人文资料进行标签化或者评论,从而为数字人文项目提供元数据。这些工作可以分别对应转录校正型任务、补充收集型任务和标记分类型任务。而存储、发现、分析和重用工作往往由数字人文数据众包的发起者或平台执行,随着数字人文数据众包实践的不断发展,未来志愿者可以参与更深层次的人文数据管理。
3.1 转录校正型任务
转录校正型任务是最受欢迎的数据众包任务之一,它对已有的大量人文资料进行人工转录和校正,从而创建可供数字人文项目所需的集成化、细粒化、关联化及可计算化的数据。虽然光学字符识别技术(Optical Character Recognition,OCR)可以通过电子设备检查纸上打印的字符,然后将形状翻译成计算机文字[11]。但它只针对印刷体字符,对扫描的图像有很高的质量要求,然而一些手稿、照片、古籍等无法通过OCR识别技术获得准确率高的可计算文本数据。因此,可以将无法OCR识别或OCR识别准确率较低的图像信息通过大量人工干预的方式转录、校正成数字人文项目所需的人文数据。边沁手稿转录项目利用对手稿转录有兴趣的志愿者对哲学家边沁的手稿进行人工转录,建立可搜索的数据库[12]。美国史密森尼转录中心为志愿者提供19个博物馆和档案馆的材料进行转录[13]。上海图书馆历史文献众包中心开展的盛宣怀档案抄录项目,选取盛宣怀档案中与辛亥革命相关的信函、电报、公牍、奏折等若干,以供抄录[14]。澳大利亚国家图书馆借助专门的数字资源呈现系统,招募志愿者对数字化了的1803-1954年间没有版权的历史报纸进行校正,以提高文本质量[15]。
3.2 补充收集型任务
补充收集型任务是在缺少现有人文资料的情况下,通过志愿者收集可参考的人文数据,一般志愿者可以在日常生活中获取这些数据,从而保证项目数据的完备性。纽约公共图书馆开展“建筑检查员”(Building Inspector)项目,利用公民在日常环境中寻找旧地图所需的数据,并提交纽约公共图书馆的数据库中[16]。上海图书馆家谱知识服务平台支持用户贡献内容的形式,吸引众多网络用户撰写反馈家谱信息,平台不断更新,使数据在使用过程中增值[17]。
3.3 标记分类型任务
标记分类型任务要求志愿者利用元数据描述数字化信息资源的属性,通过添加标签、评论的方式,评价、追踪资源,协助数据有效检索。视频是人文研究中较为复杂的资料,获取它的内容信息较为困难。纽约公共图书馆引入用户标签系统,通过志愿者浏览口述历史视频,从菜单中选择关键词,将标签映射到视频中的时间码,同时可以对缺失的字幕视频进行标记,此外还可以将非英语视频翻译成英文字幕视频[18]。英国国家档案馆开展“战争日记”项目,希望志愿者对第一次世界大战英国士兵的日记进行标记和分类[19],志愿者可以从受控词表中选择关键词进行标记。豆瓣网则允许用户对图书、电影、音乐等添加标签、评分,从而获得图书、电影的关键词信息,并用这些信息改善网站的推荐效果。
由于不同任务对于志愿者专业水平要求和限定完成时间不同,三种类型的数据众包任务难易度不同(见表1)。其中,转录校正型任务通常要求转录者具有转录内容的背景知识,如“籍合网”招募校正古籍的志愿者时,要求志愿者实名注册,具有文史哲相关专业及背景,并有古籍整理的经验,这类转录校正任务通常消耗的时间较长。补充收集型任务虽然要求志愿者对某方面研究具有一定的了解,但通过项目发起者的培训或者志愿者自我学习,可以较快掌握任务操作流程。而大多数标记分类型任务不需要志愿者具备专深的背景知识,他们可以注册登录,也可以匿名访问,一般标记、分类和评论不会花费志愿者太长的时间。
4 数字人文数据众包策略
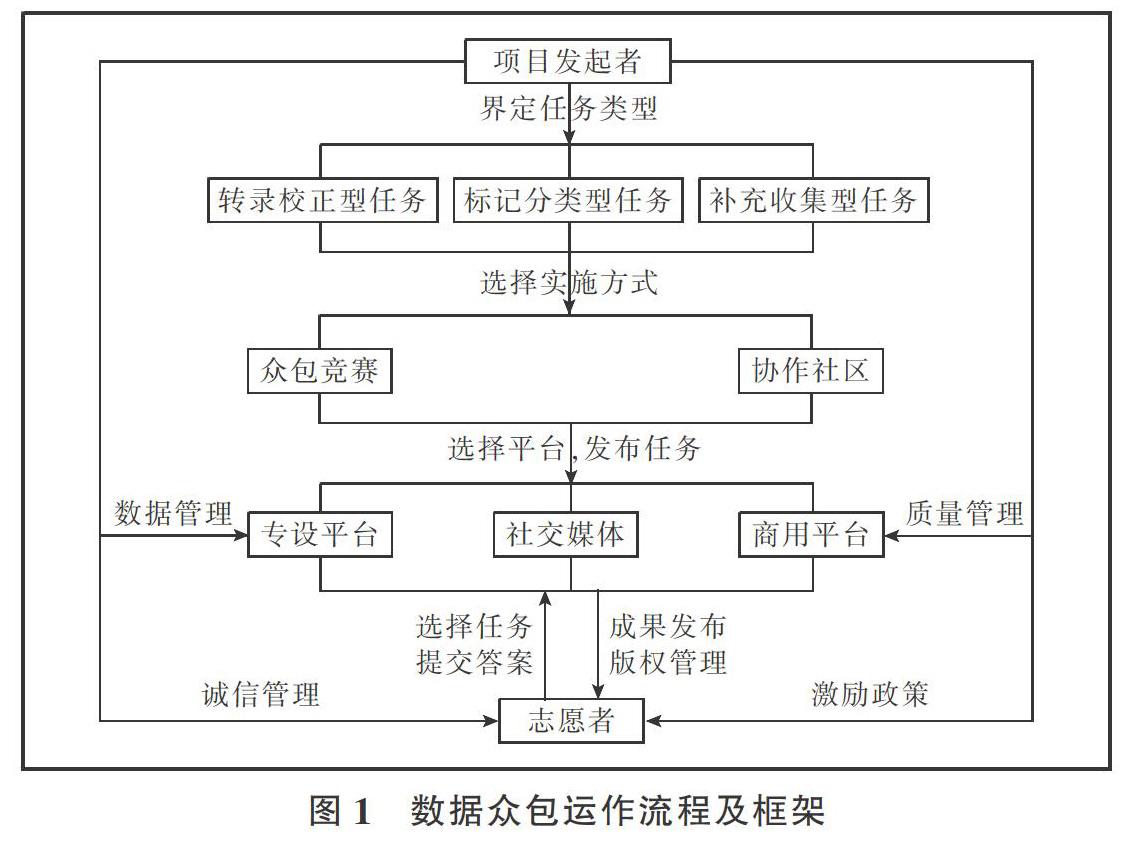
传统的众包运作流程包括3个阶段:任务准备、任务执行和任务答案整合。其中任务准备阶段包括:发起者设计任务、发布任务,志愿者选择任务;任务执行阶段包括:志愿者接收任务、解答任务、提交答案;任务答案整合阶段包括:发起者接收/拒绝答案、整合答案[20]。数字人文领域数据众包主要由数据众包发起者、志愿者和平台这三个主体组成,三个主体之间相互制约、相互影响,共同推动数据众包的运行(见图1)。从数据众包发起者的角度来说,需要考虑发起者在数据众包的前期、中期和后期的主要工作,将数据众包的运作流程分为数据众包设计、数据众包运行管理、数据众包成果管理[21]。其中,数据众包设计包括界定任务类型,选择任务实施方式、选择平台和发布任务;数据众包运行管理则需解决数据管理、质量管理、激励政策和诚信伦理等问题;数据众包成果管理对版权和成果发布问题进行讨论。
4.1 数字人文数据众包实施方式选择
传统的众包模式主要包括众包竞赛和协作社区两种类型[22]。数据众包项目的最终目的是为了解决数字人文项目的数据短缺问题,而解决问题可以有唯一最优解和无穷多最优解,分别对应着众包竞赛和协作社區。
众包竞赛以比赛竞争的形式对人文数据进行众包,发起者根据不同参与者的解决方案,进行排名并对最佳解决方案发放奖励,它强调解决方案的优选性,主要由外部动机即项目发起者所推动,采取自上而下的组织方式[23]。InnoCentive众包创新平台把需要解决的众包任务标准化成一个或若干个竞赛,并提出优胜的标准,每个项目的奖金额度为5000美元至100万美元不等[24]。2018年南京大学信息管理学院和上海图书馆历史文献众包中心联合开展了文化遗产数字化竞赛,参赛者选取盛宣怀档案中进行抄录,经过专家审核评分,共17个团队获奖[25]。
众包协作社区则是在一个和谐的环境内允许志愿者提交的不同解决方案同时存在,它强调解决方案的聚合性,主要由内部动机即志愿者所推动,采取自下而上的组织方式[23],维基百科是利用协作社区进行数据众包的典型例子。维基百科将多名贡献者的成果进行编排,整合成一个连贯的整体,实现价值的创造,通过自动化流程来协调和整合大众的编辑工作,跟踪所有的改动,由于维基百科大众规模庞大,任何一条词条都需经过多重人员的审查,从而保障了内容质量,由此可见,协作社区最适用于解决编排相对简单的项目,大众协作依靠广泛的任务模块化、标准化程序和技术来实现合作的顺畅。
因此,数字人文数据众包任务发起者应该根据所需的数据解决方案而选择合适的数据众包实施方式(见表2),以获取符合人文学者研究的人文数据。在数字人文的数据众包中任务难度较大的转录校正型众包任务可以通过众包竞赛的方式实施,获取解决众包任务的最优方案。而对于任务难度较小的标记分类型任务、补充收集型任务则适合采用协作社区的方法,一方面不必花费过多的精力设计专项众包平台,另一方面,协作社区以多元化的属性,整合尽可能多的成果。
4.2 数字人文数据众包平台选择及任务发布
众包任务的发布和数据的收集是通过众包平台来完成的。数字人文数据众包的平台主要分为三大类[6,21]:一是项目发起者设计的专项平台,这类数据众包平台虽然前期耗费一定的时间与精力设计,但是它能较好地保障项目的专业性和数据的完整性,有利于多维性数据的收集与数据之间关联的建立;二是Facebook、Twitter、微博、校内论坛等社交媒体平台,这类平台收集到的人文数据杂乱且碎片化,但是可以节约项目经费,快速部署,对参与者的门槛较低,成果传播范围更广;三是商用的众包平台,如国外的Amazon Mechanical Turk、CloudCrowd、InnoCentive等,国内的猪八戒、脑力库、三打哈等,这类平台有丰富的众包经验,可以缩短项目实施时间,优化项目管理效率。
本文提到的边沁手稿转录项目、史密森尼转录项目、盛宣怀档案抄录项目、上海图书馆家谱知识服务项目等都是设立了专门的众包平台或系统;美国国会图书馆利用Flickr社区进行图片标记分类,则吸引了众多志愿者参与,传播范围较广。因此数字人文数据众包平台的选择需要根据发布者的需求来选择,对数据专业性和数据的完整性有特殊要求、或众包数据量较大的众包项目可以自行设计自己的众包平台,不但能保证数据的完整性,而且有利于后续数据众包的继续开展,而对于数据要求不严格或众包数据量不多的众包项目则可以选择第三方的数据众包平台。
4.3 数字人文数据众包运行管理
4.3.1 数据管理
数字人文项目进行数据众包离不开对庞大的数据管理。数字人文数据众包的启动离不开大量的原始数据基础,数字人文数据众包实施过程中数据的管理直接关系到项目实施的效率和完成的质量,此外,成功的数字人文数据众包也积累了大量的数据。因此数据的可持续发展问题值得我们思考,数据众包项目需要考虑项目成果将在哪里进行存储和维护?持续研究项目的资金如何解决?如果要进行长期持续开发,可能的资助来源有哪些?哪些机构长期备份或存储项目的数据?与我们熟悉的商业活动众包项目相比,数字人文领域的数据众包在数据容量、数据种类、数据有效性及数据完整性上更加难以有效管理。因此,数字人文领域的数据众包项目对数据质量管理有更高层次的需求。
赵宇翔[6]提出以往的公众科学项目缺乏对数据的关注和深入挖掘,没有将产生的科研数据作为一种资产进行有效管理和利用,同时提倡将元数据构建、关联数据以及数据监护等图书情报学科的理论和方法应用在数字人文平台的管理中。数字人文数据众包中的数据组织及重构方法包括数据化、数据融合、数据关联及发布,首先,在OCR识别文本的基础上,加强对文献内容的重组,将文献内容转化为可制表分析的量化数据,满足数字人文研究者对数据的属性要求[26];其次,通过异构融合、多源融合、多模融合三种不同的形式对人文数据进行融合,形成有效的多视角分析数据集,从而进行多维度挖掘和分析,帮助人文学者发现新规律、新价值[27]。此外,利用数据关联技术建立人文数据集。近年来上海图书馆家谱关联数据服务平台及历史地理数据的开放方面应用关联数据技术进行大量实践研究,采用关联数据从以图书馆为中心的知识组织系统向跨领域公开可用和易于访问的知识图谱转变,可提高人文数据的可用性和重用性。
4.3.2 质量管理
由于数字人文数据众包项目的志愿者大多数是普通大众而不是具备专深理论知识的研究者,高质量的成果往往数量不多。因此,数据众包项目发起者应该均衡任务的成本、任务的质量、任务完成时间三者的关系,以提高项目质量。
首先,在数据众包实施之前可以对志愿者进行相关知识调查和测试,这不仅可以过滤不符合工作要求的志愿者,还可以让志愿者进一步了解工作任务,进而提高工作质量。如“籍合网”招募校正古籍的志愿者时,要求志愿者实名注册,具有文史哲相关专业及背景。
其次,对通过测试的志愿者进行培训,使志愿者更加熟悉任务,提高工作效率和工作质量。对于难度较大的转录校正型项目,如边沁转录项目为志愿者提供了详细的转录指南,并定期开展转录培训。补充收集型项目由于难度不大,管理者可以适量提供一些工具类的培训。如纽约公共图书馆“Building Inspector”项目开展计算机培训,鼓励参与者利用计算机软件更方便地收集地理信息。对于分类标记型项目,管理者会提供一定的受控词表,志愿者以此进行分类和标记,避免分类过大,提高项目质量。
最后,合理设计任务过期时间,使志愿者在适度的时间内完成任务。Ipeirotis[28]发现,大多数任务请求者都将任务的“过期时间”设置为12小时或7天,在12小时这个时间节点,只有大约50%的任务被完成,如果等到7天,大约90%的任务被完成。
4.3.3 激励政策
数据众包的参与志愿者多样化,因此任务发起者必须花费更多的精力来平衡志愿者的需求。完善的激励政策才能保证数据众包项目顺利实施。目前,用户参与的激励政策分为物质金钱激励方式和非物质金钱激励方式。
其中,物质金钱激励可以在短期内招募大量志愿者,但是很多数字人文项目属于非营利性项目,长期采用物质金钱激励方式不太现实。因此,数据众包项目可以支付志愿者小部分工资,同时使数据众包的志愿者对工作内容产生兴趣或实现自我满足。Mason和Watts[29]研究发现,只有合适的任务回报才能吸引志愿者参与数字人文众包项目。偏高的回报导致吸引过多的参与者,从而降低了任务质量同时给发包商增加成本压力;偏低的回报则会导致志愿者的兴趣点下降,对众包工作产生懈怠心理,导致任务时间周期较长。众包竞赛中经常利用物质金钱激励志愿者参与项目,InnoCentive众包平台根据不同难度的众包任务设置不同的奖励,一般难度的项目要求志愿者提交方案的时间为1-2个月,奖金取决于完成情况,最高为数万美元;中等难度的项目提交方案时间为2-3个月,奖金为数万至数十万美元;难度较大的项目提交方案的时间为3个月以上,奖金最高达100万美元。
麦肯锡的研究表明,推动Web2.0用户进行无条件构建知识的主要动力不是物质激励,而是兴趣和声誉[30]。非物质金钱激励方式主要包括积分制和排行榜公示。虚拟积分可以激发志愿者一定程度的兴趣和积极性。排行榜公式激励方式即在项目网站上公布参与用户的贡献度。同时进行贡献度认证,各参与用户需提供一份说明在各阶段的作用和付出的时间。根据马斯洛需求层次理论,排行榜公式方式正好满足了参与用户尊重需求和自我实现需求等高层次需求,同时排行榜能够激发参与志愿者之间的竞争,这种竞争可以良性推动数据众包工作的开展。边沁手稿转录项目采用积分和排行榜公式的方式激励志愿者,网站上公布了前五十名志愿者的积分,并根据积分将上榜者划分不同称号。盛宣怀档案抄录项目在平台首页右侧清晰地展示了前十名的用户名和积分。
此外,从外部激励和内部激励角度激发志愿者的积极性,数字人文数据众包项目还应针对不同阶段灵活采取不同的激励政策。张轩慧[3,31]对数字人文类众包项目初期和中后期公众参与动因进行了探讨,提出在众包项目实施初期,应该增强平台的易用性和社交性,提高任务的自主性、有趣性和情境性,从而激发参与者的感知有用性和使命感,从而吸引更多用户参与数据众包项目,保证项目的正常启动。在众包项目实施中后期,项目发起者应该将物质奖励和精神奖励有机结合,同时创建志愿者交流社区,将游戏化元素融入平台,同时增加反馈和协助机制,增强志愿者参与信心;此外在任务设计方面,循序渐进的任务难度和不断更新的任务种类,才能保持志愿者的持续执行动力,增加志愿者与项目的粘性,保障数据众包项目的顺利完成。
4.3.4 伦理诚信
由于公众参与众包的方式包括匿名访问、注册登录、实名参与。因此,一方面数据众包平台可能泄露参与用户个人隐私。如“籍合网”在招募古籍校正志愿者时,要求志愿者填写真实姓名、身份证号以及发放报酬用的银行卡号等,此外,一些地理空间众包工作任务可能会暴露志愿者的地理位置;另一方面,由于参与用户可以直接接触研究者的研究资料,因此可能会歪曲众包的信息,或者將研究者的众包信息泄露给其他研究者,阻碍数字人文众包项目的有效实施。因此,众包项目发起者应该与志愿者在实行任务前签订同意书和保密协议,避免知识产权纠纷,众包发起者和志愿者自觉维护双方权利,才能促进众包项目的顺利实施。
4.4 数字人文数据众包成果管理
4.4.1 成果宣传
众包成果可以分为阶段性成果和最终成果。在众包项目运行中,项目方通常会发布相关文章或报告,分享阶段性成果,同时也起到项目宣传的效果,吸引更多的志愿者参与。在项目结束后,除了发表相关文章,项目成果通常还有开放数据库、开源工具等公开性成果。如边沁手稿转录项目每个月都会在其网站上公布转录的进度和成果,并定期向学术界和公众发布演讲。“籍合网”对于完成转录校正的古籍,汇总成开放的古籍数据库供大众查阅,服务公众和社会。上海图书馆家谱知识服务平台将收集到的家谱信息集合成档案供公众浏览和搜索。
4.4.2 版权管理
从某种角度上讲,众包模式推动了文化和历史的传播。为了加快知识的有效流传,资源所有者应该积极树立开放意识,主动推进人文学科资源的数据化工作。Cooper等[31]提出应该在志愿者参与科学研究的成果中清晰地标注“公众科学”的字样,这不仅可以认同公众参与科学研究的积极作用,还能提醒未来学者归纳此领域的研究成果。数字人文项目人员逐渐从个体转变为跨领域学者和志愿者合作团队组成,数字人文的数据众包成果也应该转变著述模式,以“我”为核心的单一著述模式转变为以“我们”为中心的合作性著述模式,打破传统的以版权保护和专属授权限制为中心的著作权理念,限制程度最低的共享与授权模式应该成为主流。边沁手稿转录项目每月更新成果版本,上海图书馆家谱知识服务平台实时对家谱目录进行补充。以数字手段出版和发表的作品不再是最终版本,而是处于不断迭代过程中的更新版,新的知识和发现可以随时被补充进来。
5 结语
本文从数字人文数据众包发起者的角度论述了数据众包运作策略,在数据众包的设计、运行管理和成果管理三个阶段中,具体介绍了转录校正型、标记分类型、补充收集型这三种任务,区分了众包竞赛和协作社区的实施方式和不同众包平台的特点,并对可能出现的数据管理、质量管理、激励政策、诚信问题和成果发布与版权问题提出了应对策略。
目前,我国数字人文领域应用众包形式的案例逐渐增多,我们应当积极吸取国外数字人文众包项目的成功经验,充分利用众包的力量,加速人文数据的建设,推动数字人文研究。数字人文数据众包对人文数据的建设是有益的补充,数据众包给数字人文工作提供了数据化的平台和工具,通过数字人文数据众包活动,不仅帮助人文学者获取研究所需的人文数据,还进一步加深公众对文化和历史的理解,达到了宣传的效果[32]。我们在塑造平台、工具和技术的同时,这些平台、工具和技术也在塑造我们,由此形成了数字人文的社会生活。
参考文献:
[1] (美)安妮·伯迪克,约翰娜·德鲁克,彼得·伦恩费尔德,等.马林青,韩若画,译.数字人文:改变知识创新与分享的游戏规则[M].北京:中国人民大学出版社,2018:121.
[2] HOWE J.The rise of crowdourcing[J].Wired,2006,14(6):176-183.
[3] 张轩慧,赵宇翔,王曰芬.数字人文类公众科学项目冷启动阶段的公众参与动因研究[J].图书与情报,2019(3):61-72.
[4] Seitsonen,Oula.Crowdsourcing Cultural Heritage:Public Participation and Conflict Legacy in Finland[J].Journal of Community Archaeology & Heritage,2017:1-19.
[5] 韩文婷,宋士杰,赵宇翔,等.数字人文类众包抄录平台中任务绩效的影响因素研究——基于任务复杂度与领域知识视角[J].图书与情报,2019(3):73-84.
[6] 赵宇翔.科研众包视角下公众科学项目刍议:概念解析、模式探索及学科机遇[J].中国图书馆学报,2017,43(5):42-56.
[7] Oomen J,Aroyo L.Crowdsourcing in the cultural heritage domain:opportunities and challenges[C].International Conference on Communities and Technologies.ACM,2011:138-149.
[8] 肖奕.数字人文项目合作平台分析——以DHCOMMONS为例[J].知识管理论坛,2017,2(6):464-476.
[9] 欧阳剑,彭松林,李臻.数字人文背景下图书馆人文数据组织与重构[J].图书情报工作,2019,63 (11):15-24.
[10] DCC Curation Lifecycle Model[EB/OL].[2019-11-23].http://www.dcc.ac.uk/resources/curation-lifecycle-model.
[11] 梁连高.浅析纸质文书档案数字副本OCR识别方法[J].科技与创新,2018(4):129-130.
[12] 边沁手稿转录项目[EB/OL].[2019-03-20].https://blogs.ucl.ac.uk/transcribe-bentham/.
[13] 史密森尼轉录中心[EB/OL].[2019-03-20].https://transcription.si.edu/.
[14] 盛宣怀档案抄录项目[EB/OL].[2019-03-20].http://zb.library.sh.cn/index.jhtml.
[15] 澳大利亚国家图书馆数字报纸项目[EB/OL].[2019-03-20].http://www.nla.gov.au/content/newspaper-digitisation-program.
[16] 纽约公共图书馆“建筑检查员”项目[EB/OL].[2019-03-20].http://buildinginspector.nypl.org/.
[17] 上海图书馆家谱知识服务平台[EB/OL].[2019-03-20].http://search.library.sh.cn/jiapu/.
[18] 纽约公共图书馆“社区口述历史项目”[EB/OL].[2019-03-20].http://oralhistory.nypl.org/.
[19] 英国国家档案馆“战争日记”项目[EB/OL].[2019-03-20].http://www.operationwardiary.org/.
[20] 冯剑红,李国良,冯建华.众包技术研究综述[J].计算机学报,2015,38(9):1713-1726.
[21] 练靖雯,张轩慧,赵宇翔.国外数字人文领域公众科学项目的案例分析及经验启示[J].情报资料工作,2018(5):32-40.
[22] 邢文明,司莉.Web2.0环境下用户参与图书馆信息组织的可行性分析——基于用户接受的实证研究[J].图书馆建设,2012(4):31-35.
[23] 乔健.美国众包悬赏竞赛创新模式剖析[J].全球科技经济瞭望,2017,32(10):8-12.
[24] InnoCentive众包创新平台[EB/OL].[2019-03-20].https://www.innocentive.com/.
[25] 南京大学信息管理学院主办的文化遗产数字化竞赛活动落幕[EB/OL].[2019-03-20].http://im.nju.edu.cn/content.do?mid=3&mmid=34&cid=7bf6abc0-1634-11e9-b5d3-40a8f01ece83.
[26] 赵思渊.地方历史文献的数字化、数据化与文本挖掘:以《中国地方历史文献数据库》为例[J].清史研究,2016(4):26-35.
[27] 欧阳剑.面向数字人文研究的多源数据融合[R].第十三届数字图书馆前沿问题高级研讨班(ADLS2016),上海,2016.
[28] Ipeirotis P G.Analyzing the amazon mechanical turk marketplace[J].ACM Crossroads,2010,17(2):16-21.
[29] Mason W A,Watts D J.Financial incentives and the “performance of crowd”.Proceedings of the ACM SIGKDD Workshop on the Human Computation[J].Paris,France,2009:77-85.
[30] Michael Chui,Six ways to make Web 2.0 work[EB/OL].[2019-03-20].https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/six-ways-to-make-web-20-work.
[31] Cooper C B,Dickinson J,Phillips T,et al.Citizen Science as a tool for conservation in residential ecosystems[J].Ecology&Society,2007,12(2):375-386.
[32] S Schreibman,R Siemens,J Unsworth.Crowdsourcing in the Digital Humanities[M].John Wiley & Sons,Ltd,2015.
作者簡介:岑炅莲,女,广西民族大学管理学院硕士研究生;欧阳剑,男,上海外国语大学图书馆研究馆员;曾辉,男,广西民族大学管理学院硕士研究生。
猜你喜欢
图书与情报(2017年6期)2018-03-12
图书与情报(2017年5期)2018-01-02
科学与财富(2017年30期)2018-01-01
现代经济信息(2017年13期)2017-07-23
河南图书馆学刊(2017年6期)2017-06-30
河南图书馆学刊(2017年6期)2017-06-30
河南图书馆学刊(2017年5期)2017-05-31
大学图书馆学报(2017年1期)2017-03-25
大学图书馆学报(2016年5期)2017-02-18
大学图书馆学报(2016年5期)2017-02-18
