
基于主成分分析和K-Modes蚁群聚类的本体映射方法
2020-12-14 10:21许飞翔曹军博
计算机应用与软件 2020年12期
叶 霞 许飞翔 曹军博 王 馨
1(火箭军工程大学作战保障学院 陕西 西安 710025)2(马里兰大学巴尔的摩校区信息系统学院 马里兰州 巴尔的摩 21250)
0 引 言
指挥信息系统在作战部队中的广泛运用,产生了大量的测试与评估数据,由于不同单位建立的指标体系存在差异,相同的概念经常被使用不同的指标进行描述,导致测试与评估数据在共享和集成上存在较大困难。随着语义网络和本体技术的不断发展,本体集成可以有效解决此问题,将格式异构的测试数据转换为局部本体,建立统一的全局指标本体树[1],从而实现指挥信息系统测试评估数据的有效集成。在本体之间架起语义映射的桥梁,完成由局部本体到全局本体的映射技术已经成为当前研究的热点和难点问题。
1 相关研究
目前的本体映射[2]方法主要有基于规则的本体映射方法、基于语义网的本体映射方法和基于机器学习的本体映射方法。基于规则的本体映射主要是通过人为定义规则发现本体概念之间的映射关系,比如“如果两个概念的属性全部一致,那么可以在两个概念之间建立映射关系”等规则。Kedzia等[3]提出了基于规则的方法将plWordNet映射到SUMO本体上,使用专家定义的规则识别可能的映射关系,然后语言专家进行手动检查。姚香菊等[4]提出了由专家建立的规则学习库的映射系统,实现批量本体概念映射关系的发现。
基于语义网的本体映射主要有基于Hownet、WordNet,以及中文概念辞书CCD等现有的语义网络进行相应节点的映射,潘有能等[5]以WordNet为基础,从语义网络中获取概念的语义和结构关系,完成概念的映射。Schadd等[6]提出将本体概念与其对应的WordNet条目进行耦合的改进方法,通过创建表示不同本体概念和WordNet条目的独立虚拟文档,并根据它们的文档相似性对它们进行耦合,实现本体概念的映射。Elhadad等[7]提出一种基于WordNet的本体论方法,使用向量空间模型表示文本,通过WordNet计算元素级本体概念之间的语义相似性,完成本体映射的关键性工作,提高本体映射准确率。
基于机器学习的本体映射方法主要是将本体映射问题转化为聚类、分类或者最优化问题,采用机器学习中监督学习、半监督学习或无监督学习的算法实现映射。Shao等[8]提出的RiMOM方法将映射发现问题转化为风险最小化问题,利用贝叶斯决策理论去发现映射关系,有效地提高了本体映射结果的精度。Cheng等[9]提出基于最小生成树聚类算法的本体映射策略,对参与映射概念的候选对象进行筛选,使用系统信息熵来监督聚类,取得较好映射效果。Yin等[10]提出了一种基于词与上下文相似性分类的方法,将本体树的节点分为分类节点和概念节点,依赖于本体的树结构,完成本体概念之间的映射。
总体而言,单纯依靠规则和语义网络进行本体概念映射关系的发现逐渐暴露出费时费力、准确率不高的缺陷,基于机器学习的方法逐渐成为提高本体映射效率和质量的有效途径。因此,本文提出基于PCA和KMACC的本体映射模型,采用基于主成分分析法的相似度综合计算模型计算本体概念相似度,提高本体概念相似度计算的精度,运用改进的K-Modes蚁群聚类算法进行映射的发现,有效地提升本体映射的准确率和效率。
2 方法设计
2.1 基于PCA的本体概念相似度综合计算模型
2.1.1基于信息内容的相似度计算
基于本体概念信息内容的相似度计算需要考虑到概念对最近公共父节点的信息量,孙丽莉等[11]提出还需考虑到概念对本身的信息量,他们所提出的计算式为:
(1)
式中:M(C1,C2)表示概念对C1和C2在本体树中的最近邻公共父节点;I(C1)和I(C2)分别表示概念C1和C2包含的信息量。信息量的计算式为:
(2)
式中:N(C)为概念C在训练样本中出现的次数;N为训练样本的总数。
2.1.2基于语义距离的相似度计算
基于本体概念语义距离相似度计算的经典方法是通过计算两个概念之间的几何距离来计算语义距离。这里的几何距离是取概念对到最近公共父节点的路径和来计算的,计算式为:
(3)
式中:Dis(C1,C2)=L(C1,M(C1,C2)+L(C2,M(C1,C2)),L(C1,M(C1,C2))表示概念C1到C1与C2的最近公共父节点的最短路径,L(C2,M(C1,C2))表示概念C2到C1与C2的最近公共父节点的最短路径。
影响概念语义距离的因素还有很多,Leacock等[12]提出的改进方法主要思想是除了考虑概念对之间的最短路径外,还考虑了其所处本体树的最大深度,同时考虑到两个概念最近公共父节点在本体树中的深度。综合以上研究,给出基于本体概念语义距离的相似度计算式为:
(4)
式中:P(M(C1,C2),C1)表示概念对C1和C2最近公共父节点在概念C1所在本体树中的深度;max(P(C1))表示概念C1所处本体树的最大深度。
2.1.3基于概念属性的相似度计算
基于本体概念属性的相似度计算主要考虑能够表明概念特征的属性共有程度,早期的研究主要依据计算概念对所共有的属性个数来计算属性相似度,公共属性个数越多,则相似度越大。张贤坤等[13]提出属性信息包含属性名称、属性数据类型和属性值三个要素,需要综合计算属性相似度,算法更为科学,因此直接引用此计算模型进行概念属性的相似度计算。其中属性名称和数据类型都是字符串形式,以字符串相似度计算方法计算,本文使用余弦距离计算法。模型中设概念C1和C2的属性分别为p和q,则属性p和q的相似度计算式为:
Simpq(p,q)=ω1×sim(pname,qname)+
ω2×sim(pdatatype,qdatatype)+ω3×sim(pvalue,qvalue)
(5)
式中:ω1、ω2和ω3为权重参数且ω1+ω2+ω3=1;sim(pname,qname)表示属性名称相似度值;sim(pdatatype,qdatatype)表示属性数据类型相似度值;sim(pvalue,qvalue)表示属性值相似度值。当概念C1和C2共计算出m个Simpq(C1,C2)时,设每个属性对的权重为ωk,则C1和C2基于本体概念属性的相似度计算式为:
(6)
2.1.4相似度矩阵构建

Y=(yi1,yi2,…,yi3)Ti=1,2,…,n
(7)
2.1.5基于PCA的相似度综合计算模型
PCA[14]是一种多元统计方法,相比于传统人为确定权重的方式,PCA可以较为准确地计算出各因素对综合计算值的贡献程度。在本文的模型中,只有基于信息内容、语义距离、概念属性这三个子因素,因此都确定为主成分,根据专家评价结果对相似度矩阵Y进行主成分分析,计算出各主成分的贡献率为γ1、γ2、γ3,确定权值便可得概念对C1和C2的综合相似度计算式为:
Sim(C1,C2)=γ1Sim1(C1,C2)+γ2Sim2(C1,C2)+
γ3Sim3(C1,C2)
(8)
基于PCA的本体概念相似度综合计算模型框图如图1所示。

图1 基于PCA的本体概念相似度综合计算模型
2.2 改进的K-Modes蚁群聚类算法
2.2.1K-Modes聚类算法
聚类分析[15]是指将实体对象或者抽象对象的集合分组为由相似对象组成的多个类的分析过程,传统的聚类分析采用欧氏距离或者编辑距离来判断两个对象的相异性,实现对数值型和文本型数据的聚类,采用的距离计算方法不同对聚类的效果有很大的影响,直接影响本体映射的效果。本文定义本体概念相似度Sim(C1,C2)的倒数为两个本体概念的距离,实现本体概念的聚类,以提高本体概念聚类的精度。本体映射中多个本体的概念存在差异时,样本集合中概念出现的次数越多,意味着此概念更具有代表性,因此将各簇之中的众数设定为聚类中心,即目标本体概念,实现映射时将其他概念直接由聚类目标本体概念代替,实现本体概念的映射。因此本文提出基于众数的聚类方法发现映射关系,即K-Modes聚类算法,其思想如下:设集合中共有m个对象,从集合中随机选择k个对象,按照预先设定的聚类个数k,将它们设定为聚类中心。然后计算所有对象到这些聚类中心的距离,按照距离最近原则将所有对象聚到各个簇中,接着使用频次法将聚类中心设定为各簇中的众数对象,重复计算、选取,定义目标函数:
(9)

W是一个m×k的{0,1}矩阵;wil=1表示第i个对象被划分到第l类中;Z={z1,z2,…,zk},zl(1≤l≤k)是第l类的中心。聚类迭代,直到目标函数F(W,Z)达到最小,不再发生变化为止。
在使用K-Modes聚类算法时,初始聚类中心的选择对聚类结果的影响较大,同时K-Modes聚类算法对孤立的数据点比较敏感,容易陷入局部最优,对算法性能产生一定的影响。本文利用K-Modes聚类算法简单、易操作和运行速度快的特点,对样本数据进行初始聚类,得到具有一定聚类特征的中间数据。
2.2.2蚁群聚类算法
蚂蚁在觅食的时候会释放一种特殊的分泌物——信息素。它们在寻找食物的路径选择中,一开始是随机地挑选一条可行的路径,同时会释放出和该条路径的长度相关的信息素。当这条路径走得越远,信息的释放就会越来越少。大量的蚂蚁在完成寻找食物这个活动的过程中,通向食物的路径被越来越多的蚂蚁走过,因此在这些路径上存在大量的信息素,后来的蚂蚁再次觅食时便会选择信息素多的路径,同时给这条路径释放更多的信息素,这就形成了一个正反馈机制,这种正反馈机制被有效地用来解决路径寻优问题。而蚁群觅食的活动过程不仅仅是一个路径寻优问题,还可以抽象成聚类问题,基于蚂蚁觅食行为的聚类方法最早是由Deneubourg等[16]提出,近年来得到了广泛的发展和应用。
基于蚁群算法觅食原理的聚类算法思路如下:随机选取一个本体概念Ci作为蚂蚁遍历的起始位置,这只蚂蚁根据式(3)或者随机产生一个随机值,当该随机值小于预先设置的阈值s时则将其分配到聚类中心Xj的位置,此时蚂蚁就在数据对象Ci到聚类中心Xj的路径上留下信息素τij。蚂蚁选择聚类中心Xj的概率计算式为:
(10)

(11)
随着蚂蚁的移动,路径上的信息素不断挥发,信息素更新计算式表示为:
(12)
式中:ρ表示信息素的挥发系数;Q表示一个正常数。
在迭代初期,由于信息素较少,蚁群聚类算法的收敛速度比较缓慢,所以与K-Modes聚类算法相结合,将数据进行预处理,得到一个聚类雏形,再结合蚁群聚类算法进行聚类,提高聚类结果的准确性。
2.2.3KMACC算法
为解决传统聚类易收敛于非全局最优及早熟问题,本文将K-Modes聚类算法与蚁群聚类算法相结合并加以改进,提出KMACC算法,应用于本体概念的映射发现中,有效提高了聚类的精度和效率。KMACC算法的流程如图2所示。

图2 KMACC算法流程图
算法具体步骤为:
Step1从本体概念集合中随机选择一个本体概念作为第一个类别中心X1。
Step2对于样本集合中每一个本体概念Ci,计算与上一个刚被选择成为类别中心的本体概念之间的距离。
Step3距离较大的样本,被选取作为新的类别中心的概率比较大。
Step4重复Step2和Step3直到k个初始的类别中心被选出。
Step5对每一个本体概念计算与k个类别中心的距离,找到距离最小的Xj后,将该本体概念添加到Xj所在的样本集合中。
Step6计算得到的k个类别的样本集合中本体概念的众数,将这些众数样本作为新的k个类别中心。
Step7重复Step5和Step6,满足迭代次数或者类别中心不再变化时,得到处理后的聚类中心和簇。
Step8对于每个数据对象Ci到相应的聚类中心Xj分配初始不同的信息素τij,其中簇中各样本到聚类中心的路径上的信息素多于到其他聚类中心路径上的信息素。
Step9初始化信息素挥发系数ρ、正常数Q、分配阈值s、蚂蚁数n。
Step10随机产生p∈(0,1),当随机数p Step12所有蚂蚁完成一次遍历后,按照式(12)进行信息素更新,进行迭代。 Step13达到设定的迭代次数t或者S值不再减小时,算法终止,输出最优聚类结果。 基于PCA和KMACC的本体映射方法如图3所示。首先将多个本体树的本体概念抽取出来放入集合中,采用基于PCA的本体概念相似度计算综合模型本体概念间的距离,利用K-Modes蚁群聚类算法实现本体概念的聚类,发现映射关系,并将目标本体设定为各簇中出现频次最多的本体概念,建立映射关系,最后利用基于规则的本体映射修正策略[17]修正映射中出现的偏差,完成映射。 图3 基于PCA和KMACC的本体映射 为了评估本文模型和算法的有效性,从不同单位建立的指挥信息系统测试评估指标体系中挑选50个指标体系转换成的本体模型,共计832个本体概念,进行基于机器学习多策略的本体映射实验。 本文共设计了三个实验,实验1对比基于PCA的本体概念相似度计算模型与基于树结构的相似度计算算法[18]、基于概念属性的相似度计算算法的效果,选取具有专家评价的140组本体概念对作为训练样本,选取10组作为测试样本;实验2测试不同聚类中心数的设定对本体聚类映射效果的影响,测试取0到40时本体映射的效果;实验3对比基于PCA和KMACC的本体映射方法与基于Hownet映射的映射方法、RiMOM方法、基于信息熵聚类的映射方法在50个本体数据上的映射效果并计算算法运行时间。 本文所有实验基于PC环境,实验系统配置为Intel Core i7、8 GB内存、Windows 8.1操作系统、Python 3.7环境。 本体概念相似度计算结果通常引入Pearson相关系数[19]进行评价,比较测试样本所计算出来的相似度与专家评价数据的一致性。Pearson相关系数计算式为: (13) 表1 Pearson相关系数强度 本体映射对于准确率有较高的要求,查全率R(Recall)与查准率P(Precision)是用来评价本体映射结果质量的重要指标[20]。其中查全率又称为完整性,代表映射过程中已经找到的正确结果占所有正确结果的比例。R=1意味着所有正确的映射结果都已经找到。查准率表示所有映射的结果中,正确的映射结果所占的比例,P=1意味着所有找到的映射结果都是正确的。最后使用准确率F1值来综合评价映射的效果,F1定义为: (14) 表2为实验1中三种算法的相似度计算结果与专家评价数据的Pearson相关系数。可以看出,基于PCA的相似度综合计算结果与专家评价结果之间的Pearson相关系数最大,达到极强相关;基于树结构和基于概念属性的相似度计算结果与专家评价结果之间的Pearson相关系数较小,都处于中等程度相关。实验结果表明,基于PCA的本体概念相似度综合计算模型在本文数据集上具有较好的计算效果,可以较为准确地计算出本体概念之间的距离,提高本体概念聚类算法的精度。 表2 三种算法计算结果的Pearson相关系数 图4为实验2中K-Modes聚类算法选取不同聚类中心个数k时,映射结果的准确率F1值。可以看出,当聚类中心数较少或者较多时都会影响映射的查全率和查准率。在本文数据集上,本体概念聚类映射的效果在k取19和20时达到最好,说明可以大致将本体概念划分为19或20个类别,将所有概念聚集到这19或20个类别时,可以较好地完成本体的映射,实验3中k值取为19。 图4 本体映射准确率F1与聚类中心个数的关系 图5为实验3中基于Hownet的映射算法、RiMOM算法、基于信息熵聚类的映射方法,以及基于PCA和KMACC的本体映射方法在本文数据集上的映射效果。可以看出,基于Hownet的映射方法的查准率较高,但是查全率较低,而RiMOM方法在查准率上存在一定的差距,基于信息熵聚类的本体映射方法在查全率和查准率上都存在较大差距。实验结果表明,本文提出的基于PCA和KMACC算法的本体映射在查全率和查准率上都取得了较好的效果。 图5 四种不同方法的映射效果 本文研究一种主成分分析和K-Modes蚁群聚类的本体映射方法。在基于PCA的本体概念相似度综合计算模型计算本体概念相似度的基础上,提出K-Modes蚁群聚类算法,实现批量本体概念映射关系的发现,有效提高了映射的准确性。实验结果表明,相比于基于Hownet的映射方法、RiMOM算法和基于信息熵聚类的本体映射方法,本文方法具有较高的查全率和查准率。下一步的工作主要是增强算法对不同样本的适应性,完成大量的指挥信息系统测试评估指标的映射和集成。
2.3 基于PCA和KMACC的本体映射方法
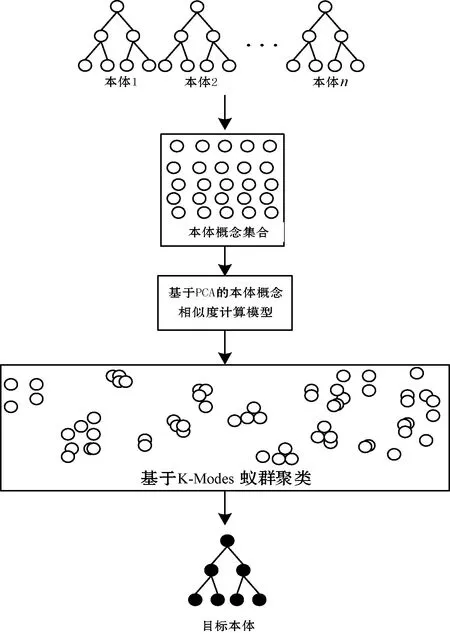
3 实 验
3.1 实验数据集与实验设计
3.2 评价方法


3.3 实验结果与分析



4 结 语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
吉林大学学报(信息科学版)(2021年5期)2021-10-26
计算机应用与软件(2021年7期)2021-07-16
哈哈画报(2021年10期)2021-02-28
舰船电子对抗(2017年6期)2018-01-11
互联网天地(2016年1期)2016-05-04
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
