
改进型深度学习模型在乳腺肿瘤良恶性鉴别中的应用
2020-12-12 04:04:02邓竹琴俞永伟
中国医学物理学杂志 2020年11期
邓竹琴,俞永伟
1.中国人民解放军联勤保障部队第901医院妇产科,安徽合肥230031;2.安徽省合肥市长荣医院普外科,安徽合肥230001
前言
乳腺癌是临床上常见的癌症,具有发病率高、死亡率高和治愈率低等特点。据不完全数据表明,全世界乳腺癌的发病率在稳步上升,其中美国女性乳腺癌的发病率更是高达12.5%[1-2]。虽然我国乳腺癌的发病率较低,但最近几年我国女性患乳腺癌的数量在逐年上升,成为近年来发病率最高的恶性肿瘤之一[3]。临床中医生根据彩超、X 线、核磁共振等对患者进行诊断,但病理图像具有更丰富的形态信息,是医生确诊的重要方式。目前病理医生进行病理图像分类时主要依靠图像中细胞形状和分布进行分类。但诊断结果容易受病理医生经验和学识的影响。近年来,深度学习的兴起,使其在医学图像处理方面大放异彩[4-5]。在乳腺癌组织病理图像分类中深度学习分类方法与传统分类方法相比准确率提高了6%[6]。虽然识别准确率提高了6%,但识别精度依然不足。针对精度不足的情况,本文通过对Visual Geometry Group-16(VGG-16)卷积神经网络的模型进行改进,提出基于VGG-16 卷积神经网络的改进模型(VGG-Improve 卷积神经网络模型)。该方法可以解决VGG-16网络过深,参数过多,收敛速度慢,训练困难等问题。另一方面采用数据增强的方法提高了模型的泛化能力和鲁棒性。
1 方法
1.1 VGG-Improve卷积神经网络模型
VGG-Improve 卷积神经网络模型由7 个卷积 层和2个全连接层组成;用ReLU函数作为激活函数,在加强网络非线性映射能力的同时,也可以提高网络收敛速度[7-8];使用正则化函数,通过对损失函数增加惩罚项,降低过拟合的风险[9];用均值池化层,减少图像细节丢失,避免了最大池化丢失局部细节。
本文使用VGG-Improve 卷积神经网络模型对乳腺癌病理图片进行训练,并与同类型文献提出的卷积神经网络进行对比。VGG-Improve 卷积神经网络模型的结构图如图1 所示[10-11]。第1 层为图像输入,输入的尺寸为224×224;第2 层为64×3×3 的卷积核,第3 层为64×3×3 的卷积核;第4 层为均值池化层,池化域为2×2;第5~7 层与第2~4 层相同;第8~10 层由3个64×3×3 的卷积核组成;第11 层为均值池化层,池化域为2×2,每一个卷积核都使用正则化;第12~13层为两个全连接层,连接参数分别为512和256,每个全连接层后面都进行正则化。最后一层使用Softmax分类器,其中卷积层和全连接层均使用ReLU 激活函数,卷积层的步长为1×1,池化层步长为2×2,全连接层的步长为2×2。
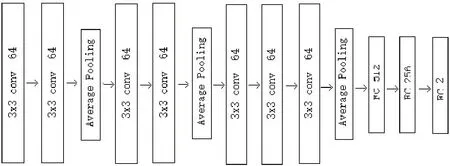
图1 改进型卷积神经网络模型Fig.1 Improved convolutional neural network model
1.2 正则化
训练神经网络的过程中,由于数据集不足,模型选取不当等原因,容易造成过拟合。使用正则化能有效防止过拟合,使训练好的模型在训练集和测试集上都有很好的准确率。常见的正则化分为L1正则化和L2 正则化。L1 正则化是将权值向量W中各个元素的绝对值求和。L1正则化可以改变权值矩阵W的稀疏性,将W中部分元素变为零。通过改变W的稀疏性减少了计算量,在一定程度上可以减少模型过拟合的概率。L2正则化是将权值向量W中各个元素进行平方和再求平方根。使得模型的解偏向于范数较小的W,通过限制W范数的大小实现了对模型空间的限制,从而在一定程度上避免了过拟合。但L2 正则化不具备稀疏化的特性,计算量并没有得到改观,但相较于L1 正则化L2 正则化对过拟合的抑制效果更加明显。本文采用L2正则化防止出现过拟合情况。L1 正则化和L2 正则化公式定义如式(1)和式(2)所示:

其中,loss 为原始的损失损失值,C为惩罚系数,w为权重参数,lossnew为新生成的损失值。
1.3 数据增强
由于本研究临床数据集数据较少,无法提供大量带有标记的样本,容易在训练中造成过拟合现象。针对上述问题,本文对原有的样本进行数据增强,数据增强的方式如下:(1)旋转,将图像在0~60°范围内随机旋转。(2)图像缩放,将图像按照一定比例进行放大或缩小。(3)平移,将图像向x 或y 方向移动。(4)增加噪声,通过加入噪声数据抵消高频特征,抑制过拟合发生。经过数据增强后,不但增加了训练样本,还会增加模型的鲁棒性。另外本文还对图像进行归一化处理,处理后的数据能防止出现“梯度弥散”现象[12-13]。通过数据增强,使样本扩大为原来的2倍。
2 实验
2.1 数据集的建立与实验平台
选取某医院肿瘤科采集的临床乳腺肿瘤细胞数据集作为研究对象,其中女性病例占83%,男性病例占17%,女性年龄为22~74 岁,平均年龄为45 岁,其中恶性乳腺肿瘤数据为2 170 张,良性乳腺肿瘤数据为1 211 张,乳腺肿瘤细胞图像见图2。乳腺肿瘤细胞数据集的分布情况如表1 所示。数据增强后数据集扩充为原来的二倍,增强后数据集分布情况如表2所示。本文训练和验证过程所使用的硬件平台配置为i5-9600k/32G RAM/2T SSD/GPU GeForce RTX 2070 Ti,操作系统为Windows 10(64bit)。本实验选取keras为实验框架。

图2 乳腺肿瘤细胞Fig.2 Breast tumor cells(a,b are benign tumors,c,d are malignant tumor cells)

表1 增强前乳腺肿瘤细胞数据集分布Tab.1 Breast tumor cell dataset before enhancement
训练模型时采用Adam 优化器,训练批次为32,学习率初始值为4×10-4,学习率根据迭代次数动态调整。动态调整学习率公式如下:
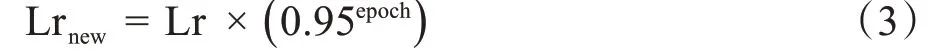
其中,Lr为学习率,epoch为迭代次数,Lrnew为新生成学习率。
2.2 实验评价指标
为了分析实验数据,本文使用召回率(Recall)和准确率(Acc)对实验数据进行评价。计算定义如下:

其中,TP表示将良性肿瘤数据分类到良性类别,TN表示将恶性肿瘤分类到恶性类别,TP和TN均表示分类准确;FP表示将恶性肿瘤数据分类到良性类别,FN表示将良性肿瘤数据分类到恶性类别,FP和FN表示分类错误。召回率表示样本中正例被正确预测的比例;准确率表示判定正确的数据在总体数据中的比例。通过上述两个指标可以反映模型的分类能力,数值越大,分类能力越强。VGG-Improve模型评价结果表3所示。
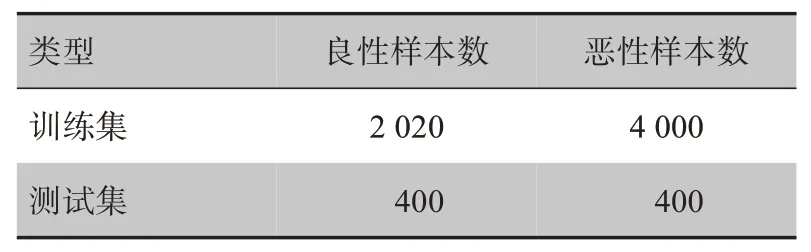
表2 增强后乳腺肿瘤细胞数据集分布Tab.2 Breast tumor cell dataset after enhancement
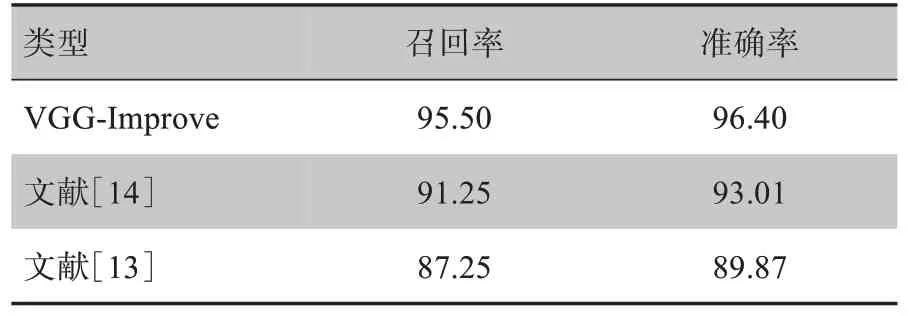
表3 同类文献网络的评价结果(%)Tab.3 Evaluation results of similar literature networks(%)
2.3 模型改进前后的比较
本文比较了模型改进前后对肿瘤数据集分类结果的准确率和损失值。其中VGG-Improve 卷积神经网络模型在测试集上的准确率高于VGG-16 卷积神经网络模型,损失值小于VGG-16 卷积神经网络模型。可以看出VGG-Improve 相比于VGG-16 在乳腺癌识别中有更好的表现。表4 中为模型改进前后训练及测试时各项参数对比。由表4 可知改进后模型测试集上的错误率和损失值均低于改进前模型。可以看出改进后模型解决了过拟合情况,并且正确率达到96.4%,相较于为改进前拥有更低的错误率。

表4 VGG-16改进前后各项参数对比(性能最佳的Epoch)Tab.4 Comparison of various parameters before and after VGG-16 improvement(Best Epoch)
2.4 与同类文献对比
文献[13]中卷积神经网络模型由7个卷积层和2个全连接层组成,其中第二、三层卷积层采用两个卷积并联的方式。这种做法能够增加网络模型宽度,实现多尺度的图像特征提取,使用该模型可以有效地对宫颈癌细胞进行分类。文献[14]中卷积神经网络由4 个卷积层,4 个池化层和2 个全连接层并联组成,其中池化层选用最大池化。
通过表5 可以看出在相同的乳腺肿瘤细胞测试集下,本文提出的方法相较于文献[13]和文献[14]的模型都有很大的提升,正确率明显提升。经上述对比可以看出,本文提出的VGG-Improve 卷积神经网络模型相较于同类文献提出的模型在相同数据集的情况下拥有更好的准确率。通过表3 和图3 可以看出VGG-Improve 卷积神经网络模型准确率和召回率都高于其他两种方法。证明了VGG-Improve 卷积神经网络模型具有良好的泛化性。
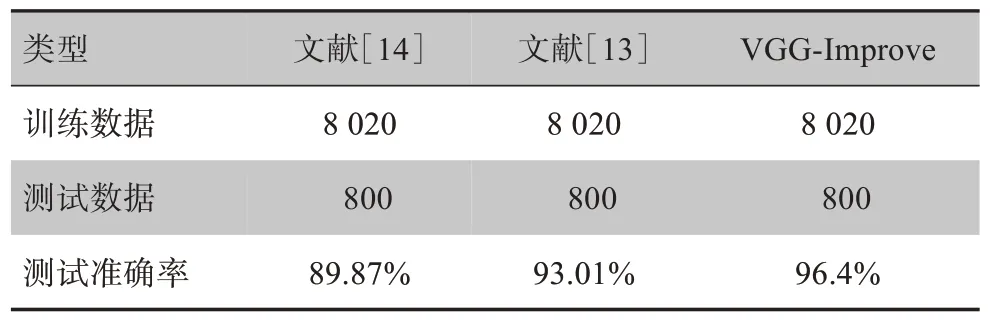
表5 本文与同类相关文献准确率对比Tab.5 Comparison of the accuracy between related literatures and the paper
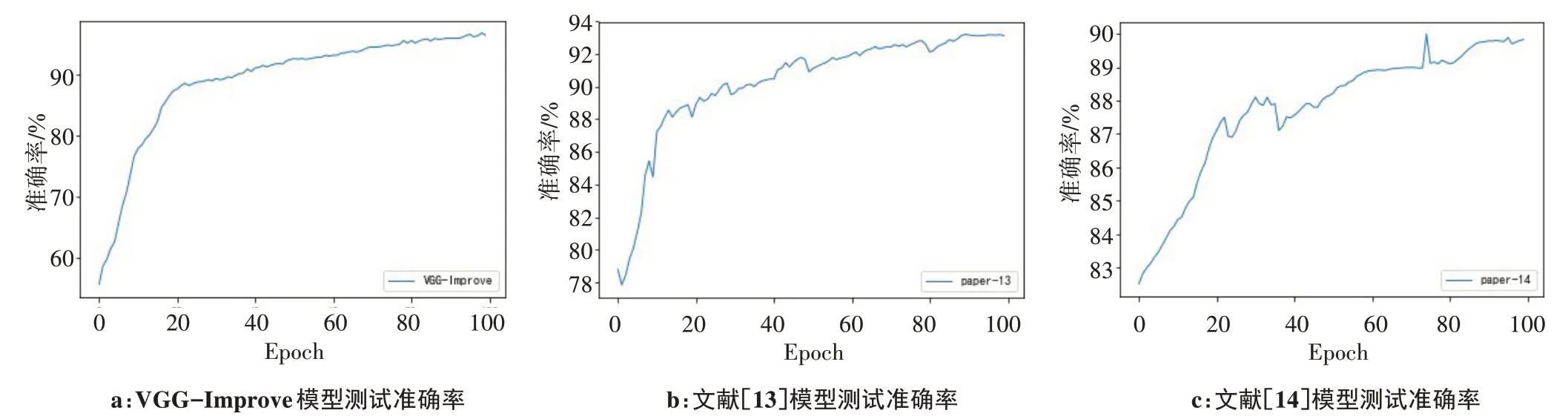
图3 测试集准确率与迭代次数的关系Fig.3 Relationship between test set accuracy and number of iterations
3 讨论
国外在癌症分类方面,Jiang 等[16]提出一种基于卷积神经网络的新型识别系统,该系统可以对图像进行预处理并对神经祖细胞(NPC)和非NPC 进行分类。Pansombut 等[17]使用多种机器学习算法对淋巴细胞进行分类,通过对比得出CNN 能更好的对淋巴细胞进行分类。李正义[18]通过对细胞边缘纹路、曲率、大小等特征的提取,使用一种改进的随机森林分类器对宫颈癌细胞进行识别。在信息化时代的背景下各种机器学习算法愈发重要,人工智能算法在医学诊断中已经广泛应用。本文提出的模型可以辅助医生对乳腺肿瘤进行良恶性分析。未来训练样本量足够时,可以代替医生进行肿瘤细胞良恶性识别。通过人工智能算法代替人工进行医学诊断可以大大缩短医生诊断时间,提高就医效率[19-20]。现阶段人工神经网络是图像分类中重要的分支,使用人工神经网络搭建针对特定疾病的自动化医学诊断系统是未来发展的趋势。由于本文使用的数据集为乳腺肿瘤细胞,目前在乳腺肿瘤识别中有很好的效果,但尚未对其他类型肿瘤细胞进行辨别,后续将考虑建立其他类型肿瘤细胞良恶性辨识模型。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
数学年刊A辑(中文版)(2019年1期)2019-01-31 02:35:44
中国生殖健康(2019年5期)2019-01-06 09:16:36
数学杂志(2018年5期)2018-09-19 08:13:48
中国交通信息化(2018年5期)2018-08-21 03:37:40
妈妈宝宝(2017年2期)2017-02-21 01:21:22
中国医学科学院学报(2015年5期)2015-03-01 04:03:43
数学年刊A辑(中文版)(2014年5期)2014-11-01 05:43:38
