
文献的合作网络模型及实证研究
2020-12-09 06:52宋涛刘双花
网络安全技术与应用 2020年12期
◆宋涛 刘双花
(百色学院广西 533000)
1 引言
随着知识经济的兴起,知识在社会经济中的地位愈发突出。知识的消费层次也由传统的以获取单一型的事实和机理为主的“无机温饱型”模式向上发展为以搜索复合型知识的产生、脉络和联系为主的“有机营养型”模式,逐渐呈现出多层需求共存的状态。而专业门类的高度细分增强了学术壁垒,加剧了跨界研究规律的不可知性,迫切需要新的文献服务组织方式。从学术文献的发展来看,学术成果数量激增,内容涉及广泛,不仅人文学科内部交叉研究活跃,与自然科学的融通渗透性也不断增强。而人们对跨界研究规律的认识却极为有限,已有的研究多以定性研究为主,观点多局限在某单一领域,缺乏整体性认识[1]。另一方面,对于逐渐走向国际化的人文学科而言,其学术成果对国家的发展具有不可低估的重要价值。探索人文学科跨界知识模型建模方法,将延展学术成果的展现半径,促进知识承载来源话语体系之间的交流,为学术服务、学科建设和研究规划等领域提供诸多决策参考[2]。
2 跨界知识模型的内涵
跨界知识是相对于领域知识而言,熊伟等[3]在强调跨界搜索通过组织资源改善提高组织竞争优势时,指出跨界搜索与组织群落之间的密切关系,一方面,跨界搜索行为需要相应的组织加以依托,另一方面,组织反映着从事这种组织的个人和群体的活动、价值观及意图。Tortoriello 和 Krackhardt[4]指出组织群落背景下跨界知识的强关系是实现跨界搜索的必要条件,群落内部和群落之间的桥接关系能够促进组织搜寻界外不同的新知识,两类信息的集成是有效提升组织跨界搜索能力的关键,于是跨界结构的关键是稳健的跨界群落的发现。
跨界知识模型提出的一个诱因是现存人文学科学术成果评价体系无法满足跨界研究规律的认识需要。目前人文学科学术成果评价体系中的主流评价方法有两类:一是专家系统同行评议法;二是基于引文分析的文献计量影响因子法。将同行评议法直接用于跨界知识提取存在跨界评审专家的遴选困难,数据主观性强,成本高,可比性差等问题[5]。基于引文分析学术影响因子是学术评价体系的主要标准,对知识结构的揭示作用有限。鉴此,科学数据文献情报学领域已尝试使用引文网络研究文源规律,典型的研究如[6]等,但引文分析的学科广度评价不适用于跨界知识提炼。
从文献的搜索来看,学科之间大范围的密切渗透无疑加大了跨界知识搜索的难度,倒不如承认跨界的普遍存在性,而将实际的跨越定义为程度或距离上的统计显著性,于是可以将问题简化为通过大量数据来对未知的跨界进行估计,估计知识之间的联通关系成为认识跨界知识发展脉络的主题,关系的估计和检验过程是建立稳定的跨界知识模型的核心。
3 跨界知识模型维度和数据基础
3.1 跨界知识模型维度
根据Li,Y等和Sid hu等对跨界搜索的需求调查显示,学者们主要关注的跨界内容分为三层结构:个体、项目和组织[7]。其中个体层次的搜索是指个体获取外部创造性想法的活动;项目层次的跨界搜索指了解外部项目新信息或搜寻新项目组成员的过程;组织层次的跨界需求表现为侧重于搜寻新联盟成员或对有意向合作的联盟的可行性分析。
3.2 跨界知识模型维度与学术成果评价之间的关系
跨界知识和学术成果评价之间的关系是紧密的,跨界知识模型与学术评价共同构成知识的评价体系,如图1所示,其中基于引文关系的学术影响力因子、半衰期等主要反映了知识自身体系的成长发展的贡献,另一方面,知识对外部领域的渗透与融合是其学术影响力的一个重要方面。跨界知识模型可以是对不同来源技术领域创造性活动的规律总结,是对基于引文的知识评价体系的有益补充。
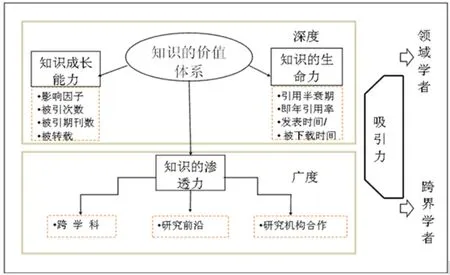
图1 知识的价值体系
3.3 跨界关系矩阵产生的数据基础
为了使跨界知识规律能够体现社会的认可程度,选择学者选读文献是基础。
首先,纳入社会化影响效果是建立面向学术服务的知识模型的必要条件。美国社会学家罗伯特·默顿[9]1985年在《科学的规范结构》中给出了学术成果的一个重要的功能,指出其价值是在科学家之间起着根本的交流作用。交流的结果是科学家通过同构性问题映射开启新思维,获得新知识创作的源泉与素材,选读文献一般贯穿于整个研究过程之中,可作为社会化影响效果的一个重要方面。
其次,学者选读文献是提炼跨界知识的最佳视角。塔佳,瓦卡瑞,弗莱和沃特斯(Talja,Vakkari,Fry,Wouters)指出跨学科性与一个领域的科学家使用其他学科的文献有关,科学家对文献的选择行为可用于度量学科之间联系的程度[10]。
4 跨界知识模型的建模算法
跨界知识是一种隐性知识,不易直接测量,只能通过微观个体数据间接估计得出,并利用建模过程进行模式的统计确认,关键的问题是对不同维度的强关系矩阵进行估计,主要解决的问题有两个:一是关系类的识别,主要使用社会网络理论中的社群关系估计挖掘算法;二是关系结构的解释,使用统计推断中的随机图检验方法,两者联合命名为 “网络关系估计-随机图检验”跨界知识连体建模框架,该框架首先是将彼此具有较强关系的节点聚集,并将互联显示较弱的群彼此割裂,随机图检验则固化核心结构。
4.1 社群发现的模块化方法
Newman于2004[11]年提出模块Q方法是社群挖掘中比较典型的方法。
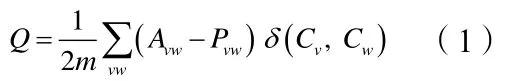
其中Avw表示关系图中顶点v和w之间的边数,这里我们选择复杂图,此时Avw取值为0或权重c,表示节点之间有关系或强度为c的两两关系;m是总边数,常数项1/2是归一化系数,Pvw表示零模型(即随机图)中顶点v和w之间期望的边数;示性函数δ(Cv,Cw)=1,如果社群Cv=Cw(即顶点v和w属于同一个社群),否则为0。Q定义了实际图社群边连通密度相对于随机图的差异,社群内边密度与随机图期望边密度相比越大,表明社群结构越明显。在跨学科研究中,学科合作具有规模不等和合作不平衡等特点,直接使用Q算法,将掩盖小学科的特色合作。社群挖掘算法需要考虑带边权重的WFN算法。
4.2 随机图模型-学术跨界模式检验
随机图模型的作用是对典型的网络模式的显著性进行检验,指数图模型是较为常见的检验模式的方法,假设图G=(V,E),Y=(Yij)是随机关系矩阵,如式2所示,
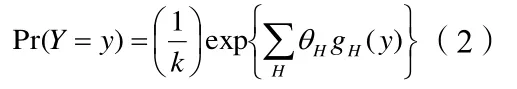
其中,H是一种图结构,gH(y)是关于某个结构的统计量,θH是对应的参数。k是归一化常数。
直接解指数族图模型的参数估计不容易,一般是采用指数族图模型估计方程,如式(3),对于y,令是两个对应的矩阵。的(i,j)、(j, i)位置上的元素是1,其他位置元素与y相同;的(i,j)、(j, i)位置上的元素是0,其他位置元素与y相同。那么边(i,j)存在的概率的对数为:
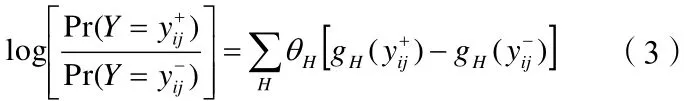
概率随机图模型参数估计采用对式(3)进行极大似然估计,求解期望的问题就可以使用蒙特卡罗或Gibbs采样。逼近估计表示为:
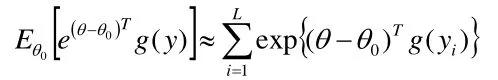
5 实证研究结果
5.1 人文学科跨机构协同创新网络图
文章以学者选读文献为分析对象,对跨地域协同合作的成效进行相关分析,试图找出人文学科领域跨界协同创新联盟的合作特点。数据以211或985高校和边远地区高校组成创新联盟,时间选择了自2011年201月共计16204条取某人文学科大学博士生和在职教师下载中国知网学术文献,西部地区选择了西藏、重庆、四川、贵州、云南、陕西、甘肃、青海、宁夏、新疆、内蒙古和广西12个有西部省市自治区机构参与的论文共计2457篇作为研究跨机构合作的基础数据,其中涉及了2102个不重复的中外研究机构,这些机构包括所在省市、机构名称、主管部门、所在地和办学层次。根据记录生成机构间的邻接矩阵。通过Q方法产生合作网络关系图2,9个社群彼此相对独立,7个社群群内成员多数仅限于同一省份内,说明地理位置是实现跨界协同创新的一个重要因素。9个社群多位于不同的省份,但其共同点是每个区域的中心机构均为“社群多位或全国重点建设大学。
表1的随机图模型检验中,三角型互联结构没有通过检验,p-值为0.1148,星型辐射结构较互联结构相比通过检验,p-值为10-6,支持了辐射结构的结论。结果说明社群名校的强弱“帮补型”合作在创新研究中特色突出,反映了跨机构协同创新合作中的星型结构和地域特点,星型结构中的强校纽带作用比较突出,呈现出明显的强弱联盟合作创新模式,这离不开教育部2001年开始实施的“对口支援西部地区高等学校计划”。
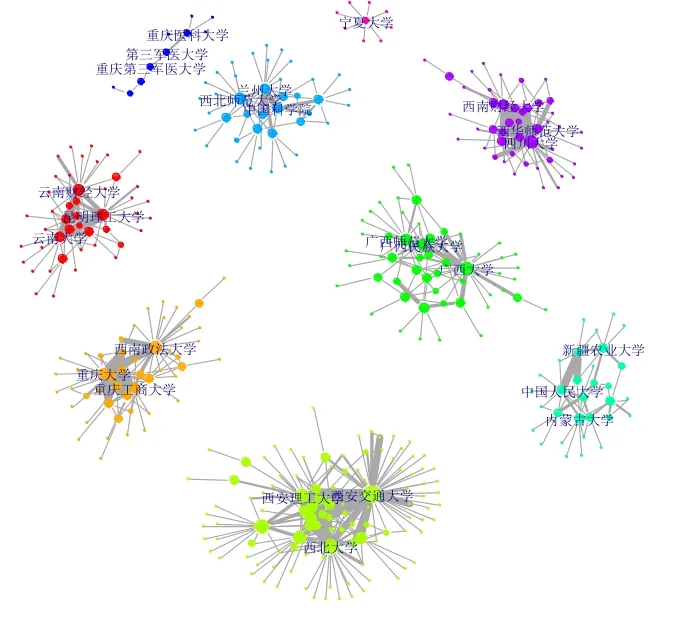
图2 跨层次机构合作关系图
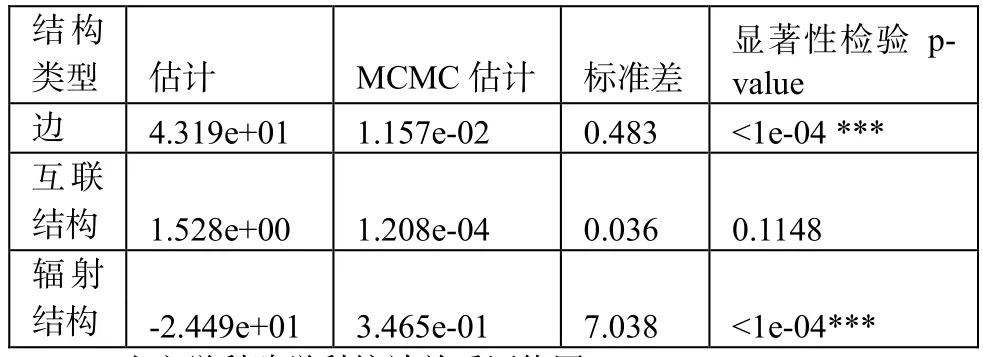
表1 随机图检验结果
5.2 人文学科跨学科统计关系网络图
取某人文学科大学二级教授及其博士生2011年上半年在中国知网选读文献,两个学科的跨学科关系强度定义为被同一学者在所选时间范围内两学科文献的数量,基于同读同时性的要求,获取有效文献53268篇,学者300位分属22个学科,文献来自37个学科。对数据一次做二分图转化和过滤程序后,使用社区提取方法得到共读文献的跨学科影响,文献学科网络聚类将跨学科影响关系分为4大群:第一大群是人文学科类(红色类和绿色类),绿色类可以看作是人文学科类,红色类为社会科学类,可以看出人文与社会科学两类联系很紧密;第二大群是理工类。计算机科学与技术在理工科类和人文学科类中起到关键的联系作用。
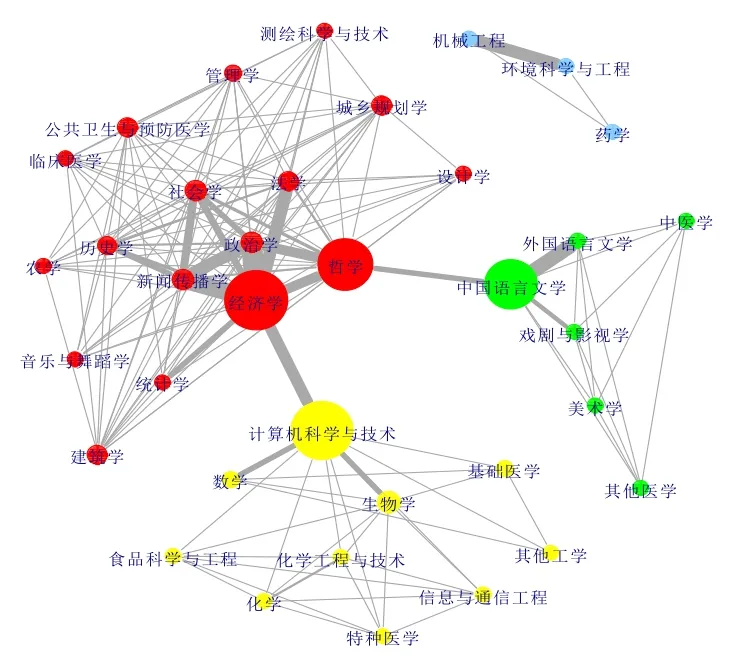
图6 文献跨学科影响社群结构图
第三大群是工程类学科组成的群,包括计算机科学与技术、数学、基础医学、生物学等组成的社群。其中核心学科是计算机科学与技术,跨学科最强的关系是计算机科学与数学,生物学-计算机科学。第四大群是机械工程、环境科学与工程、药学等组成的社群。
从跨学科文献阅读来看,自然科学向人文学科的渗透强于人文学科向自然科学的渗透,人文学科各门类之间的交融面上发挥连接桥梁的学科是经济学、政治学、法学、哲学、新闻学、语言文学等学科。
6 结论
文章研究了学术成果中蕴含的跨界群落产生的数据和分析模型,从人文学科学者选读文献视角出发探讨跨界关系的估计问题,引入社会网络理论的网络关系估计算法,发展出 章网络关系估计-随机图检验”跨界知识连体建模框架,该框架包括跨界关联矩阵的估计算法和随机图模型稳健模式检验两个部分。综合使用模块社群挖掘算法和随机图检验连体,揭示了人文学科跨机构协同创新合作和跨学科合作基本模式。
猜你喜欢
科学大众·教师版(2022年6期)2022-05-23
大学(2021年2期)2021-06-11
浙江树人大学学报(人文社会科学版)(2021年2期)2021-04-15
课程教育研究(2021年21期)2021-04-14
销售与市场·渠道版(2020年2期)2020-03-17
销售与市场(营销版)(2020年2期)2020-03-09
销售与管理(2019年10期)2019-12-06
现代家电(2019年4期)2019-06-12
博览群书(2017年12期)2018-01-15
贵州省党校学报(2016年6期)2017-01-16
