
一种基于特征选择与迁移学习的数据预测方法
2020-12-02 01:54:38陈通宝温亮明黎建辉
数据与计算发展前沿 2020年2期
陈通宝,温亮明,黎建辉
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
引言
联合国可持续发展目标(SDGs)已经成为国际社会上最重要的科学议题之一,其主要目的是号召世界各国通过采取措施消除贫穷、保护地球进而确保到2030年时全人类能够实现和平以及繁荣[1]。如何通过相应措施实现科学地监测和评估SDGs 进而据此作出相应战略,是世界各国摸索的重大议题。由国务委员王毅对外发布的《地球大数据支撑可持续发展目标报告》在揭示了地球大数据相关技术对监测评价SDGs的应用价值和前景的同时也为国际社会填补了数据和方法论的空白,进而推动落实2030年议程[2]。由此可见数据在监测评估SDGs中的重要支撑作用,但是数据缺失问题严重影响了联合国对各国目标实行过程的有效监测。
针对缺失数据的处理措施主要可以划分为删除法、加权法以及插补法三种,而插补法通常又可分为统计学插补法以及机器学习插补法两种[3]。删除法主要适用于数据缺失比例较低的大数据集,当数据集的缺失值较多,或者数据集中包含的样本量很少时,采用删除法可能会丢失过多的样本,导致较大误差[4]。均值插补法、回归插补法以及最近邻插补法是统计学插补法中具有代表性的三种。其中,均值插补法的主要思想是运用所研讨属性(或变量)的已观测数据的均值作为缺失值的代替值,适用于分布集中、缺失率较低的数据集;而回归插补法则利用无缺失值且与缺失数据相关的变量作为辅助变量来建立适当的回归模型,并根据得到的模型插补缺失值,适用于有多个辅助变量的数据集,但若辅助变量与目标变量间不存在可靠的相关关系则会使得结果存在较大误差[5];最近邻插补法由Hodges 等人在20世纪初提出,其原理在于通过利用不存在缺失数据的变量作为辅助变量并基于定义的距离函数来对目标变量的缺失值进行填充。机器学习插补法适用于各种分布类型的数据,对高维数据的插补有较好的处理效果[6],Jerez 等通过将机器学习插补法和统计学习插补法进行详细对比,进而得出机器学习插补法具有较为明显优势的结论[7],Eirola 等人提出的一种将高斯混合模型以及极限学习机(ELM)应用于数据补全的方法能在大量数据的情景下具有较好的泛化性能,但该方法需要耗费较长的运行时间且不适用于小样本的情景[8];Kumar S 等人提出了一种基于迁移学习的GDP 预测方法[9],该方法使用与GDP 正相关的二氧化碳排放量作为特征,通过发达国家或发展中国家的二氧化碳排放量预测人均国内生产总值,但该方法并无涉及如何在高维数据中进行特征选择;而在SDGs 情境下,许多目标变量所能收集到的样本量少,同时并没有给定与变量相关的特征,故传统的数据补全方法受到限制。
针对SDGs 中存在的问题,本文提出了一种基于特征选择和迁移学习的数据预测方法TLM。该方法利用最大信息系数Maximal Information Coefficient(MIC) 从其它数据源中为目标变量构造出具有代表性的特征,达到特征增强的目的,然后将源域数据和少量目标域数据进行混合以建立回归预测模型,这强化了模型的鲁棒性和自适应性,在改善由于源域数据不足而导致的性能受限问题的同时能较好地处理源域和目标域之间的分布差异,最终使得模型对缺失值的预测准确率上升。
1 基于MIC与迁移学习的预测方法TLM
1.1 最大信息系数(MIC)
MIC是一种能被应用于衡量两个变量X与Y之间的线性或非线性强度的方法,是基于信息的非参数性探索[10]。
假设用a乘b的网格对存在于二维空间中的数据点集进行划分,以网格(x,y)中数据点落下的频率估计P(x,y),以第x行数据点落下的频率估计P(x),同样估计P(y),进而基于所获得的量推算出随机变量X和Y之间的互信息。由于用a乘b划分数据点的方法有很多种,因此需要寻求一种具有最大互信息的网格划分模式。通过运用归一化因子将互信息的值转换至(0,1)间,最终挖掘出能最大化归一化互信息的网格分辨率,并视其为MIC的测量值。
MIC 测量既拥有普适性,也具备均衡性。它能够在找到变量之间的线性函数关系的同时挖掘出变量之间的非线性函数关系,此外,其能够在纵向对比同一关系的强度的同时对不同关系的强度进行横向对比。
1.2 迁移学习
迁移学习(TL):对于源域Ds及其学习任务Ts、目标域Dt及其学习任务Tt,迁移学习的基本原理是利用Ds在解决Ts的过程中所获得的一些知识协助目标任务Dt学习到较优的预测函数F(x)[11]。
源域指用于训练的训练集,目标域指用于预测的测试数据。域的差异可以分为两种情况:其中一种是特征空间存在差异,另一种是边缘概率分布存在差异。任务的差异体现在两个层面:其中一方面是标签空间存在差异,另一方面是条件概率存在差异。
从迁移内容来看,迁移学习可分为样本迁移、特征迁移以及参数迁移[12]。
一般来说,样本迁移将源域的样本作为目标域的加权样本集成到目标域中,直接用于训练,经过不同的算法能够调整目标域中样本的权重。特征迁移包括两种方式,第一种方式的主要思想是在调整训练权重后将特征加入到目标域中,第二种方式是通过利用映射建立源域和目标域之间的特征关联进而达到减小源域和目标域之间的分布差异的目的。参数迁移的主要思想是在源域和目标域之间应用参数共享,或者结合多个源域模型来解决目标域问题。
1.3 TLM 构建
TLM(a method of incorporating transfer learning and MIC)的主要思想是利用最大信息系数来进行特征选择,然后结合样本迁移的思想来建立数据预测模型,其主要过程如下所示:

算法1 TLM(Om,Dm,Tm,Dt,Tt)输入:Om:公开数据源Dm:混合的源域数据和少量 目标域数据;Tm:与Dm中每个样本相对应的目标变量的取值;Dt:目标域数据中除了Dm外的剩余部分;Tt:与Dt中每个样本相对应的目标变量的取值;输出: Tt':由预测模型预测而得的目标变量的预测结果开始:{Step1:利用Om,通过MIC构造特征.Step2:构建Dm Step3:根据(Dm,Tm)训练回归模型Model Step4:使用训练得到的Model在Dt上进行预测得到Tt'Step5:根据Tt对Tt'进行评估}
在步骤1中,使用MIC 从公开数据源中为目标变量构造具有代表性的特征。
在步骤2中,使用完整的源域数据和少量的目标域数据进行混合构成训练数据Dm。其中Dm为k 维,且其对应的输出标签为Tm。
在步骤3中,使用回归技术,以Dm作为输入向量,Tm作为标签,训练所选回归器。
在步骤4中,使用步骤2 中经过训练得到的回归器对目标域数据Dt进行预测,得到T't。其中Dt的数据特征维度与Dm的相同。
在步骤5中,使用MAE和RMSE 两种度量标准并根据真实的标签值Tt对预测值T't的效果进行评估。
迭代步骤2至步骤5,针对目标域数据,得出效果最优的源域数据及其MAE和RMSE。
支持向量机是在统计学习理论下提出来的一种可应用于小样本机器学习相关问题的通用方法,而支持向量回归(SVR)旨在应用支持向量机的思想解决回归问题。在SDGs 情景下,考虑到一般的回归模型容易由于样本量小而导致模型泛化效果差,故步骤3中的回归技术采用径向基核函数的SVR,记为TLM-SVR。
2 实证研究
2.1 评价指标
由于使用误差评估能够更加直观地衡量模型的预测性能,故大多数研究者在机器学习中均采用误差评估,本文应用平均绝对误差(MAE)以及均方根误差(RMSE)两种常用的误差评价指标。
这两种统计方法定义如下:
2.1.1 RMSE
表示预测值,Yi表示实际值,n表示样本数。则
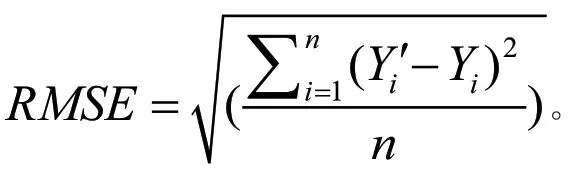
模型预测精度与RMSE的值成反比,即RMSE越小,模型性能越好。
2.1.2 MAE
表示预测值,Yi表示实际值,n表示样本数。
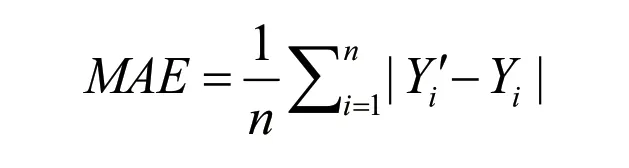
模型预测精度与MAE的值成反比,即MAE 越小,模型性能越好。
2.2 SDGs3.2.1 数据集
2017年,可持续发展目标指标机构间专家组(以下简称“IAEGSDGs”)发布了包括232个指标在内的可持续发展目标官方指标体系,用来监测全球可持续发展目标的施行进程。
根据定义和统计方法,IAEGSDGs 将232个指标分为三类。截至2019年12月,类别一有指标116项,这些指标都明确了定义,同时在规范了相应的统计方法的基础上收集了相应的统计数据;类别二有指标92项,这些指标虽然明确了定义,同时建立了规范的统计方法,但是缺乏必要的相关统计数据;类别三有指标20项,这些指标或没有明确定义或没有建立规范的统计方法;除此之外,还有4个指标有多个层次(指标的不同组成部分分为不同的层次)。在类别一的116项指标中,有些指标的组成部分在不同国家中存在不同程度的统计值缺失率[13]。
本文拟以SDGs 3.2为例,其中指标3.2.1为“五岁以下儿童死亡率”,即Under-five mortality rate,其下有统计变量“五岁以下儿童的死亡率(每千名活产婴儿死亡)”,表1展示了部分国家于1950年-2016年间在该统计变量上的缺失率(缺失率=该统计值缺失的年份数/年份跨度)。
从表1中可以看出,部分国家,如Costa Rica、Germany 等在目标值上的缺失率超过20%以上。由于世界各国和地区的发展状况不同,所处的社会稳定情况不同,如有的国家因为常年处于战乱状态而难以收集到该国家在相关可持续发展指标上的统计数据等,个别国家和地区在可持续发展指标上相关统计数据的缺失率较高,这限制了联合国对相应国家在可持续发展目标上进行有效监测。
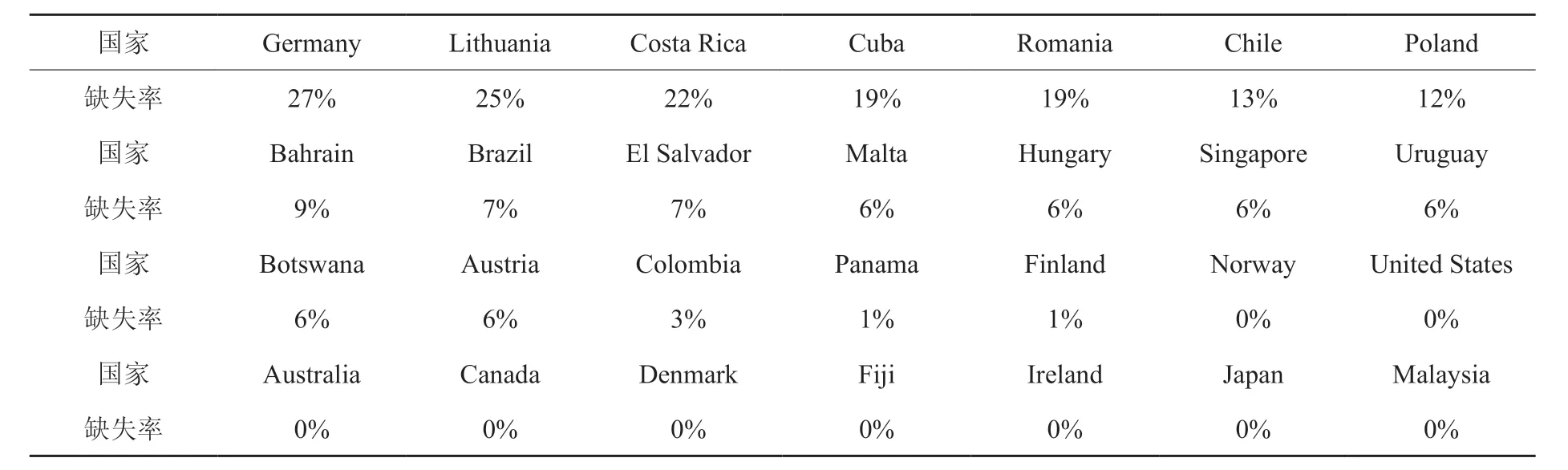
表1 SDGs 指标3.2.1 缺失率Table1 Missing rate of SDGs indicator 3.2.1
在缺失率大于0的19个国家中随机挑选8个国家作为待预测填充缺失值的目标域。
表2展示了随机抽取而得的8个国家:Bahrain、Botswana、Brazil、Colombia、Costa Rica、Romania、Uruguay、El Salvador 在1950-2016年间的缺失情况。
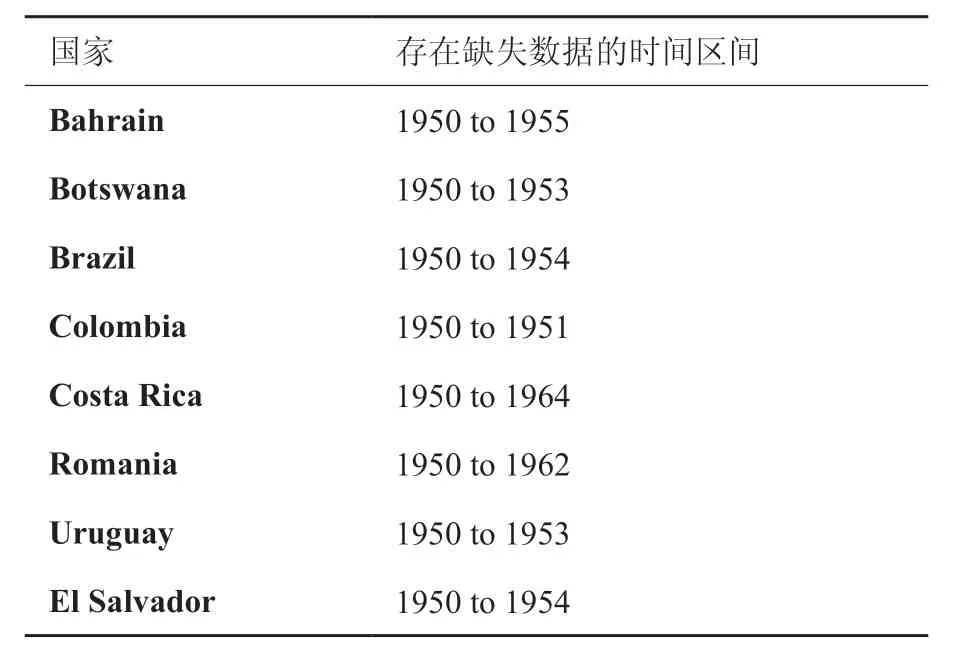
表2 1950-2016年间的数据缺失情况Table2 Time period of missing values during 1950 to 2016
2.3 实验过程
本文采用的实验环境为1台windows10 64
位操作系统的PC,运行内存8GB,编程环境是Python3.6。
2.3.1 为SDGs 指标3.2.1构造特征
首先,数据收集。从公开数据集OECD[14]、ITU[15]、Fund for Peace[16]、World Bank Open Data[17]上收集整理255个国家和地区于2000年的统计数据,共涉及统计变量1601个。
其次,特征选择。为了从以上1601个统计变量中找到与指标3.2.1(5岁以下死亡率 Under 5 mortality rate)相关的统计变量,我们以国家为维度形成维度为255的统计变量x,接着采用MIC 计算指标与统计变量之间的相关度。最终得到与指标3.2.1 相关性最高的三个变量分别为“女性出生时的预期寿命”、“政府在医疗保健上的人均支出PPP”、“35-59岁间女性由传染病引起的死亡(相关年龄组的百分比)”。鉴于数据的可获取性和完整性等现实客观原因,最终采用“女性出生时的预期寿命”作为指标3.2.1的特征。
2.3.2 实验结果和性能分析
我们以表1中的28个国家在1970-2016年间的数据为实验样本,共1 316个样本。其中取出1970-2012年间的数据作为训练集,2013-2016年的数据作为测试集,以此数据进行模型训练和性能测试。针对表2中的每一个特定的国家,使用该国家的数据作为目标域,分别将剩余27个国家作为源域训练预测模型TLM-SVR,并对测试集进行测试,然后将TLMSVR模型与广为采用的均值插补法和SVR 方法进行对比,分析三种不同方法对同一测试集的效果。
SVR模型和TLM-SVR模型均有两个重要的参数,分别为C和gamma,其中C为惩罚系数,即模型对误差的容忍度,gamma是选择RBF(径向基核函数)作为核函数之后,该函数自带的一个重要参数。在SVR模型和TLM-SVR模型中,根据经验和实验调参,最终将参数设置为:SVR(kernel ='rbf',C =1e3,gamma = 0.01)
图1、图2分别展示了由本文所提出的TLM 方法训练所得的均值插补方法、SVR 方法与TLM-SVR模型在Bahrain、Botswana、Brazil、Colombia、Costa Rica、Romania、Uruguay、El Salvador 八个国家的测试集上所取得的MAE和RMSE。从图1、图2可以看出,在8 组实验中,相比较于传统的均值插补法和SVR模型,TLM-SVR模型能有效地提升模型的预测性能。
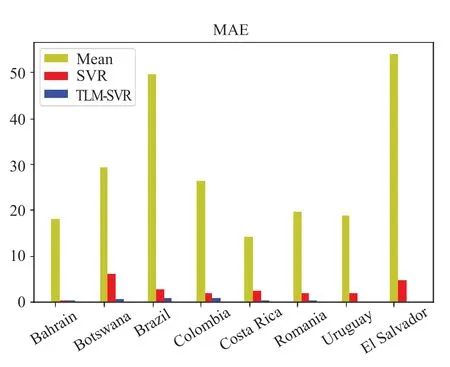
图1 三种方法在同一测试集上的MAEFig.1 The MAE of three methods on the same test set

图2 三种方法在同一测试集上的RMSEFig.2 The RMSE of three methods on the same test set
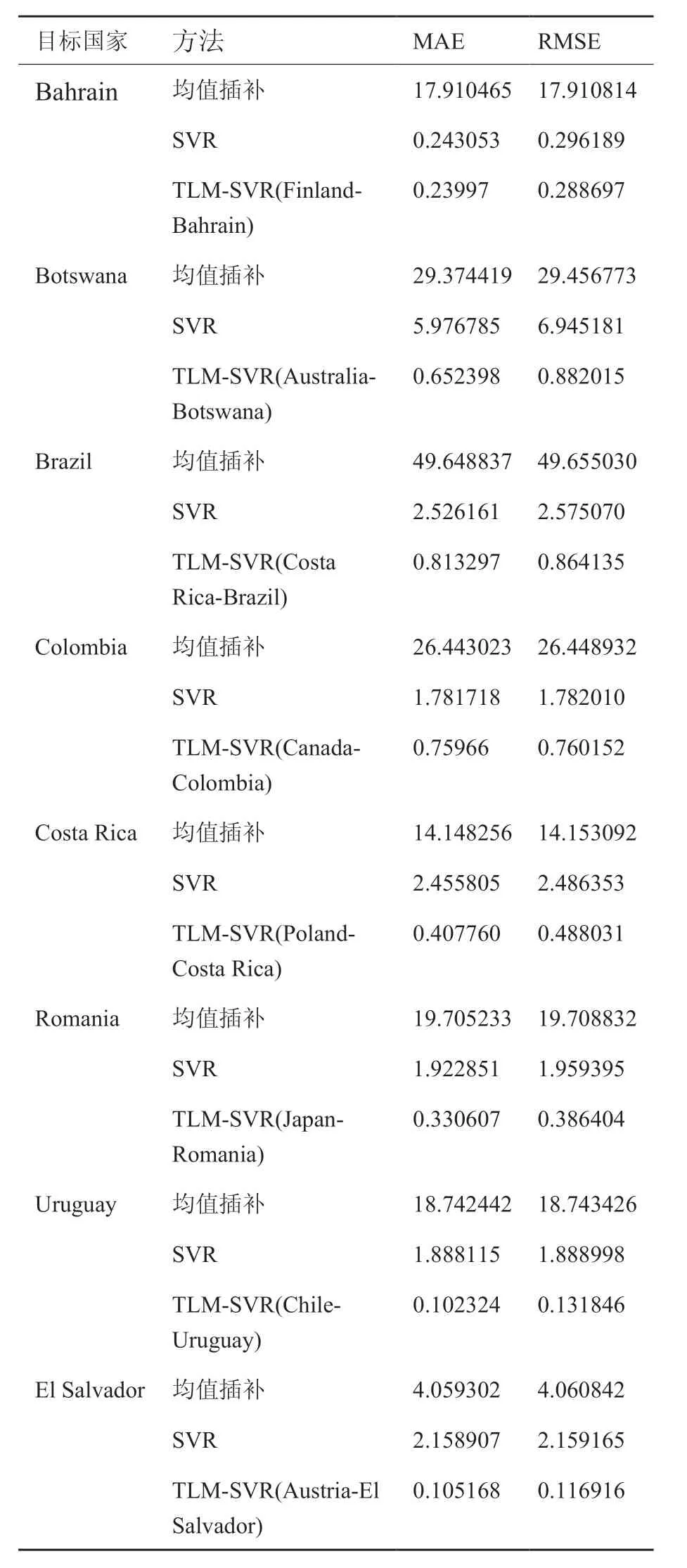
表3 三种方法分别在8个国家的测试集中得到的MAE和RMSETable3 MAE and RMSE obtained by three methods in the test set of eight countries
表3表示针对以上八个国家,均值插补方法、SVR 方法和TLM-SVR模型对同一测试集的效果,其中,TLM-SVR(Finland-Bahrain)表示以Finland的数据作为源域数据并融合Bahrain的已有数据进而经过TLM-SVR 训练而得的模型。从表3可以看出,针对Bahrain 这个国家而言,均值插补法在测试集上的MAE和RMSE的值均最大,且SVR模型相比均值插补法,明显提升了预测精准度,MAE和RMSE分别从17.910465和17.910814降至0.243053和0.296189,而TLM-SVR(Finland-Bahrain) 在 测试集上的MAE和RMSE 均比SVR的小,MAE和RMSE分别降至0.23997和0.288697,说明TLMSVR(Finland-Bahrain)的泛化能力更强(即对测试集的效果更好)。综合起来看,可见TLM-SVR(Finland-Bahrain)取得了更好的预测效果,这表明了TLMSVR(Finland-Bahrain)的有效性。
其余七个国家也可从表3中得到与Bahrain 相似的结论。
2.4 缺失值预测
在衡量SDGs 指标3.2.1的实例中,通过8 组实验,我们看到:
针对同一测试集,当采用传统的均值插补法时,误差较大,而使用TLM 方法,通过MIC 进行特征选择,进而采用回归模型SVR 对缺失值进行预测时,其预测误差取得一定下降;而当采用样本迁移训练得到回归模型TLM-SVR,进而对缺失值进行预测时,其预测误差得到显著下降,比使用均值插补法和SVR模型要好。这是因为TLM 方法通过MIC 进行特征选择后在增强了特征的同时利用源域数据和目标域数据进行混合来训练预测模型,最终使得设计出的模型有更好的鲁棒性和自适应性,能够进一步较好地处理源域和目标域两者间的分布差异,从而增强模型的预测性能。
根据表3,可知针对Bahrain、Botswana、Brazil、Colombia、Costa Rica、Romania、Uruguay、El Salvador,作为其最佳源数据的国家分别为Finland、Australia、Costa Rica、Canada、Poland、Japan、Chile、Austria。现针对八个国家在SDGs 指标3.2.1于1950-2016年间的缺失值,采用TLM-SVR 方法对其进行预测。
图3-10分别表示采用TLM-SVR 方法对八个国家中缺失值的预测结果。其中,橙色的线代表该变量可获取到的真实值,蓝色的线代表模型对缺失值的预测。

图3 Chile-Uruguay 缺失值预测Fig.3 The prediction of missing value in “Chile-Uruguay”
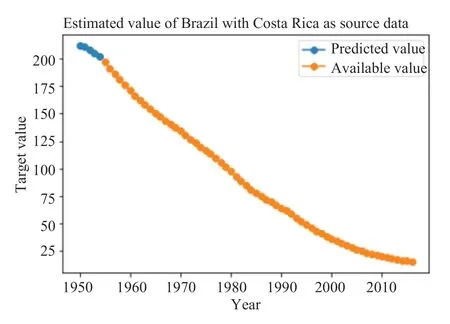
图4 Costa Rica-Brazil 缺失值预测Fig.4 The prediction of missing value in “Costa Rica-Brazil”
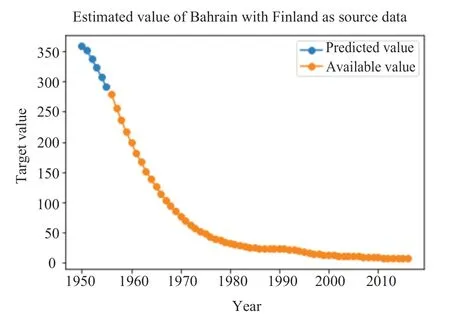
图5 Finland-Bahrain 缺失值预测Fig.5 The prediction of missing value in “Finland-Bahrain”
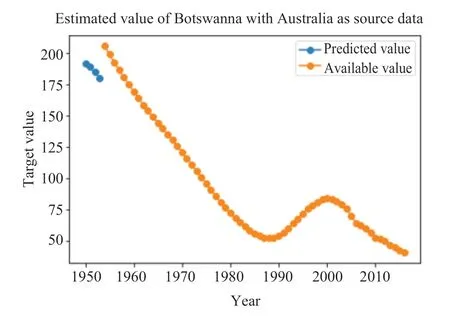
图6 Australia-Botswana 缺失值预测Fig.6 The prediction of missing value in “Australia- Botswana”
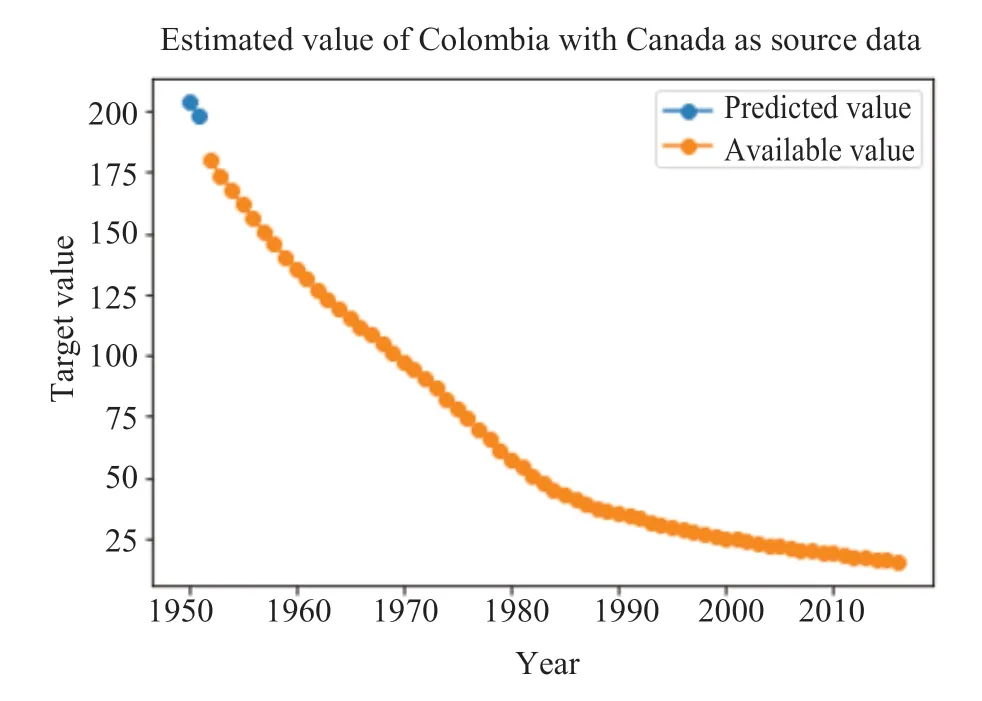
图7 Canada-Colombia 缺失值预测Fig.7 The prediction of missing value in “Canada-Colombia”
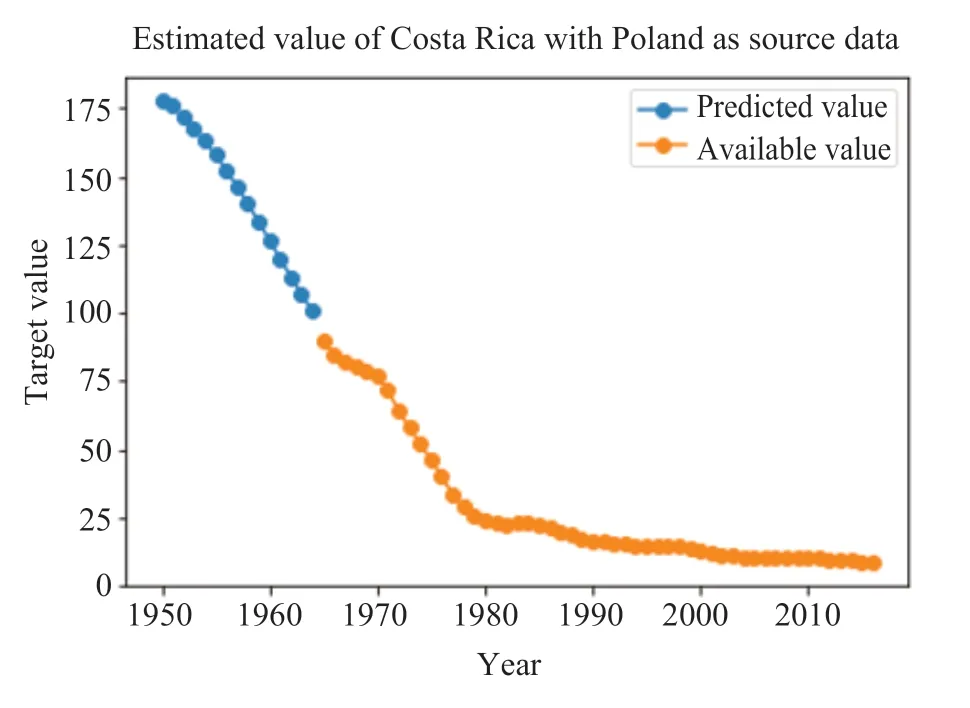
图8 Poland-Costa Rica 缺失值预测Fig.8 The prediction of missing value in “Poland-Costa Rica”
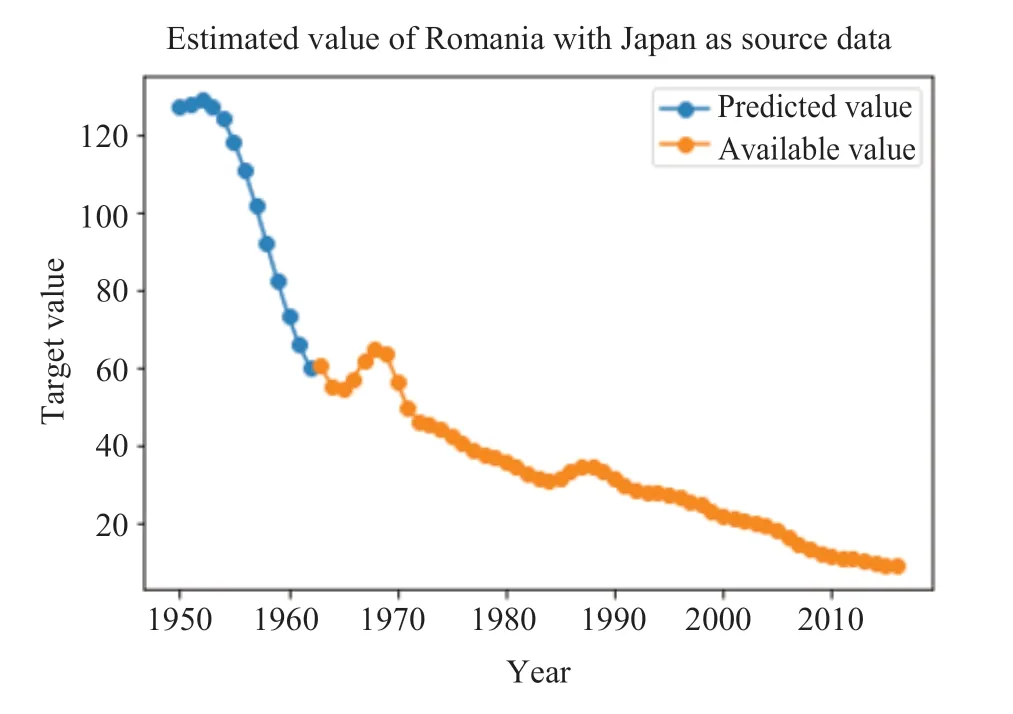
图9 Japan-Romania 缺失值预测Fig.9 The prediction of missing value in “Japan-Romania”
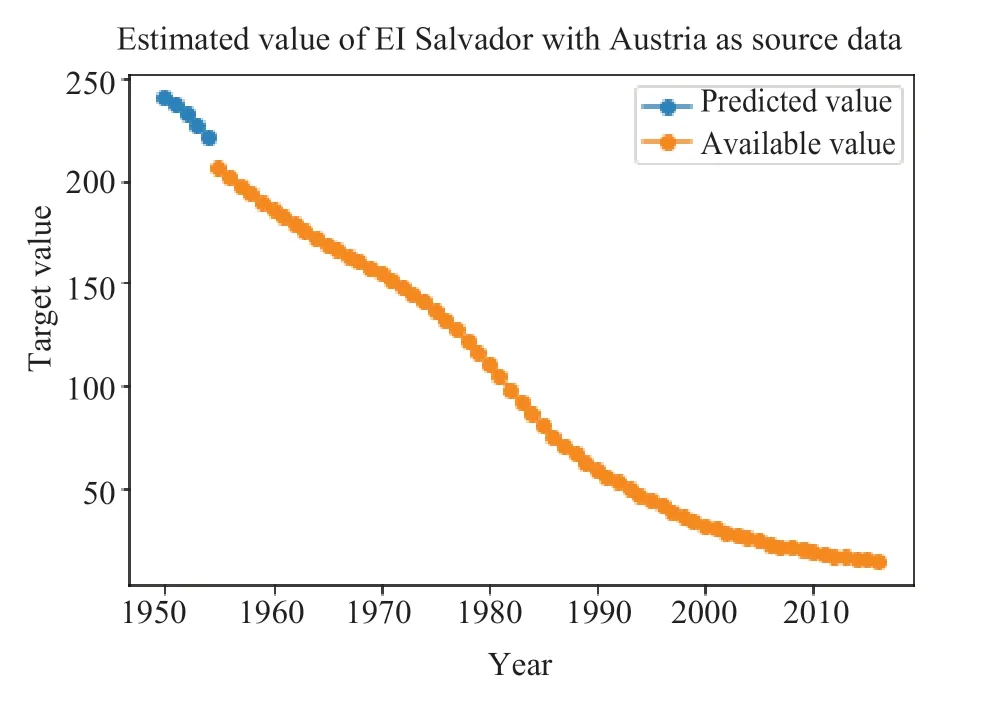
图10 Austria-El Salvador 缺失值预测Fig.10 The prediction of missing value in “Austria-El Salvador ”
3 总结与讨论
SDGs 指标数据缺失率过高的现状大大地影响了联合国对各国可持续发展目标实行过程的有效监测。本文提出了一种基于特征选择和迁移学习来对缺失值进行数据预测的方法(TLM)。首先利用非线性相关分析方法从收集到的大量统计数据中挖掘出与SDGs 指标3.2.1 中相关性较高的统计变量,接着以随机选择的8个国家作为目标域,通过实验验证了由TLM 建立的TLM-SVR模型的预测性能比传统的均值填充和SVR 回归预测效果更好,最终利用TLM-SVR模型对8个国家在1950-2016年间的缺失值进行了预测。
本文为相关领域的工作者提供了一种处理SDGs相关指标缺失问题的新思路。当然,影响SDGs 指标3.2.1的波动因素众多,且随着时间的推移,各种可变因素可能随时发生变化,因此,如何进一步收集更多的统计变量,探索更多相关性分析方法来丰富SDGs 指标3.2.1的特征,进而采
用TLM 方法对缺失值进行更加精确的预测,是今后研究的重点方向。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
世界科学技术-中医药现代化(2021年7期)2021-11-04 08:11:48
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
统计与信息论坛(2021年1期)2021-01-26 09:40:24
计算机技术与发展(2020年11期)2020-12-04 07:50:46
河北理科教学研究(2020年2期)2020-09-11 06:15:48
统计与信息论坛(2018年8期)2018-08-15 12:44:02
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
电子与信息学报(2015年12期)2015-08-17 11:14:42
新高考·高二数学(2014年7期)2014-09-18 00:42:02
