
基于深度迁移学习的农业病害图像识别
2020-12-02 01:54:30陈雷袁媛
数据与计算发展前沿 2020年2期
陈雷,袁媛
中国科学院合肥智能机械研究所,安徽 合肥 230031
引言
农业病虫害是影响农业产量和粮食安全的重要因素之一[1-2]。根据联合国粮食及农业组织的报告,每年超过三分之一的自然损失是由农业病虫害引起的[3]。农业病虫害种类繁多,传统人工观察和经验判断容易误诊;同时由于专业农技人员不足,在生产实际中往往难以对病虫害进行及时的识别或预警。随着机器学习方法与计算机视觉技术的发展,研究人员开始利用信息技术来识别农业病虫害图像。作为智能农业重要的组成部分,农业病虫害图像识别技术综合利用机器学习方法、计算机视觉技术、植物病理学知识等手段来分析处理病虫害图像数据,建立学习模型获取图像特征,快速、准确地识别出病虫害种类,据此为农业病虫害防治提供技术指导。
自20世纪80年代以来,机器学习方法不断发展,从传统的浅层机器学习,如分类器法、判别式法、聚类法等[4-8],到2006年Hinton 等人提出的深度学习方法[9],都已广泛用于农业病虫害图像识别方面的研究,并且取得了一定的成果[10-15]。然而农业病虫害发生环境非常复杂,当这些方法应用于实际的农业病虫害图像识别时存在一定的局限性,容易受到数据规模、样本质量、硬件算力、模型能力等因素的影响,从而导致识别效果难以满足需求。尤其是相对于虫害来说,农业病害发生的影响因素更为复杂,且在不同农作物品种上的症状也存在差异等特点,导致这些局限性更为突出。
迁移学习方法的提出,特别是基于深度神经网络的深度迁移学习方法[16-17]为解决传统浅层机器学习方法与深度学习方法在农业病害图像识别中的局限提供了启发。本文重点围绕农业病害图像识别问题,在分析传统机器学习方法与深度学习方法优缺点的基础上,探讨在不同数据规模条件下融合不同的机器学习框架,引入深度迁移学习方法来提高小样本条件下的建模质量,并通过具体实验对提出的方法进行验证,为提高农业病害图像识别准确率、构建符合实际需求的农业病害智能识别系统提供技术支撑。
1 相关工作
1.1 基于传统机器学习的农业病害图像识别
从上个世纪80年代开始,国内外研究人员广泛利用多种传统机器学习方法来进行农业病害图像识别技术的研究,包括支持向量机分类器法[4-5]、判别分析法[6]、K 近邻分类法[7-8]等,对于促进信息技术在农业病害图像识别中的应用研究起到了积极的作用。
虽然这些传统机器学习方法在用于农业病害图像识别时已经取得了一定的成果,但仍然存在以下一些问题:首先,这些方法的识别效果依赖于原始病害图像样本的质量,当训练数据的质量比较差时,建模效果也容易受到影响,而高质量的农业病害图像训练数据往往难以获取,对病害图像采集环境与采集方式提出了更高的要求;其次,使用这些方法的相关工作中所处理的农业病害图像数据集规模较小,大多不超过300 张图像,当训练样本数量较大时,这些传统机器学习方法难以高效构建相应的识别模型;第三,用于分类识别所提取的特征需要人工设计,特征设计的好坏取决于设计者的先验知识,很难利用大数据的优势,同时由于依赖手工调整参数,因此特征设计中所允许出现的参数数量十分有限;第四,这些传统机器学习方法仅作为病害图像识别关键技术,在构建整个农业病害图像识别系统时大多需要复杂的前处理,例如对原始图像进行噪声滤波、图像分割、特征提取等,其中部分环节的精度对于结果非常关键,至今仍有待进一步研究以提高处理精度,多环节的误差累计也影响了最终的识别精度。
因此,传统的浅层机器学习方法难以在农业病害图像识别中取得满意的效果。在数据呈现爆炸式增长的背景下,面向现代智能农业快速发展的需求,利用新型机器学习算法从大数据资源中获取有用的信息来提高农业病害图像的识别效果显得尤为重要。
1.2 基于深度学习的农业病害图像识别
尽管人工神经网络方法在二十世纪四五十年代就已经出现,但直到2006年Hinton 等人提出深度学习[9]后,神经网络方法在诸多研究和应用领域才取得了突破性的进展。在信息爆炸的大数据时代,深度学习方法能够有效解决大数据的学习与建模问题。尤其在利用深度学习方法处理图像识别任务时,对原始图像进行滤波、分割和特征提取等复杂的预处理不再是必须的环节,这为进一步提高基于计算机视觉技术的农业病害图像识别精度、快速构建在线的智能化农业病害诊断系统提供了新的思路和技术支撑。
近年来,国内外学者已经开展了大量基于深度学习的农业病害图像识别研究工作[10-15]。相比传统的机器学习方法,使用深度学习框架能够自动学习图像数据所蕴含的特征,当数据集达到一定规模时,建模质量较高,在农业病害图像识别任务中能够达到较好的准确率和鲁棒性。然而利用深度学习进行农业病害图像识别仍然存在一些局限:首先,深度学习方法要求训练数据集具有较大的规模,农业病害图像数据库的规模和质量在很大程度上决定了病害图像识别系统的效果,但是由于农作物品种繁多,病害种类非常复杂,即使同一病害在相同作物不同品种上的表现症状也不完全一致,导致在短时间内难以获取目标数据大规模的样本;其次,尽管深度学习可以从大数据中自动学习特征表示,且在理论上允许成千上万的参数,但目前的深度学习技术过于依赖数据标注,只有在大量标注训练样本的情况下才能够构建出较好的模型;第三,随着模型复杂度的增加,参数个数也呈指数级增长,但同时模型的泛化能力有限;第四,如果面向一个全新的数据集和任务,利用深度学习方法从头开始训练模型对于硬件的算力要求较高,在实际应用中往往难以满足。
因此,在针对农业病害图像识别任务上,受到现有的理论方法、计算设备的硬件条件、数据集规模与质量等制约,难以直接利用深度学习构建出理想的识别模型,需要进一步探索在小样本条件下如何学习得到高质量的分类识别模型。
1.3 基于迁移学习的农业病害图像识别
传统机器学习与深度学习都存在两个重要的基本假设,即:用于学习的训练样本与新的测试样本满足独立同分布;必须有足够可用的训练样本才能学习得到一个好的分类模型。然而在实际中很多领域的数据难以满足这两个基本假设,因此出现了迁移学习。迁移学习的基本思想是学习目标领域和已有知识之间的相关性,把知识从已有的模型和数据中迁移到要学习的目标领域中,与传统机器学习过程的区别如图1所示。迁移学习的思想早在上个世纪70年代就已经出现,但一直没有得到广泛的应用,直到近年来随着深度学习的发展而得到了广泛关注[16-17],尤其是与深度学习结合产生的深度迁移学习方法,能够利用从大数据领域所学到的知识来辅助构建数据规模相对较小的目标领域的模型构建,直接降低了目标领域建模对于数据规模的要求,适用于许多样本数据不足以直接利用深度学习方法建模的研究与应用领域,这其中就包括农业病害图像识别研究领域。由于农作物品种多样,所发生的病害更加繁杂,难以采集大规模的目标病害图像数据来支撑深度学习建立分类模型。在受到深度迁移学习方法的启发后,国内外研究人员开展了相关的研究工作[18-21],使用已有的某一些数据集规模较大的病害图像数据来辅助建立样本数据较小的目标病害图像的识别模型,并取得了一定的成果。
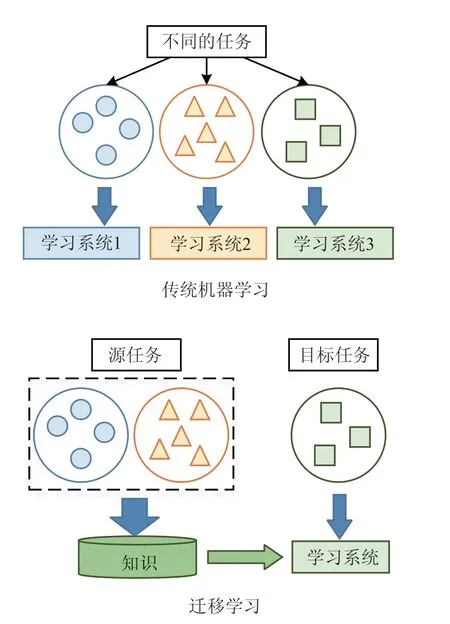
图1 传统机器学习与迁移学习的对比Fig.1 Comparison between traditional machine learning and transfer learning
利用深度迁移学习方法建模同样受到一些因素的影响,包括辅助数据集的选择、目标数据集的质量以及具体迁移学习方法等,使得最终的建模质量参差不齐,因此基于深度迁移学习方法的农业病害图像识别技术还存在许多问题需要进一步的研究与探讨。Barbedo[22]讨论了数据集规模和种类对基于深度学习和迁移学习的植物病害分类效果的影响。与该工作不同,本文重点探讨不同迁移学习方法对于提高小样本条件下农业病害图像识别模型构建质量的影响,并据此给出不同数据规模条件下迁移学习方法的选择建议,以获得更高的农业病害图像识别准确率。
2 基于深度迁移学习的农业病害图像识别
2.1 迁移学习方法概述
依据不同的条件,迁移学习方法有不同的分类。以特征空间来说,可分为同构和异构两种迁移学习;以迁移场景来说,可分为归纳式、直推式、无监督三种迁移学习;以迁移层面来说,又可分为基于实例、基于特征、基于关系和基于模型共四种迁移学习,其中前三者属于数据层面的迁移,最后一种属于模型层面的迁移。具体到农业病害图像识别任务,按照农业病害图像数据的特点,本文从迁移层面入手,分别探讨了基于实例和基于模型两种迁移学习方法。
2.2 基于实例迁移的农业病害图像识别
基于实例的迁移学习是一种同构迁移学习,此种情况下通常是对辅助领域的实例进行重新加权以校正数据的边缘分布差异,然后将这些加权的实例直接用于目标领域的模型训练。当两个领域的条件分布相同时,该方法最有效。因此,我们尝试引入基于实例的迁移学习方法,利用已有的规模较大的农业病害图像数据集来辅助训练目标病害图像的分类模型。我们针对TrAdaBoost 算法[23]提出了一种基于训练集优化的改进算法。TrAdaBoost 算法是一种基于实例的迁移学习算法,基本原理是对目标训练样本和辅助训练样本的权重进行不断调整,得到最终的分类器。将该算法用于农业病害图像识别任务时,如果辅助数据样本噪声比较多或者迭代次数控制不好,训练分类器的难度将会增加。针对该问题,我们借鉴分类的思想对训练集进行优化,采用K 近邻算法过滤与目标训练数据相似度较小的辅助数据,具体算法步骤如下:
输入:辅助数据集,目标训练数据集,最近邻样本点数量k
输出:新的辅助数据集
(1)计算目标训练数据和辅助数据之间的欧式距离;
(2)以递增的形式对步骤(1)中的距离进行排序,确定距离最小的k个样本点;
(3)计算k个样本点的类别出现的频率;
(4)将步骤(3)中出现频率最高的类别作为辅助数据的预测类别;
(5)比较辅助数据的真实类别和步骤(4)中得到的预测类别,去除预测错误的数据;
(6)返回新的辅助数据集。
基于上述算法,在农业病害图像识别过程中,首先选取其他规模较大的病害图像数据集作为辅助数据,通过训练集优化KNN 算法对其进行过滤。然后采用TrAdaBoost 算法调整训练数据的权重,再构建最终的病害图像分类识别模型。引入基于实例的迁移学习方法是为了解决某些农业病害图像数量较少、基于传统机器学习方法难以取得理想识别效果的问题,这种基于实例的迁移方法需要借助相似度较大且数据量较多的其他病害图像数据,然而实际中寻找这种相似度较大的辅助数据集也比较困难,因此我们还研究了基于模型的迁移学习方法。
2.3 基于模型迁移的农业病害图像识别
基于模型的迁移学习方法也是一种同构迁移学习。该方法通过共享辅助领域和目标领域机器学习模型的参数,或通过创建多个辅助领域的模型,并将其重新加权优化组合来改进目标领域的模型构建。在这种情况下,当辅助数据规模较大或模型参数较好时,和目标数据之间不需要非常高的相似性。因此ImageNet 数据集[24]通常被当作辅助数据来训练所需的参数,然后在目标数据建模中进行调整。同时,考虑到目标数据即农业病害图像数据的特殊性,与ImageNet 数据集差异仍然较大,因此在辅助数据选择方面也采用另一个开源数据集PlantVillage[25],该数据集中包含大量单一背景单张叶片的病害图像,与本文的农业病害图像数据集具有较好的相似性,在基于迁移学习的识别方法中是较好的辅助数据[26]。
在基于模型的迁移学习方法中,模型的选择也非常重要。我们选择三种常用的深度学习框架AlexNet[27],VGGNet[28]和ResNet50[29]作为模型迁移的基本架构来训练恰当的参数,辅助目标数据的建模。基于模型的迁移学习框架如图2所示。
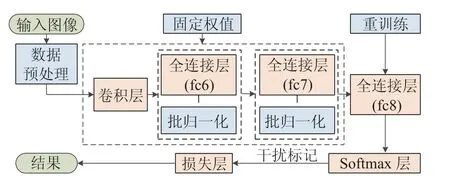
图2 基于模型的迁移学习框架Fig.2 Framework of model-based transfer learning
此外,在基于模型的迁移学习方法中,为了防止模型的过拟合问题,我们引入批归一化与干扰标记两种方法来对模型参数进行优化。批归一化能够减少模型训练至收敛过程所需的迭代次数,同时可以起到正则化的作用,降低模型训练的过拟合现象。干扰标记是一种在损失层实现正则化的方法,在每个批次训练过程中随机选取一部分数据样本,将这些样本的标记设置为错误标记,该操作能进一步防止模型训练过程发生过拟合现象。
3 实验与讨论
3.1 实验数据
本文实验所采用的目标数据即农业病害图像数据均来自农业病虫害研究图库IDADP(http://www.icgroupcas.cn/website_bchtk/),由作者在安徽省、江西省的大田或温室中采集整理。在采集作物病害图像时,主要是在露天或大棚的自然光照条件下,拍摄角度使光路尽量垂直于作物器官所在平面,保证作物器官受光均匀,所拍摄的作物器官占据画面的中央主要位置。图像采集设备具体如下:Canon EOS 6D 型数码单反相机,配备佳能EF 17-40mm f/4L USM镜头与佳能EF 100mm f/2.8L IS USM微距镜头,佳能Canon EOS M6,配备EF-M 28 f/3.5 IS STM 微距镜头。拍摄时采用相机的最优画质与最大分辨率6000*4000与5472*3648,拍摄时采用光圈优先模式使得图像景深足够大,以保障被拍摄的作物器官在画面中具有符合要求的清晰度。
3.2 基于实例迁移的实验结果与分析
在基于实例迁移的实验中,病害图像数据规模较小,仅有750 张图像,共包括6种病害图像:黄瓜靶斑病(CTS)、黄瓜霜霉病(CDM)、黄瓜细菌角斑病(CBAS)、稻瘟病(RB)、水稻胡麻斑病(RBS)和水稻纹枯病(RSB),进行不同的辅助数据和目标数据的搭配以构建不同的实验组合,具体如表1所示。
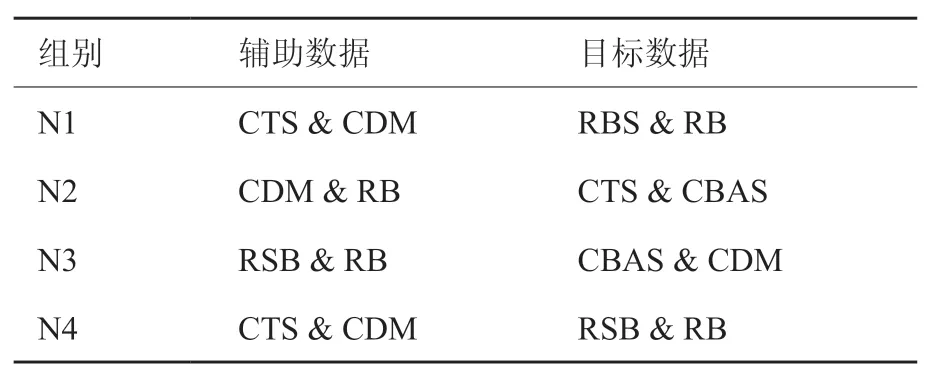
表1 基于实例迁移的实验数据Table1 Dataset of instance-based transfer learning
为了探讨恰当的辅助数据与目标数据规模之间的比例,实验中将目标数据与辅助数据的比例记为r,取值范围从4%到20%分别开展了实验,实验结果采用分类准确率作为评价标准,即正确分类的目标病害图像数量占目标病害图像总数量的比例,准确率越高说明模型的分类识别性能越好。图3给出了在N1 组数据集上不同比例r 情况下的实验结果(其余三个组别上的结果类似),其中横坐标为比例r,纵坐标为分类准确率,我们提出的改进方法为TRBM,对比模型分别为支持向量机SVM与TrAdaBoost。从图3中可以看出,随着目标数据集比例的增加,分类准确率也随之提高,可见数据集规模对于图像识别准确率的重要性;在比例r 取值为4%时,我们提出的改进方法与SVM和TrAdaBoost相比在准确率的提高上更加明显,说明目标数据集规模较小情况下,本文的方法具有明显的优势。
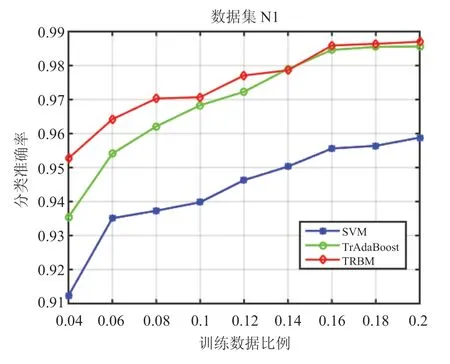
图3 不同比例的目标数据与辅助数据的结果Fig.3 Results of different ratio of target data to auxiliary data
表2给出了比例r 取值为4%时四组实验的结果,可以看出使用实例迁移学习的准确率明显优于传统机器学习方法SVM,同样可以看出使用我们提出的对辅助数据集进行过滤的优化方法比TrAdaBoost 方法取得了更好的分类准确率。实验结果表明,引入基于实例的迁移学习方法后,能够发现辅助数据中对目标数据分类有帮助的信息,从而在目标数据规模较小的情况下提高建模质量,对于农业病害图像识别技术研究具有一定的参考价值。
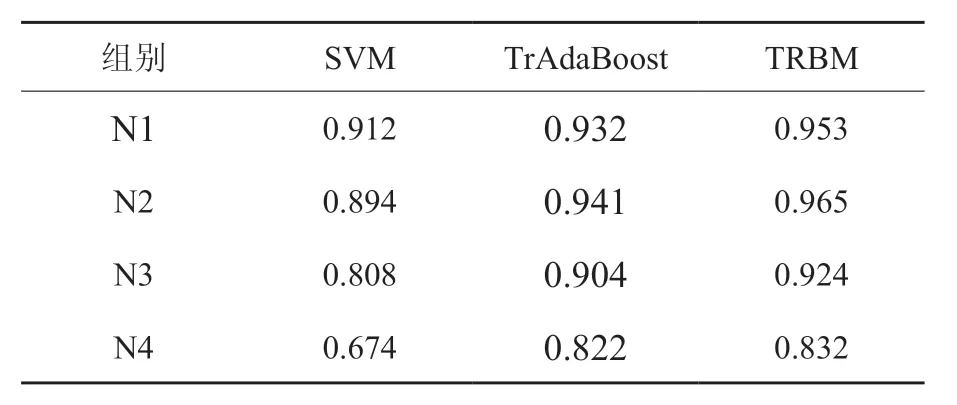
表2 基于实例迁移的实验结果Table2 Results of instance-based transfer learning
3.3 基于模型迁移的实验结果与分析
在基于模型迁移的实验中,相比基于实例迁移的实验增加了病害种类,包括黄瓜白粉病、水稻白叶枯病、稻曲病,原始图像数据规模达到2 429 张。由于基于模型的迁移采用了AlexNet,VGGNet和ResNet50 三种流行的深度学习框架,对于数据规模的要求较大,因此对原始图像数据进行了随机缩放、随机水平翻转、随机裁剪、归一化、正则化等常用预处理,以增加数据规模,预处理后再筛除无效图像数据,总量达到9 592 张。
表3给出了基于模型迁移的实验结果,其中AlexNet,VGGNet和ResNet50 作为对比模型,TRBD为我们的方法,在建模过程中为了防止模型训练的过拟合问题,引入批归一化与干扰标记来对模型参数进行优化。
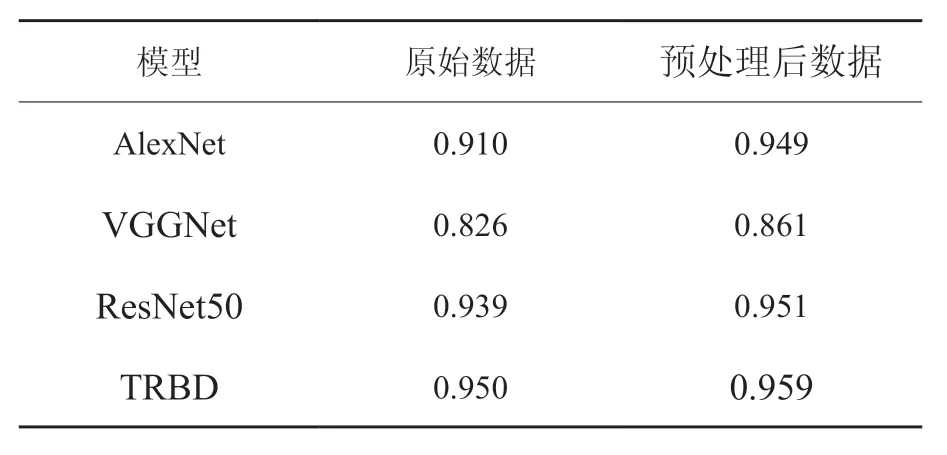
表3 基于模型迁移的实验结果Table3 Results of model-based transfer learning
通过表3的实验结果可以看出,随着建模数据量的增加,基于模型迁移的方法整体效果优于基于实例迁移的方法;经过预处理后增加了数据集的规模,同样对提高准确率具有比较明显的作用;相比三种常用深度学习模型的迁移学习,我们引入批归一化与干扰标记两种方法对参数进行优化,有效抑制了模型训练的过拟合现象,在基于模型的深度迁移学习实验中取得了最佳的实验结果。
4 结论与下一步工作展望
本文针对农业病害图像识别问题,首先分析比较了传统机器学习方法与深度学习方法的优缺点,然后介绍引入深度迁移学习方法来解决目标数据规模较小条件下的机器学习建模问题,重点探讨了在不同数据规模条件下如何采用不同的深度迁移学习方法来提高图像分类识别模型的构建质量:
(1)在目标数据集规模较小且与辅助数据比较相似时,采用基于实例的迁移学习方法的提升效果比较明显;
(2)在目标数据集具有一定规模但又不足以直接利用深度学习方法建模时,则采用基于模型的迁移学习方法比较有效;
(3)针对不同的深度迁移学习方法给出了相关的优化方案;通过具体实验对提出的方法进行了验证。
目前,农业病害图像数据资源仍然十分稀缺。在下一步的工作中,建设规模化、标准化的图像数据资源是农业病害图像识别技术研究领域应当先行的基础工作。在具体技术方面,下一步的工作包括以下内容:一是探索更加优秀的深度迁移学习框架,进一步降低对目标数据规模及数据质量的依赖性,同时提高图像分类识别的准确率;二是在训练数据中考虑增加无病害的正样本图像,以提高分类识别模型的鲁棒性和普适性;三是与实际应用需求相结合,以农业病害图像识别技术为核心,研发可用于实际农业生产过程中病害防治的应用软件和系统平台,尤其是轻量级、移动端的应用[30];四是考虑引入更多的先进机器学习方法来解决农业病害图像识别问题,如利用生成对抗学习方法来增强数据,利用联邦学习来保护数据的隐私等。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
今日农业(2022年3期)2022-06-05 07:12:02
河北理科教学研究(2021年3期)2022-01-18 05:34:24
今日农业(2021年8期)2021-11-28 05:07:50
发明与创新(2021年39期)2021-11-05 07:15:28
烟台果树(2021年2期)2021-07-21 07:18:28
今日农业(2020年19期)2020-11-06 09:29:38
电子制作(2019年16期)2019-09-27 09:34:50
中国交通信息化(2019年4期)2019-07-13 05:51:34
电子制作(2018年19期)2018-11-14 02:37:04
电子制作(2018年14期)2018-08-21 01:38:16
