
利用LSF API实现GPU集群的并行机时统计
2020-12-07 06:08盛乐标游伟倩张予倩周庆林
计算机时代 2020年11期
盛乐标 游伟倩 张予倩 周庆林
摘 要: 近年来GPU的使用越来越广泛,更多的高性能计算集群采用CPU和GPU的异构架构。准确的GPU计算机时统计,是大型计算机集群执行计费政策的基础,但作业调度软件LSF并未提供简便直观的GPU计算机时统计功能。文章提出利用LSF API结合C语言、MPI和Shell脚本语言等进行编程来解决,实现多样化、可定制的GPU计算机时统计和报表制作,为高性能计算中心和超级计算中心的管理带来便利。
关键词: 高性能计算; 集群管理; GPU集群; 机时统计
中图分类号:G482 文献标识码:A 文章编号:1006-8228(2020)11-63-03
Abstract: In recent years, GPUs have become more and more widely used, and more high-performance computing clusters have adopted heterogeneous architectures of CPU and GPU. Accurate GPU computation time accounting are the basis for large computer clusters to implement billing policies, but the job scheduling software LSF does not provide simple and intuitive methods for GPU computation time accounting. By using LSF API, programming with C language combined with MPI and Shell scripting language etc. is a good resolution, which can realize diverse and customizable GPU computation time statistics and make corresponding reports, so as to bring convenience to the management of high-performance computing centers and supercomputing centers.
Key words: high performance computing; cluster management; GPU cluster; computation time accounting
0 引言
高性能計算在科学研究、国防建设以及科技发展中发挥着重要作用,人们对此已经取得广泛共识[1]。随着计算需求的不断增长,国内外对高性能计算集群的建设兴趣也有增无减,欧美、日本、中国等在E级超级计算机的研发和建设方面更是投资巨大。在国内,除了建设多个国家超级计算中心,高校和科研院所也不断地增加高性能计算方面的投入[2-4]。近年来,随着人工智能的迅速发展,对GPU服务器的需求急剧增加,新建的大型集群往往都采用CPU和GPU的混合架构。由于各地高性能计算中心或超级计算中心都采取收费政策,因此,准确的CPU和GPU计算机时统计数据是超算中心或高性能计算中心进行计费的前提,并且可以为管理者提供可靠的分析数据,辅助管理者进行相关决策。目前,LSF、PBS Pro等作业调度软件所提供的计算机时统计功能还不太完善,并不适合高性能计算中心的个性化需求[5-7]。以IBM公司的Spectrum LSF 10.1为例,其提供的bacct命令只能查询某段时间内用户累计使用的CPU time,而不能提供对应的wall time,同时也无法直观获取计算作业使用的GPU卡数量。因此,对GPU机时的统计会遇到诸多困难,但高性能计算中心又的确在这方面有切实的需求。之前,我们设计过利用LSF API实行CPU机时的统计[7],在前面工作的基础上,本文将探讨一种利用LSF API实现对GPU计算机时进行高效统计的并行程序设计方法。
1 GPU计算机时统计策略
超算中心对计算资源的计费,往往是依据用户对计算资源的实际占用时间,这样比较客观和公平。GPU服务器的计算机时,主要分为两部分,即CPU计算机时和GPU计算机时。CPU计算机时一般采用wall-clock time(简称wall time)与所用CPU核数的乘积进行CPU计算资源使用量统计,单位为核时;GPU计算机时与此类似,也可采用wall time与所用GPU卡数量的乘积进行GPU计算资源使用量统计,单位为卡时。CPU计算机时的统计方法,我们在之前的文章中已有充分阐述[7],本文重点阐述的 GPU 计算机时的统计,主要解决两方面的问题:一是获得作业占用的GPU卡的数量;二是机时统计程序的并行化。这里需要特别提醒的是,不宜大范围使用CPU time作为作业CPU机时的统计,因为CPU time忽略了I/O和系统开销等对计算资源的实际占用时间;在过去一些不支持CGROUP的旧版操作系统和旧版LSF,有些多线程程序在实际运行时会占用节点内比申请数更多的CPU核资源,这时CPU time会高于wall time与所用CPU核数的乘积,出现这种情况时使用CPU time是对机时损失的一种补偿。随着虚拟化技术的不断进步,新的Linux操作系统内核已支持CGROUP资源隔离,新版LSF也加入了相应支持,计算节点和LSF同时启用CGROUP功能,则可以规避上述问题。
2 软件设计
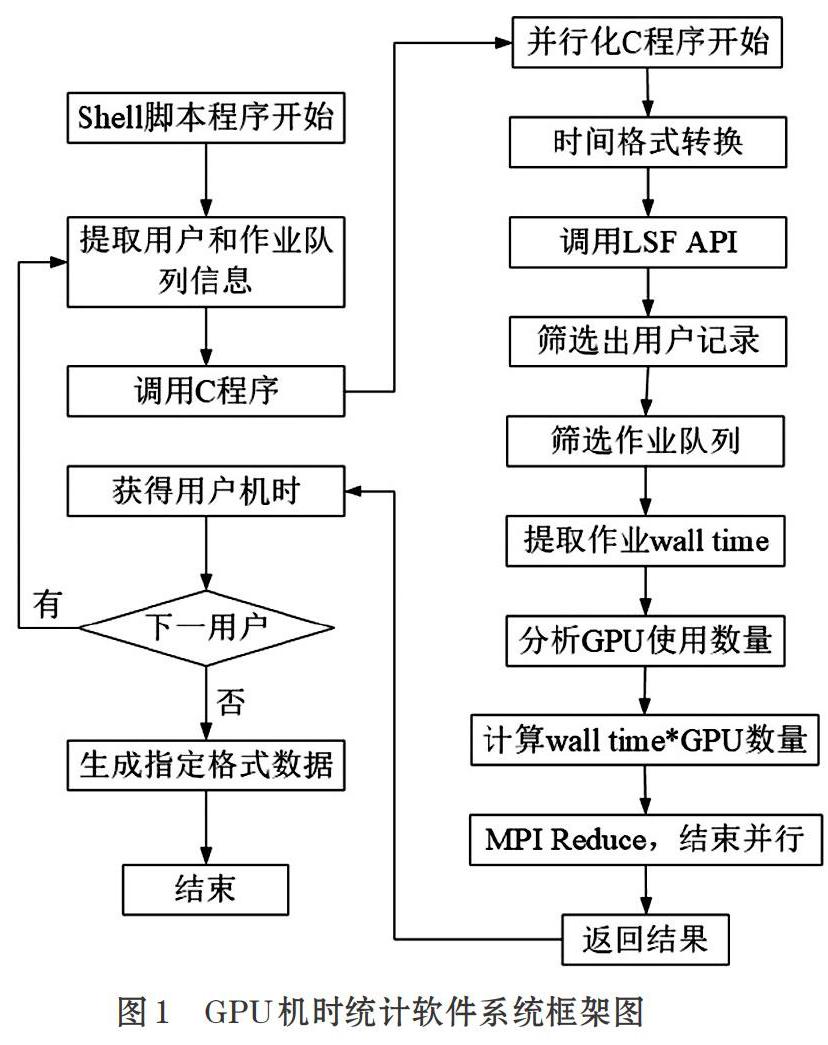
由于IBM Spectrum LSF 10.1的计算机时统计程序bacct本身并不包含对作业wall time和GPU机时的统计,因此我们必须通过编程手段来实现相关统计。Spectrum LSF提供了应用程序接口API,方便我们灵活地通过编程实现一些个性化的需求。本文中介绍的GPU计算机时统计软件主要由一个C语言程序和一个Shell脚本程序构成,软件框架图见图1。
C语言程序负责调用LSF API库函数进行作业wall time统计和作业使用的gpu卡数量的统计,是整个软件的核心部分;MPI相关语句实现核心计算部分的并行化;脚本语言则在调用C语言程序的基础上分析出各个用户在不同队列不同时间段的计算资源使用量。
2.1 LSF API
Spectrum LSF API主要包含两种类型的库:一种是LSLIB,这是LSF的基础库,为外部应用使用LSF的基础服务提供支持;另一种是LSBLIB,LSF的批处理库,为外部应用提供作业查询、提交、控制、操作等的批量处理服务接口,也可实现对批量日志文件的读取与分析。本文中介绍的程序主要涉及LSBLIB库中的两个数据结构eventRec、jobFinishLog和一个函数lsb_geteventrec()。lsb_geteventrec()函数需要读取LSF的lsb.events或lsb.acct文件,这些文件记录了与用户作业有关的关键信息。在使用LSF API的LSBLIB库函数前,需要调用lsb_init()函数进行LSBLIB的初始化。
2.2 C语言编程
此部分主要是利用lsb_geteventrec()函数来实现对作业从开始到结束的所用时间进行统计,程序设计时涉及到多个C语言头文件,包括:stdio.h、stdlib.h、string.h、time.h;另外还包括两个LSF软件所提供的头文件:lsf.h和lsbatch.h。
2.2.1 时间格式转换
由于该程序操作的主要对象就是时间,然而LSF的bacct程序对时间有一定的格式要求,为了程序设计的统一,我们将此C程序所需读入的时间参数格式确定为“年/月/日/小时:分钟:秒”,如“2020/7/10/0:0:0”。另外,由于历史原因,计算机的计时系统存在一个千年问题,因此也需要在时间格式转换时加以考虑。时间格式转换的具体实现方法可以参考我们之前的相关工作[7]。
2.2.2 获取作业wall time
该部分需要实现对某段时间范围内某用户在某个队列或某些队列中的作业使用的wall time、CPU核数和GPU卡数进行统计。Wall time可以通过作业结束时间减去作业开始时间获得,作业所用的CPU核数也可以通过finishJob->numExHosts获得,但是LSBLIB的jobFinishLog函数中并未直接提供作业所用GPU卡数量的相关变量,这就给我们提取GPU卡数量带来了困难。不过,jobFinishLog函数提供了gRusage结构化数据,在该结构化数据中包含了GPU_ALLOC、GPU Models、GPU Factors等信息,这些信息经过处理,可以分析出实际使用的GPU卡数量。以GPU Models为例,在gRusage的结构化数据中,通过提取JOB_GPU_ALLOC键值对,可以获得类似GPU_MODELS="TeslaK40c-11441{0[0,1]1[0,1]}"这样的信息,该信息明确了作业使用了哪些GPU计算节点的哪些GPU卡,而GPU卡的计数通过上述信息则很容易统计。
程序的关键部分如下(省去了变量声明、参数检查、lsb.events/lsb.acct文件检查等部分):
/* gpu_s为gRusage中获取的结构化数据,gpu_np为
GPU_FACTORS字符串的长度*/
for (;;) {
record=lsb_geteventrec(fp, &lineNum);
finishJob=&(record->eventLog.jobFinishLog);
if (strcmp(finishJob->userName, userName)==0 &&
strcmp(finishJob->queue, queue)==0) {
np2=finishJob->numExHosts;
if (finishJob->endTime>startt && finishJob->
endTime<=endt) {
walltime=walltime+(finishJob->endTime-
finishJob->startTime)*np2;
if(gpu_s) {
strncpy(gpufactors, gpu_s, gpu_np);
strtok(gpufactors, delim3);
while((numchar=strtok(NULL, delim3))) {
ngpus++; }
gpuwalltime=gpuwalltime+(st2-st1)*ngpus; }
cput=cput+finishJob->cpuTime; }}
else {
continue;}}
2.3 代碼的并行化
基于上一节的内容,我们获得了某用户在某段时间内某个队列的计算资源占用时间;然而,随着集群规模的不断增大、集群用户数的增多和完成作业数的急速增长,如果沿用串行的编程方法进行一次完整的计算机时统计就相当费时。因此,对串行代码的并行化变得非常必要。为了实现并行化,我们需要在某个或某些维度,对串行程序进行切分,比如用户维度、作业队列维度等;但是,由于不同用户在不同队列的计算作业数是个动态变化的量,因此,通过用户维度或队列维度并不能有效地使计算量均衡分布于各个计算节点。另外,通过进一步研究LSF API处理事件日志的工作机制发现,其并未提供批量的事件文件和记账文件的读取方法,但LSF基础配置中可以对事件文件和记账文件按文件大小或记录时间进行存档。在我们的并行化方案中,选择按文件大小来进行事件文件和记账文件的存档,然后通过不同计算节点计算不同存档文件,实现程序的并行化。除了最新的未存档文件,每个存档文件的大小相同,在存档文件足够多的情况下,这也将使计算负载可以较为均衡地分布于各个计算节点。
