
以数据质量为核心的电网调度数据治理应用研究
2020-11-29 14:05梅傲琪周立德
机电信息 2020年33期
梅傲琪 张 锐 周立德
(广东电网有限责任公司东莞供电局,广东东莞523008)
0 引言
在信息技术逐渐走向完善的当下,数据不断膨胀的情况无法避免,在电网数据治理方面,全面分析由现场数据构成的大数据已成为大势所趋,这也是相关人员纷纷选择利用由大数据所衍生出的理念和技术,围绕数据质量对治理体系进行设计的原因。由此可见,本文所研究课题有较为突出的社会价值,应当引起重视。
1 研究背景
对电网数据进行治理的初衷是为用户提供优质服务以及给用户带来更符合预期的体验,而持续增长的电网数据致使用来存储和分析数据的常规体系面临着被淘汰的风险,要想使数据提取及分析工作发挥出应有价值,并为调度工作指明方向,优化现有系统是必然选择。由研究所得结论可知,要想使数据治理及相关工作取得和预期相符的良好效果,最有效的方法便是对大数据进行引入,这是因为由大数据延伸出的技术可使高效检测数据、离线分析数据等设想成为现实。基于此,本文选择以大数据调度为基础,借助云平台所拥有的功能,参考数据所表现出的特点,通过分布存储并处理数据的方式,对大数据容错性进行凸显,另外,数据存储量也会得到显著增加。与此同时,本文还以分离器为载体,对电网数据所适用调度方法进行了设计,通过将调度方法融入处理框架的方式,确保输入数据可获得理想的挖掘及处理质效,检测精度随之提升,数据治理自然也会拥有符合预期的精度。
2 数据治理应用
2.1 治理体系
研究表明,若将数据质量视为核心,对电网数据进行治理,与常规数据治理模式间有十分明显的差异存在,具体表现为:对数据挖掘、云平台存储及其他相关技术进行引入。技术人员对治理体系的设计如图1所示,此体系涵盖诸多功能模块,例如数据挖掘/存储、输入解析等[1]。其中,输入解析强调对数据进行解压缩处理,明确数据所处阵营为实时数据或是历史数据,判断数据控制方向为存储还是应用展示。另外,在传输或存储数据时,通常以压缩数据为依托,旨在避免大量带宽、存储空间被数据占用的情况出现,所引入云平台,在解压缩方面,现已拥有相对完善的技术,这也为压缩数据得到充分利用提供了有力的技术支持。
在数据挖掘方面,本文拟采用以映射规约所衍生出的并行设计,通过筛选并全面评价电网数据的方式,确保所设计治理体系可发挥出应有作用。从本质上说,映射规约是映射、规约的集合体,通常要先分别处理再进行整合,才能满足大数据所提出的诉求。
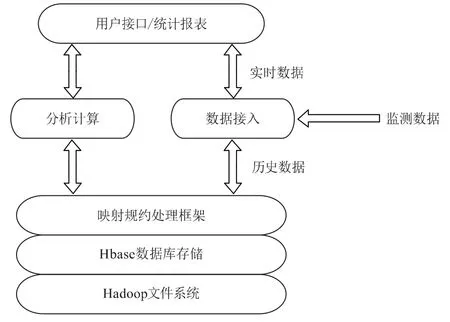
图1 治理框架图
而数据存储所依托工具为数据库,本文所选用数据库即可借助键值对,高效完成标记存储数据的操作,且拥有理想的存储质效。另外,这样做对非关系数据的处理操作,具备较为突出的积极影响,这点应尤为重视。
2.2 治理方法
众所周知,数据治理的切入点通常为实时数据、历史数据,这也给调度系统提出了较为严格的要求,一方面,要对数据流进行从容应对,另一方面,要拥有分布存储数据所适用的处理功能,可借助Hadoop等平台,为分布存储数据提供融合框架,并为业务处理及后续环节的开展做铺垫。研究表明,映射和规约都是调度管理不可或缺的步骤,二者往往被用来对数据集合进行分割与并发排序,在落实相关工作时,技术人员应确保映射结果可向规约任务进行实时发送,而规约任务的作用主要是重新融合所接收子集,获得以原始数据为主要内容的集合,并借助作业跟踪器完成分析及调度压缩集合的操作。
下文将以优化治理效果为出发点,以调度技术为依托,综合考虑数据层次及其他相关因素,对管理过程进行描述,供技术人员参考。
首先,管理层要控制大量数据,在存储和传输数据的同时,对数据集合进行精准分割。
其次,处理层强调以作业跟踪器为依托,将任务融入计算架构,参考键值对所表现出的方式,完成映射及排序现有任务的操作,并向规约操作进行传输。随后,经由规约操作,逐一合并相关子集,以键值对为参考,通过逆运算的方式,得到未经处理的真实数据。
最后,挖掘层往往与映射、规约存在密切联系,通过检测识别预处理大数据的方式,获得可被用来衡量电能质量及其状态的结论。
上文所提映射规约操作,现阶段常被用来并行分析及深入挖掘数据,其中,并行操作与大数据调度表现出特征高度契合,对数据集合进行分割时,技术人员往往会选择对分类器加以运用,现有分类器较多,Naive Bayes的出镜率较高,一方面,此分类器对参数的依赖性较弱,另一方面,此分类器未对参数完整与否提出要求,稳定性突出。本文用X={x1,x2,…,xn}代表电网数据集合,通过数据计算的方式,明确不同数据特点对应条件概率公式为:
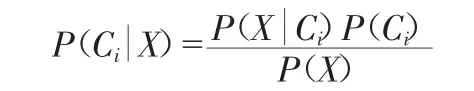
式中:P(Ci)指代基于原始数据所得先验概率;Ci指代分割子集[2]。
另外,技术人员仅需直接计算,便可明确离散数据所表现出特征,而连续数据的计算流程,通常是先转化为离散数据,再利用相关公式完成计算。
在借助分类器对数据子集进行分割后,技术人员应对不同任务适用处理和分配加以设计,一般来说,客户端程序是配置任务的主体,待配置环节结束,再向任务跟踪器对任务进行下发,确保任意跟踪器都有需要映射和规约的任务与之对应,并且所产生数据均利用固定文件系统加以保存。
若以分类器为依托,对数据进行全面处理,通常要经历以下步骤:
第一步为输入分离,落实该步骤时,技术人员应借助文件处理的方式,使映射规约数据分离,经由分离所得输入数据,通常由分片大小及位置构成,另外,还应在数据区对原始数据进行系统存储。
第二步为拆分任务,以贝叶斯公式为依托,明确不同节点对应选择概率及先验概率,为参数拆解提供便利,待获得映射规约任务后,技术人员应借助追踪器对概率计算流程进行管理,并确保所输入数据满足键值对特征。
第三步为数据分类,从全局的视角出发,结合上文所介绍公式,对未得到识别数据的选择概率进行计算,确保任意数据样本都有分类与之对应。
3 实证结果分析
信息时代的到来,使电网系统拥有了更加广泛的覆盖范围,对数据进行获取的途径也不断增加,在落实数据治理的相关工作时,只有及时转变观念,对大数据及所涉及技术进行充分运用,通过建立治理体系的方式,为电网系统提供可靠而安全的运行环境,才能使电力企业乃至整个行业拥有源源不断的前进动力。
本文拟利用仿真实验,对数据检测流程、计算处理环节、最终结果评估分别进行模拟,搭建分布处理平台,其中,主节点的作用是拆解并分配数据,子节点的功能则是计算与存储数据,将检测精度打造成核心评价指标,确保治理成果经由直观且准确的方式展现。由检测精度实验所得曲线(图2)可知,在数据量不断增加的前提下,检测精度的下降趋势十分明显且平缓,8×104的数据量,通常对应80%的检测精度,由此可见,检测精度和理想水平的差距较小,可被用来对电网数据进行治理[3]。另外,图2所绘制曲线还表明,检测过程无震荡问题存在,这也佐证了“基于数据质量所开展治理工作,拥有良好抗噪能力”的观点。
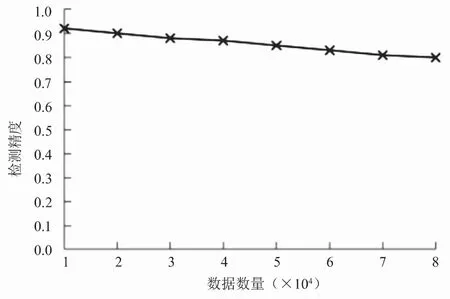
图2 实验曲线
综上,在调度和检测数据不断增加的当下,持续膨胀的电网数据使治理工作面临着巨大挑战,原有模式所取得成绩与理想状态相距甚远,这便是本文所研究课题的提出背景。事实证明,将数据质量打造成治理核心,以大数据云平台为依托,经由数据库存储相关数据,并对调度方法进行设计与完善,可使电网数据得到深入挖掘和系统解析。
4 结语
从数据治理的视角来看,大数据所带来的影响有明显的两面性,一方面,使电网运行拥有了强有力的技术支持,另一方面,后续开展的信息处理等工作,无形中被赋予了更高难度。基于此,技术人员以数据质量为切入点,结合电网数据所表现特点,对治理工作适用体系进行了设计,投入运行后,此体系所取得成绩较为醒目。
猜你喜欢
北方民族大学学报(2021年5期)2021-11-27
云南农业(2021年11期)2021-11-12
水上消防(2021年4期)2021-11-05
装备制造技术(2020年4期)2020-12-25
装备制造技术(2020年4期)2020-12-25
北京航空航天大学学报(2018年10期)2018-10-30
中国惯性技术学报(2017年5期)2017-12-02
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
汽车维修与保养(2015年2期)2015-04-17
