
基于CNN+LSTMAttention的营销新闻文本分类
2020-12-04 07:50刘高军王小宾
计算机技术与发展 2020年11期
刘高军,王小宾
(北方工业大学 信息学院,北京 100144)
0 引 言
近年来,许多公司宣传自己的产品使用了一种新型营销方式-营销新闻,营销媒介经过多年的演化之后形成了营销新闻。营销新闻同新闻一样从多方面多角度给用户灌输产品信息、产品理念等,通过传播产品资讯信息来引导消费者购买。但是随着信息技术和互联网的迅猛发展,千人千面的信息推荐方式给亿万网民的阅读带来了便利,但同时营销、低俗、标题党等低质量新闻的掺杂也给用户带来了不同程度上的困扰。为了给用户更好的阅读体验,需要识别出有营销意图的新闻,因此文本挖掘技术的研究变得越来越重要。文本分类作为高效的挖掘技术和信息检索,对文本数据的管理有着重要的作用,目前已经广泛应用于垃圾邮件检测[1]、舆情分析[2]和新闻分类[3]推荐等场景。文本分类使用传统机器学习,自然语言处理和深度学习技术来有效地分类和发现不同类型的文本。如何从这些庞大的文本中提取有价值的信息并自动检索,分类和汇总,是文本挖掘的重要目标,因此利用文本分类技术对营销新闻进行分类识别近年来成为一个值得研究的课题。
文本分类是数据挖掘的重要组成部分,它对大量文本的分类和挖掘具有重要的理论和应用价值,它的主要任务是将给定的文本集划分为几种已知的类型集合,例如将新闻文本分为带有营销意图的垃圾新闻和普通的新闻,又比如分辨一个文本是人类作者还是机器自动生成的等等。目前文本分类任务已经应用到了许多领域,如主题分类、垃圾邮件检测、情感分析等。要解决这些问题,研究者需要对数据进行获取分析、挖掘、归类,帮助人们提高信息检索的效率。该文的主要工作是融合CNN和引入注意力机制的LSTM模型解决营销新闻文本识别分类的问题。
1 相关工作
文本分类技术是自然语言处理领域中的重要应用,它将文本分类为预定义的类别,在当今的网络时代,文本数据已成为最常见的数据形式之一,例如:用户评论[4]、新闻、电子邮件等。文本分类的基本过程通常包括:文本预处理[5],特征提取[6],文本表示[7]和分类器训练[8]。传统的特征表示方法通常会忽略上下文。对于捕获单词的语义,文本中信息的顺序仍然不能令人满意。同时,特征提取的方法存在数据稀疏、维度爆炸等问题,降低了训练模型的泛化能力。
深度学习在图像处理和语音识别等研究领域取得了令人瞩目的成就,在自然语言处理中也发展迅猛。深度学习技术已逐渐取代传统的机器学习方法,并已成为文本分类中的主流技术。深度学习可以更准确地表达对象,并且可以从海量数据中自动获取对象的特征。基于此类功能属性的深度学习模型包括卷积神经网络(CNN)[9]和递归神经网络[10]。
如何对这些海量文本数据进行有效的分类受到了极大的关注。2013年崔建明等人提出基于支持向量机的文本分类[11],使用支持向量机(SVM)算法优化文本分类器的参数,从而提高了文本分类器的分类精度。2017年武永亮等人提出基于TF-IDF和余弦相似度的文本分类方法[12],传统的机器学习方法被用于分类。TF-IDF模型用于提取类别关键字,并通过这些类别关键字和需要分类的文本关键字进行余弦相似度计算。2011年姚全珠等人提出基于LDA的文本分类研究[13],提到基于隐式Dirichlet分布的LDA模型和SVM算法的文本分类,但是在大量的短文本中,有短文本长度和过多的噪声,分类效果不好。2017年夏从零等人提出了基于事件卷积特征的新闻文本分类[14],通过卷积神经网络从新闻文本中提取特征文本,以对文本进行分类,但是,尽管这种方法可以很好地提取特征,但是通常会忽略上下文并且文本语义不够准确。
基于以上考虑,该文拟结合卷积神经网络(CNN)和引入注意力机制的长短时记忆网络结构(LSTMAttention)来解决营销新闻文本分类的问题,提出一种新的新闻营销文本分类的训练模型CNN-LSTMAttention,以提高新闻营销文本分类的准确率。实验是使用搜狐新闻给出的数据集进行训练和测试的,并使用单个基模型进行了比较。结果表明,与其他单个模型相比,该融合方法对营销新闻分类具有一定的提升。
2 模 型
本节将描述神经网络体系结构的组件(层),并且逐层介绍使用地神经网络中的神经层。
2.1 CNN用于字符级表示
之前Santos和Zadroznw,Chiu和Nichols的研究表明[15],CNN是一种有效的方法,可以从单词的字符中提取形态信息,并将其编码为神经表示。图1显示了用于提取单词的字符级表示的CNN。CNN与Chiu and Nichols中的CNN相似,不同之处在于该文使用了字符嵌入作为CNN的输入,而没有字符类型特征。在将字符嵌入输入到CNN之前添加dropout layer。

图1 用于提取单词字符级表示的卷积神经网络
2.2 引入注意力机制的LSTM
2.2.1 LSTM单元
Hochreiter和Schmidhuber[16]在1997年提出了LSTM的网络结构,引入CEC单元解决了RNN的梯度爆炸和梯度消失的问题。LSTM由输入层、隐藏层和输出层构成。LSTM区别于RNN的地方在于,它在算法中加入了一个判断信息有用与否的“处理器”——cell,一个cell当中被放置了三扇门,分别叫做:输入门it、遗忘门ft、输出门ot,LSTM还有一个记忆单元ct,这些结合起来能够提高LSTM处理长序列数据的能力。图2给出了LSTM单元的基本构图。

图2 LSTM单元示意图
在时间t更新的时候,LSTM单元的公式为:
ft=σ(Wf·[ht-1,xt]+bf)
it=σ(Wi·[ht-1,xt]+bi)
ot=σ(Wo·[ht-1,xt]+bo)
mt=tanh(Wm·[ht-1,xt]+bm)
ct=ft*ct-1+it*mt
ht=ot*tanh(ct)
其中,it、ot和ft分别为输入门、输出门和遗忘门,W和b是模型的参数,σ表示sigmoid函数,输出在0,1之间,tanh表示双曲正切函数,输出在-1,1之间,mt是当前节点的输入数据,Ct-1是上一个LSTM节点的输出信息。
2.2.2 注意力层
注意力机制(attention mechanism)源于对人类视觉的研究。因此注意力机制最早是应用在图像领域的。在自然语言处理领域,注意力机制最成功的应用是机器翻译。基于神经网络的机器翻译模型也叫神经机器翻译(neural machine translation,NMT)。一般的神经机器翻译模型采用“编码-解码(encoder to decoder)”的方式进行序列到序列的转换。通过注意力机制直接从源语言的信息中选择相关的信息作为辅助,可以有效地解决编码向量的容量瓶颈问题和长距离依赖问题,无需让所有源语言信息都通过编码向量进行传递,在解码的每一步都可以直接访问源语言的所有位置上的信息,同时源语言的信息可以直接传递到解码过程中的每一步,缩短了信息传递的距离。因此在传统机器学习模型中引入注意力机制会有效地提升模型的实用效果。该文对LSTM模型进行改进,将注意力机制引入LSTM模型当中。

图3 引入注意力机制示意图
图3所示输入层中的词向量X1,X2,…,Xn,通过输入到上层的LSTM单元层中,在隐藏层输出的过程中,引入注意力机制,分配各个输入的注意力概率的分布值A0,A1,…,An,之后加和求平均到V。
分配权重公式为:
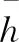
2.3 ATTLSTM-CNN
最后,文本通过将引入注意力机制的LSTM加权求平均之后,输出给softmax层,从而进行全连接操作,最后得到预测分类结果Y,从而构建整个神经网络模型。图4为神经网络主要架构。

图4 神经网络主要架构
对于每个单词,有字符嵌入作为输入,由图1中的CNN计算出字符级表示。然后将字符级表示向量与单词嵌入向量连接起来,以输入到LSTM层,在LSTM的隐藏层上引入不同权重的注意力机制分配,最后加权求平均,经过softmax全连接得到分类结果。
softmax得到预测分类结果Y,公式为:
Y=softmax(Wvv+bv)
3 实 验
3.1 数据集
本次实验是在Linux系统下进行的,使用GPU是Cuda -v 9.0,实验编程语言为Python3.6,使用到的深度学习框架为PyTorch 0.4.0。实验数据集的来源为搜狐新闻数据,从中提取出用于训练词向量的新闻文本语料,大约40 000条左右,根据有标注的训练集,分为0:无营销新闻,1:部分营销新闻,2:全营销新闻,利用没有经过训练的测试集文本数据去评估模型的分类效果。
3.2 实验评价指标
本次实验使用三个评价指标来衡量模型的效果,包括准确率(precision)、召回率(recall)和F1值:
3.3 实验设置及结果分析
本次实验针对新闻语料数据集,使用CNN模型、LSTM模型、LSTMAttention模型和CNN+LSTMAttention融合模型对新闻进行分类。
CNN模型:输入卷积神经网络的是经过word2vec训练后的词向量形成的矩阵,从而进行分类。
LSTM模型:输入长短期记忆神经网络的是经过word2vec训练后的词向量形成的矩阵,从而进行分类。
LSTMAttention模型:经过word2vec后得到的词向量矩阵输入到引入注意力机制的LSTM模型中。
CNN+LSTMAttention融合模型:使用word2vec训练后的词向量矩阵作为输入,CNN计算出字符级表示。然后将字符级表示向量与单词嵌入向量连接起来,以输入到LSTM层。
通过以上三个评价指标对本次实验的分类结果进行衡量。为了说明本次实验当中引入注意力机制的LSTM模型,再融入CNN模型中对分类结果的影响,使用对比实验的方式将CNN+LSTMAttention融合模型与CNN模型,经典的LSTM模型,LSTMAttention模型的分类结果进行对比。通过相同数据集上对比实验结果说明本次融合实验的优势,实验结果如表1所示。
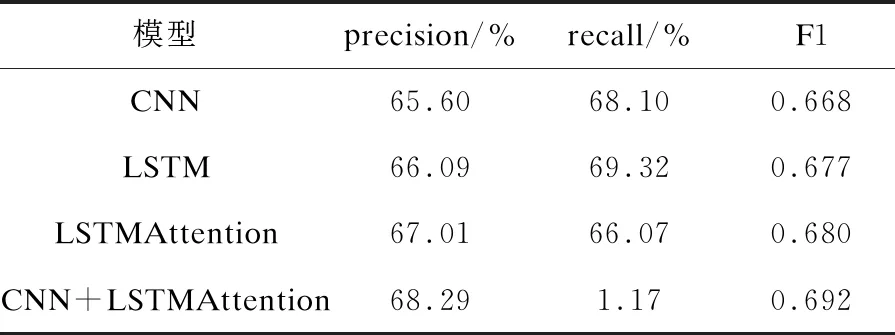
表1 不同分类模型的分类结果比较
从表1可以看出,在相同数据集的基础上,CNN模型的分类效果略次于LSTM模型,而通过引入注意力机制的LSTMAttention模型要表现的比LSTM好,因为在特征提取的过程中,LSTMAttention模型会更多地关注句子中更加重要的词语信息,进而减少那些不重要的信息带来的干扰。该文提出的CNN+LSTMAttention将CNN和LSTMAttention相结合,能够更好地完成分类任务。
此外,本次还设计了显著性检验实验,在搜狐新闻数据集上使用准确率、召回率、F1值进行评价,从而进一步验证CNN+LSTMAttention模型与其他神经网络模型CNN、LSTM以及引入注意力机制的LSTMAttention模型的比较结果,如图5~图7所示。
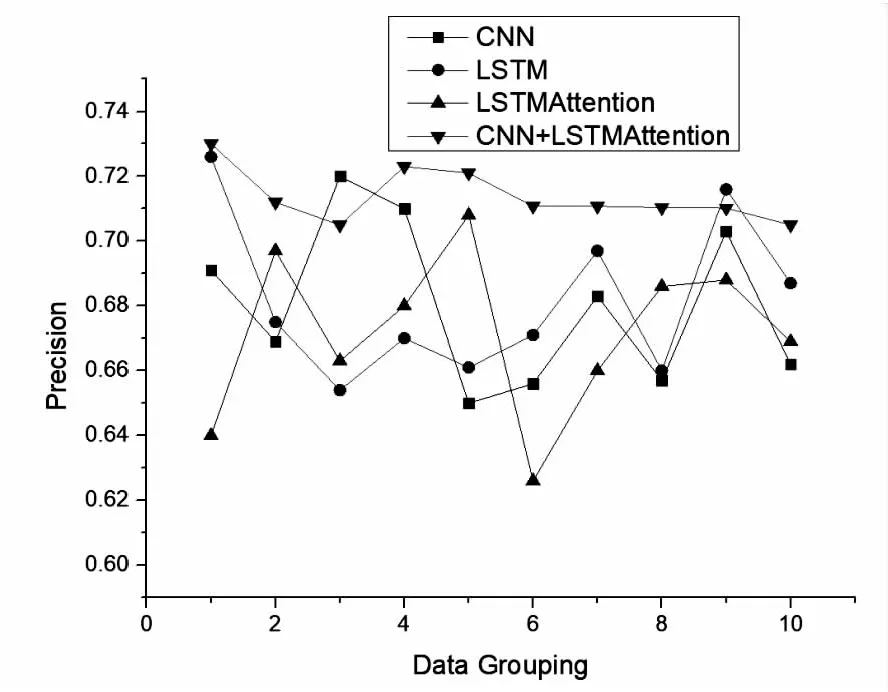
图5 模型的准确率评估对比

图6 模型的召回率评估对比

图7 模型的F1值评估对比
从图5~图7可以看出,在准确率、召回率和F1值的评估中,对于相同的搜狐新闻语料数据库,CNN+LSTMAttention模型在三个评估指标大多分布在其他三个模型之上,评估指标准确率基本在0.72左右,F1值也明显高于其他三个模型。因此该文提出的CNN+LSTMAttention融合模型的分类效果要优于CNN模型,LSTM模型和引入注意力机制的LSTM模型。
4 结束语
提出了一种融合CNN和LSTMAttention的营销新闻分类,首先将大量的营销新闻语料使用word2vec来训练,然后再从这些训练的新闻文本信息中提取出新闻的文本特征表达-词向量,与其他用于提取特征值的深度学习方法相比较,word2vec可以高效地对大流量本文数据进行分析,将文本word映射到数值空间,进行特征提取,再用提取好的新闻特征向量输入到预先准备的分类模型中,最后使用softmax分离器构建分类模型。根据实验,可以看出提出的CNN+LSTMAttention模型对于营销新闻的分类效果相对于CNN模型和引入注意力机制的LSTM模型都有了一定的提升,但是,实验只用了中文新闻语料,没有使用英文新闻语料。下一步的研究工作可以尝试使用该模型对英文新闻语料进行分类,而且可以尝试不用Pytorch深度学习框架改用tensorflow深度学习框架进行自然语言处理。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
软件(2017年6期)2017-09-23
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
