
规则约束下基于深度强化学习的船舶避碰方法
2020-12-09 01:58:34周双林刘克中吴晓烈刘炯炯王伟强
中国航海 2020年3期
周双林,杨 星,b,刘克中,b,熊 勇,b,吴晓烈,刘炯炯,王伟强
(武汉理工大学 a.航运学院; b.内河航运技术湖北省重点实验室, 武汉 430063)
随着海上交通密度的增加和船舶航速的提升,人为制定船舶航行避碰决策正面临巨大的压力。[1]调查显示,80%的碰撞事故是由船员因素造成的,其中船员未遵守《国际海上避碰规则》是船舶之间发生碰撞的主要因素。[2]自主避碰技术作为保障船舶在海上安全航行的关键技术,其研究受到各国学者的关注。ABDALLAH等[3]采用非线性优化方法解决两船避碰问题,并将COLREGS(International Regulations for Preventing Collisions at Sea,COLREGs)作为优化算法的约束条件,通过仿真试验验证该避碰算法的有效性;倪生科等[4]基于多种群的遗传算法进行船舶避碰辅助决策研究,通过合理设置算法的终止条件对遗产算法的适应度函数进行评价,从而为船舶避碰提供有效的辅助决策;ZHANG等[5]和张金奋等[6]提出一种基于分布式框架的实时多船决策支持系统,建立让路船和直航船的行动方式和幅度等避碰模型,并将其应用于多船避碰;李丽娜等[7-8]结合避碰规则和良好船艺,提出一种船舶拟人智能避碰决策方法,通过实时处理避碰参数计算模型和目标交会特征模型等避碰模型,实现对多个危险目标船舶的避让;SZLAPCZYNSKI等[9]采用船舶域评估船舶的碰撞危险,并采用光栅海图优化算法中的搜索策略得到能适用于开阔水域和受限水域的多船避碰方法;沈海青等[10]基于深度竞争Q学习和A*算法提出一种无人船智能避碰方法,将COLREGs转化成动态航行限制线,使避碰决策符合COLREGs;于家根等[11-12]分别基于拟态物理学优化算法和社会情感优化算法对船舶特定会遇场景下的转向避碰决策问题进行研究。
在船舶自主避碰相关研究中,仍存在对COLREGs考虑不够充分和构建复杂环境模型时避碰算法计算量较大的问题。当前人工智能技术飞速发展,具有模型简单、鲁棒性强和能自主学习适应环境等特点,其深度强化学习技术广泛应用于智能避碰和路径规划研究中。本文针对当前自动避碰算法存在的不足,结合船舶航行特性和COLREGs基于深度强化学习中的深度Q网络(Deep Q Network,DQN)算法,提出一种针对多种会遇场景的船舶智能避碰方法,利用深度神经网络对智能体进行训练,并通过数值仿真对两船会遇和多船会遇场景进行测试,验证该方法的有效性。
1 基于深度强化学习的船舶智能避碰方法
1.1 深度强化学习原理
强化学习算法理论框架基于马尔可夫决策过程(Markov Decision Process, MDP),其本质是agent与环境不断交互实现学习适应环境的过程,通过不断更新agent行为策略,使其获得最大累计奖励Rt。[13]
(1)
式(1)中:γ∈[0,1]为折扣系数,可调节未来奖励对当前动作的影响;rk为k时刻获得的瞬时奖励。
累计回报奖励期望即动作值函数Qπ(s,a)和状态值函数Vπ(s),通常作为评价策略π的标准,其中:s为agent所处状态;a为agent采取的动作;Qπ(s,a)为agent依据策略π在处于状态s时采取动作a获得的期望奖励值;Vπ(s)为agent处于s时采取策略π获得的期望奖励值。
Qπ(s,a)=Eπ{Rt|st=s,at=a}
(2)
Vπ(s)=Eπ{Rt|st=s}
(3)
强化学习的目标是得到最优动作值函数Q*(s,a)和最优状态值函数V*(s),有
(4)
(5)
将式(2)代入式(4),可得Q*(s,a)的迭代形式为
(6)
式(6)中:s′和a′为下一时刻的状态和动作,Q*(s,a)满足Bellman方程。由此可求得最优策略函数π*(s)为
(7)
利用深度神经网络对Q*(s,a)进行估计,其代价函数为
L(θi)=E{(yi-Q(s,a;θi))2}
(8)
式(8)中:θ为深度神经网络中的参数;i为训练回合数。
神经网络优化目标为
(9)
深度强化学习采用记忆回放技术解决样本数据关联性问题,加速估计Q*(s,a)的训练过程。
1.2 基于DQN的船舶智能避碰模型
船舶会遇场景复杂,避碰行动受操纵性和COLREGS的约束,因此选择具有良好鲁棒性的DQN算法构建船舶智能避碰模型,该模型的核心工作是合理设计MDP中的各个要素。根据船舶间实时获取的航行信息,从全局的角度建立包含会遇环境信息的状态集St,保证输入神经网络中船舶航行信息的完整性。船舶避碰行为at主要考虑转向,保证避碰决策的可执行性。奖励函数rt是船舶DQN避碰模型中最核心的部分,是船舶智能避碰决策制定的依据。当不存在碰撞危险时,船舶在海上通常按规定航向航行;当存在碰撞危险时,船舶采取的避碰决策既需考虑船舶间避碰过程的安全有效性,又要考虑船舶在避碰过程中是否遵守COLREGs。因此,应综合考虑航向跟随、船舶碰撞和规则符合等因素,对船舶智能避碰模型DQN奖励函数进行设计。基于DQN的船舶智能避碰模型框架见图1。
2 船舶智能避碰深度强化学习算法方案
2.1 状态集设计
船舶航行时衡量本船与周围船舶危险度的直接
且重要的标准是两船在最近会遇点时的距离和方位。[14]船舶避碰行动通常开始于6 n mile,为提高避碰算法处理本船与周围船舶会遇信息的可计算性,以半径rencounter=6 n mile作为本船对周围环境感知并记录的范围。
1) 为减小计算量,缩短训练时间,以12°为1个单位,将本船可航行范围分成30个区域,每个区域的边界弧长L=2 327.29 m,小于大多数船舶航行的安全距离,保证在开阔水域中每个区域内最多有1艘目标船。记录每个区域中目标船到本船的距离d0,没有目标船的区域记录di=rencounter=6,并以距离值作为强化学习的状态因数之一,有
xt=[dt,1,dt,2,…,dt,30]
(10)
2) 为量化两船会遇的紧迫程度,引入最近会遇时间(Time to Closest Point of Approaching,tCPA)和最近会遇距离(Distance of Closest Point of Approaching,dCPA)作为指标,该状态因数为
Tt=[TCPA1,Tt,CPA2,…,Tt,CPA30],
dt=[dt,CPA1,dt,CPA2,…,dt,CPA30]
(11)
将本船相对目标船的方位作为状态因数之一,有
θt=[θt,1,θt,2,…,θt,30]
(12)
综上,强化学习的状态集为
(13)
2.2 动作集选择
频繁改变船舶航速易对主机造成损害,且花费的时间较长,为保证算法输出的避碰决策具有良好的可操作性,系统动作集选择航向变化量,本船进行避碰行为采取的转向角度设计为:A={-Δψ,0,Δψ},左转为负,右转为正,Δψ>0,其中Δψ可根据实际船舶操作特性进行合理设置。
2.3 奖励函数设计
船舶智能避碰深度强化学习算法中的奖励函数是船舶智能避碰决策制定的依据。当船舶不存在碰撞危险时,本船应按预先规定航向航行;当船舶存在碰撞危险时,本船应采取合理的避碰决策,其执行的避碰行动既要考虑船舶间避碰过程的安全有效性,又要考虑船舶在避碰过程中是否遵守COLREGS。
2.3.1航向保持奖励函数
当本船周围不存在需要避让的目标船时,应按照预先规定的航向航行。观察本船每一时刻的航向,并将其与规定的航向相比较,计算其偏差。当偏差值大于可接受的最大误差时,认为此时的状态处于偏离航向状态,需对其进行惩罚。因此,设计航向保持奖励函数为
(14)
式(14)中:Δφe为此时本船航向与规定航向之间的偏差;Δφe,max为可接受的最大航向偏差值;-rcf为航向偏差的惩罚值。
2.3.2避碰奖励函数
当存在碰撞危险时,本船应采取避碰决策,始终与周围船舶保持安全的物理距离,对船舶间距离小于安全会遇距离(Safe Distance of Approach,SDA)的状态给予惩罚。[14]因此,设计避碰奖励函数为
(15)
式(15)中:Pt,0为本船在t时刻的位置;Pt,Ti为目标船i在t时刻的位置;SDA为两船间的安全会遇距离;-rcollision为发生碰撞的惩罚值。
2.3.3遵守规则奖励函数
船舶避碰过程除保证避让的安全有效性外,还要考虑避让过程是否遵守COLREGs。通过对该规则进行解读分析,量化部分要求,设计针对避碰决策是否符合规则的奖励函数。分析每一时刻输入到强化学习系统中的状态信息,通过对局面和阶段进行判断,确定船舶责任和会遇态势,分别针对不同情况逐一设计对应的奖励函数,在训练时视不同情况对奖励函数进行调用。
2.3.3.1 直航船
COLREGs第17条规定:两船中的一艘船应给另一艘船让路时,另一艘船应保持航向和航速。[15]当本船判定为直航船时,应对其采取变向的行为进行惩罚,设计直航船奖励函数为
(16)
式(16)中:Δφ为本船作为直航船时航向改变量;Δφmax为直航船可接受的最大航向改变量;-rcourse为直航船采取变向行为的惩罚值。
2.3.3.2 让路船
COLREGs第16条规定:须给他船让路的船舶,应尽可能及早地采取大幅度的行动,宽裕地让清他船。[15]因此,当检测到存在碰撞危险且判定本船为让路船时,本船应及早地采取避碰行动,对迟缓的动作进行惩罚。设计让路船及早行动奖励函数为
(17)
式(17)中:φtdetect为检测到危险时刻的本船航向;φtdetect-1为检测到危险上一时刻的航向;Δt为检测到发生危险的时刻与采取动作的时刻之间的差值;-rsoon为对应的惩罚值。
根据COLREGs要求,让路船应该宽裕地让清他船。因此,定义本船最近会遇距离的预警范围dpre和发生碰撞的物理距离dcol见图2。[16]当船舶会遇时,计算船舶间的最近会遇距离dCPA,通过判断dCPA是否小于各阈值来判断船舶间是否存在碰撞危险,进而判断避让行动是否宽裕。预警范围dpre和物理距离dcol与船舶尺度、船舶运动特性和船舶操纵性等相关,各船舶可根据自身属性设定不同的dCPA阈值dpre和dcol,设计宽裕奖励函数Rwide为
(18)
综上,让路船奖励函数设计为
Rgive-way=Rsoon+Rwide
(19)
考虑本船同时与多船形成复杂会遇场景的情况,判断本船为让路船或直航船的依据见式(20)。若相对其中至少1艘目标船本船判断为让路船,则认为本船需采取避让行动,即本船为让路船;若相对所有目标船本船判断为直航船,则本船为直航船。
(20)
式(20)中:fi为本船相对第i条目标船的船舶责任;f为本船同时应对多船会遇时的船舶责任。
2.3.3.3 对遇局面
根据COLREGs第十四条的要求,当2艘机动船在相反的或接近相反的航向上相遇致有构成碰撞危险时,应各向右转向从他船的左舷驶过。[16]两船处于对遇局面时,本船应采取转向动作,保证两船在最近会遇点时本船处于他船左舷位置,即本船相对他船的相对方位角θcpa为180°~360°,对该状态给予奖励。因此,设计对遇局面下的奖励函数如式(21)所示,其函数示意见图3。
(21)
式(21)中:rhead-on为对遇局面奖励值系数。
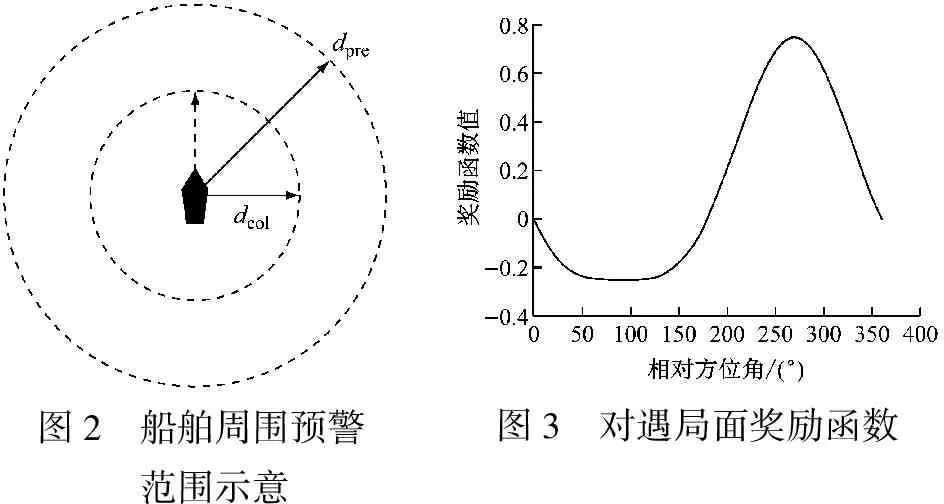
图2 船舶周围预警范围示意图3 对遇局面奖励函数
2.3.3.4 交叉让路局面
根据COLREGs第15条的要求,当2艘机动船交叉相遇,并构成碰撞危险时,有他船在本船右舷的船舶应给他船让路,且应避免横越他船的前方。[16]在交叉让路局面下,本船应从他船艉部经过,因此定义相对方位阈值θε=[90°,270°],通过判断在最近会遇点时本船相对他船的相对方位θcpa是否属于θε来判断本船是否横越他船的前方,设计交叉让路局面奖励函数Rcross为
(22)
式(22)中:rcross为交叉让路局面奖励值系数。通过对局面和阶段进行判断确定本船的责任和会遇态势,训练时视不同情况对奖励函数进行调用。处于各局面与责任下本船调用奖励函数具体情况为:对遇局面Rhead-on+Rgive-way;交叉让路局面Rcross+Rgive-way;追越局面Rgive-way;交叉直航局面Rstand-on;被追越局面Rstand-on。
2.4 算法步骤
船舶避碰深度强化学习过程是DQN算法中神经网络收敛的过程,将本船的航行状态集作为神经网络输入数据,初始给定一个避让策略求出值函数,并利用值函数更新避碰策略,如此循环即可训练出收敛的最优避碰策略。完整算法步骤如下:
Input:rt={Rgive-way,Rstand-on,Rhead-on,Rcross} %输入船舶可调用奖励函数集
Input:at%输入动作集1. Initialize replay memoryDto capacityN
2. Initialize action-value function Q with random weights
3. for episode = 1;Mdo
4. Initialize sequences1={x1} and preprocessed sequencedφ1=
φ(s1)
5. fort=1,Tdo
6. With probability ∈ select a random actionat
8. Execute actionatin emulator and observe rewardrtand imagex(t+1)
9. Setst+1=st,at,xt+1and preprocessφt+1=φ(st+1)
10. Store transition (φt,at,rt,φt+1) inD
11. Sample random minibatch of transitions
(φj,aj,rj,φj+1) fromD
13. Perform a gradient descent step on (yj-Q(φj,aj;θ))2
14. end for
15. end for
3 船舶避碰仿真验证
基于TensorFlow深度学习框架编程实现提出的避碰算法。训练开始时设置1艘用于训练的本船agent,并设置其初始位置、航速、航向、dpre(1.5 n mile)和dcol(0.5 n mile)等参数。[14]根据训练场景的要求增加一定数量长宽与agent相同的目标船,针对不同会遇场景设置目标船的初始位置、航向和航速等参数,目标船航行时具备自主航行能力,用以模拟多种会遇场景的情形。
设置DQN算法的相关参数如下:记忆回放池的大小为2 000;批量数据集的大小为500;最大训练回合为10 000;学习率γ=0.99;奖励折扣系数ε为0.9;设计神经网络结构为[120,128,128,3],即1个输入层、2个隐藏层和1个输出层,输入层包含120个节点,输入为船舶智能避碰深度强化学习算法中的状态集数据;每个隐藏层都有128个节点,隐藏层节点的激活函数选择ReLU非线性激活函数;输出为动作集中对应3个动作的动作值;层与层之间的节点全连接;采用Adam优化算法进行训练,得到基于深度强化学习的船舶智能避碰模型。
3.1 两船会遇局面的避碰仿真验证
为验证提出的避碰算法在两船会遇局面下能使船舶在COLREGs的要求下有效避让来船,分别对不同会遇局面进行仿真验证。
3.1.1对遇局面
两船的初始参数设置见表1,仿真的船舶航行轨迹和两船距离随时间的变化曲线分别见图4和图5。由图4和图5可知,本船按照COLREGs的要求向右转向实现与目标船左对左安全通过,并在驶过让清后恢复原航向,整个避碰过程安全有效。
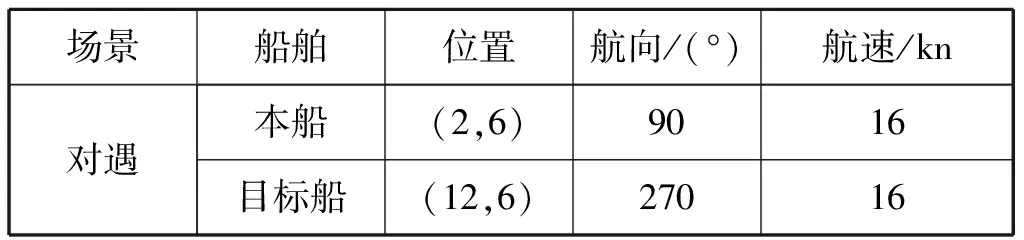
表1 对遇局面的船舶初始参数设置

图4 对遇局面中两船的航行轨迹图5 对遇局面中两船距离随时间变化曲线
3.1.2交叉相遇局面
两船的初始参数设置见表2,仿真的船舶航行轨迹和两船距离随时间的变化曲线分别见图6和图7。由图6和图7可知:本船按照COLREGs要求向右转向,并从目标船的艉部驶过,实现对目标船的避让。

表2 交叉相遇局面的船舶初始参数设置
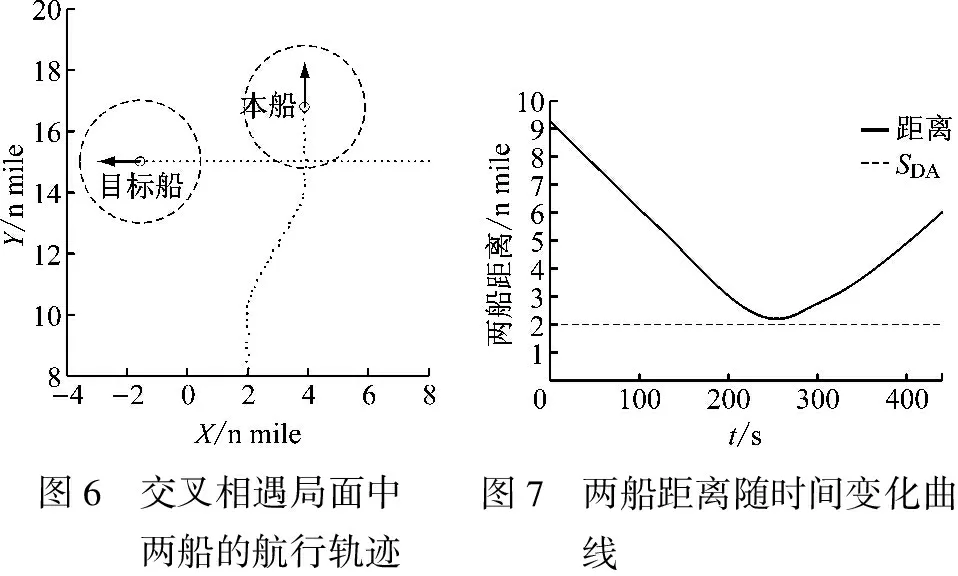
图6 交叉相遇局面中两船的航行轨迹图7 两船距离随时间变化曲线
3.1.3追越局面
两船的初始参数设置见表3,仿真的船舶航行轨迹和两船距离随时间的变化曲线分别见图8和图9。由图8和图9可知:本船追越他船局面中本船按照COLREGs在目标船的右舷作为让路船从目标船的艉部通过,被追越目标船作为直航船保持原来的航行状态继续航行。
3.2 多船会遇局面的避碰仿真验证
作为船舶避碰研究中的重要内容之一,多船避碰中各船面临的会遇场景比两船会遇局面更复杂。为验证提出的避碰算法可使本船在应对复杂会遇场景时具备自主避碰能力,进一步进行多船避碰仿真试验。
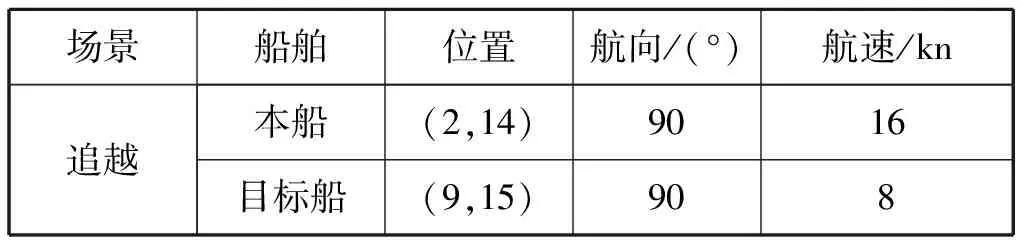
表3 交叉相遇局面的船舶初始参数设置
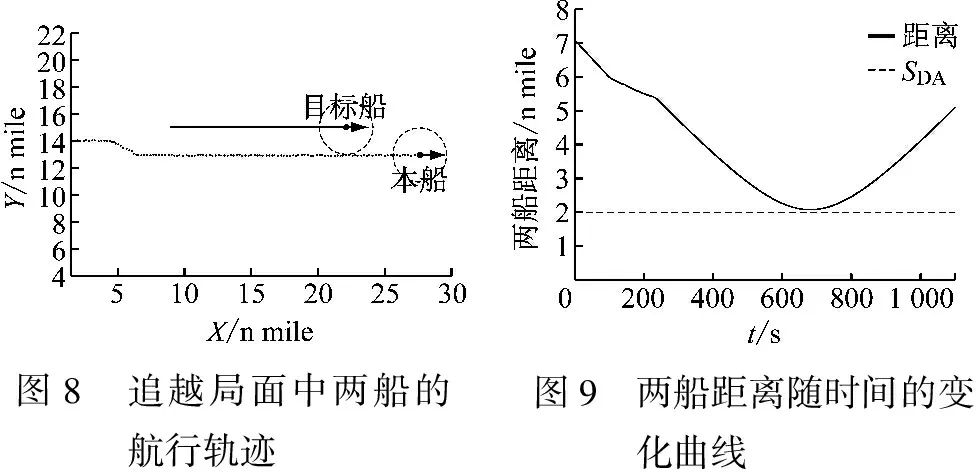
图8 追越局面中两船的航行轨迹 图9 两船距离随时间的变化曲线
3.2.1多船会遇初始参数设置
以3艘船舶会遇场景为例进行多船避碰测试,船舶初始参数设置见表4。
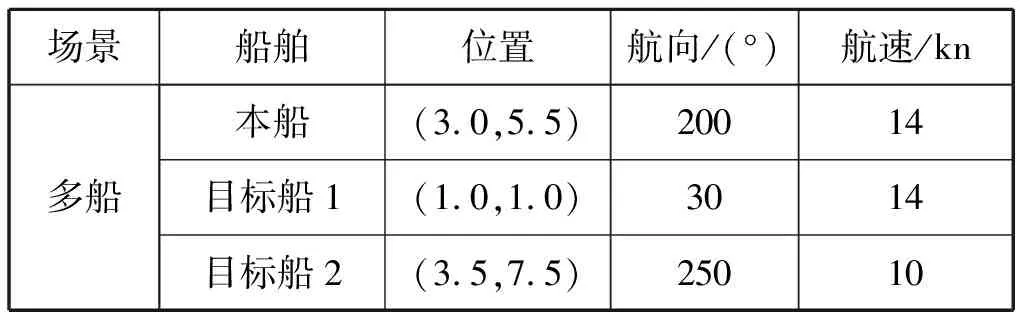
表4 多船会遇场景船舶初始参数设置
3.2.2多船避碰仿真验证结果分析
多船会遇仿真试验中的单次训练回合累计奖励函数值的变化曲线和船舶航行轨迹分别见图10和图11。由图10可知:随着训练回合数的增加,DQN算法中的累计奖励函数值逐渐增大,算法在不断地学习。通过足够次数的训练学习后,可得到符合COLREGs的深度强化学习多船避碰模型。由图11可知:本船一开始与目标船1形成碰撞危险,因此本船采取向右转向对目标船1进行避让,在转向过程中为避免与目标船2形成新的危险,本船进行左转向,实现对目标船2的避让并恢复航向,最终形成的多船避让过程如图11所示。
多船会遇场景中各船舶间距离随时间变化曲线见图12,其中OS-TS1、OS-TS2和TS1-TS2分为本船与目标船1、本船与目标船2、目标船1与目标船2之间的距离随时间的变化曲线。由图12可知:各船舶间的距离始终保持在安全会遇距离之外。
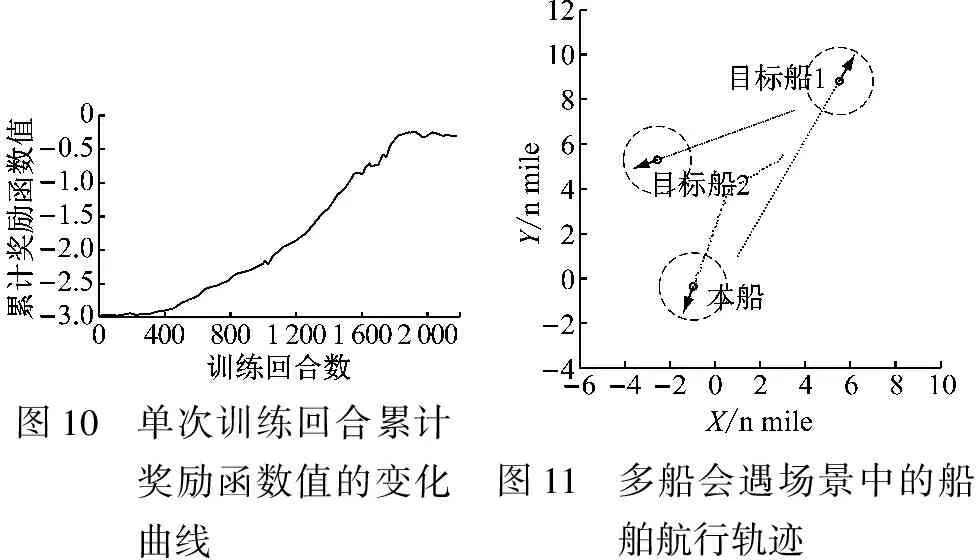
图10 单次训练回合累计奖励函数值的变化曲线图11 多船会遇场景中的船舶航行轨迹
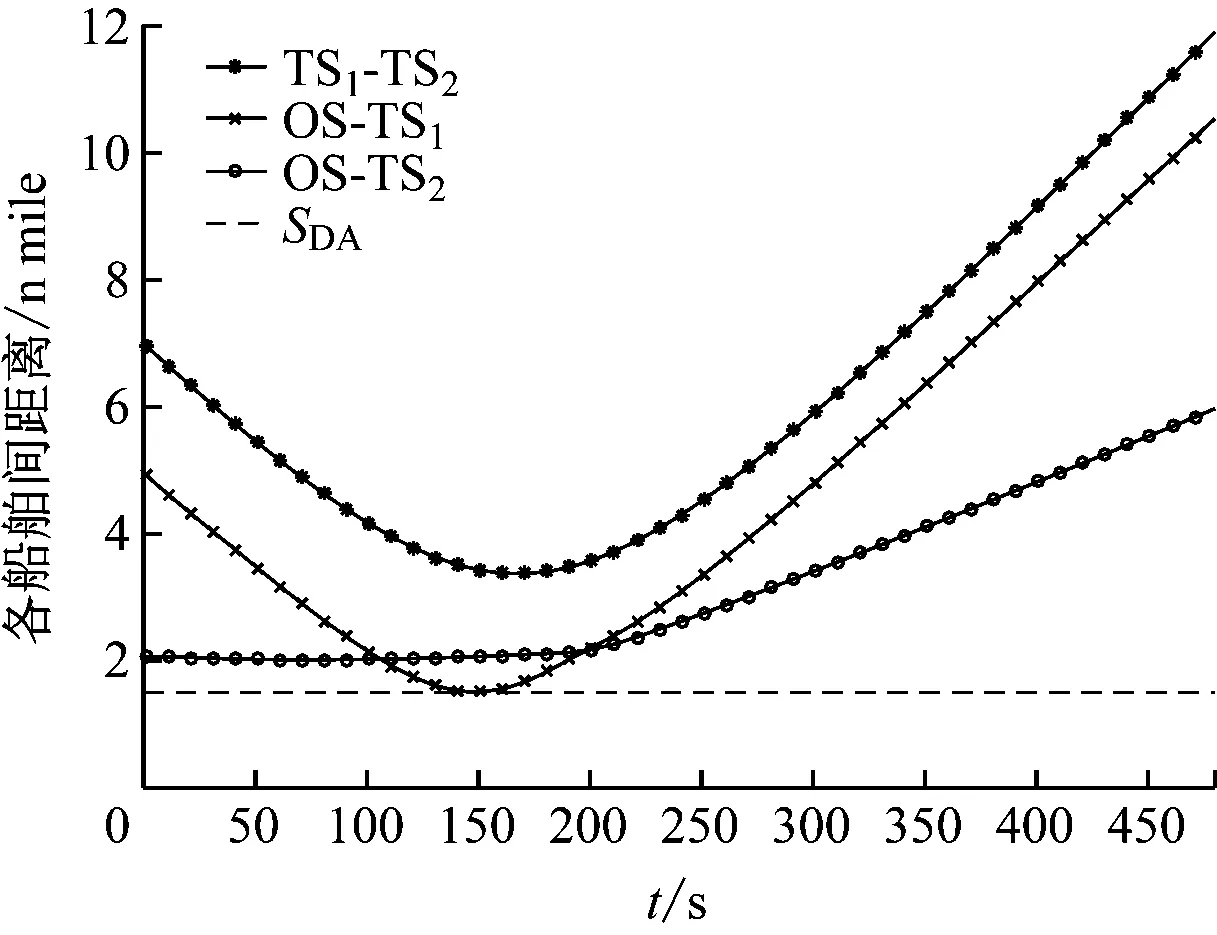
图12 多船会遇场景中各船舶间距离随时间变化曲线
4 结束语
针对船舶自主避碰问题,在对COLREGs充分理解的基础上,基于深度强化学习技术能自主学习适应环境的特点,提出一种COLREGs约束下的船舶DQN避碰算法,通过分析船舶避碰影响因素,设计船舶智能避碰DQN模型。将本船视为智能体,根据船舶间实时获取的航行信息设计准确描述船舶避让过程的状态集和动作集,保证输入神经网络中船舶航行信息的完整性和可计算性;结合船舶避让决策制定中对安全性和遵守COLREGs的要求,设计考虑航向跟随、船舶碰撞和规则符合等要素的奖励函数;利用深度神经网络对智能体进行训练,并采用Adam优化算法提高训练速度。通过多种会遇场景的数值仿真试验验证了该算法的有效性。目前,针对两船通过沟通绕开规则进行协同避让的情况暂未考虑,今后可就平衡严格遵守COLREGs与船舶协商避让开展进一步的研究,同时通过增加会遇船舶数量和会遇场景复杂度来优化算法。
猜你喜欢
集美大学学报(自然科学版)(2022年4期)2022-09-04 03:13:02
华人时刊(2022年7期)2022-06-05 07:33:56
舰船科学技术(2021年5期)2021-07-03 07:20:48
中国航海(2021年1期)2021-03-10 13:31:32
武汉理工大学学报(交通科学与工程版)(2020年3期)2020-07-27 06:46:00
上海海事大学学报(2018年1期)2018-04-30 05:15:32
中国航海(2015年3期)2015-11-29 01:02:53
学习月刊(2015年12期)2015-07-09 03:36:52
重庆交通大学学报(自然科学版)(2015年4期)2015-06-07 11:22:58
中国航海(2014年3期)2014-11-28 11:17:08
