
基于元学习和神经网络的快速路瓶颈区识别模型
2020-11-30 06:53吉静
科学技术创新 2020年34期
吉静
(上海电科智能系统股份有限公司,上海200063)
城市快速路作为大型城市交通网络的重要组成部分,在城市交通“提速”上起着重要作用。但是近年来,随着私家车的增多,人们出行需求的快速增加,现有的快速路交通拥堵现象频频发生,严重影响了快速路出行效率。
快速路上的交通拥堵通常是由于瓶颈区所导致的,快速路瓶颈区可以分为常发性瓶颈区和非常发性瓶颈区。非常发性瓶颈区具有较强的突发性,传统的方法难以识别预测。交通瓶颈识别方法除了传统的基于三相交通流理论的方法、基于非局部气体动理论模型的方法和基于元胞自动机模型的方法外,自动识别(Automatic Traffic congestion identification,ACI)算法也随着网络的发展以及计算机算力的提高而被提出,如:杨小宝等人以生理- 心理模型中的MITSIM模型为基础,在跟车子模型加入了随机扰动项,换道子模型的可行性检测中加入了前后间距不足时司机的减速行为[1]。
Richard Arnott 等人提出了一种集交通拥堵和路边停车饱和于一体的市区停车模型,该模型会d 额外对市区出行的金钱和时间成本敏感[2]。Syuichi Masukura 等人提出了一个简单的单车道模型,对由慢速车辆引起的干扰过渡进行了研究[3]。
Katsunori Tanaka 等人将传统的最佳速度模型拓展到考虑了波动加速度的模型,并对如何将扩展的交通模型应用于飓风疏散中的高速公路上的交通流进行了研究[4]。林瑜、杨晓光等人提出了间断交通流阻塞度的概念,反映了城市道路间断交通流实际运行状态[5]。
虽然自动识别模型能够在一定程度上提高模型识别准确率,但是由于我国智能交通发展年限较短,在大多数城市中,有关快速路瓶颈区的有记录样本并不会很多,尤其是非突发性瓶颈区样本更是很少,少样本会严重影响机器学习模型的精度。虽然快速路瓶颈区样本较少,但轨道交通瓶颈站点、高速公路瓶颈区等存在着一定的样本,由于业务的不同,这些数据样本根据传统的人工智能方法,不能用于智能模型的训练。为了解决上述问题,本文将元学习方法用于快速路瓶颈区自动识别建模中,并且该方法可以进一步扩展到轨道交通瓶颈区和高速路瓶颈区识别中。
1 模型构建
1.1 元学习方法(Meta Learning)介绍
元学习方法是一种先进的深度学习方法。元学习通过使用数据量大的相关数据集对模型进行预训练,再使用这个数据量小的训练数据集来对此预训练模型进行训练以得到精度足够高的最终模型[6]。
元学习方法从多个给定的数据量丰富的数据集:D1,D2,D3….DN,捕捉跨数据集的总体信息(例如形状和物体种类的关系,车流量和交通拥堵情况的关系),从而当我们有一个新的数据量较小的数据集DN+1时,可以利用学习到的跨数据集总体信息来对数据集DN+1内的特征进行更精确的判断[7,8]。
1.2 基于元学习的快速路瓶颈区自动识别模型构建
模型将快速路的瓶颈区的特征定义为五个维度:发生时段、交通事件情况、天气情况、当前区域车速、道路维修情况。将轨道交通的瓶颈站点特征定义为发生时段、发车频率、车站站台拥挤度、是否为换乘车站、是否有重大活动。将高速公路瓶颈区特征定义为五个维度:发生时段、交通事件情况、通行能力、天气情况、道路维修情况。
通过较少样本量的快速路瓶颈区数据、高速公路瓶颈区数据、轨道交通瓶颈站点数据,根据空间元学习方法,结合神经网络模型,训练得到一个通用的、精度较高的快速路瓶颈区识别模型,该模型可以实时、不间断地主动对快速路段可能会形成瓶颈区的区域和时间进行推理,一旦模型检测到可能会形成瓶颈区,会及时进行预警。
模型结构见图1。
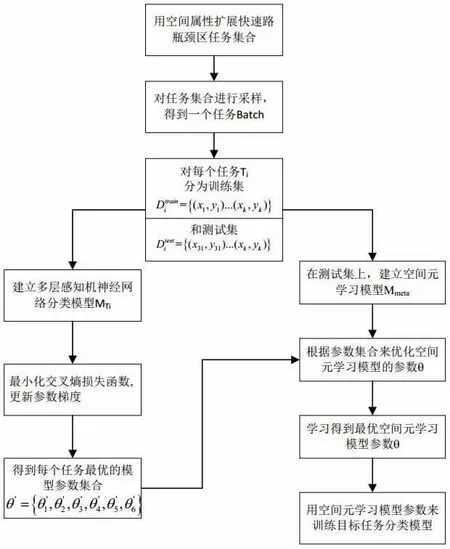
图1 模型的整体结构
1.3 模型的训练方法及参数设置
本文提出基于空间元学习结合神经网络的城市快速路瓶颈区识别方法,进行模型训练与参数调优,具体包括以下步骤:
步骤1:将快速路瓶颈区识别模型M 训练设置为2-way 100-shot,即2 个类别,每个类别包含50 个样本的分类任务。快速路瓶颈区识别模型M的输入为5 个维度。
对于快速路瓶颈区识别,模型的输入为:发生时段x1、交通事件情况x2、天气情况x3、当前区域车速x4、道路维修情况x5。对于轨道交通的瓶颈站点识别,模型的输入为发生时段x1、车辆发车频率x2、车站站台拥挤度x3、是否为换乘车站x4、是否有重大活动x5。对于高速公路瓶颈区识别,模型的输入为:发生时段x1、交通事件情况x2、行驶速度x3、天气情况x4、当前区域流量x5。将上述输入的特征进行one-hot 编码后,得到每个样本的输入X={x1,x2,x3,x4,x5},输出Y={y1,y2},其中y1代表形成了瓶颈区,y2代表没有形成瓶颈区。
步骤2:确定包含空间属性的任务集合T={T1,T2,T3,T4,T5,T6,T7,T8}。T1代表了A 城市的快速路样本,T2代表了B 城市的快速路样本,T3代表了A 城市的高速公路瓶颈区相关样本,T4代表了B 城市的高速公路瓶颈区相关样本,T5代表目标城市的高速公路瓶颈区相关样本,T6代表了A 城市的轨道交通瓶颈区相关样本,T7代表了B 城市轨道交通瓶颈区相关样本,T8代表了目标城市轨道交通瓶颈区相关样本。
任务集合T 为相似任务的集合,“相似任务”不仅包括高速公路瓶颈区识别模型和轨道交通瓶颈站点识别模型,还包括空间属性。不同的城市之间瓶颈区形成因素变化较大,因此空间属性有效地扩展了“任务集合”,从而进一步提高了元学习的算法精度。
步骤3:确定空间元学习模型MMETA 的神经网络结构,多层感知机神经网络模型输入层有5 个神经元,有2 个隐藏层,第一个隐藏层有4 个神经元,第二个隐藏层有3 个神经元,输出层有2 个神经元,激活函数为Sigmoid 函数,最后输出层的激活函数为Softmax。随机初始化空间元学习模型MMETA 的权重参数θ。
步骤4:设定每个任务Ti在任务集合T 中满足均匀分布p(T),从任务集合T 中按照均匀分布概率从8 个任务中采样6 个任务,组成了用于空间元学习模型Mmeta的训练样本集S={T1,T2,T3,T4,T5,T6}。
步骤5:开始进行内循环,求得每个任务上的最优模型权重参数θi',i=1,2,3,4,5,6,包括以下步骤:
步骤5.1:对训练样本集S={T1,T2,T3,T4,T5,T6}中的每个任务Ti,i=1,2,3,4,5,6,制作好训练数据集Dttrain={(x1,y1),(x2,y2),…,(x30,y30)}和测试数据集Dttest={(x31,y31),(x32,y32),…,(x50,y50)}。
步骤5.2:对于每个任务Ti,确定分类模型为多层感知机神经网络模型MTi,多层感知机神经网络模型MTi模型结构与空间元学习模型结构相同。损失函数为交叉熵LTi(fθ)。
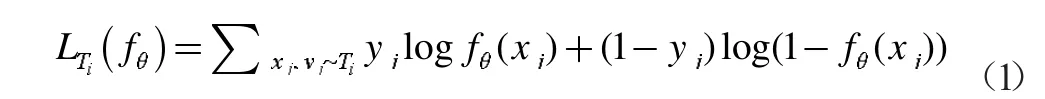
式中,xj表示训练数据集Ditrain中的样本输入值,yj表示Ditrain中的标签值,fθ(xj)表示多层感知机神经网络模型MTi预测出来的结果。
步骤5.3:对于每个任务Ti,在训练数据集Ditrain上,用梯度下降的方法对模型权重参数θi'进行更新,即最小化损失函数。模型权重参数θi'的更新计算公式为:

式中,θ 表示更新前的模型权重参数,α 表示学习率,取值0.001。

表1 快速路示例数据

表2 上海轨道交通某区域部分站点数据
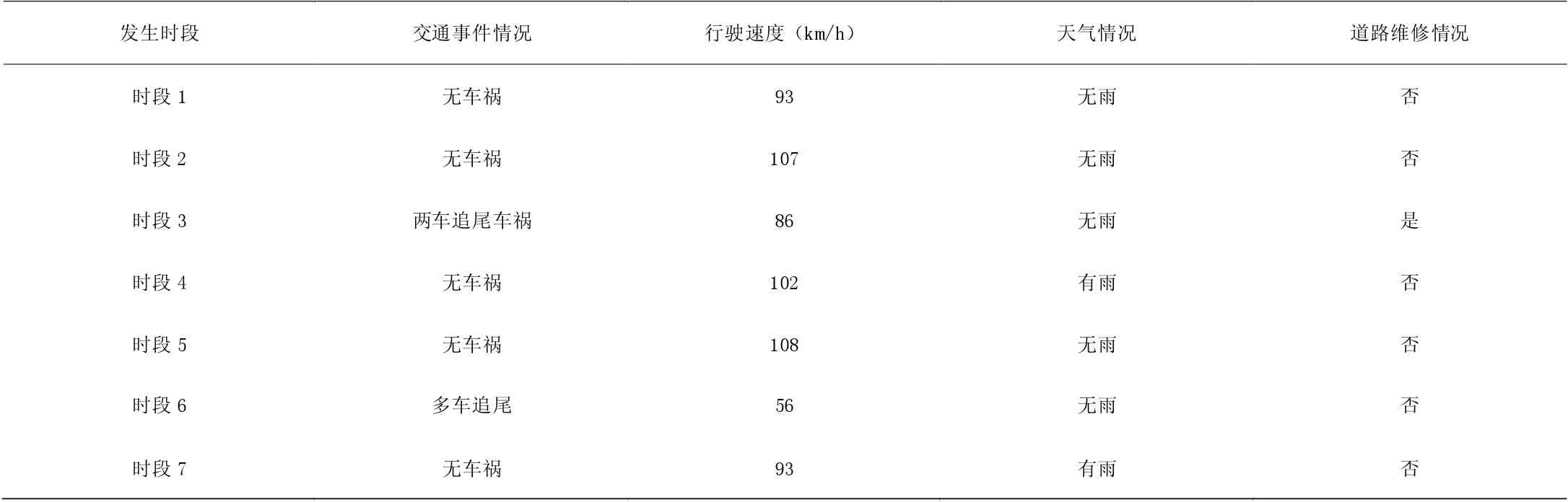
表3 某高速段交通数据
最后得到采样出来的6 个任务的模型最优参数集合θ'={θ1',θ2',θ3',θ4',θ5',θ6'}。
步骤6:开始进行外循环:在测试数据集Ditest上,对空间元学习模型Mmeta 的权重参数θ 进行优化更新,更新公式为:
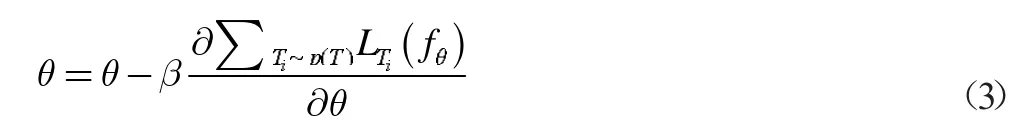
式中,∑Ti~p(T)LTi(fθ)为损失函数,是子任务模型(根据每个任务Ti建立的模型)最优参数下的预测误差之和;β 为空间元学习模型学习率,取值为0.002;
步骤7:重复上述步骤4 到步骤6,进行10 次迭代,直到收敛。
步骤8:最后学习得到的空间元学习模型Mmeta的权重参数θ 为目标任务的最优模型初始参数。对于目标任务,只要在少量样本上进行2 次迭代,即可得到快速路瓶颈区识别模型M。当路况发生了变化,模型判别出将会形成瓶颈区后,会及时主动发出预警。
2 案例分析
2.1 数据集介绍
本次实验所用的快速路数据主要是上海市某高架发布段数据。数据示例见表1。
本次实验所用的轨道交通站点数据为上海地铁在浦东新区区域的各站点。数据示例见表2。
本次实验所用的高速公路数据采用了某高速段的数据。数据示例见表3。
2.2 模型精度评价指标
本文采用召回率(Recall score)、精确率(Precision)、F1 分数、ROC 曲线来衡量模型的好坏。
(1)召回率
召回率(Recall score)说明了被正确预测为阳性的样本占所有阳性样本的比例,计算公式为:

式中,Recall 表示召回率,TP 表示正确阳性,FN 表示错误阴性。当召回率越接近于1,这个模型的准确率就越高,召回率的取值范围是0-1。
(2)精确率
精确率(Precision)说明了被正确预测的阳性样本占所有被预测为阳性的样本的比例,计算公式为:

图2 是基于元学习模型的ROC 曲线。横坐标表示假阳率,
式中,P 表示精确率,TP 表示正确阳性,FP 表示错误阳性。当精确率越接近于1,这个模型的准确率就越高,精确率的取值范围是0-1。
(3)F1 分数
精度和召回指数在某些时候是不可兼得的,需要一个更加全面的评价指标来综合考虑精度和召回指数这两个指标。F1 分数可以看做是模型精确率和召回率的一种调和平均,计算公式为:

式中,F1 表示分数,P 表示精确率,Recall 表示召回率。当F1 分数越接近于1,这个模型的准确率就越高,F1 分数的取值范围是0-1。
(4)ROC 特征曲线(ROC 曲线)
ROC 曲线代表了在不同的操作条件(阈值)下,其敏感性(FPR)和精确性(TPR)的趋势走向。ROC 曲线上每一个点表明了不同阈值下的敏感性和精确性。ROC 曲线的横轴为敏感性,竖轴为精确性。敏感性和精确性可以表述为以下公式:

式中,FPR 表示敏感性,TPR 表示精确性,TP 表示正确阳性,FN 表示错误阴性,FP 表示错误阳性,TN 表示正确阴性。
3 结果分析
对该模型的精确度本文使用了召回率、精确率、F1 分数进行了评价。具体评价结果见表4。

表4 模型的精确度评价指标
召回率和精确率均达到了85%以上,F1 分数达到了0.862。该模型的精确度已经足够高,达到了建模的目的。
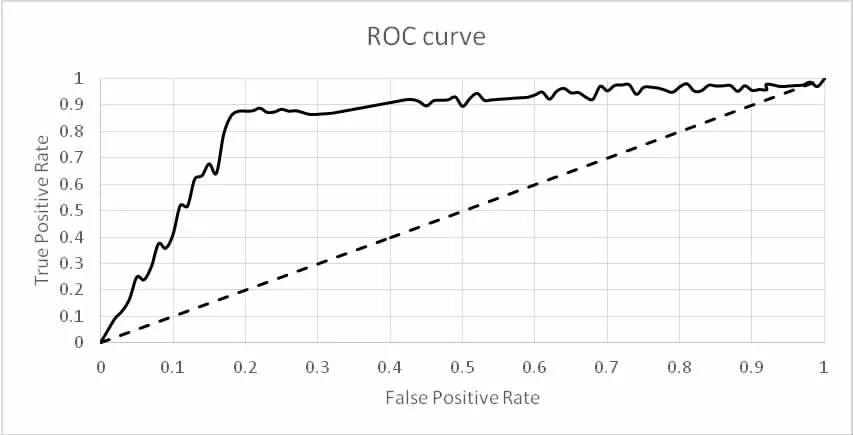
图2 模型ROC 曲线
本文还使用了接受者操作特征曲线(ROC 曲线)进行了评价。具体结论见图2。纵轴表示真阳率。图中实线是元学习模型的ROC 曲线。图中虚线是对角线,对应的是一个“随机猜测模型”(50%的概率猜测正确)。ROC 曲线越靠近左上角,模型的预测准确率就越高。对于图中的左上角,即坐标为(0,1)这个点,对应的是“理想模型”(ideal model),其中FPR=0,同时TPR=1,这意味着模型把所有的样本都分类正确。从上图中可以看到,元学习模型(转下页)靠近左上角,说明元学习模型的准确率较高。
4 结论
本文使用元学习方法来构建预测模型,能够在城市快速路瓶颈区数据集的数据量非常小的情况下,利用有足够大的数据量的轨道交通站点及高速公路的数据集对模型进行预训练,有效提高城市快速路瓶颈区小样本模型的识别精度。并且以上海某高架段为例,结果显示得到的元学习模型准确率为85.3%,召回率为87.1%,F1 得分为86.2%。本模型一定程度上解决了小数据量情况下如何进行交通预测的现实问题,对城市快速路瓶颈区能够进行智能精确自动识别,从而及时提前进行预警,为后续的交通诱导措施和决策提供精准及时的信息依据,有效缓解城市拥堵。
猜你喜欢
中国水运(2022年4期)2022-04-27
商品与质量(2021年14期)2021-11-23
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
作文周刊·高二版(2019年43期)2019-01-06
建筑工程技术与设计(2015年33期)2015-10-21
创业家(2015年9期)2015-02-27
体育师友(2012年1期)2012-03-20
商场现代化(2009年16期)2009-06-22
