
主成分分析法和K-均值聚类算法在入侵检测系统中的运用
2020-12-03 07:34卢永祥李巧兰
武夷学院学报 2020年9期
卢永祥,李巧兰
(武夷学院 信息技术与实验室管理中心,福建 武夷山 354300)
随着信息时代的到来,计算机网络得到飞速发展,给人们带来便利的同时也遭受越来越严重的网络攻击。网络安全变得尤为重要,国内外广大学者对网络安全防护技术的研究也越来越深入,网络安全防护技术中防火墙技术和数据加/解密技术仅仅是静态防护,在错综复杂网络环境中,单单靠静态的防护是完全不够的。入侵检测系统是对防火墙技术的有效补充,不仅对系统提供实时的防御,而且能主动对穿越防火墙的攻击进行有效的响应,但一般的入侵检测技术,具有效率低、误差率高的特点。针对大数据网络的特征以及目前存在的问题,入侵检测系统自身存在着很多不适宜大数据网络的缺点,容易给外来入侵者机会,对来自网络内部的非法访问也容易误报。这就要求我们研究出一种新的网络数据检测的方法来弥补入侵检测系统的不足。
本文研究集成主成分分析法和K-均值聚类算法相结合的入侵检测系统,主成份分析法是从多元的事物中解析出具有代表性的特征,简化复杂数据,K-均值聚类算法能够减少因高维数据所带来的计算量和计算时间。将这2种算法结合起来对网络流量的数据进行数据预处理,利用主成分分析法提取能代表每一类数据集合的主成分作为入侵检测系统的输入数据,一方面实现了降低数据集合的维数、数量级以及数量,另一方面去除了冗余、非主要特性的特征属性,有效提高了输入数据集合的有效性。再利用K-均值聚类算法对数据集合进行重分类,一方面提高分类的准确性另一方面使得数据集合具有一定的简洁性。并通过实验进行验证,采用检测入侵检测系统性能的标准数据集KDD CUP 99中的部分子集作为仿真实验数据集合,经过对比实验验证基于这两种算法的入侵检测系统具有较高的检测效率和低的误报率。
1 主成分分析法对数据进行降维
主成分分析法(principal component analysis,PCA)是一种用数学推导的方法来实现高纬度数据的降维处理,用主成分分析法PCA来实现数据降维比较简单。PCA算法的步骤有六步。
第一步,计算样本的协方差矩阵


第二步,记特征空间X的协方差矩阵为Σx,并且记该特征空间的协方差矩阵的特征值为λ,前p个特征值分别记为λ1,λ2,…,λp,并假设λ1≥λ2≥…≥λp≥0。
第三步,记每个特征值对应的特征向量为a1,a2,…,ap,则特征向量ai可表示为:

第四步,计算累计方差贡献率,达到85%及其以上时,计算主成分的个数。

第五步,计算所选出的K个主成分的贡献率。

第六步,根据方差贡献率排序,统计出累积方差的贡献率,当累积方差的贡献率达到85%以上时,计算K值,即可计算出能代表原数据特征属性的主成分的个数。
经国内外学者实验证明,当累计方差贡献率超过85%就表示可以代表原特征空间的属性了[1]。我们可以根据这个累计方差的贡献率来求出K,那么这K个主成分就可以用来代表原数据集的主要特征,已达到对高维数据进行降维的目的。
2 K-均值聚类算法对数据进行重分类
K均值聚类算法是一种应用非常广泛的聚类算法,K可以由用户指定,给定一个数据点集合和需要的聚类数目K将各个聚类子集内的所有的数据样本的均值看作是这个聚类的代表点。这个算法的主要的思想是通过一系列的迭代过程把数据集划分成为不同的类别[2],并且每个聚类内部紧凑,聚类间相互独立。目前是应用于工业领域的一种非常有影响的技术。
K均值聚类算法的工作原理是首先确定初始聚类中心,这个聚类中心的确定是从数据集合中随机选取的K个点,然后分别计算除了作为聚类中心的这些点以外的数据集合的其他点到这个聚类中心的距离,并且计算这个距离的大小,最后根据判断距离的大小把数据样本归类到距离它最近的类别中,并形成新的聚类中心[3]。具体算法描述如下:
设数据集合为X,其中X=(x1,x2,…,xd),执行第一步得到分组特征子集记为Xi,其中i=1,2,…,d。

在大数据网络时代背景下,网络数据呈现复杂、冗余、庞大、高维等特性,网络数据集的特性不仅多而且存在着不相干特征属性,特征属性集之间的关系也很复杂,对网络数据集进行重聚类分析,主要应用K-均值聚类算法的聚类过程对网络数据特征属性进行计算。
可以设定不同的K值和聚类中心对网络数据集进行分类,经过研究可通过设置k=2,3,…,u,其中u=,并每次执行时设置随机初始中心,执行u次K均值聚类算法得到u个聚类结果,每个聚类中都被标记为一个特征组合,从而简化了数据量。
3 集合主成分分析法和K-均值聚类分析法的入侵检测系统
基于主成分分析法和K-均值聚类算法对入侵检测系统的输入数据进行预处理的的过程包括,首先进行网络数据集的提取,用主成分分析法对网络数据进行降维处理,最后用K-均值聚类算法对数据进行重聚类。
将主成分分析法和K-均值聚类算法结合起来对网络数据进行预先处理,并将处理后的网络数据集导入到入侵检测系统里,会很大程度上提升入侵检测系统的检测效率,降低误/漏报率。其模型如图(1)所示。
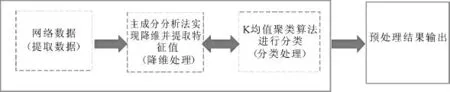
图4-1 集合主成分分析法和K均值聚类算法网络数据预处理模型Fig.1 Network data pre-processing model that assembled principal component analysis method and K-means clustering algorithm
1)提取网络数据集
入侵检测系统以旁路的方式部署在网络中,实时检测流经网络接口的数据包,主要是监测网络中的数据链路层的数据帧、IP数据包等。
2)数据降维处理
对网络数据进行主成分分析实现数据降维并特征值提取,进行数据规范化、标准化,方便后续K-均值聚类算法进行重聚类。
3)对数据进行分类处理
网络数据集经过主成分处理阶段后,再利用K-均值聚类算法对这些网络数据集进行聚类分析,建立聚类中心,并进行标记。
4)输出
对预处理后输出的网络数据集进行入侵检测操作,标记出哪些是正常的网络数据,哪些是异常的网络数据,并对异常网络数据进行处理。
采用集成K-均值聚类算法和主成分分析法的入侵检测系统,一方面监测并预警来自互联网的黑客攻击行为,另一方面也阻击了来自用户群体的误操作、IP地址滥用、非法下载以及违反安全策略的用户行为等。下面通过实验验证得知,这种方法具有高的检测效率和较低的误报率。
4 仿真实验验证及分析
通过主成分分析法提取出数据集的主要成分,再采用均值的方法来对数据聚类,经过这样一系列处理后得到的数据更纯净,特征之间的属性相对更独立,作为入侵检测系统的输入数据更高效和更低的误码率。实验采取数据集KDD CUP 99的10%的特征子集进行仿真实验。
4.1 采用数据集简介
KDD CUP 99数据集是公认比较实用的网络安全审计数据集,分为训练数据集和测试数据集两部分[4]。数据集里每一行代表一条记录,每条记录有42个属性。其中,前面41个属性有41维特征,这些特征又有4种类型,基于TCP连接基本特征(共9种,1~9)、基于TCP连接的内容特征(共13种,10~22)、基于时间的网络流量统计特征(共9种,23~31)、基于主机的网络流量统计特征[5](共10种,32~41)这42个属性中最后一个是标识属性,用来表示该条记录是否正常,如果不正常,将标记出是哪种网络攻击,下面介绍网络攻击的一般种类,一般分为四种类型,表1介绍了该数据集的四种网络攻击类型的分类标识类型。

表1 KDD Cup99数据集的标识类型Tab.1 Identification types of KDD CUP99 dataset
4.2 入侵检测系统的评测标准
评测入侵检测系统性能好坏的最主要的标准之一是检测率和误报率[6],检测率和误报率并给出其公式定义。
定义1检测率 定义检测率为DR,表示入侵检测系统检测出网络数据集合中的数据异常的效率。

其中:TP表示入侵检测系统检测出网络数据中非法数据的数量;FN表示未能识别到的网络数据中非法数据的数量。TP+FN表示入侵检测系统需要处理的总得网络数据量。
定义2误报率 我们定义误报率为FR,误报率表示入侵检测系统对于正常数据流量的误判断占总数据流量的比率。

其中:FP表示入侵检测系统在工作过程中出现错误的判断正常网络数据量的比率;TN表示入侵检测系统能够识别出正常网络数据的数量。
4.3 KDDCUP 99数据集的10%的子集降维处理过程
本文进行仿真实验,为了简化实验数据,利用特征值提取方法提取KDD CUP 99数据集的10%子集的部分属性,如下图2所示为该数据集部分集合截图。

图2 KDD CUP 99数据集10%子集部分记录Fig.2 Partial records of 10%subset of KDD CUP 99 data set
我们利用特征提取的方法,提取该数据集合中属性为的记录,如下图3所示为截取的该数据集合中属性值为的部分记录。
图3 提取特征属性后的数据子集的部分记录Fig.3 Partial records of the data subset after has extracted the feature attributes
对提取特征值的网络数据子集中的部分属性进行主成分分析操作,我们提取了该数据子集的10个属性,组成10维特征向量,可当做1×10维的特征矩阵,提取的数据子集可当做10×1 391的特征矩阵,执行主成分分析后,可以得到网络数据集中代表不同的方差贡献率和累积方差的贡献率。如表2所示。
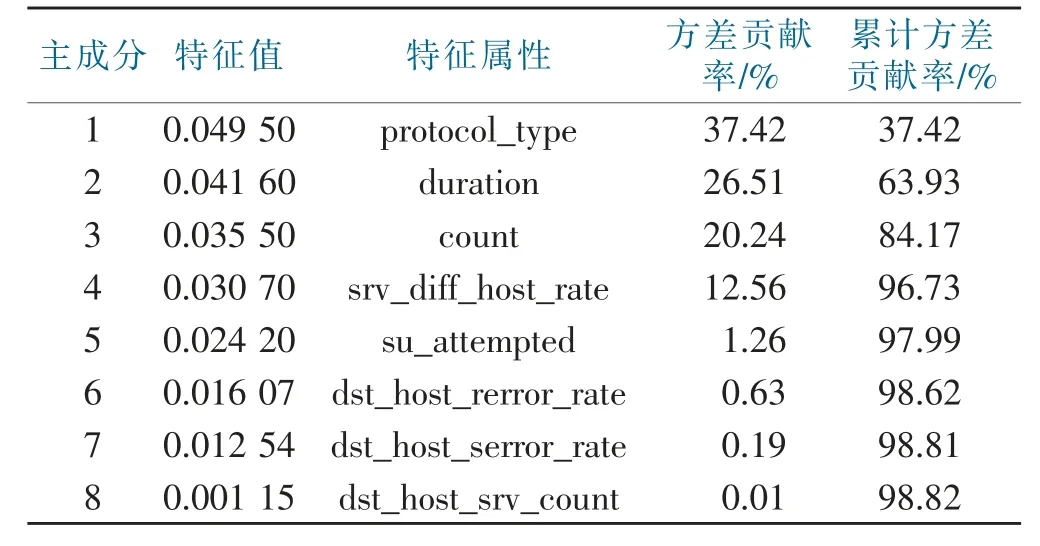
表2 方差贡献率Tab.2 The contribution rate of variance
由上表可明显看出:k=4时,累计贡献率超过85%。即特征值的属性分别为protocol_type、duration、count、srv_diff_host_rat所对应的特征值可以代表我们仿真所选择数据子集的几乎全部特征属性。
我们可以用这4个特征属性的数据代表原提取的10维的特征向量,为后续的分类工作既减少了计算量同时又降低了相关的维数,提高了分类的准确性。下面我们介绍用均值聚类方法对这些数据集合进行分类。
4.4 用K-均值聚类方法进行分类
利用主分分析法对数据进行降维处理以后,接下来就可以进行分类了。从KDD CUP 99数据集合的10%子集的训练集中选出一组,同时从该数据集的测试集中选出三组。其中,训练数据集有21 500条,包括315条是非法入侵网络数据,选取这些非法入侵网络数据时把四类攻击类型的数据都包括进来;测试数据集中每一组包括5 250条,包括65条是非法入侵数据。训练集和测试集中的非法数据占总数据量的比例[0.9%,1.5%],符合聚类的条件。
经过计算,K-均值中聚类的个数K分别为14、18、22、28、36,我们首先标识训练数据类别,用测试网络数据进行测试,得出入侵检测系统的检测率和误报率的结果如表3所示。

表3 K-均值聚类算法检测率和误报率Tab.3 The detection rate and false positive rate of K-means clustering algorithm
从表3可以看出,在对检测网络数据的检测率上集合PCA和均值算法比传统的均值算法检测效率更高,从误报率上来看集合PCA和均值算法比传统的均值算法有明显的降低。
4.5 入侵检测系统检测率和误报率分析
由公式(6)和公式(7)可以计算出采用主成分分析法PCA、信息增益法IG和相关系数法进行比较,基于不同特征提取方法下的均值聚类算法处理后作为入侵检测系统输入数据的检测效率和误报率,结果如表4所示。

表4 3种方法效率比较Tab.4 Efficiency comparison of three methods
从表4可以得出结论,采用主成分分析法和K-均值聚类算法相结合处理对入侵检测系统的输入数据进行预处理具有高检测率和低误/漏报率。下面我们通过图示比较三种方法得出的结果,如图4、5所示。
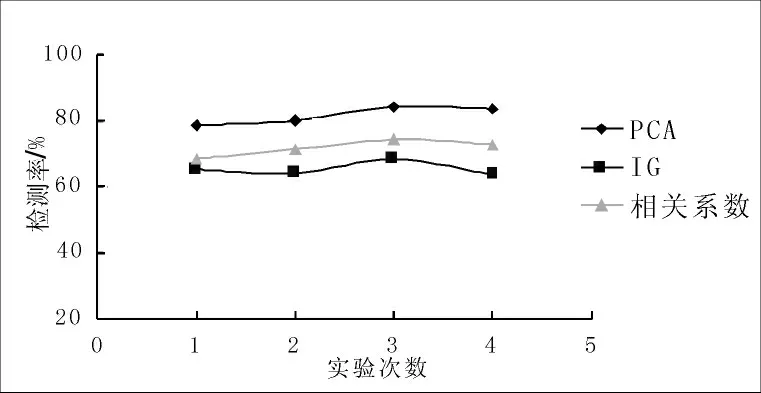
图4 三种特征提取方法得到的入侵检测系统的检测率(%)比较Fig.4 Comparison of detection rates(%)of the intrusion detection systems obtained by three feature extraction methods

图5 三种特征提取方法得到的入侵检测系统的误报率%比较Fig.5 Comparison of false positive rates of the intrusion detection systems obtained by the three feature extraction methods
5 结论
对基于主成分分析法PCA对网络数据进行降维处理,经过数据降维后再用K-均值聚类算法对网络数据进行分类处理。并且通过仿真实验进行验证,实验数据采用KDD CUP 99数据集,经过实验验证本文提出的集合这2种方法来对网络数据进行预处理后应用到入侵检测系统中具有较高的检测率和较低的误报率。
猜你喜欢
防爆电机(2022年4期)2022-08-17
建材发展导向(2022年4期)2022-03-16
智富时代(2019年5期)2019-07-05
智富时代(2019年5期)2019-07-05
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
现代计算机(2018年27期)2018-10-25
数学大世界(2018年35期)2018-02-22
舰船电子对抗(2017年6期)2018-01-11
分析化学(2017年12期)2017-12-25
