
基于扩散连接试样金相照片的非焊合缺陷的自动识别*
2020-12-08 03:08胡京徽谢鹏志
航空制造技术 2020年21期
胡京徽,谢鹏志,2,杨 威,2,姚 罡
(1.中国航空制造技术研究院,北京 100024;2.数字化制造技术航空科技重点实验室,北京 100024)
扩散连接(Diffusion Bonding,DB)是一种广泛运用于现代航空制造领域的先进钣金成形制造技术[1–2]。扩散连接技术具有成本低、可靠性高、稳定性好等诸多优势,主要的应用场景有飞机机身壁板、防火墙、航空发动机舱、静/转子叶片等复杂空腔结构的制造。目前,由于钣金材料表面状态,扩散连接温度、压力、保压时间等一系列工艺参数的影响,扩散连接成形的工件会存在一定比例的非焊合缺陷,工业上通常要求采用无损检测方法对装机件进行检测,确保工件的质量。早期,对于尚未建立可行的无损检测方法的应用场合,需要通过对工件加工余量区取样,进行金相显微观察,然后根据其
观察结果,推测工件中是否存在扩散缺陷。这种方法首先抽样检测同一批次的部分样品,然后人工判定产品是否存在缺陷。然而,随着产品检测需求量的日益增加,一方面,传统的人工判定方式已经不能满足日常工作的需求;另一方面,由于检测人员的工作经验参差不齐,在长时间检测过程中还可能疲劳误判漏判。如何使用软件代替人工判定使判定标准一致,减少误判漏判已经成为目前工业界亟待解决的问题。因此,本文提出了一种可以自动检测扩散连接缺陷的机器学习平台的构建方案,并将其应用到实际工业场景中。
1 机器学习平台构建总体方案
本文所构建的机器学习平台包括影像存储、模型训练和检测平台3个模块,具体方案流程如图1所示。
影像存储模块功能是对原始影像数据收集、整理和存储。影像收集步骤将原始金相影像数据收集到系统中;接着,人工标注步骤提供人工标注原始数据的功能;然后,影像对齐步骤对影像进行对齐操作,使得输入数据符合对齐的标准;最后,将标注好的影像数据分成训练集和测试集两个部分,其中训练集用于检测平台模块训练初始样本数据,测试集用于模型训练模块来评估卷积神经网络。
检测平台模块是系统的底层应用,它的输入是训练集,通过网络提供给模型训练模块基础的训练数据。检测平台内部的一个核心部件是影像采样,它包含特征提取器、图像增强器和图像窗口生成器。通过这些采样预处理步骤可以将训练集中的数据处理成识别所需要的图片窗口。识别平台的另一个核心部件就是TensorFlow 训练平台,TensorFlow 平台读取窗口图片,通过定义损失函数、优化器以及训练梯度和参数来提供机器学习模型的建模要素。
模型训练模块是算法工程师训练和调优智能化识别算法的主要模块。由于算法训练需要消耗大量的计算资源,故模型训练模块的底层采用了GPU 高性能计算服务器作为主要硬件资源,同时通过CPU 作为辅助计算的备选方案。两类不同架构的硬件资源提供一套模型基础算法接口向上兼容。硬件资源之上是模型的构建和调优部分,该部分接收模型输入数据,使用训练数据来训练深度学习模型,使用测试数据来评估和验证模型的好坏。本文采用深度学习神经网络作检测识别的模型,该模型的重要工作就是对卷积神经网络的层级关系,神经元数量、丢弃层以及池化层等相关参数反复试验调优来得到识别率高的检测模型。同时,模型训练模块还需要接收影像存储模块中的测试集数据,通过测试集中数据来对训练后模型的实际识别效果进行评估。
2 卷积神经网络构建与训练方法
2.1 卷积神经网络的构建
卷积神经网络是机器学习中一种非常常见的网络结构[3]。近几年,由于高性能计算的快速发展和GPU并行计算的应用普及,卷积神经网络在工业级开发场景中发生了巨大的变化[4]。本文中建立的机器学习模型就是基于开源工业级深度学习框架TensorFlow[5]。
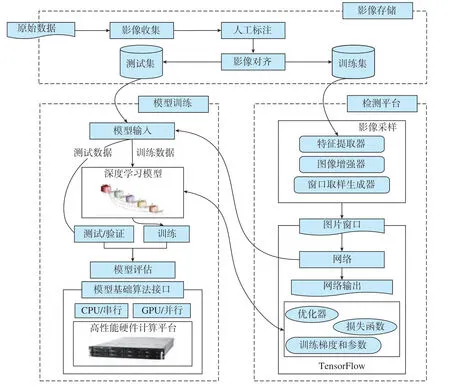
图1 平台构建总体方案图Fig.1 Overall platform construction architecture
本文中的卷积神经网络主要基于AlexNet 模型并对网络参数调整然后进行试验,下一步的工作着重结合VGG和ResNet 等网络模型进一步试验,模型具体参数如表1所示,模型的输入是分辨率为256×256的单通道灰度图像,输入图片经过第1个卷积层conv1 得到256×256×16的特征图,其中conv1中的卷积运算核维度为5×5,卷积步长为1,采用same 填充方式;接着,特征图通过第一个池化层pool1,pool1 采用最大池化方式,选取维度2×2、步长为2的核来完成池化操作,得到128×128×16的特征图;然后,使用类似的方法经过第2个卷积层conv2和第2个池化层pool2 得到64×64×32的特征图。在完成卷积操作后,特征图会通过一个全连接层dense 得到131072个训练参数;然后,通过一个丢弃层dropout 来控制参数保留比例,防止模型在训练集上产生过拟合现象[6];接着,通过两个前向传递层fc1和fc2 将训练参数数量变成512和64;最后,输出参数通过softmax 分类器得到判定结果。
2.2 机器学习平台的模型训练方法
本文中的模型训练方法流程如图2所示,每个步骤的功能如下。(1)输入数据增强:该步骤将输入的图像数据进行扩充,对原始图像进行旋转、缩放、平移以及对称变换等操作,这些操作在获取更多的训练数据的同时可以使得训练后的模型识别时不受几何变换影响。(2)模型参数初始化:在上一个小节中定义的卷积神经网络中包含了大量的权值矩阵和偏置向量参数,这些参数初始化策略有很多种,不同的初始化策略可能会对模型求解过程和参数收敛速度有一定的影响,常见的有标注初始化[7]、随机正态分布初始策略、Gram–Schmidt 正交化初始策略以及随机正交初始策略[8],本文采用最常见的随机正态分布初始策略来初始化网络中的权值。(3)获取下一批数据:使用全部训练集数据来训练会使得模型计算量过大而增加训练时间。试验证明采用小批量加入随机噪音的训练方式可以显著提高训练效果[9]。因此,本文每次在训练集中随机选取一定数量的样本作为同一批次训练数据来训练模型,后文中将批次数量记做 batch_size值。(4)模型参数优化:该步骤定义了模型的损失函数、优化器、学习率等训练的基本要素,通过反向传播算法[10]来寻找模型梯度下降的路径,不断改进模型达到对模型参数优化。同时,为了避免过拟合现象,在模型中插入了丢弃层,通过调整丢弃层的保留比例来动态控制需要保留连接边的数量,后文中将保留比例记做 keep_prob值。(5)评估模型准确率:在每个小批次训练过程中,需要对上一次训练的模型中的好坏进行评估,本文统计每个小批次数据在模型识别准确率,即在新的批次数据中统计模型中识别正确的数量占该
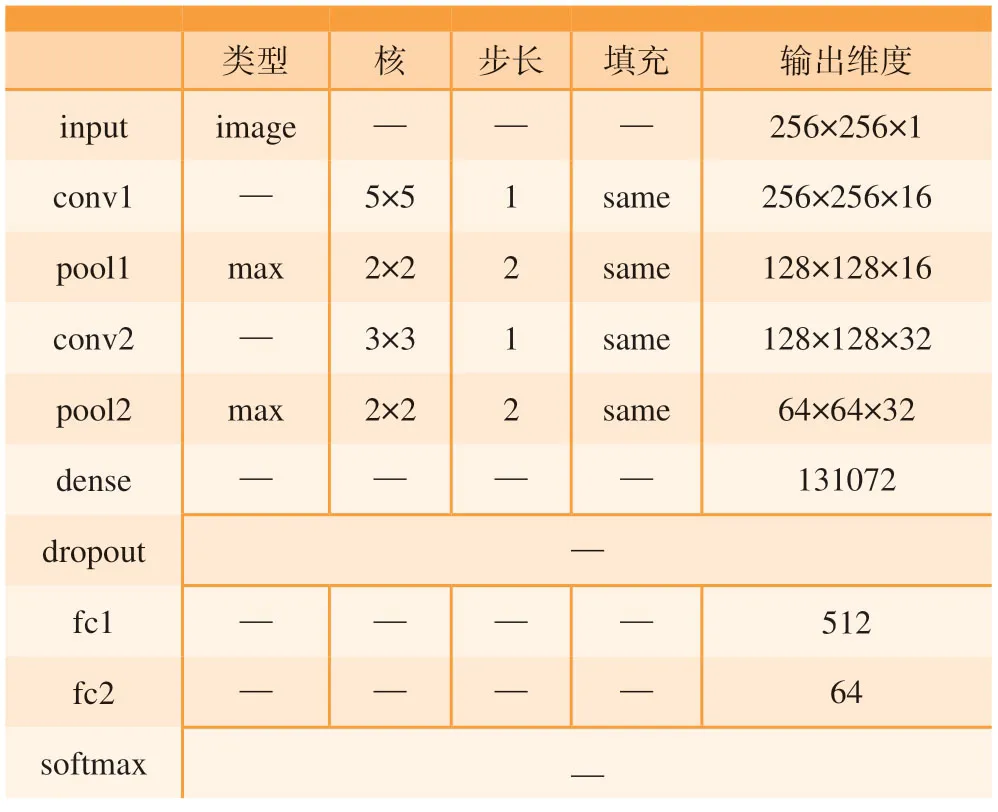
表1 卷积神经网络参数Table1 Parameters of convolutional neural network

图2 模型训练流程图Fig.2 Training flow chart of the model
3 应用案例及试验分析
3.1 试验数据
本文试验数据是某单位检测中心自2014年至2018批次总数量的百分比。(6)训练终止条件:模型训练过程需要定义算法的终止条件。通常定义终止条件有两种:一种是预先定义算法迭代次数;另一种是预先定义损失值的终止范围,本文中采用前者作为终止条件,后文中将总迭代次数记做epochs值。年总共5年的检测报告中的影像数据。样本数据是航空发动机中整流叶片检测结果图像,可分为正样本和负样本两类,正样本是检测合格的产品,负样本中出现非焊合缺陷,是检测不合格的产品。试验数据一共包含46101 条数据,其中23191 条正样本和22910 条负样本。图3列举了试验数据的部分正负样本,其中,图3(a)为正样本,图3(b)为负样本。
3.2 机器学习平台的试验环境
本文中机器学习平台训练的硬件环境是Nvidia Tesla V100 16GB 型号计算级别显卡,搭载了48核心Intel(R)Xeon(R)Gold 5118 2.30GHz的CPU。平台的软件环境是基于CUDA 10 运行时环境,使用cuDNN v7.4.2.24 库加速卷积计算过程;在Python 3.6.5中编译了TensorFlow 1.12.0 wheel 安装包作为基础开发框架。
3.3 机器学习平台训练过程分析
机器学习平台训练过程详见2.2节,本文为评估机器学习的训练效果一共做了3组独立随机试验。每组试验选取的迭代次数epoch值为1400 次,保留比例keep_prob值为0.6,批数量batch_size值分别为200、300和400。训练的识别准确率随训练迭代次数变化如图4所示。
(1)图4中的3个子图的横轴表示迭代次数;纵轴表示对应的识别准确率的百分比;蓝色实线为识别准确率为50%分位线;红色虚线是准确率为96%分位线。可以看出:在模型初始化权值的情况下,识别准确率一般在50%左右;随着训练迭代次数的增加,模型的识别准确率不断提高,在3 次小组试验中都达到了96%以上。机器学习平台的训练过程是有效的。
(2)图4中的3个子图从上至下依次将批数量batch_size值设置成了200、300和400。通过对比3张子图可以看出,不同batch_size值对模型的识别准确率最终收敛效果影响较小,只是识别准确率收敛速度不尽相同。由此可见,在进行小批量的训练时,batch_size值的选取只要在合理的范围内就不会对模型训练过程产生较大的影响,最终都可以得到较优的模型。
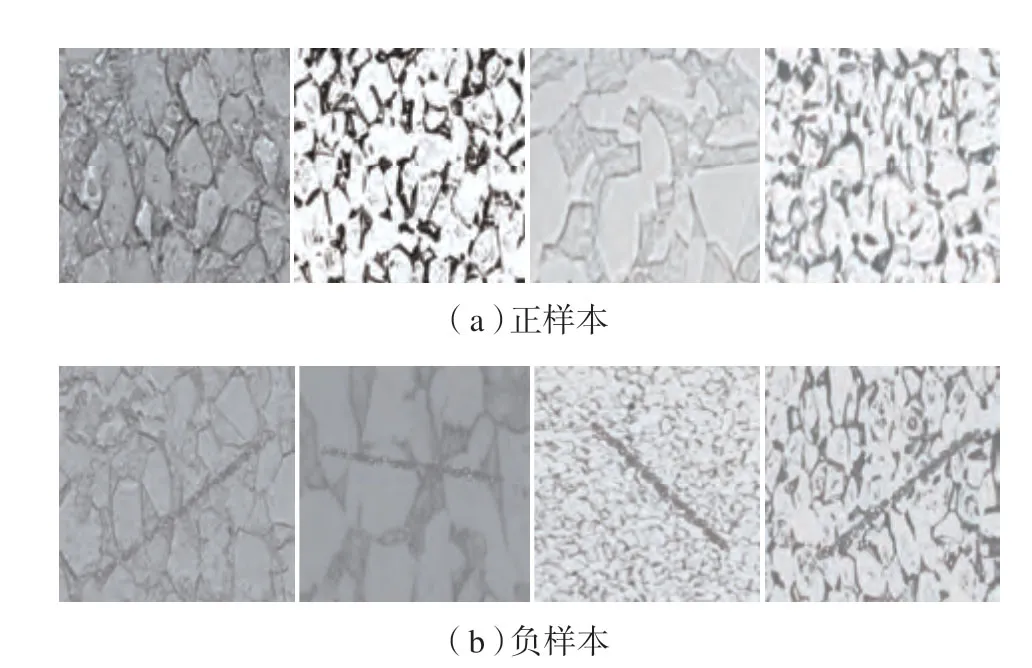
图3 正负样本试验数据示例Fig.3 Example of positive and negative sample data
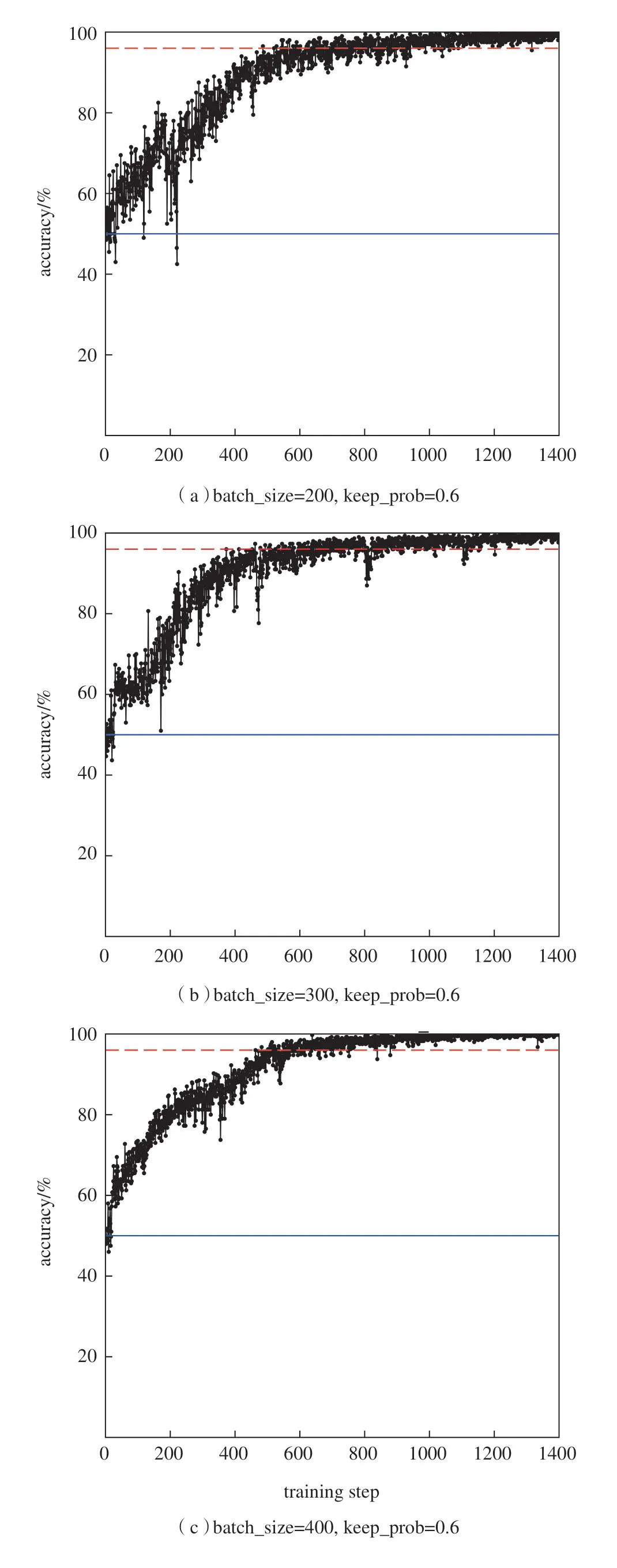
图4 准确率随训练迭代次数变化Fig.4 Accuracy rate as a function of training iterations
通过上述分析可以得知:机器学习平台在训练集的训练效果是合理有效的,通常可以达到96%的识别准确率。
3.4 机器学习平台在测试集上识别结果评估
本文将试验数据按照0.9比值划分成了训练集和测试集。首先在训练集数据基础上训练好模型,然后在测试集上做预测试验,最好,计算出准确率、正确率、召回率和F1值。相关参数的计算公式为:


式中,TP表示把正类预测为正类的数量;FP表示把负类预测为正类的数量;FN表示把样本中原来正类预测为负类的数量。
本试验分别变化迭代次数epoch、批数量batch_size和保留比例keep_prob 这3个参数。其中,epoch值选取了1000、1200和1400 3个数值;batch_size值选取了200、300和400 3个数值;keep_prob值选取了0.6和0.9这两个数值。本文共完成了18 组独立随机试验,试验的结果统计如表2所示,根据试验结果统计可以看出:
(1)18 组独立随机试验中的epoch 数值从1000、到1400 变化,平均准确率最低达到93.8%,最高达到95.9%,并且随着训练次数的增加平均准确率不断提高。纵观这18 组试验结果,识别准确率最大值出现在epoch为1400,batch_size为200,keep_prob为0.6的第13小组试验,识别准确率高达97.6%。所以本文中建立的机器学习平台可以出色地完成扩散连接缺陷自动检测任务。
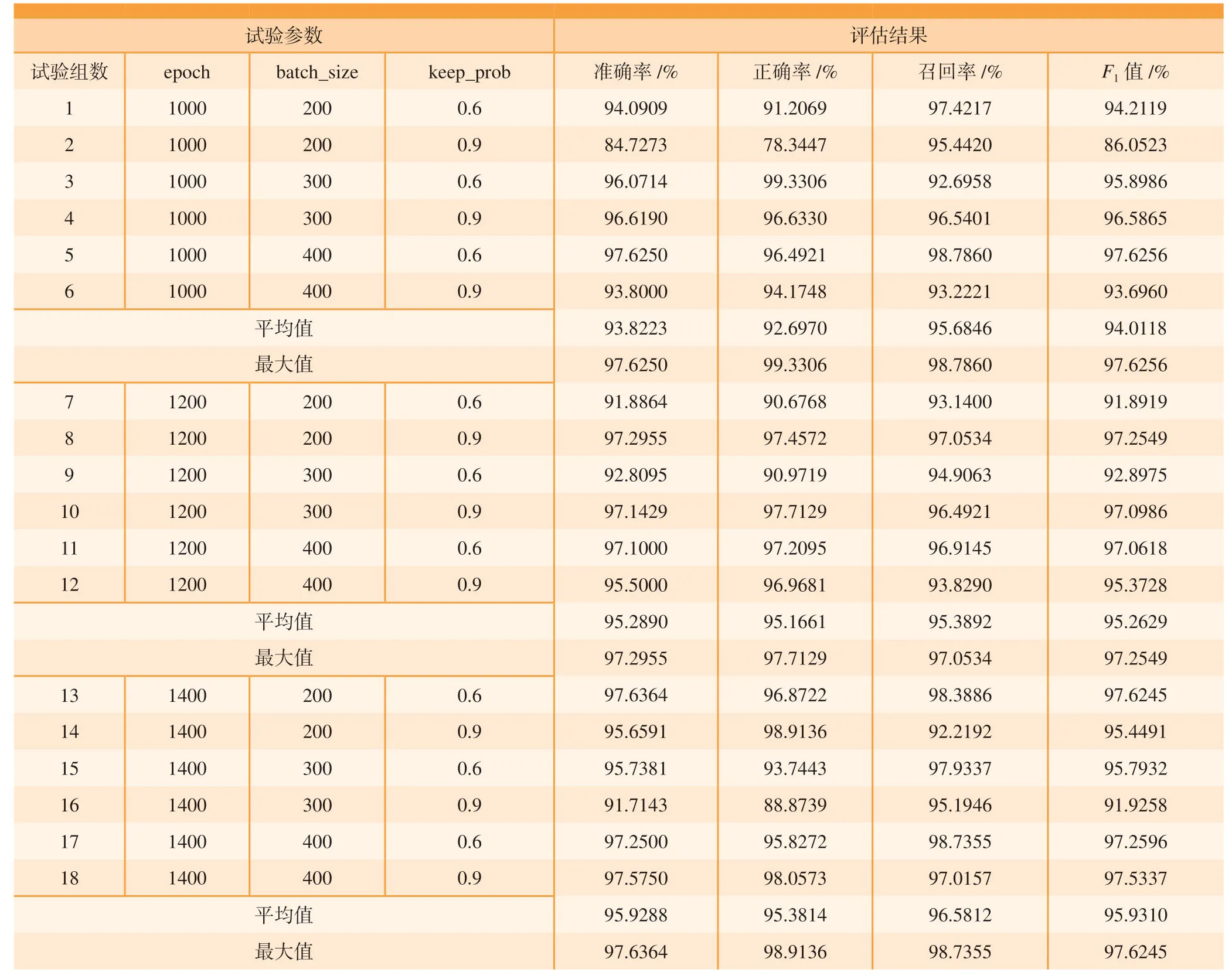
表2 测试集各项试验结果统计表Table2 Statistics of experimental results in test set
(2)在18 组预测试验中,正确率平均值最低达到了92.7%,召回率平均值最低达到了95.3%,F1值平均值最低达到了94.0%;正确率最大值达到了99.3%,召回率最大值达到了98.8%,F1值最大值达到了97.6%。所以,本文中建立的机器学习平台在对大规模扩散连接检测任务中可以高效地提取有缺陷的样本,优化人工检测流程。
通过在测试集上的对照试验结果分析,可以得出:本文设计的自动识别模型的识别准确率已经基本满足减少人工重复工作的需求。本模型在实际应用场景中测试能到达约1500 张/s的处理速度,能够很好地完成非焊合缺陷自动识别任务。
4 结论
本文针对目前扩散连接缺陷检测人工处理效率低和检测人员长期工作容易产生疲劳漏判的现状,提出了构建对扩散连接缺陷检测的机器学习平台总体设计方案。此外,还将机器学习平台应用到整流叶片缺陷检测实际工业案例中,完成了在某单位近5年内总计46101条的整流叶片检测影像数据集上的评估试验。试验结果证明:本文所提出的缺陷检测模型对整流叶片非焊合缺陷的识别准确率可以达到96%以上,并且在测试集中也表现出很好的预测效果。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电影(2018年8期)2018-09-21
