
基于NLP的兴趣点数据上线系统设计与实现
2020-12-14 10:19张先荣郑贵俊
计算机应用与软件 2020年12期
张先荣 郑贵俊
(中国科学技术大学软件学院 安徽 合肥 230051)
0 引 言
地图位置POI数据在电子地图中扮演着重要角色。常见的电子地图中存在两种数据,一种是底图数据,另一种是地图位置数据——POI数据。底图数据一般在电子地图中描述大的轮廓,如哪一片是小区,哪一片是公园。底图数据一般在国家地理测绘局购买,这些数据不需要人为测量,由卫星照片合成。
一个电子地图的好坏一般是由POI数据决定。POI数据严格意义上属于向量数据,该数据与底图数据最大的不同是不需要描述建筑物或者实体的轮廓,在地图上呈现的是一个点的标注,这些点都是坐标点。如银行、餐厅和咖啡馆等,这些都可以用POI坐标表示,一般比较容易更新或者编辑。如果用面向对象的思维考虑POI数据,其属性应该包括:数据编号(Id),数据名称(Name),经度(Longitude),纬度(Latitude),国别(Country),省(Province),市(City),县区(County)和地址(Address)等。
因此,本文提出并设计一种POI数据采集与判重系统,利用程序实现自动数据采集,能够满足地图厂商实时更新的需要,尤其为企业节约了大量的成本,具有重要的工程设计价值意义。
1 研究现状
1.1 网络爬虫
本文系统的核心是数据采集与判重,数据采集技术主要是主题网络爬虫[1-2]。相对于全网爬虫,该技术更准确高效,目前主要有以下几类:
(1)基于内容的启发式方式。Best first search算法[3]:将需要采集的网页的URL加入到一个优先级队列中,队列的优先级是根据主题和网页内容的相关性计算的。Cho等[4]把等待采集的URL队列又细分成两个队列,一个队列叫作hot_queue,另一个叫作URL_queue。仅当hot_queue相关网页的数据采集结束之后,才开始采集URL_queue队列。算法缺点是当主题词比较多时,效率特别低。Fish search算法[5]:将待采集的网页看成一群鱼。如果有相关主题信息,鱼就有“食物”,鱼有了“食物”就会“繁殖”。没有相关主题信息,鱼则会出现死亡。算法的缺点是相关度计算设置成离散,计算不够准确,相关度相同的网页容易被忽略掉。Shark search算法[5]继承了Fish search 方法,相关度度量方法不是利用离散值,而是利用0~1之间的相关度。在计算相关性时,还充分利用了锚文字。这样能更好地提高爬行方向的正确性。
(2)基于超链图方式。Page Rank算法[7]利用一个网页的重要性传递到了它所引用的网页,因此它被称为权威网页。
(1)
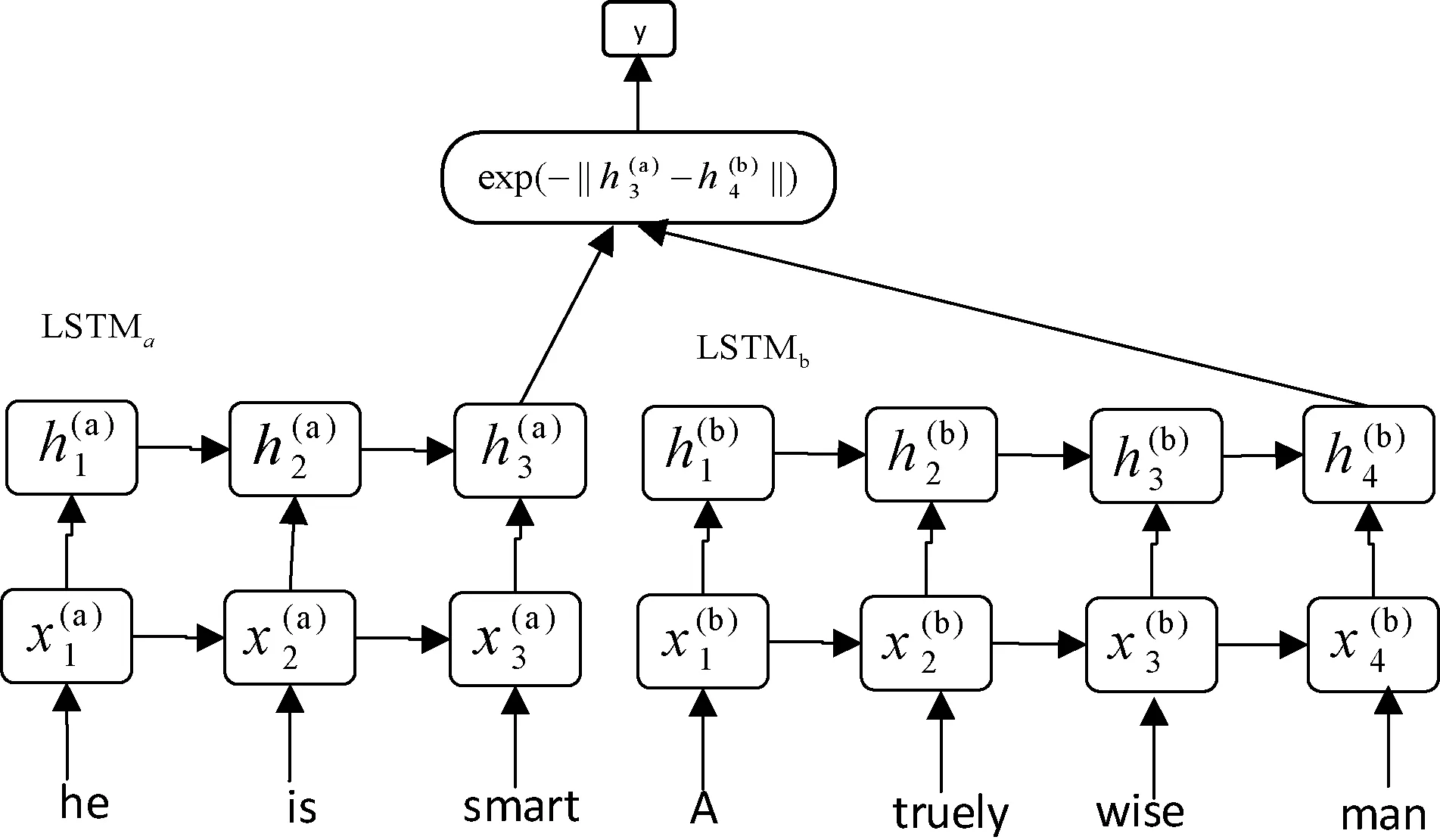
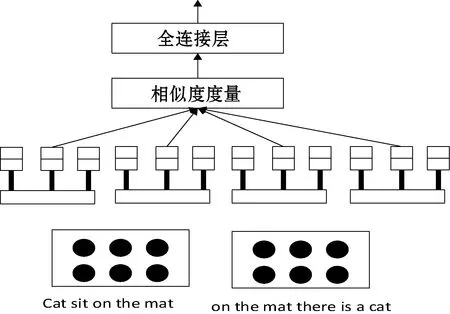
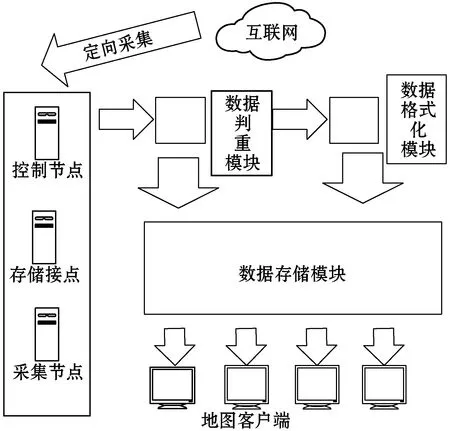
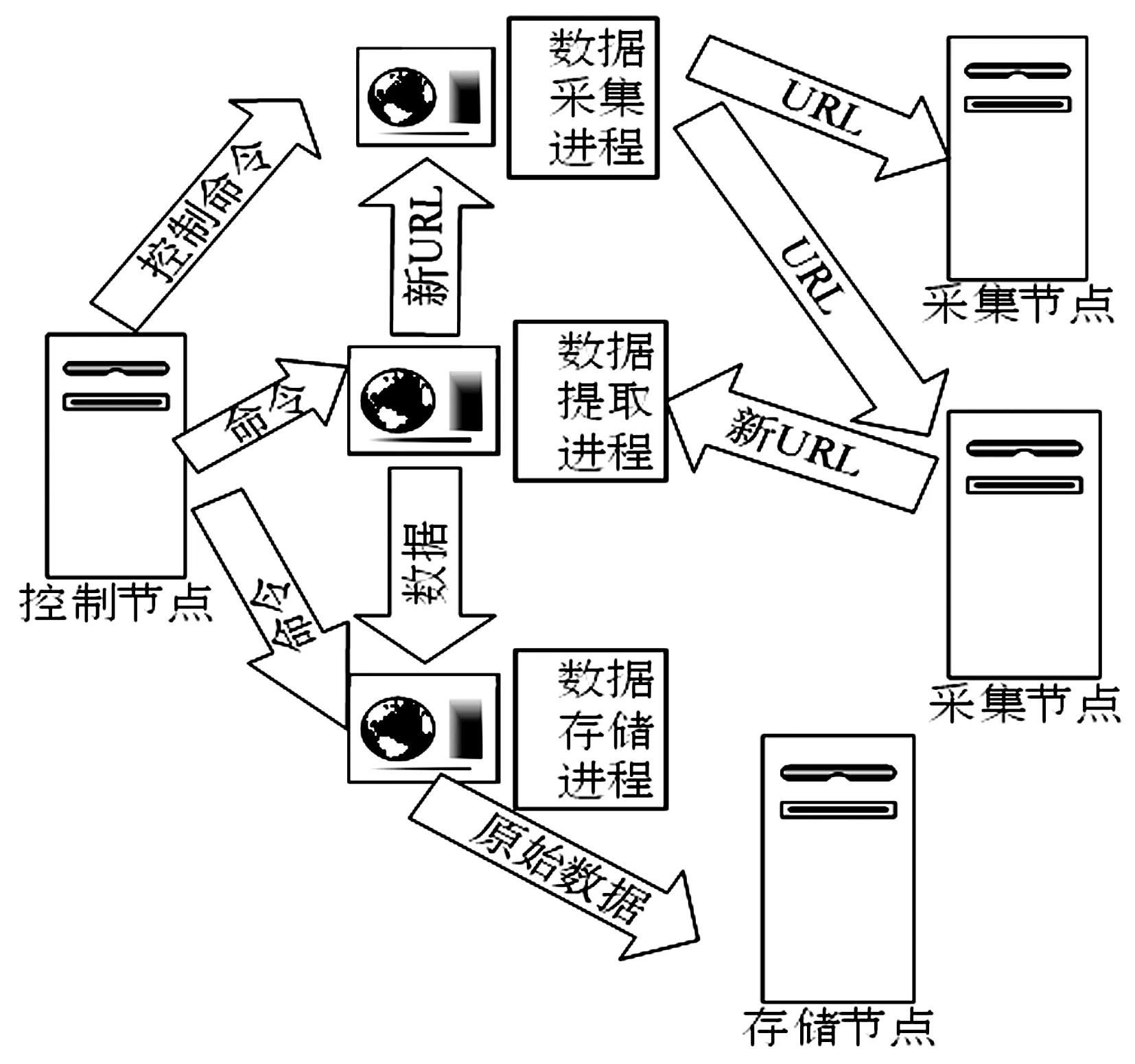
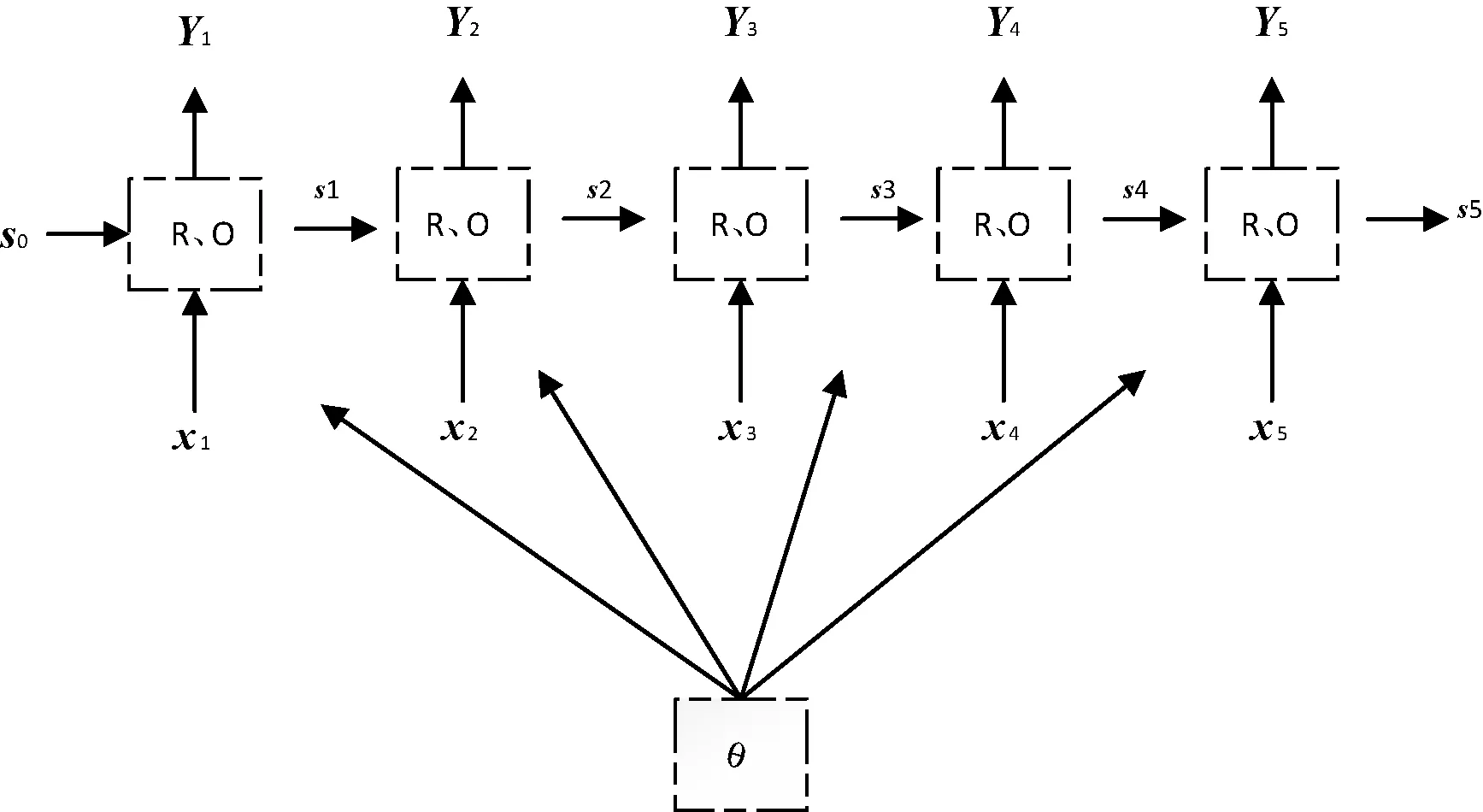
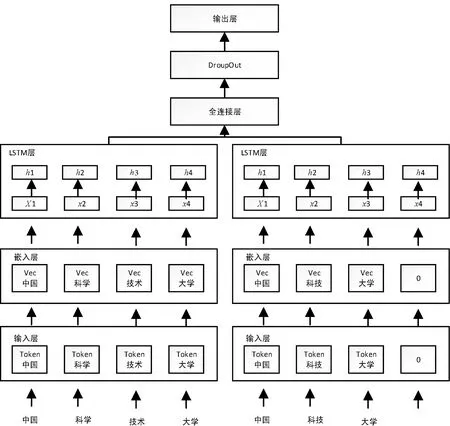
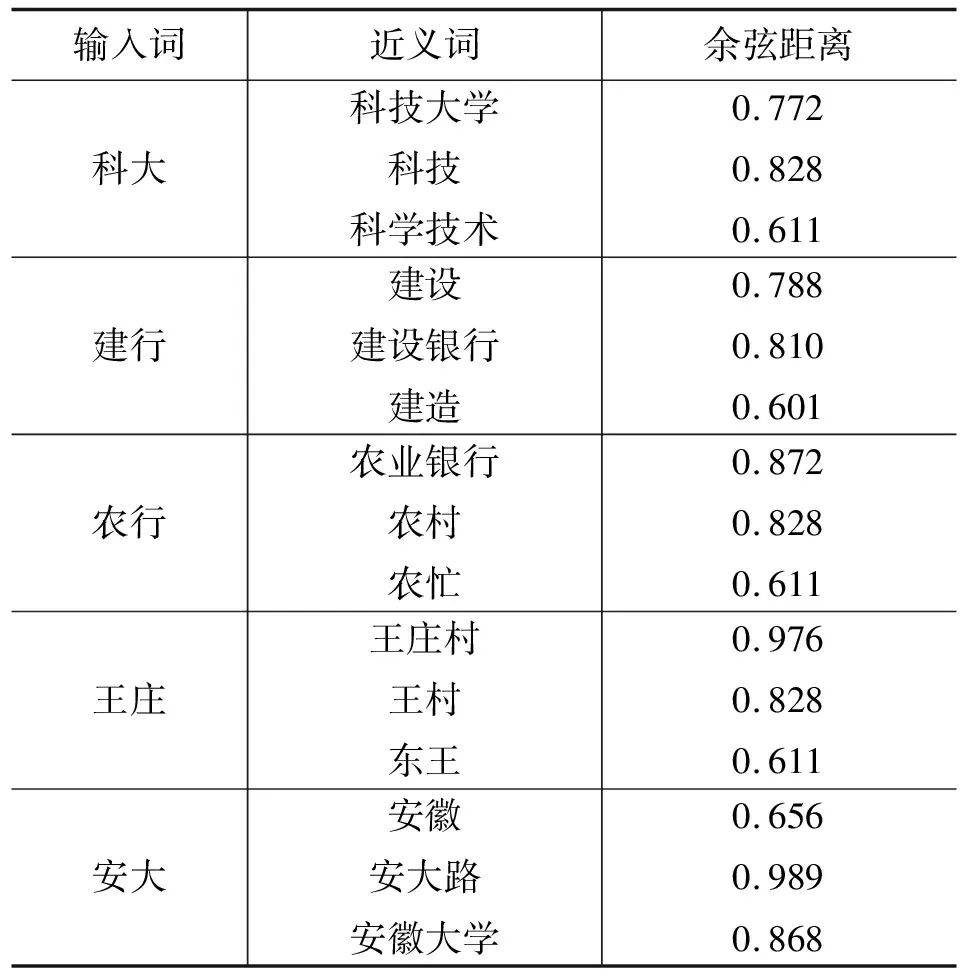
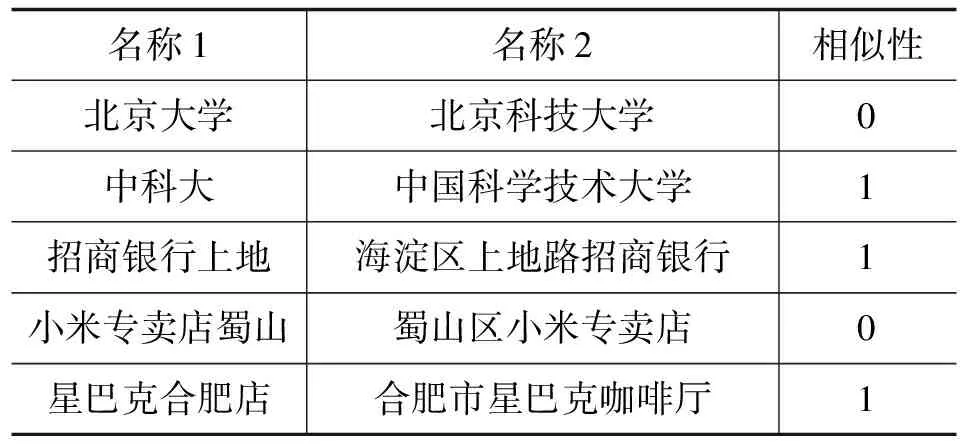
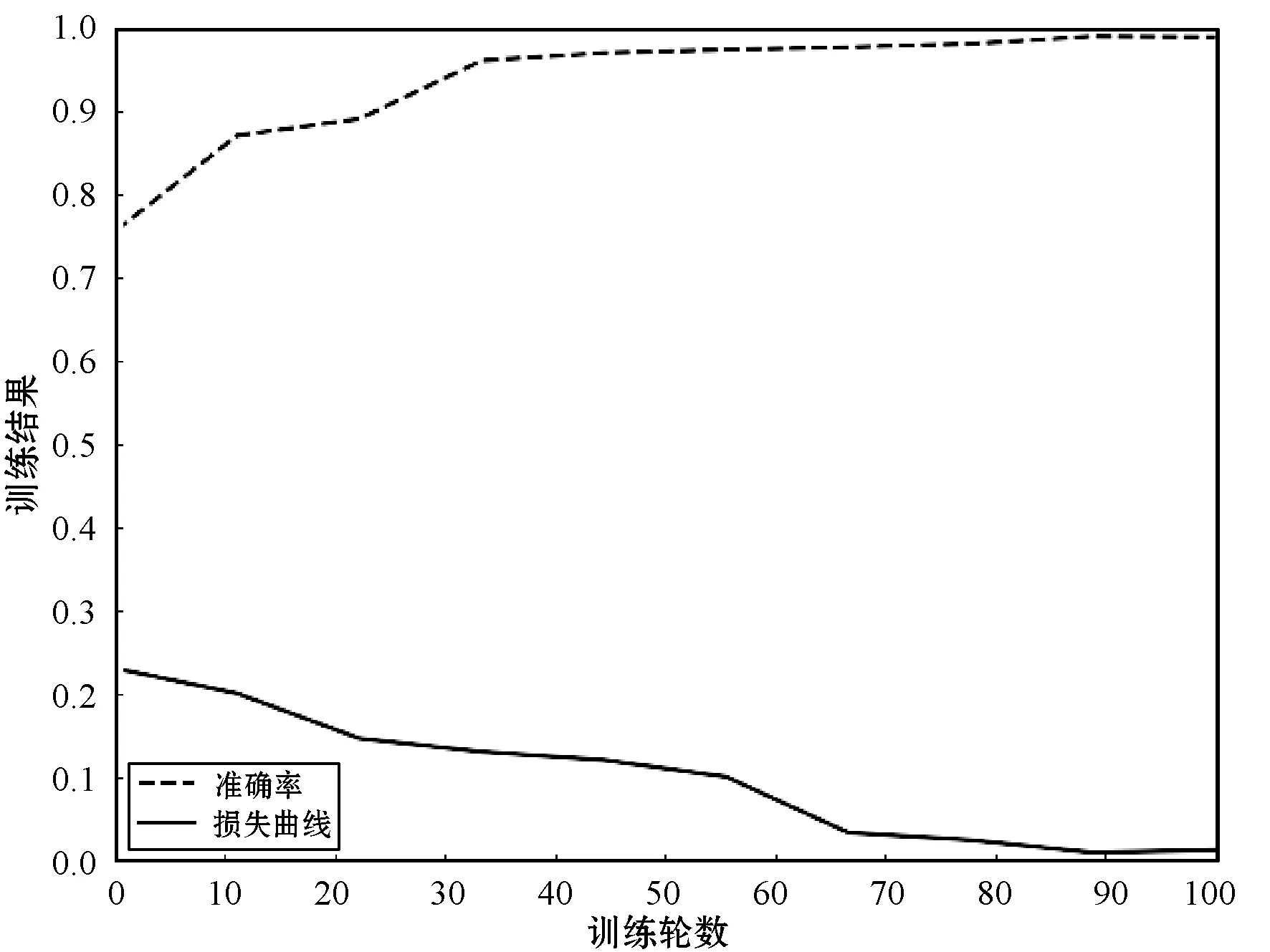
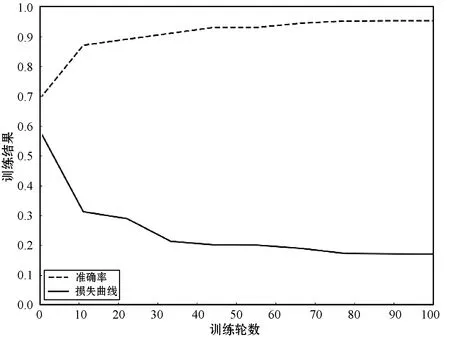
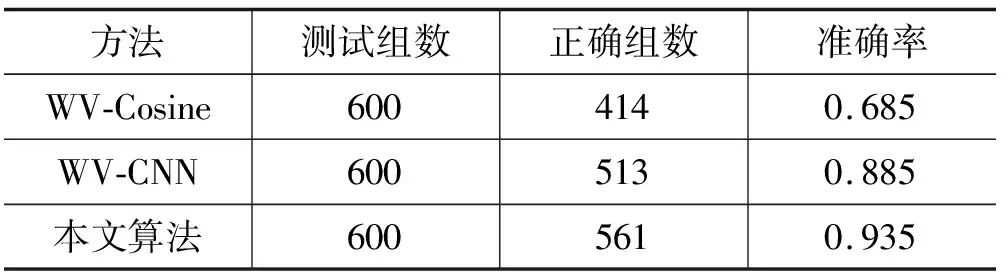
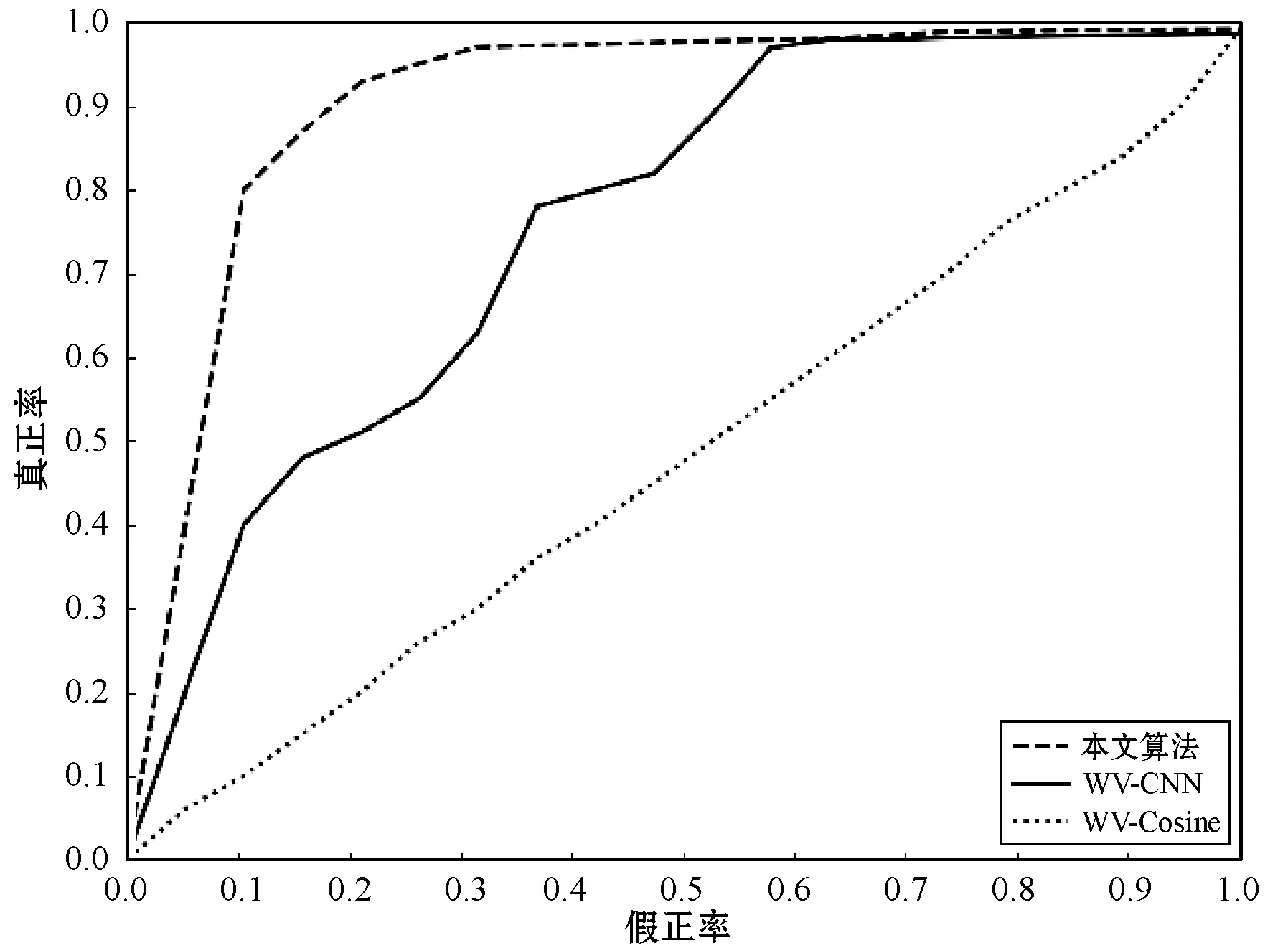
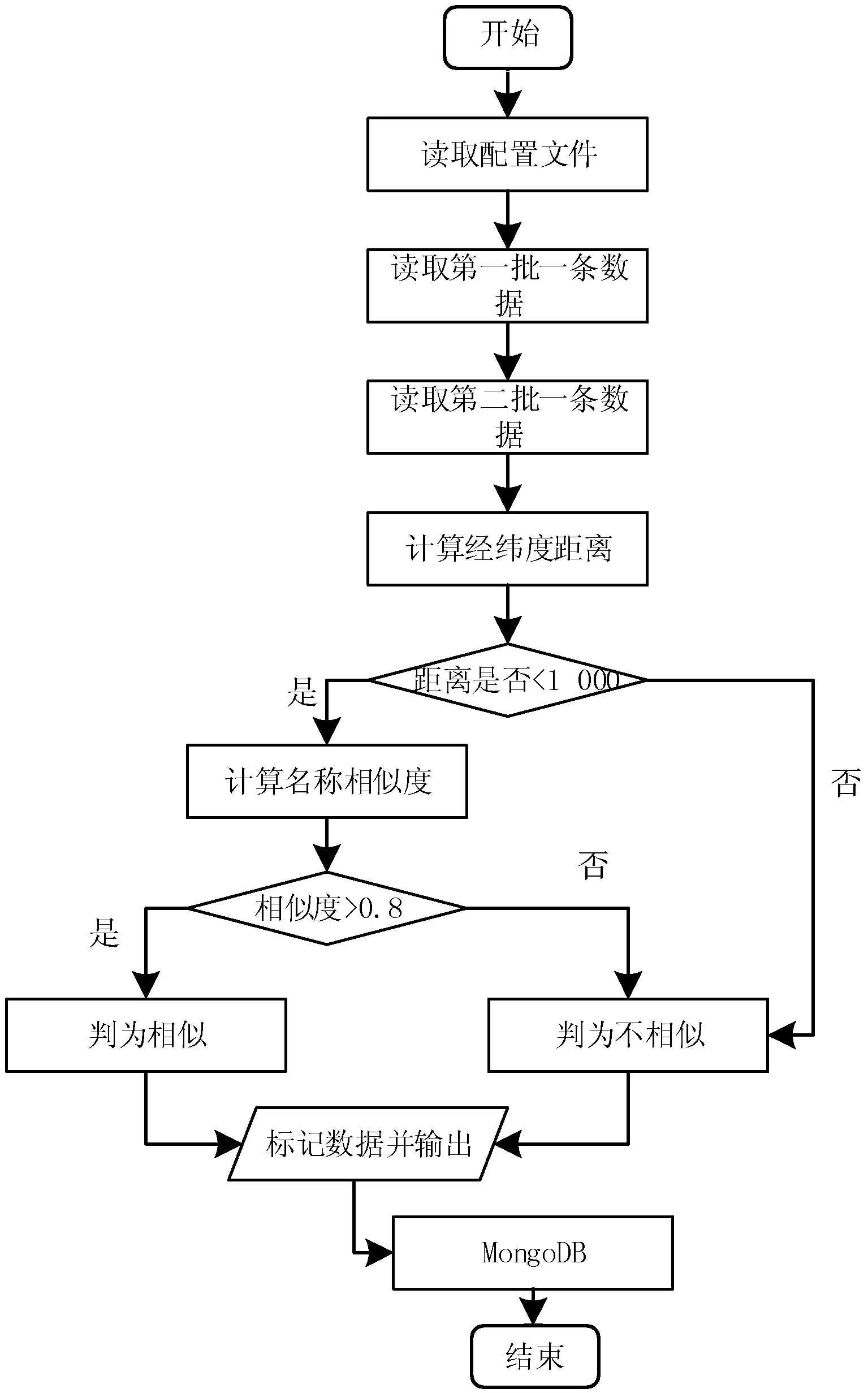
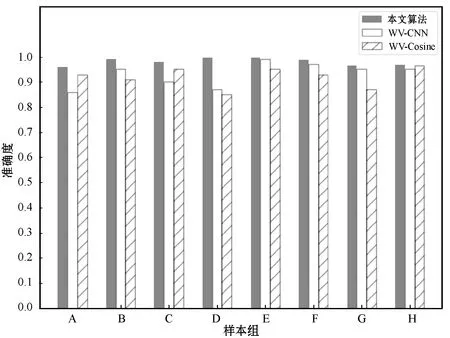
式中:B(i)表示那些指向网页i的网页;N(j)表示网页j指向的其他网页的数目;R(i)表示i这个网页的权威度;R(j)表示网页存在指向网页i的链接,网页在上一次迭代时的Page Rank值;d(0 (1)基于字符串。设两个文本分别是X(x1,x2,…,xn)和Y(x1,x2,…,xn),则计算文本距离的公式如下: 余弦相似度: (2) 曼哈顿距离: (3) 欧氏距离: (4) 由于仅是从字面的层次上进行比较,运行速率快,但没有考虑文本中词与词之间的顺序关系、语义关系,所以不能有效地识别近义词。 (2)基于向量空间。将两个文本编码后看成向量空间[9]中的两个向量,通过余弦距离计算相似度。TF-IDF[10]中的TF指的是“词频”,IDF指的是“逆文本频率”,公式如下: TF-IDF(Wi)=tfj(Wi)×log(N/df(Wi)) (5) 式中:tfj(Wi)表示Wi这个词在文档j中出现的频率;N表示的是文档的总数;df(Wi)表示有多少个文档中出现过Wi这个词。通过将所有的文档都进行分析,然后可以得出每一个词的TF-IDF值,利用这个值可以对所有文档中每个词进行编码。Word2vec[11]模型分为两种:一种是CBOW,另一种是Skip-grim。CBOW利用词Wi前后的各m个词预测Wi,而Skip-grim则刚好相反,它利用Wi预测前后m个词。这两种模型的训练比较相似,这里主要讨论CBOW。输入层是2m个词向量,投影层是2m个向量的和。输出层是语料库中所有的词为叶子节点,词的出现次数为权值的哈夫曼树,通过随机梯度下降算法对投影层进行预测,使得条件概率公式p(Wi|context(Wi))最大化,其中context(Wi)指的是Wi的上下文2m个词。训练结束就得到了每个词的编码。 图1 孪生LSTM 孪生CNN[13]模型采用孪生卷积神经网络结构,分别对两个句子进行建模,然后利用一个句子相似度测量层计算文本相似度,最后通过一个全连接层输出相似度得分。其结构如图2所示。 图2 孪生CNN 本文系统的采集模块,以一定的种子URL开始,通过主题分析以及深度优先搜索、广度优先搜索等策略,确定待采集的URL。常见的分布式数据采集器框架主要分为控制节点、数据采集节点、存储节点。控制节点包括URL管理器、数据存储器、控制调度器。数据采集节点包括HTML下载器、HTML解析器、数据采集调度器。存储节点主要是MongoDB,负责数据增改删查。数据采集、格式化、存储结束,一定时间后需要对数据更新和判重。系统整体架构如图3所示。 图3 整体架构设计 网络数据采集功能通过主题网络爬虫实现。与传统网络数据采集不同,采集模块用分布式以及多进程提高采集效率,多台主机可协同采集数据。数据采集节点架构图如图4所示。 图4 数据采集节点架构图 1)控制节点: (1)控制节点的URL管理器。主要包括两个集合,一个集合是已采集URL的集合,另一个是未采集的URL的集合。如果重复采集URL,根据Best first search算法会出现死循环。 URL去重复主要有如下解决方案:① 内存去重;② 关系数据库去重、缓存数据库去重。大型成熟的网络数据采集系统采用缓存数据库去重的方式,这样可以尽可能避免内存的限制。URL管理器是本文系统重要的模块,直接影响着最后数据的召回率。定义一个优先级队列,运用Page Rank算法计算优先级,按照优先级大小顺序进行采集。对于上千万条URL,URL又非常长,需要做MD5处理,以防止内存溢出。MD5的信息摘要是128位,可以减少好几倍的内存消耗。不过Python的MD5值是256位,所以取前128位即可。 (2)控制节点的数据存储器。主要功能是将解析出来的数据,批量放入文本文件或者HTML文件。文件名以日期命名,文件格式主要是以Key-Value形式保存。 (3)控制节点的调度控制器。调度控制器主要是产生并启动URL管理线程、数据提取进程、数据存储进程,同时维护4个队列保持进程间通信。URL_q队列是URL管理进程将URL传递给数据采集节点的通道。Result_q队列是数据采集结点将数据返回给数据提取进程的通道。Conn_q是数据提取进程将新的URL数据提交给URL管理进程的通道。Store_q是数据提取进程将取得的数据交给数据存储进程的通道。URL管理进程从Conn_q队列获得新的URL提交给URL管理器,经过去重之后,读取URL放入URL_q队列中传递给数据采集节点。数据提取进程从Result_q队列读取返回数据,并将队列中的URL添加到Conn_q队列交给URL管理进程。数据存储进程从Store_q中读取数据并调用数据存储器进行存储。 2)爬虫数据采集节点:数据采集节点主要包括HTML下载器、HTML解析器、数据采集调度器。执行流程如下:首先数据采集调度器从控制节点中的URL_q读取URL;然后数据采集器先调用HTML下载器获得网页的源代码,再从源代码中解析出新的URL;最后数据采集调度器将新的URL和摘要传入Result_q队列并交给控制节点。 (1)数据采集节点的HTML下载器。主要利用HTTP协议向服务器发送请求,从服务器返回的数据中得到有用的数据。客户端向服务器发出请求,请求建立TCP连接。服务器对数据采集器作出响应,并把对应的HTML文本发送给数据采集器,然后释放TCP连接,数据采集器将HTML文本保存。 (2)数据采集节点的HTML解析器。HTML解析器是通过Xpath或者BeautifulSoup解析出有用的数据。 (3)数据采集节点的采集调度器。数据采集节点的调度器需要先连接上控制节点,然后从URL_q中获取URL,下载并解析网页。再把获得的文件交给Result_q队列并返回给控制节点。这里需要用到分布式进程——服务进程的创建以及客户进程的创建。 3)采集模块的存储节点:实现数据持久化存储。 断点续传也是网络爬虫设计难点。一个数据采集程序一旦启动就必须等它运行完,如果中途中断就前功尽弃,这样的数据采集程序系统是非常不健壮的。由于不可控因素无法预料,中间会因各种原因中断,如某些数据量大的网站需要采集很长时间,中途可能会遇到断电、网页请求超时、程序崩溃、网页请求频繁被禁止等问题。健壮的网络数据采集系统应该是随时都可以启动,而且每次启动都是从剩下的开始而不是从头开始重复采集。解决该问题的一种策略是记录日志,对于采集失败的URL放入日志记录,采集一轮结束后,程序遍历日志记录,再次采集日志记录中采集失败的URL。如果采用该日志策略,可能会出现某几个URL总是采集不成功,程序可能会陷入死循环。另一种策略是URL输入两个队列,一个队列存储采集过的URL,另一个队列存储未采集的URL,此时就实现了断点续传。断点续传流程设计可使网络爬虫程序可以随时停下,随时启动,并且每次启动都不会做重复工作。 对于主题爬虫,为了加速主题网站的采集速率,本文系统采集模块改进了常见的网络爬虫请求方法以提高采集效率。不同数据品牌采用多进程,品牌内采用多线程。受TCP拥塞控制启发,设计出线程回退算法自动化调整线程数量。该算法描述如下: (1)增长阶段:该阶段按照指数规律分配线程的数量。在线程数量指数增长节点,每次分配线程数量结束,在一定的时间窗内检测爬虫是否稳定。剔除检测到的异常的线程,并将下一个时间窗口设置为当前线程数量的一半。 (6) 式中:Nt+1表示下一个时间窗口的线程数;Nt表示当前时间窗口的线程数;state表示当前是否异常,值为0表示异常,值为1表示正常。 (2)衰减阶段:在该阶段表示以线性规律增加或者减少线程数。经过一定的时间窗口,检测网络爬虫是否异常,正常则线性增加线程数,异常则线性减少线程数。 (7) (1)RNN。循环神经网络可以将任意长度的序列映射成定长的向量,捕获线性序列的特征非常有效[13],则RNN是将n个din维向量X1:n=X1,X2,…,Xn(Xi∈Rdin)序列作为输入返回单个dout维向量yn∈Rdout的函数。 yn=RNN(x1:n)xi∈Rdinyi∈Rdout (8) 式(8)隐式定义了:每一个输出向量yi,可以将返回输出向量序列的函数记为RNN*: y1:n=RNN*(x1:n)yi=RNN(x1:i)xi∈Rdinyi∈Rdout (9) 构建一个循环神经网络类似于构建一个前馈网络。必须指定输入向量xi和输出向量yi的维度: RNN*(x1:n;s0)=y1:nyi=o(si)si=R(si-1,xi)xi∈Rdinyi∈Rdoutsi∈Rf(dout) (10) 式中:o(·)是激活函数;si是隐层单元输出;R(·)是处理隐层单元的线性函数。加入参数θ强调时间步的相同,不同的R、O实例会得到不同网络结构,如图5所示。 图5 RNN图形化表示 (2)长短记忆网络(LSTM)。长短记忆网络用于解决梯度消失问题[15],并且引入了门结构。将状态向量Si分解成记忆单元和运行单元,记忆单元设计为跨时间记忆并保存相关梯度信息,同时由平滑数学函数控制。形式化定义如下: (11) 式中:sj是时刻j的状态;RLSTM(·)是LSTM算法模型函数;⊙是hadamard乘积操作;W为LSTM模型待更新的权重矩阵。因此,时刻j的状态由上一时刻sj-1和第j时刻的x得出。时刻j的状态由两个向量组成,分别是cj和hj。其中,cj是记忆组件,hj是隐藏状态组件。有三种门结构i、f、o,分别控制输入、遗忘和输出。门的值由当前输入xj和前一状态hj-1的线性组合通过Sigmoid激活函数σ(·)得到。一个更新候选项z由xj和hj-1的线性组合经过一个非线性激活函数tanh得到。 各个值取值范围如下: sj∈R2·dhxi∈Rdxcj,hj,i,f,o,z∈RdhWxo∈Rdx×dhWho∈Rdh×dh (12) (3)Word2Vec。Word2Vec有2种模型:连续词袋模型(continuous bag-of-words model,CBOW)和Skip-Gram。本文使用的是CBOW模型。 (4)POI相似度模型。以Simase-LSTM设计短文本相似度模型,如图6所示。该模型由输入层、词嵌入层、Simase-LSTM层、全连接层以及输出层组成。将两条POI数据的Name字段首先进行分词,建立词库字典,以字典中的位置进行初始编号,输入词嵌入层用Word2Vec进行计算,得到一组向量。部分词向量效果如表1所示。 图6 短文本相似度模型 表1 部分词向量效果 统一长度后输入Simase-LSTM。学习结果进行拼接。采用简单的单层LSTM+全连接层对数据进行训练,两个LSTM的输出拼接后作为全连接层的输入,经过Dropout和Batch Normalization正则化,最终输出结果进行训练。 数据采集之后,需要对数据进行格式化处理,一般POI数据的格式是JSON形式,这种由多个Key-Value形式组成的一条数据便于数据的处理和研究。大多数网页的原始数据都是这种形式。 直接把数据处理程序包含在数据采集模块的实现方式虽然易于实现,但是仔细分析后会发现众多问题。该编程方式增加了程序模块间的耦合度,违反了软件工程的高内聚低耦合的标准,会导致原始数据丢失,比如在数据上线之后数据出现差错,是原始网站的错误还是编程导致的错误无法定位。另外,程序开发完成后,需要对所有数据修改一个属性,如将“经度”与“纬度”合成一个属性“经纬度”,那么就需要一个一个地修改所有的网络爬虫代码,显然这种方式是不明智的。 可以用一种改进的编程方式,即使用设计模式中的工厂模式就可以解决上述所有问题,将“工厂”单独抽象出来一个格式化模块,该格式化模块包含一个数据配置信息映射表和一个映射程序。每一个主题的数据,将是否缺属性、缺哪个属性、属性的映射、原始数据的存储地址都事先写入映射表中,通过该方式将千变万化的数据统一成一种格式,既有利于降低耦合,又有利于批量操作数据,使得系统更加健壮。 图7是根据目标分析出的数据格式化模块的程序流程图。 图7 POI数据格式化流程图 已入库并且已经格式化的数据,经过3个月需要进行一次重新的数据采集与判重上线。 得到两批POI向量数据后,首先循环遍历第一批数据,对于第一批每个数据,如ODi,循环遍历计算第二批数据NDj与第一批数据ODi的距离,找出与ODi距离小于1 000米的数据集合LODi,该集合中每条数据的Shop_name、Address与ODi的Shop_name,Address使用POI相似度模型比较并打分,分数最高的一条第二批数据NDl即为关联数据。 假设第一批数据数量为M,第二批数据数量为N,其中M和N大小不确定,那么执行判重算法后,关联数据列表List的长度一定小于M并且小于N。设关联数据条数为L,则这L条数据既存在于第一批数据,又存在于第二批数据,并且是第一批数据和第二批数据的交集,设为D。则第一批数据中不在D内的数据应下线,第二批不在D内的数据应上线。 算法1POI数据判重算法 1.List=[]; 2.For ODi←第一批采集数据; 3.For NDj←第二批采集数据; 4.If Distance(ODi, NDj)<1 000: 5.NameScore=Compare(name(ODi,NDj)); 6.AddressScore=Compare(addre(ODi,NDj)); 7.TotleScore=0.8 * NameScore + AddressScore * 0.2 8.找出与ODi比较后totleScore最高的ODj。 9.ODi,ODj一起存入List 10.Return List 为了验证本文方法的可行性,分别对单线程网络爬虫、多线程网络爬虫、多进程网络爬虫,以及本文提出的自适应分布式网络爬虫进行对比实验,表2为实验环境的参数。 表2 实验环境 实验将数据品牌“劳力士表”“中国建设银行”“特斯拉汽车”“星巴克咖啡厅”“爱马仕”“小米”“华为”“学校”等8种品牌网站进行编号,如表3所示。 表3 网站品牌 数据采集实验:将本文提出的负载均衡自适应算法应用到多线程以及本文设计的分布式爬虫系统上,得到如图8所示的实验结果。 图8 POI数据采集性能对比图 在刚开始采集阶段,多线程的采绩效率明显高于其他方案,在采集60分钟之后,由于源网站反趴策略的限制,效率开始下降。自适应分布式采集策略趋于稳定。 (1)数据集的构造。将从表3中采集到的8类品牌数据随机取出3 000条,标注是否相似,1代表相似,0代表不相似。样本示例如表4所示。 表4 实验环境 (2)模型训练。把2批6 000条数据按照7∶2∶1分为训练集、验证集、测试集。使用梯度下降法更新神经网络权值。batch_size是每块训练样本数,本文系统中为15,每次对15个参数进行训练。Epochs参数是迭代次数,本文系统中为100。 如图9所示,模型的训练损失每轮都在下降,准确率每轮都在上升,达到80轮之后,呈现稳定状态。准确率达到98%,损失函数降至1.3%。 图9 模型训练结果 (3)模型验证。如图10所示,达到80轮之后,模型在验证集上准确率达到95.2%,损失函数值降至17%。 图10 模型验证结果 (4)模型测试。除了使用本文介绍的Word2Vec结合LSTM方法,实验还对比了Word2Vec结合CNN方法、仅用Word2Vec方法。以下简称本文算法、WV-CNN、WV-Cosine。其中WV-Cosine指的是将短文本用Word2Vec编码后直接用COS函数计算短文本相似度。各方法在测试集上的性能如表5和图11所示。 表5 多种算法在测试集上的准确率比较 图11 模型ROC曲线 本文模型在准确率和ROC曲线[16]上的表现优于其他算法。WV-Cosine算法效果最差,因为Word2Vec虽然解决了词语间语义关系的问题,但是其类似于词袋模型,简单地把词语向量堆积组成文本向量,往往会造成误判。虽然WV-CNN有较高准确率,但不适用于序列化文本的处理。对于文本处理LSTM更有优势。由于计算的相似度是介于[0,1]之间的浮点数,因此需要规定阈值,这里定义相似度小于0.8,算法判断为不相似,相似度大于0.8,算法判断为相似。这样就可以计算真正率与假正率。 从图11中ROC曲线看出,本文提出的短文本相似模型具有最佳性能。 (1)判重算法的基本流程。三个月前采集一批数据,现在采集一批数据,为了保证电子地图实时更新,需要将第一批没有的数据识别出之后上线。两批数据的交集不用上线。基于短文本相似度的POI判重算法的目的就是找到两批数据的交集。流程如图12所示。 图12 POI数据判重算法 (2)判重算法性能比较。将短文本相似度算法分别换成WV-CNN、WV-Cosine,与本文的算法性能对比如图13所示。 图13 POI数据判重算法性能对比 由图13可得,本文提出的算法更具有稳定性,在各类品牌上的准确率均保持在95%以上。 系统采用自适应分布式爬虫技术从银行、小米手机店、汽车4S店等官方网站采集电子地图的POI数据,经格式化模块补全属性后进行上线。经过一定时间重新采集数据、判重上线。后端使用MongoDB存储数据。主要功能包括数据抓取、数据格式化、数据判重、数据入库。腾讯地图、高德地图等地图厂商可使用本文思想自动化更新数据。以下是系统实现后得到的数据例子: (1)原始数据例子。从魅族手机官方网站抓取的一条营业厅的数据。 {″province″: ″四川省″, ″name″: ″四川宜宾授权服务体验中心″, ″city″: ″宜宾市″, ″address″: ″四川省宜宾市翠屏区东街经纬商场9楼8号″} (2)格式化数据的例子。由于原始数据可能会缺少字段,如原始数据例子中没有经纬度信息,在格式化模块需要用百度地图工具API将″四川省宜宾市翠屏区东街经纬商场9楼8号″这条地址信息转换成经纬度信息,并加上唯一ID号。 {″province″: ″四川省″, ″thirdId″: ″3 326 575.453 603 036″, ″name″: ″四川宜宾授权服务体验中心″, ″city″: ″宜宾市″, ″longitude″: ″11 648 275.596 548 6″, ″address″: ″四川省宜宾市翠屏区东街经纬商场9楼8号″, ″latitude″: ″3 326 575.453 603 036″} 这样就可以将这条数据上线到腾讯地图App中。 (3)数据的判重例子。数据上线到腾讯地图App中,3个月以后,腾讯地图App的数据上线人员再次运行爬虫程序,抓取同样的数据,发现原始数据“name”字段有变化,如: 三月前:″name″: ″四川宜宾授权服务体验中心″。 现在:″name″: ″魅族官方授权服务体验中心(四川宜宾店)″。 可能经纬度也有变化,上线人员可以认为这个营业厅可能搬至别处。因此,可以运行本系统的判重算法,通过经纬度计算,得到此时POI数据与三月前同一POI数据距离″distance″: 65.939 936 304 486 3,即65米。旧name(即″oldname″: ″四川宜宾授权服务体验中心″)与新name(即″name″: ″魅族官方授权服务体验中心(四川宜宾店)″)相似度分数为″score″: ″0.731 213″。因此可以判断该条数据与三个月前那条数据是同一条数据,仅让新采集的未找到关联的数据上线即可。 {″province″:四川省″, ″distance″: 65.939 936 304 486 3, ″sametype″: ″diff″, ″thirdId″: ″3 326 575.453 603 036″, ″oldname″: ″四川宜宾授权服务体验中心″, ″city″: ″宜宾市″, ″longitude″: ″11 648 275.596 548 6″, ″score″: ″0.731 213″, ″name″: ″魅族官方授权服务体验中心(四川宜宾店)″, ″address″: ″四川省宜宾市翠屏区东街经纬商场9楼8号″, ″latitude″: ″3 326 575.453 603 036″, ″guid″: ″fd3fcb4e-a2a4-11e7-a06b-6c92bf270e68″} 本文提出并设计的系统很好地解决了地图App的数据来源问题,全程自动化处理,具有很好的用户体验。但在以下方面也有值得改进的地方: (1)运行效率。虽然本文系统在目前来看,运行速度还算可以,但是数据量如果加大,效率还有待提高。由于本文系统是面向过程设计的整体架构,因此,一个功能模块不稳定,就会让后期数据处理无法执行。 (2)算法的准确率。NLP的文本相似度算法的准确率一直在0.93左右,所以算法准确率的提高有待进一步研究。1.2 短文本相似度
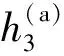
2 设计研究思路
2.1 分布式采集架构
2.2 数据质量管理
2.3 负载均衡
2.4 相关算法
2.5 POI数据格式化流程
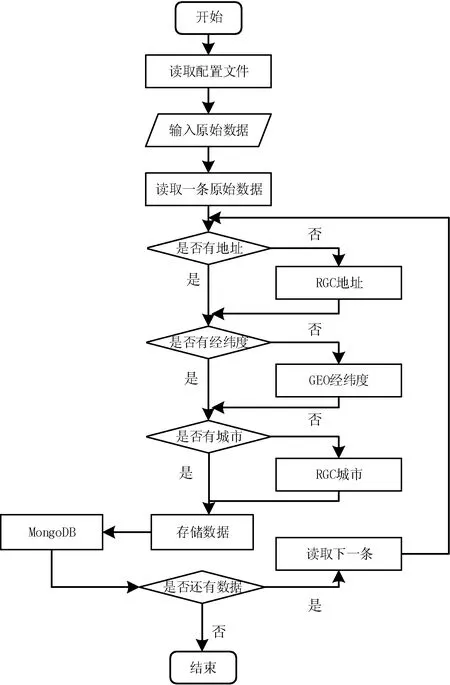
2.6 POI数据判重算法
3 实验与分析
3.1 分布式系统数据采集性能
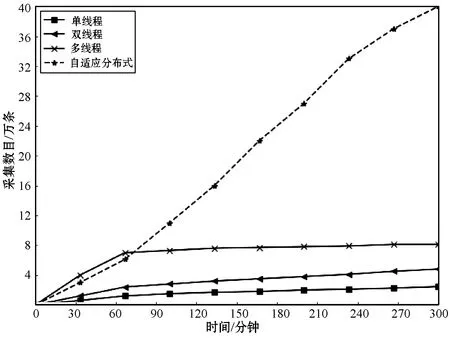
3.2 POI数据的短文本相似度算法
3.3 基于短文本相似度的POI判重算法
3.4 系统实验实例
4 结 语
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
智能计算机与应用(2018年5期)2018-10-20
魅力中国(2018年5期)2018-07-30
电脑知识与技术·经验技巧(2018年1期)2018-05-30
